神经网络:基本原理
欢迎访问个人博客网站获取更多文章:
此篇写给对神经网络感兴趣,但是还没入门的同学们。
从最简单的一元线性回归开始,延伸到神经网络的基本原理。
1. 最简单的学习
我们首先来看一个我们最熟悉的“机器学习“——一元线性回归
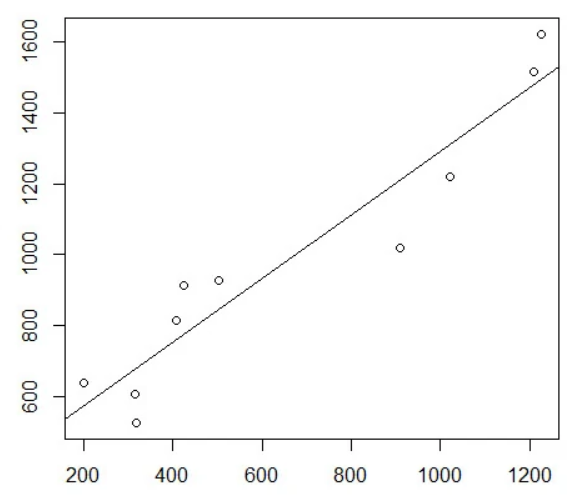
- 通过给定的一系列样本点\((x, y)\),我们计算出一条直线来拟合这些点,使给定的自变量\(x\)的预测值\(\hat{y}\)尽可能地接近真实值\(y\),这一直线需要通过两个参数—截距和斜率确定下来。当有新的自变量\(x\)时,我们就可以根据这条直线预测出一个\(\hat{y}\)值。这便是一种机器学习了。直线的斜率、截距便是这个机器学习模型的参数。计算直线的斜率、截距的过程便是学习的过程。
从一元线性回归到神经网络
-
稍微的将这一原理拓展一下:以自动驾驶中识别路标这一算法为例,这一模型接收一个自变量\(x\)(x是图片),输出一个预测值\(\hat{y}\)(y可以是路标的种类,比如用0代表“不是路标”,1代表“禁止停车”等),计算的过程中需要用到许多参数。在创建这一模型时,我们需要有大量的样本点\((x, y)\)让这个模型来学习,不过这里的\(x\)是一张张图片,而\(y\)则是路标的种类。通过大量的样本点和特定的算法,我们可以计算出模型中的参数,让模型的预测结果\(\hat{y}\)尽可能地逼近真实值\(y\),这一计算的过程就是该模型学习的过程,或者说训练的过程。学习结束后,我们就可以实际运用这一模型了。
-
对比一下这两段话,就可以看出一个复杂的机器学习模型实际上和一元线性回归的原理是相同的。
-
因为一元线性回归过于简单,所以可以直接用公式计算出所需要的参数。但是实际的机器学习问题需要有数以万计的参数,没办法直接通过公式直接计算,只能用梯度下降算法不断逼近理想值。
-
关于梯度下降的介绍会在后续博文中介绍。
2. 神经网络的计算过程
-
神经网络计算方式
神经网络实际是一种图,用节点表示数值,用边表示计算方式。
![image-20210731075730371]()
-
通常将第0层称为输入层(input layer),用于输入自变量的各个参数;最后一层称为输出层(output layer),剩下的的中间层统称为隐藏层(hidden layer)。如图所示,一个神经元会与前一层的所有神经元链接,这样的层也叫做全连接层,除此之外,还存在卷积层,池化层等等类型,将在后续进行介绍。
-
使用一定的计算方式,从第1层开始逐层计算神经元的值,一直向前计算到输出层就可以得到这个神经网络的输出了。这个过程也称为前向传播(forward propagation)。
-
-
计算方式
-
我们这里先只介绍全连接层的计算方式。
-
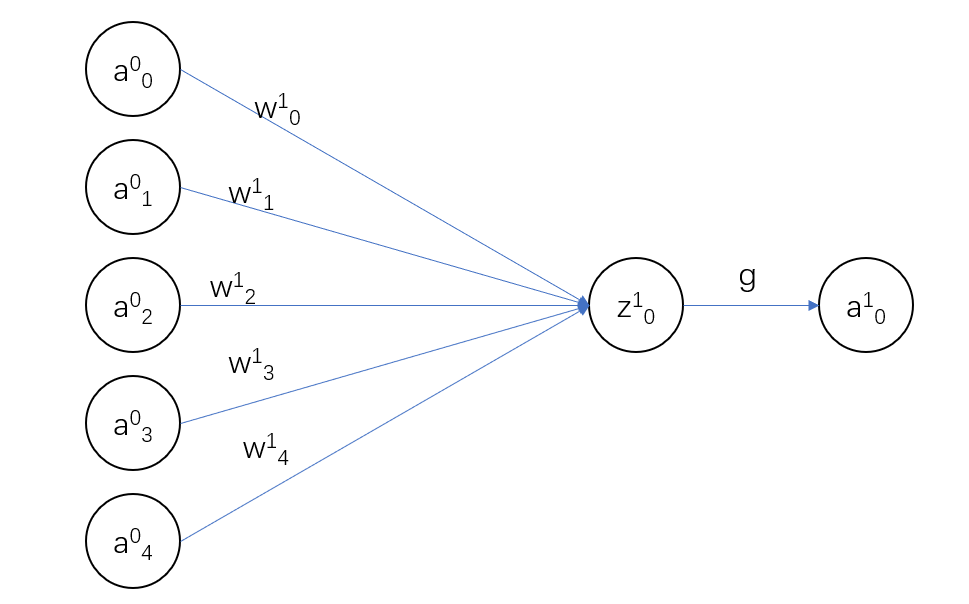
以第0层和第1层中的一部分为例:
![image-20210729102824005]()
-
\(z^{(1)}_0=w^{(1)}_0a^{(0)}_0+w^{(1)}_1a^{(0)}_1+w^{(1)}_2a^{(0)}_2+w^{(1)}_3a^{(0)}_3+w^{(1)}_4a^{(0)}_4+b^{(1)}\)
-
\(z^{(1)}_0=\sum_iw^{(1)}_ia^{(0)}_i+b^{(1)}_0\)
-
\(a^{(1)}_0=g(z^{(1)}_0)\),\(g\)是激活函数(\(activation\)),在后面会提到。
-
\(w\)叫做权重值(\(weight\)),\(b\)叫做偏置(\(bias\))。\(w\)和\(b\)是我们这一层的参数,需要通过算法将它们调整为合适的值。
-
-
上标、下标约定:
- 神经网络往往分成许多层,\(a^{(t)}_i\)是指第\(t\)层的第\(i\)个节点,\(w^{(t)}_i\)是指第\(t-1\)层到第\(t\)层的权重值中的第\(i\)个,\(b^i\)是指第\(t-1\)层到第\(t\)层的偏置。
-
关于梯度下降算法可以去看以下视频,讲解非常清晰。这一系列视频包括了整个神经网络的原理,十分生动形象。非常推荐去看这一系列视频。

https://www.bilibili.com/video/BV1bx411M7Zx/?spm_id_from=333.788.recommend_more_video.0
实操
-
下面这篇博文介绍了用神经网络解决“手写数字识别”问题的过程,需要读完这一系列博文后才能完全看懂,但是感兴趣的也可以提前看一下👇
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号