情韵杂七杂八的学习笔记
北方情韵学习笔记
idea快捷配置类的创建时信息
效果图:

添加步骤:
- 创建File Header 和File Top
ctrl + alt + s 打开设置 搜索 File and code Template

分别创建两个文件:
File Header:

/**
*
* <p>Project: ${PROJECT_NAME} - ${NAME}
* <p>Powered by ${USER} On ${YEAR}-${MONTH}-${DAY} ${HOUR}:${MINUTE}:${SECOND}
*
* @author ${USER} [tianwenle2000@163.com]
* @version 1.0
* @since 17
*/
File top:

/*
* Copyright (c) 2006, ${YEAR}, ${USER} 编写
*
*/
-
在Files找到
Java的class文件粘贴下面代码:
#parse("File Top.java") #if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end #parse("File Header.java") public class ${NAME} { }此时就添加完成了
添加代码快捷注释
按道理来说应该有三种注释快捷键添加的 ,但是我感觉作用大一些两种
注释的演示
-
个人信息快捷注释
效果图:

-
类信息快捷注释
效果图:

这个和自带的注释虽然差不多,不过感觉像是一种对本来的一种加强
自带的方法注释:

添加步骤
打开设置,搜索
Live Templates
-
添加
Template Group为了不和idea自带的快捷键冲突,也为了方便查找修改,最好还是自己添加一个

-
选中自己添加的快捷模板 添加Live Template
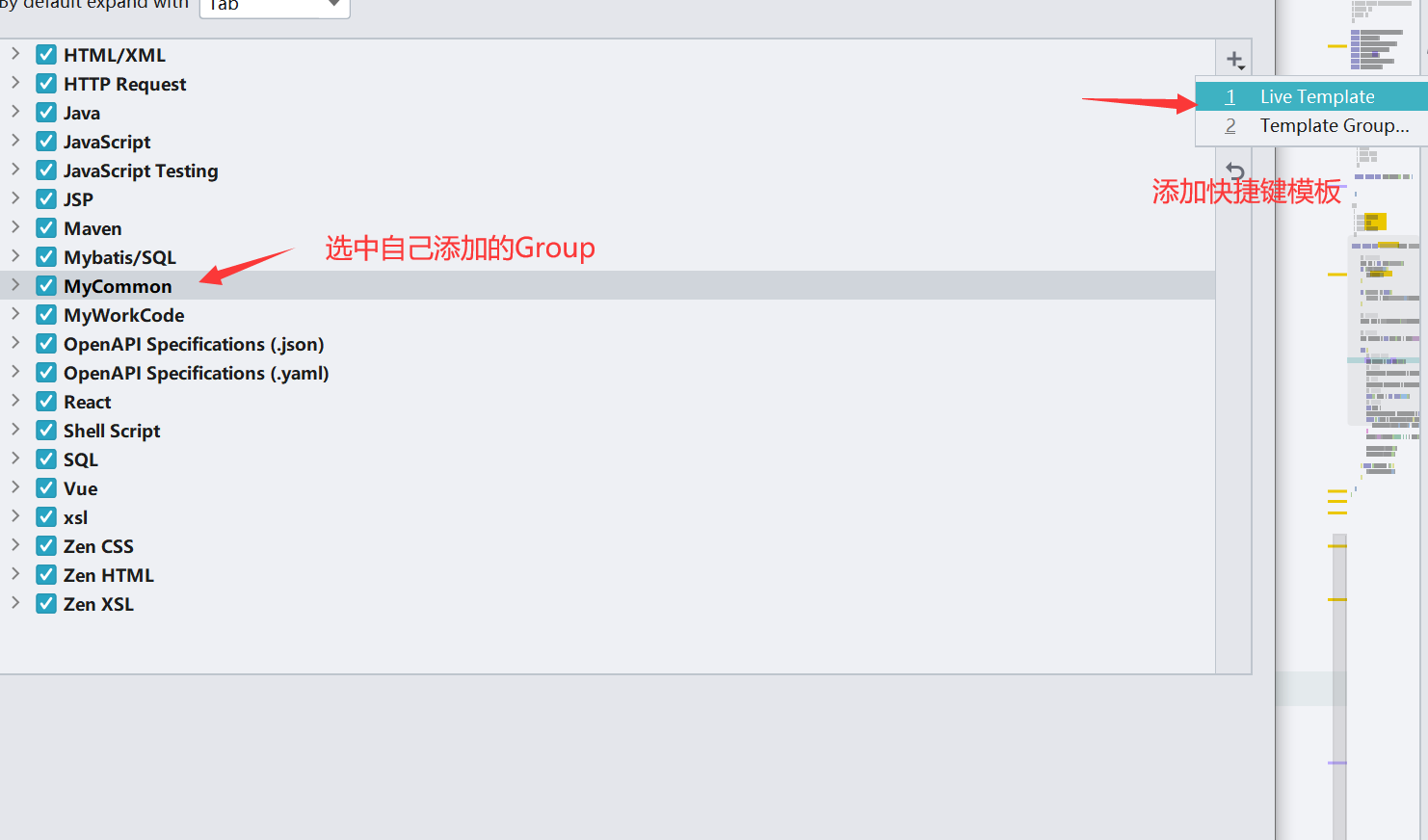
-
添加个人信息注释快捷键

代码如下:
/** * <p>Powered by $user$ on $y$-$m$-$d$ $time$</p> * @author $user$ [tianwenle2000@163.com] * @version 1.0 * @since */对应变量信息:


-
添加方法注释信息快捷键
同上,添加一个新的Live Template,放在上面的Group里面就行

对应代码:
* Description: * @date: $DATE$ $TIME$ * @params $params$ * @return $return$ */对应表格数据

因为params使用官方的方法效果不太好,所以使用下面代码
groovyScript("if(\"${_1}\".length() == 2) {return '';} else {def result=''; def params=\"${_1}\".replaceAll('[\\\\[|\\\\]|\\\\s]', '').split(',').toList();for(i = 0; i < params.size(); i++) {if(params[i]=='null'){return;}else{result+='\\n' + ' * @param ' + params[i] + ': '}}; return result;}", methodParameters());完成
正则表达式的基础学习
| 实例 | 描述 |
|---|---|
[Pp]ython |
匹配 “Python” 或 “python”。 |
rub[ye] |
匹配 “ruby” 或 “rube”。 |
[abcdef] |
匹配中括号内的任意一个字母。 |
[0-9] |
匹配任何数字。类似于 [0123456789]。 |
[a-z] |
匹配任何小写字母。 |
[A-Z] |
匹配任何大写字母。 |
[a-zA-Z0-9] |
匹配任何字母及数字。 |
[^au] |
除了au字母以外的所有字符。 |
[^0-9] |
匹配除了数字外的字符。 |
| 实例 | 描述 |
|---|---|
. |
匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
? |
匹配一个字符零次或一次,另一个作用是非贪婪模式 |
+ |
匹配1次或多次 |
* |
匹配0次或多次 |
\b |
匹配一个长度为`0`的子串 |
\d |
匹配一个数字字符。等价于 [0-9]。 |
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
\w |
匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。 |
\W |
匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]‘。 |
\u4e00-\u9fa5 |
中文 汉字 |
| 符号 | 释意 | 示例 | 解释 |
|---|---|---|---|
| [ ] | 可接收的字符列表 | [efgh] | e、f、g、h中的任意1个字符 |
| [^] | 不接收的字符列表 | [^abc] | 除了a、b、c之外的任意一个字符包含数字和特殊符号。 |
| - | 连字符 | A-Z | 任意单个大写字母 |

设计一款文字加密的软件
思路: 单个字符是可以被强转为int的,比如情字对应的数字就是:24773
同理,我们可以进行数字的求余,这样就能把很多的数字,转换为两位数甚至更少的数字。将数字转换为中文字符。
接口和抽象类的区别
抽象类
抽象类本质上和普通类没什么区别,只不过在普通类的基础上,可以定义抽象方法。
抽象方法必须是被public abstatct修饰。
抽象类可以不包含抽象方法,但包含抽象方法的类一定是抽象类。
抽象类不能直接被实例化,如果通过new关键字实例化,会产生内部类。

编译的时候如果编译不出来,得从包名处进行编译。

抽象类可以通过被子类继承实现抽象方法后使用。
接口
接口在JDK 1.7和JDK 1.8及以后略显不同
jdk1.7之前
接口包含:常量和抽象方法。
jdk1.8及以后
Java 1.8定义接口新规则,接口包含:常量,抽象方法,default默认方法,以及static静态方法。
如果抽象方法有且仅有一个,就会被当做函数式接口,可以主动标注 @FunctionInterface注解,也可以不标记
通过lambda表达式进行声明函数时接口不会产生内部类。但是通过new 接口的方式会产生匿名内部类。
== 和 equals()方法区别
-
对于基本类型来说,==用来比较数值的大小,基本类型没有equals()方法。
-
对于引用类型来说 ,==用来比较地址值,equals()用来比较引用类型的数值大小
-
所有的引用类型都有equals()方法。
-
如果自己在创建某个类时没重写equals()方法,则默认使用object的equals()方法
/* JDK17: String的equals() */ public boolean equals(Object anObject) { // 如果地址相同 直接判定为相同 if (this == anObject) { return true; } return (anObject instanceof String aString) // 类型是否相同 && (!COMPACT_STRINGS || this.coder == aString.coder) // 编码格式是否相同 && StringLatin1.equals(value, aString.value); // 如果前面两个都相同 这里判断内容是否相同 } /* StringLatin1.equals(value, aString.value) */ @IntrinsicCandidate public static boolean equals(byte[] value, byte[] other) { if (value.length == other.length) { for (int i = 0; i < value.length; i++) { if (value[i] != other[i]) { return false; } } return true; } return false; } /* JDK8: String的equals() */ public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; // 较于JDK17 , JDK8 String的equals方法少了对编码格式的判断 if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
块级字符串 JDK14
String str = """
字符串内容。
""";
相同字符串【面试题】

我感觉还是集合用着舒服
/*
* Copyright (c) 2006, 2022, wuyahan 编写
*
*/
package cn.lele.stropt;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* <p>Project: CrossFireAndLive - Main
* <p>Powered by wuyahan On 2022-12-28 09:41:51
*
* @author wuyahan [tianwenle2000@163.com]
* @version 1.0
* @since 17
*/
public class Main {
public static void main(String[] args) {
String[] strs = {"eat", "book", "tea", "tan", "ate", "nat", "bat", "bkoo"};
System.out.println("Arrays.toString(strs) = " + Arrays.toString(strs));
String[] strings = strs[0].split("");
List<String> list = new ArrayList<>();
List<String> result = new ArrayList<>();
// 如果之前检测到相同的单词 则跳过 ,继续没有检测过的
for (String str : strs) {
if (!list.contains(str)) {
List<String> eachOne = eachOne(strs, str.split(""));
result.add(Arrays.toString(eachOne.toArray()));
list.addAll(eachOne);
}
}
System.out.println("result = " + result);
}
// 获取每次循环到的相同字母的集合
private static List<String> eachOne(String[] strs, String[] strings) {
List<String> list = new ArrayList<>();
for (String str : strs) {
int i;
for (i = 0; i < strings.length; i++) {
if (!str.contains(strings[i])) {
break;
}
}
if (i == strings.length) {
list.add(str);
}
}
return list;
}
}
计算123456789等于100【 面试题】
public static void main(String[] args) throws IOException {
Set<String> set = new HashSet<>();
for (int i = 0; i < 10; i++) {
new Thread(()->{
while (true){
StopWatch watch = new StopWatch();
watch.start("计算11种需要多长时间");
String s = numsGenerator();
if (getSum(s)){
set.add(s);
}
if (set.size() == 11){
watch.stop();
System.out.println(watch.getLastTaskName() + " ---- " + watch.getTotalTimeMillis() + "毫秒");
break;
}
}
}).start();
}
}
private static String numsGenerator() {
StringBuilder builder = new StringBuilder("1");
String[] opt = {"+", "-", ""};
Random random = new Random();
for (int i = 2; i <= 9; i++) {
builder.append(String.format("%s%d", opt[random.nextInt(3)], i));
}
return builder.toString();
}
private static boolean getSum(String nums) {
// -? 代表有一次或者0次-
Pattern pattern = Pattern.compile("-?[0-9]+");
int sum = 0;
Matcher matcher = pattern.matcher(nums);
while (matcher.find()) {
int i = Integer.parseInt(matcher.group());
sum += i;
}
return sum == 100;
}
异常的继承实现图

List集合源码分析
再次接触List集合,已经有一定的能力可以看看List的源码,接下来便分析一下。
ArrayList源码分析
-
构造方法
无参数构造方法:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; transient Object[] elementData; // non-private to simplify nested class access public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }可以发现,ArrayList集合底层采用数组。当我们采用无参构造方法初始化的时候,默认会初始化一个空数组。
初始化容量构造方法:
private static final Object[] EMPTY_ELEMENTDATA = {}; transient Object[] elementData; // non-private to simplify nested class access public ArrayList(int initialCapacity) { // 如果容量大于0,则创建一个容量为初始化值的数组,赋值给底层的数组 if (initialCapacity > 0) { this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { // 如果初始化数值为0,则赋值一个空对象 this.elementData = EMPTY_ELEMENTDATA; } else { // 小于零就直接抛出异常 throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); } }当初始化时ArrayList数组时,如果在参数部分填上数值,则代表初始化容量:
ArrayList<String> list = new ArrayList<>(18);
通过添加另一个集合的方式来初始化
// 官方注释: 数组列表的大小(它包含的元素数) // The size of the ArrayList (the number of elements it contains). private int size; private static final Object[] EMPTY_ELEMENTDATA = {}; public ArrayList(Collection<? extends E> c) { // 将传入的集合转化成数组 方便后面赋值给底层的数组 Object[] a = c.toArray(); // 判断传入数组的容量是否不等于0 , // 如果不等于0就把传入集合的元素数量传给ArrayList的计数变量 size if ((size = a.length) != 0) { // 判断传入的集合是否为ArrayList对象 如果时ArrayList直接将传入集合转化的数组赋值给底层数组 // 这里再JDK8有提示: // c.toArray might (incorrectly) not return Object[] (see 6260652) /* 因为看的是JDK17的源码 所以 ‘‘感觉’’下面判断好像貌似似乎可以不加 用JDK17好像复现不了jdk8的错误了 有兴趣的取百度搜一下 */ if (c.getClass() == ArrayList.class) { elementData = a; } else { // 不是ArrayList对象则拷贝传输的集合转化的数组给底层的数组 elementData = Arrays.copyOf(a, size, Object[].class); } } else { // replace with empty array. // 如果传入的集合元素数量为0,则初始化底层的数组为空数组 elementData = EMPTY_ELEMENTDATA; } }Collection继承图:

-
添加元素
一个参数的添加元素
/* 官方解释:此列表在<i>结构上被修改的次数<i>。结构修改是指更改列表大小或以其他方式干扰列表,使正在进行的迭代可能会产生不正确结果的修改。<p>此字段由 {@code 迭代器} 和 {@code listIterator} 方法返回的迭代器和列表迭代器实现使用。如果此字段的值意外更改,迭代器(或列表迭代器)将抛出 {@code ConcurrentModificationException} 以响应 {@code next}、{@code remove}、{@code previous}、{@code set} 或 {@code add} 操作。这提供了<i>快速故障行为<i>,而不是在迭代期间面对并发修改时的非确定性行为。<p><b>子类使用此字段是可选的。<b>如果子类希望提供快速失败迭代器(并列出迭代器),则只需在其 {@code add(int, E)} 和 {@code remove(int)} 方法(以及它覆盖的任何其他导致列表结构修改的方法)中递增此字段。对 {@code add(int, E)} 或 {@code remove(int)} 的单个调用必须向此字段添加不超过一个,否则迭代器(和列表迭代器)将抛出虚假的 {@code ConcurrentModificationExceptions}。如果实现不希望提供故障快速迭代器,则可以忽略此字段。 个人理解:避免在使用迭代器进行遍历的时候,有另外线程进行添加或者修改元素,从而出现不正确的结果 如果计算的结果modCount和预计的结果不相等就会出现并发修改异常。后面迭代遍历再说。 */ protected transient int modCount = 0; public boolean add(E e) { modCount++; // 调用添加元素的方法 add(e, elementData, size); // 默认返回值 true 插入成功与否都会提示true return true; } // 被调用添加的方法 private void add(E e, Object[] elementData, int s) { // 判断如果当前数组的实际容量如果和size大小一致 就调用grow()方法提升容量 // elementData虽然是存放数据的地方,但真正控制集合大小 还是由size来决定。 // 如果size 等于 底层数组的长度,就代表要进行扩容了 if (s == elementData.length) elementData = grow(); // 不需要扩容就进行赋值 elementData[s] = e; // 添加一个元素 size要加1 size = s + 1; } // ========== 添加容量的方法 =============== // 继续调用另一个方法 private Object[] grow() { return grow(size + 1); // 这里加1 ,是当前数组存下刚加入的元素需要的最小容量 } // 真正扩增容量的方法 /* 官方解释:增加容量以确保它至少可以容纳最小容量参数指定的元素数。 @param 最小容量 所需的最小容量 @throws内存不足错误 最小容量小于零时出错。 */ private static final int DEFAULT_CAPACITY = 10; private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; private Object[] grow(int minCapacity) { // 现在的容量 = 现在底层数组的容量长度 int oldCapacity = elementData.length; if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { int newCapacity = ArraysSupport.newLength(oldCapacity, minCapacity - oldCapacity, /* minimum growth */ oldCapacity >> 1 /* preferred growth */); return elementData = Arrays.copyOf(elementData, newCapacity); } else { // 如果当前底层数组的长度为0 或者数组还是一个{} // 就给数组初始化长度10,或者当前底层数组的容量 return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)]; } } /** * 所以,当ArrayList用无参方法初始化时,默认容量为0。 当第一次添加时 如果添加的元素的数量小于10,则默认数量为10. 如果元素数量等于10时,再次添加容量会扩充到1.5倍。 通过构造方法添加元素时,容量变成构造方法的提供的容量/传入集合的数量, 下一次再添加时,容量扩充到1.5倍。 * **/ /* oldLength: 当前底层数组的容量 minGrowth: 所需要的最小容量 ==== 1 / 添加集合的长度 (当前集合需要添加的最小容量) prefGrowth: 首选增长量 (oldLength >> 1) 并不是每次添加都会出发这个机制,只有当底层数组容量不够支持再添加下一个元素时,会触发这个机制 */ public static int newLength(int oldLength, int minGrowth, int prefGrowth) { // preconditions not checked because of inlining // assert oldLength >= 0 // assert minGrowth > 0 int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // might overflow if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) { return prefLength; } else { // put code cold in a separate method return hugeLength(oldLength, minGrowth); } } // 这里时避免集合数量达Math.max时 继扩容就是每次增长1 不进行1.5倍扩容 private static int hugeLength(int oldLength, int minGrowth) { int minLength = oldLength + minGrowth; if (minLength < 0) { // overflow throw new OutOfMemoryError( "Required array length " + oldLength + " + " + minGrowth + " is too large"); } else if (minLength <= SOFT_MAX_ARRAY_LENGTH) { return SOFT_MAX_ARRAY_LENGTH; } else { return minLength; } } // 对ArrayList集合进行反射 ,查看真实的容量 private static int getArrayListLength(ArrayList<String> list) { Class<ArrayList> arrayListClass = ArrayList.class; try { //获取 elementData 字段 Field field = arrayListClass.getDeclaredField("elementData"); //开始访问权限 field.setAccessible(true); //把示例传入get,获取实例字段elementData的值 Object[] objects = (Object[]) field.get(list); //返回当前ArrayList实例的容量值 return objects.length; } catch (Exception e) { e.printStackTrace(); return -1; } } JDK17需要添加VM参数: --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.lang.reflect=ALL-UNNAMED
多个参数添加元素
搞懂上面的扩容机制,再往后看就简单很多了!
根据索引位置插入元素:
public void add(int index, E element) { // 检查所插入的索引是否合规 rangeCheckForAdd(index); modCount++; final int s; Object[] elementData; // 这里是判断容量是否支持这次插入,如果不支持就进行扩容 if ((s = size) == (elementData = this.elementData).length) elementData = grow(); // 容量足够时,进行数组的拷贝 System.arraycopy(elementData, index, elementData, index + 1, s - index); // 数组赋值完之后(将索引以及后面的元素往后复制一个后) 再对索引位置进行数据覆盖。 // 这样就完成了数据按照索引的插入 elementData[index] = element; // 元素插入后 数量加1 size = s + 1; } private void rangeCheckForAdd(int index) { if (index > size || index < 0) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } // 这是一个本地方法,我们不能查看方法体,所以可以看一下官方的解释 /* 将数组从指定的源阵列(从指定位置开始)复制到目标阵列的指定位置。 数组组件的子序列从 {@code src} 引用的源数组复制到 {@code dest} 引用的目标数组。 复制的组件数等于 {@code length} 参数。源数组中位置 {@code srcPos} 到 {@code srcPos+length-1} 的组件分别复制到目标数组的位置 {@code destPos} 到 {@code destPos+length-1} 中。 。。。。。。。。 */ // 个人理解就是将要插入索引后面的元素往后挪一位,将当前元素插入进来 /* 参数说明: src: 要被复制的元素 srcPos: 要开始复制的位置 src: 被赋值的元素 destPos: 复制到的位置 length: 要复制的长度 其实我们可以自己写一个数组的挪位置。回头有时间写写。 */ public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
把另一个集合的元素添加进来
经过前面的分析 这里就很简单了。
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; // 如果添加的集合元素为空,就不添加 返回false if (numNew == 0) return false; Object[] elementData; final int s; // 判断容量够不够,如果(当前容量减去控制大小的size 就是剩余没有用到的数组容量)小于新添加集合元素的数量,就进行扩容。 if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); // 进行数组的拷贝 和上面一致 // 就是把传入的数组全部复制到原来数组后面 System.arraycopy(a, 0, elementData, s, numNew); // 复制完成 元素数量添加 size = s + numNew; return true; }
按照索引进行复制
public boolean addAll(int index, Collection<? extends E> c) { // 对索引的正确性进行检查 rangeCheckForAdd(index); // 将添加的集合的元素转化为数组 Object[] a = c.toArray(); modCount++; int numNew = a.length; // 如果长度为0就不用添加了 直接返回false if (numNew == 0) return false; Object[] elementData; final int s; // 判断当前可用的容量够不够支持插入新的集合里面的元素 if (numNew > (elementData = this.elementData).length - (s = size)) // 不够的话就进行扩容 elementData = grow(s + numNew); // 对要移动元素的位置进行判断 int numMoved = s - index; // 大于0,则代表在当前底层数组中进行插入 if (numMoved > 0) // 进行数组元素的拷贝 ,简单来说就是把原数组挪出来可以容下新元素的位置 System.arraycopy(elementData, index, elementData, index + numNew, numMoved); // 不大于0,代表在当前底层数组后面插入 // 在这里进行新数组的数据覆盖 System.arraycopy(a, 0, elementData, index, numNew); // 集合的大小扩大 size = s + numNew; return true; }
-
删除元素
根据索引删除元素
public E remove(int index) { // 检查元素是否越界 这里很简单就不复制下面的代码了 Objects.checkIndex(index, size); // 拿到当前数组的元素 final Object[] es = elementData; // 获取当前索引对应的元素 @SuppressWarnings("unchecked") E oldValue = (E) es[index]; // 这里是删除的核心代码,详情看下面 fastRemove(es, index); // 返回被删除的元素 return oldValue; } /* 参数说明: param1: 源数组 param2: 要删除的索引位置 */ private void fastRemove(Object[] es, int i) { modCount++; // 删除一个元素后,剩余集合容量的大小 final int newSize; // 如果是大于代表当前元素在底层数组的中间或者前面,否则在末尾 if ((newSize = size - 1) > i) // 数组拷贝 和前面一样 不再分析 System.arraycopy(es, i + 1, es, i, newSize - i); // 这里代表正好要删除的元素在末尾 直接赋值为null就行 等待GC的处理 // 并且给size重新赋值大小 es[size = newSize] = null; }
根据元素删除
// 这里其实也是调用了索引删除 // 通过变量i拿到对应元素索引的位置,然后进行底层数组的覆盖(复制) /* 为什么这里写的那么复杂呢 因为ArrayList支持存储null, 当存储的元素为null的时候,寻找元素会空指针异常,所以分成了为null和不为null两个分流 这里也可以发现 这里的移除只会移除第一个符合的元素 后面的不会移除 */ public boolean remove(Object o) { final Object[] es = elementData; final int size = this.size; int i = 0; found: { if (o == null) { for (; i < size; i++) if (es[i] == null) break found; } else { for (; i < size; i++) if (o.equals(es[i])) break found; } return false; } fastRemove(es, i); return true; } /* 参数说明: param1: 源数组 param2: 要删除的索引位置 */ private void fastRemove(Object[] es, int i) { modCount++; // 删除一个元素后,剩余集合容量的大小 final int newSize; // 如果是大于代表当前元素在底层数组的中间或者前面,否则在末尾 if ((newSize = size - 1) > i) // 数组拷贝 和前面一样 不再分析 System.arraycopy(es, i + 1, es, i, newSize - i); // 这里代表正好要删除的元素在末尾 直接赋值为null就行 等待GC的处理 // 并且给size重新赋值大小 es[size = newSize] = null; }
按照条件删除
// 说实话 并看不懂这个。。特别牵扯到位运算。。。。想不清楚为什么这么做。 @Override public boolean removeIf(Predicate<? super E> filter) { return removeIf(filter, 0, size); } /** * Removes all elements satisfying the given predicate, from index * i (inclusive) to index end (exclusive). */ boolean removeIf(Predicate<? super E> filter, int i, final int end) { Objects.requireNonNull(filter); int expectedModCount = modCount; final Object[] es = elementData; // Optimize for initial run of survivors for (; i < end && !filter.test(elementAt(es, i)); i++) ; // Tolerate predicates that reentrantly access the collection for // read (but writers still get CME), so traverse once to find // elements to delete, a second pass to physically expunge. if (i < end) { final int beg = i; final long[] deathRow = nBits(end - beg); deathRow[0] = 1L; // set bit 0 for (i = beg + 1; i < end; i++) if (filter.test(elementAt(es, i))) setBit(deathRow, i - beg); if (modCount != expectedModCount) throw new ConcurrentModificationException(); modCount++; int w = beg; for (i = beg; i < end; i++) if (isClear(deathRow, i - beg)) es[w++] = es[i]; shiftTailOverGap(es, w, end); return true; } else { if (modCount != expectedModCount) throw new ConcurrentModificationException(); return false; } }
-
修改
设计lambda表达式额真的不太好想,能力上还是差了太多。
根据索引下标进行修改:
public E set(int index, E element) { // 检查数组是否越界 Objects.checkIndex(index, size); // 获取当前索引的元素 E oldValue = elementData(index); // 将当前索引的值进行覆盖 elementData[index] = element; return oldValue; } E elementData(int index) { return (E) elementData[index]; }
-
查询元素
// 这个很简单就不分析了 public E get(int index) { Objects.checkIndex(index, size); return elementData(index); } -
遍历元素
// 使用增强for进行遍历的时候,会自动创建一个迭代器 public Iterator<E> iterator() { return new Itr(); }
简单做一个的个人的图片展示网页
文件列表:

成品效果:
(该图片来源于网略,若有侵权联系删除,抱歉抱歉~)

成品代码:
可以直接拿去做单页,但是没有数据。
数据都存储在data.json里面,可以自己修改下面的json数据地址。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<!-- import CSS -->
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
<style type="text/css">
* {
margin: 0;
padding: 0;
}
body{
/* height: 100vh; */
}
</style>
</head>
<body>
<div id="app" style="overflow: hidden;">
<el-carousel indicator-position="none" height="95vh" indicator-position="outside">
<el-carousel-item v-for="url in urls" :key="url">
<el-image
style="width: 100%; height: 100vh"
:src="url"
:fit="fit"></el-image>
</el-carousel-item>
</el-carousel>
</div>
</body>
<!-- import Vue before Element -->
<script src="https://unpkg.com/vue@2/dist/vue.js"></script>
<!-- import JavaScript -->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<script>
new Vue({
el: '#app',
data: function() {
return {
fit: 'contain',
urls: [
'./01c3d7fd5c5cefbcfe6bf6e256fcb611(2).jpeg',
'https://fuss10.elemecdn.com/a/3f/3302e58f9a181d2509f3dc0fa68b0jpeg.jpeg',
'https://fuss10.elemecdn.com/1/34/19aa98b1fcb2781c4fba33d850549jpeg.jpeg',
'https://fuss10.elemecdn.com/0/6f/e35ff375812e6b0020b6b4e8f9583jpeg.jpeg',
'https://fuss10.elemecdn.com/9/bb/e27858e973f5d7d3904835f46abbdjpeg.jpeg',
'https://fuss10.elemecdn.com/d/e6/c4d93a3805b3ce3f323f7974e6f78jpeg.jpeg',
'https://fuss10.elemecdn.com/3/28/bbf893f792f03a54408b3b7a7ebf0jpeg.jpeg',
'https://fuss10.elemecdn.com/2/11/6535bcfb26e4c79b48ddde44f4b6fjpeg.jpeg'
]
}
},
created() {
// 可以自己修改这里 json数据里是一个包含图片地址的数组
axios.get('./data.json').then(resp=>{
console.log(resp.data.urls);
this.urls = resp.data.urls;
})
}
})
</script>
</html>
思路:
收集了一些网络照片,为了更好的管理和存储以及展示,所以打算做成网页,想看的时候点开就能直接看,感觉方便一些。于是便有了这个简单的小Demo。
核心: 将文件夹下的图片信息组合成json文件存储起来,然后通过异步请求获取到。
下面是自己遇到的问题以及写的一些小工具:
文件名称的修改:
// 从网上下载的文件,名字乱七八糟 甚至有乱码的,所以可以自己手动修改一下
// 文件随机名修改
private static void changeName(File file) {
// 判断文件时目录还是文件
// 目录就采用递归进行遍历
if (file.isDirectory()){
File[] files = file.listFiles();
for (File f : files) {
changeName(f);
}
}else {
// 如果是文件就可以进行修改
// 这里对文件进行名称的修改
try {
BufferedInputStream inputStream = new BufferedInputStream(new FileInputStream(file));
String name = UUID.randomUUID().toString().substring(0, 15);
String type = file.getName().substring(file.getName().lastIndexOf(".") );
// 将之前的文件复制改完名字之后继续存储到当前文件夹下面
inputStream.transferTo(new FileOutputStream(file.getParent() + File.separator + name + type));
inputStream.close();
} catch (IOException e) {
System.out.println(file.getName() + "改名失败");
throw new RuntimeException(e);
}
/*
修改为完毕,删除当前的文件
注意:
流未关闭之前,删除会失败!
*/
if (file.delete()) {
System.out.println("删除成功");
}
}
}
json文件生成:
// 之前打算自己拼接一个json字符串,但是后来感觉还是用fastjson好一些
// private static StringBuilder builder = new StringBuilder();
private static ArrayList<String> list = new ArrayList<>();
private static Map<String,ArrayList> map = new HashMap<>();
public static void main(String[] args) throws IOException {
// 获取文件名称截图字符串 最后存储到json文件中
File file = new File("F:\\12\\首页\\二次元头像");
System.out.println("file.getPath() = " + file.getPath());
getJsonData(file);
map.put("urls",list);
String json = JSON.toJSONString(map);
System.out.println("json = " + json);
BufferedWriter writer = new BufferedWriter(new FileWriter(new File(file.getPath(),"data.json")));
writer.write(json);
writer.close();
}
private static void getJsonData(File file) {
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File f : files) {
getJsonData(f);
}
}else if (file.isFile()
&& !file.getName().contains("html")
&& !file.getName().contains("json")
&& !file.getName().contains("rar")
){
String name = file.getName();
list.add("./" + name);
}
}
压缩图片质量:
// 我这里并没用上 如果在一些不太好的服务器上,或许会使用这个
private static void shutPictureWith(File file) {
// 判断文件类型
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File f : files) {
shutPictureWith(f);
}
} else {
// 绘制缩略图
desPhoto(file);
}
}
private static void desPhoto(File file) {
try {
// 创建文件对象 获取文件宽高
BufferedImage read = ImageIO.read(file);
int height = read.getHeight();
int width = read.getWidth();
// 对宽高进行缩小0.5倍
height = height - (int) (0.5 * height);
width = width - (int) (0.5 * width);
// 创建等同大小的文件进行覆盖
BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_BGR);
// 获取刷子
Graphics2D graphics = image.createGraphics();
// 绘制图片
graphics.drawImage(read, 0, 0, width, height, null);
// 释放画笔
graphics.dispose();
// 生成图片
String type = file.getName().substring(file.getName().lastIndexOf(".") + 1);
// System.out.println("type = " + type);
ImageIO.write(image, type, new File("F:\\JavaRepo\\CrossFireAndLive\\zimgs", file.getName()));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
前端代码的准备:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<!-- import CSS -->
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
<style type="text/css">
* {
margin: 0;
padding: 0;
}
body{
/* height: 100vh; */
}
</style>
</head>
<body>
<div id="app" style="overflow: hidden;">
<el-carousel indicator-position="none" height="95vh" indicator-position="outside">
<el-carousel-item v-for="url in urls" :key="url">
<el-image
style="width: 100%; height: 100vh"
:src="url"
:fit="fit"></el-image>
</el-carousel-item>
</el-carousel>
</div>
</body>
<!-- import Vue before Element -->
<script src="https://unpkg.com/vue@2/dist/vue.js"></script>
<!-- import JavaScript -->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<script>
new Vue({
el: '#app',
data: function() {
return {
fit: 'contain', //让图片按照原来的比例展示
urls: [
'./01c3d7fd5c5cefbcfe6bf6e256fcb611(2).jpeg',
]
}
},
created() {
axios.get('./data.json').then(resp=>{
console.log(resp.data.urls);
this.urls = resp.data.urls;
})
}
})
</script>
</html>
下载live-server:
npm install -g live-server
直接在需要展示的文件夹下面使用cmd执行就行。
水印添加

二分查找算法以及面试真题
在一组排好序的数组中,找到所求值的索引。
二分查询思想如下:
取左left、右边界right,以及左右边界的中间值index
如果所求的值小于索引index对应的值:
将右边界right赋值为index-1,因为此时index所对应的值是大于所求值num,所以可以直接排除index.
赋值之前:

赋值之后:

如果所求索引的值大于索引值index对应的值:
将左边界left赋值为index+1`,因为此时index所对应的值是小于所求值num,所以可以直接排除index.
赋值之前:

赋值之后:
理论同上,不再画图,可以看下面二分查找的动画:

如果index对应的值和num的值相等:
所求值对应的索引就是index.
因为在Java语言中。整数之间的乘除加减最后返回值都是整数,所以在求中间索引时不用担心小数问题。
代码如下:
private static int binarySearch(int[] nums, int target) {
// 声明左右边界,以及中间索引
int left = 0, right = nums.length - 1, index;
while (left <= right) {
// 计算中间索引位置
// index = (left + right) / 2;
// 避免数值超过int最大值
// index = left + (right - left) / 2;
index = (left + right) >>> 1;
// 如果相等 代表找到了元素索引
if (nums[index] == target) {
return index;
}
// 如果当前中间值大于要查找的元素 ,让右边界等于索引-1(毕竟索引那里不相等 可以忽略掉)
if (nums[index] > target) {
right = index - 1;
}
// 如果中间值小于要查找的元素,让左边界等于索引+1
if (nums[index] < target) {
left = index + 1;
}
}
return -1;
}
面试题口诀:
1.奇数二分取中间。
2.偶数二分取中间左边。
面试题:
-
有一个有序表为1,5,8,11,19,22,31,35,40,45,48,49,50 。当二分查找值为48的节点时,查找成功需要比较的次数是?

-
在拥有512个元素的数组中二分查找一个数,需要比较的次数最多不超过多少次。
解题方法1:
用512/2/2/2....直到最终等于1,中间除了几次2就是几次。
解题方法2:
2^n = 512 ,求解n的值即可。
解体方法3:
如果结果为整数,即为最终答案。
如果是小鼠,则舍弃小数部分,整数再加1,为最终结果。
Maven切换编译语言版本
我总感觉在pom.xml里面的properties标签里的版本信息以及部署编译插件和settings.xml文件里面的有些冲突。为什么settings.xml里profiles配置了一个或者多个jdk,为什么在pom.xml还需要写那些参数以及编译插件呢。
测试删除pom.xml里的properties标签和build标签,只通过idea里的maven工具切换profile

刷新maven,查看语言级别

再次修改profile,查看语言级别


所以当通过idea切换settings里配置的profile时,不用配置什么参数,以及编译插件,直接通过idea的可视化参数配置即可。
其实,还有些疑惑,如果pom.xml以及settings.xml都配置,最后遵循哪一个?
下面用编译语言jdk11做演示:
不选择profiles

查看语言级别:
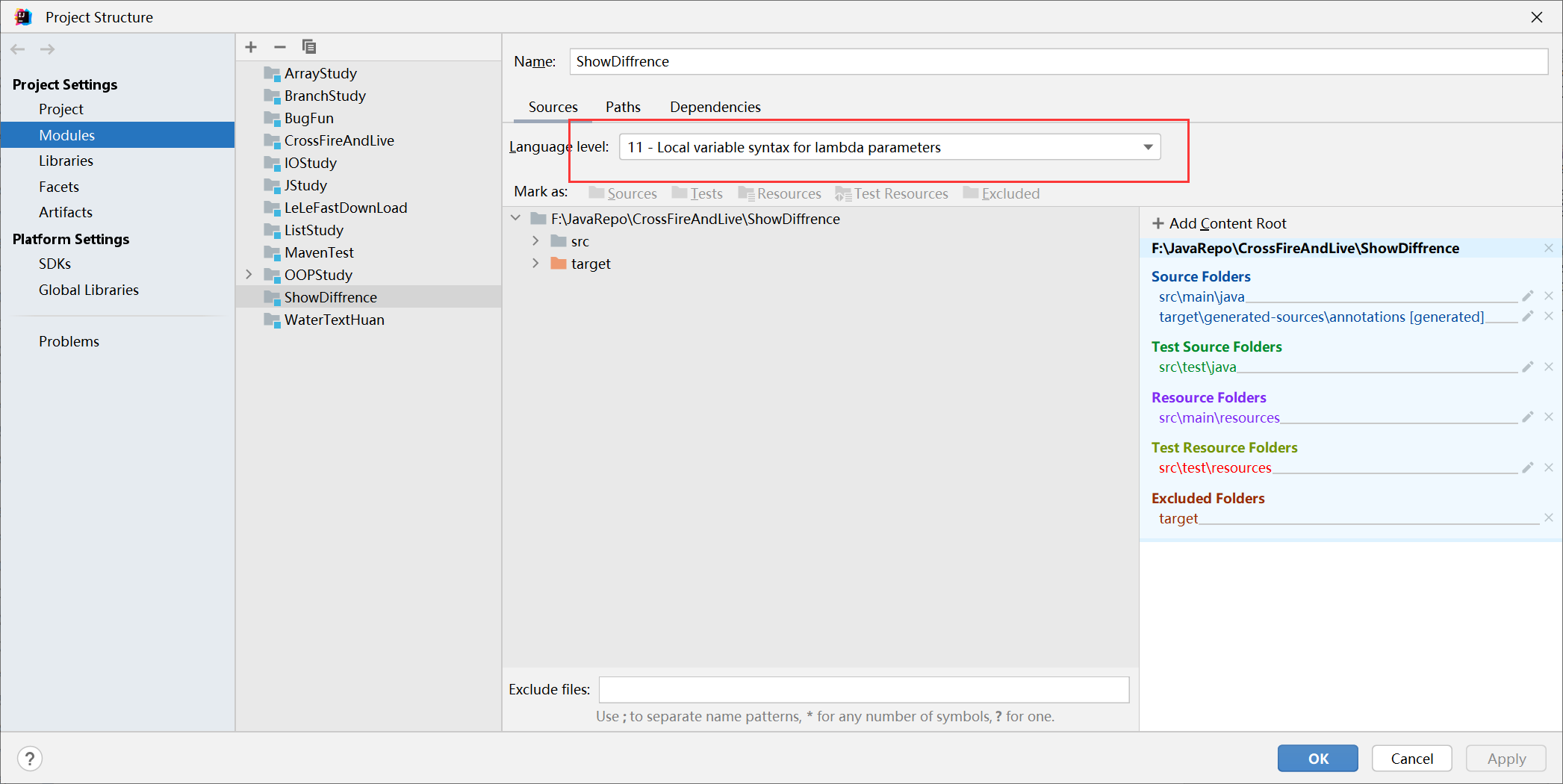
测试选择profile jdk17

查看语言级别:
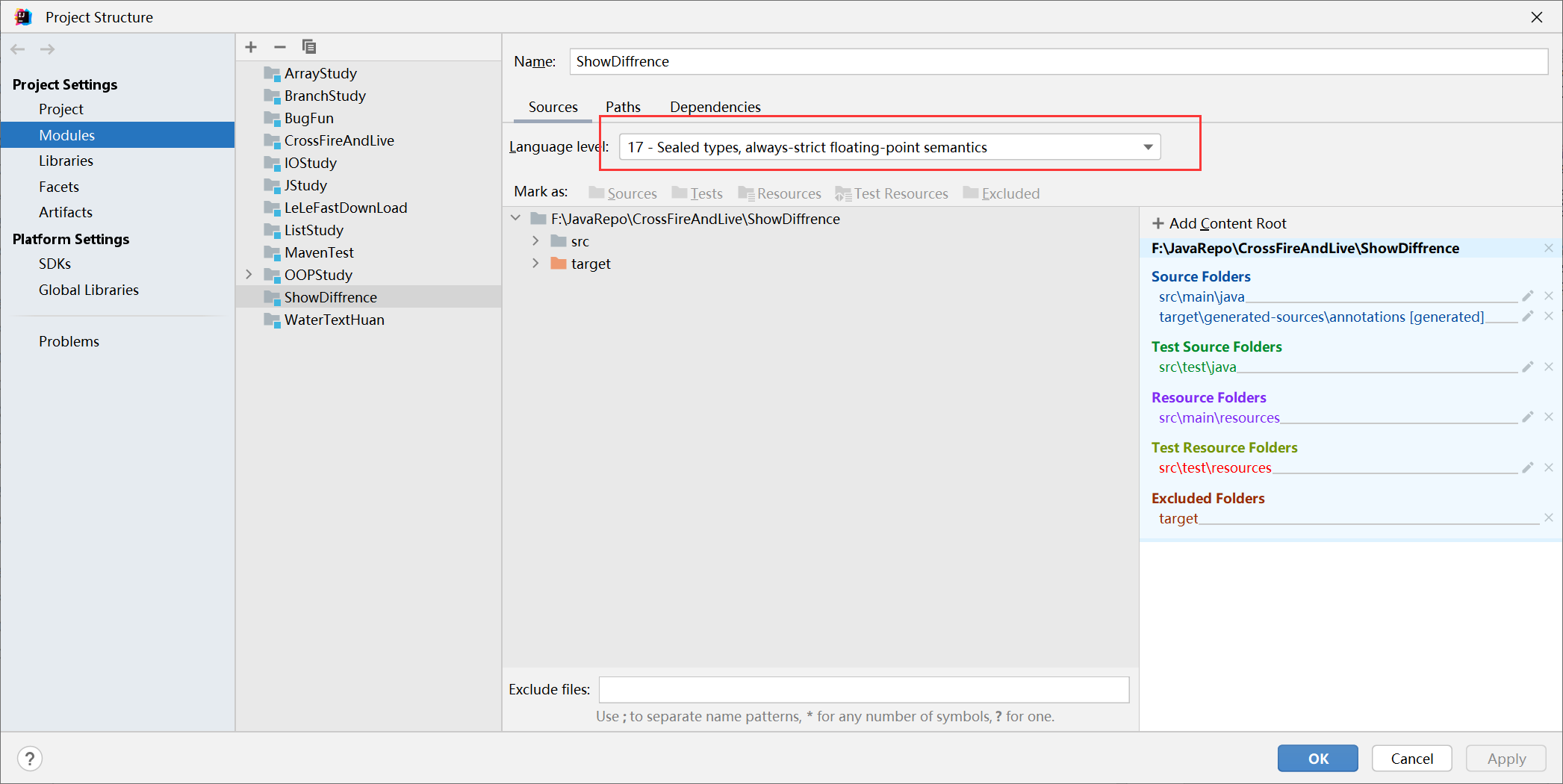
不难发现,profile的优先级还是比maven配置插件高一些的,所以当maven选择profiles后,可以不用再去配置编译插件。
如果我把settings里配置的profile都删除了,最后会按照哪个呢?
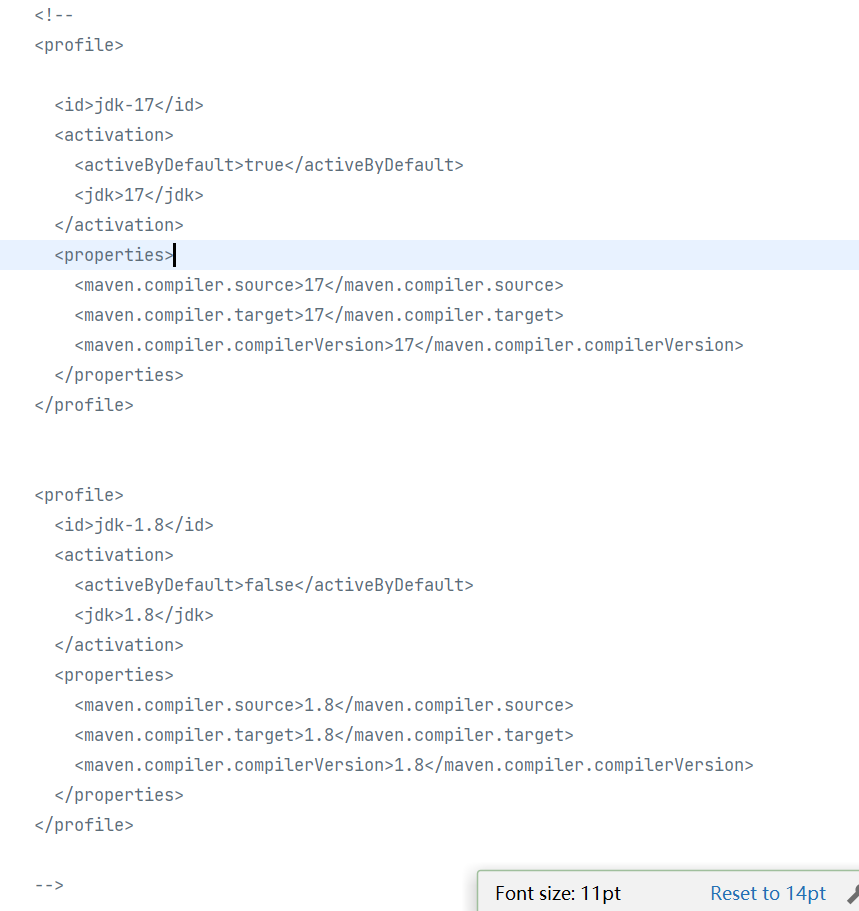
再回到程序,刷新maven,继续查看当前配置jdk11插件的语言级别
此时idea里不再显示peofiles:

查看语言级别:

如果此时删除配置的编译插件,语言级别会改变吗?

查看语言级别:

果然jdk语言级别变成了默认jdk1.5。
恢复settings里的profile

不选择profile

总结:
优先级从大到小排序:
settings.xml里profile配置 > pom.xml配置 > maven默认配置
maven打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.lele.fun.LeToolsApplication</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Thread

利用多线程实现文件的分片下载
因为之前并未真正意义上使用线程池,现在正好用这个案例练习一下。
工作原理:
-
通过URL实例对象获取HttpUrlConnection
// 地址信息 URL ur = new URL(url); // 获取连接信息 HttpURLConnection httpURLConnection = (HttpURLConnection) ur.openConnection(); -
在主线程获取要下载文件的字节大小,然后平分给每个子线程,让他们去分片下载。
// 获取文件长度 long contentLengthLong = httpURLConnection.getContentLengthLong();在子线程里通过RandomAccessFile进行字节的设置
// 设置请求分段下载 httpURLConnection.setRequestProperty("Range", "bytes=" + start + "-" + end); // 设置文件片段 这里的rw 是可读可写的意思 RandomAccessFile accessFile = new RandomAccessFile(new File(filePath,filename), "rw"); // 文件的总大小 accessFile.setLength(contentLength); // 字节开始填充的地方
accessFile.seek(start);
子线程获取流对象,进行获取相对应的分片数据
```java
// 通过HttpUrlConnection获取流对象
InputStream inputStream = httpURLConnection.getInputStream();
// 读取暂存空间
byte[] bytes = new byte[8092];
// 判断是否读取完成的额条件
int size;
while (-1 != (size = inputStream.read(bytes))) {
accessFile.write(bytes, 0, size);
}
这样就完成了分片的数据下载。
-
为了方便线程的管理和创建,所以采用了线程池的方法。
// 为了省事 写了一个静态的方法来获取线程池对象(也不知道合不合规矩) public static Executor getThreadPool() { //先写死 后面再调整 Executor executor = new ThreadPoolExecutor( 4, 8, 5000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(5), new ThreadPoolExecutor.AbortPolicy() ); return executor; }这样在子线程调用的时候,就可以通过线程池进行调用
// 获取线程池 Executor threadPool = ThreadPoolConfig.getThreadPool(); // 通过线程池下载文件 System.out.printf("文件%s 字节数:%d 开始下载。。。。 %n", url.substring(url.lastIndexOf("/") + 1), contentLengthLong); for (int i = 0; i < 4; i++) { long start = i * contentLengthLong / 4; long end = (i + 1) * contentLengthLong / 4 - 1; if (i == 3) { end = contentLengthLong; } // 这里使用线程池的execute方法 执行线程任务 threadPool.execute(new DownLoadThread(url, contentLengthLong, savePath, start, end)); }为什么这里要创建子线程呢?因为每个子线程要下载的任务的字节数据不一样,所以需要我们去指定不同的参数。
/** * <p>Project: CrossFireAndLive - DownLoadThread * <p>Powered by wuyahan On 2023-01-05 15:15:47 * * @author wuyahan [tianwenle2000@163.com] * @version 1.0 * @since 17 */ @Data @AllArgsConstructor @NoArgsConstructor public class DownLoadThread implements Runnable { // 文件下载路径 private String url; // 文件总长度 private Long contentLength; // 文件保存路径 private String filePath; // 开始下载的片段 private Long start; // 结束的片段 private Long end; @Override public void run() { try { // 获取文件名称 String filename = url.substring(url.lastIndexOf("/") + 1); // 获取文件地址 URL url = new URL(this.url); // 获取文件链接对象 HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection(); httpURLConnection.setReadTimeout(5000); httpURLConnection.setRequestMethod("GET"); // 设置请求分段下载 httpURLConnection.setRequestProperty("Range", "bytes=" + start + "-" + end); // 设置文件片段 // 这里让线程指向同一个文件地址,这样每个线程字节填充完毕就会合成一个文件 RandomAccessFile accessFile = new RandomAccessFile(new File(filePath,filename), "rw"); // 设置文件的总大小 accessFile.setLength(contentLength); // 让文件台跳转到对应字节位置 accessFile.seek(start); // 获取传输输数据的流对象 InputStream inputStream = httpURLConnection.getInputStream(); // 读取暂存空间 byte[] bytes = new byte[8092]; // 判断是否读取完成的额条件 int size; while (-1 != (size = inputStream.read(bytes))) { accessFile.write(bytes, 0, size); } System.out.printf("线程名称:%s | 文件%s , 字节数%d - %d下载完毕%n",Thread.currentThread().getName(),filename,start,end); accessFile.close(); inputStream.close(); httpURLConnection.disconnect(); } catch (MalformedURLException e) { throw new RuntimeException(e); } catch (IOException e) { throw new RuntimeException(e); } } }下载效果:

下载大文件速度还是很快的,就是多线程测速还真是有一些麻烦。
IntelliJ IDEA使用lombok的@Slf4j后无法使用log问题解决
查阅了一些资料。可能与lombok的版本又相关的问题。
<dependency>
<groupId>org.apache.cassandra</groupId>
<artifactId>cassandra-all</artifactId>
<version>3.0.26</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
1. 常用的java虚拟机参数
GC参数
-
-XX:+PrintGC在JDK17已经过时了 打印GC信息
展示效果:
[0.017s][warning][gc] -XX:+PrintGC is deprecated. Will use -Xlog:gc instead. [0.041s][info ][gc] Using G1 [0.315s][info ][gc] GC(0) Pause Full (System.gc()) 5M->2M(14M) 4.833ms -
-Xlog:gc打印GC信息
展示效果:
[0.011s][info][gc] Using G1 [0.165s][info][gc] GC(0) Pause Full (System.gc()) 5M->2M(14M) 3.531s -
-XX:+PrintGCDetails打印详细的GC信息 【JDK17使用 -Xlog:gc* 效果一样】展示效果:
[0.004s][warning][gc] -XX:+PrintGCDetails is deprecated. Will use -Xlog:gc* instead. [0.014s][info ][gc] Using G1 [0.016s][info ][gc,init] Version: 17.0.5+9-LTS-191 (release) [0.016s][info ][gc,init] CPUs: 8 total, 8 available [0.016s][info ][gc,init] Memory: 8037M [0.016s][info ][gc,init] Large Page Support: Disabled [0.016s][info ][gc,init] NUMA Support: Disabled [0.016s][info ][gc,init] Compressed Oops: Enabled (32-bit) [0.016s][info ][gc,init] Heap Region Size: 1M [0.016s][info ][gc,init] Heap Min Capacity: 8M [0.016s][info ][gc,init] Heap Initial Capacity: 126M [0.016s][info ][gc,init] Heap Max Capacity: 2010M [0.016s][info ][gc,init] Pre-touch: Disabled [0.016s][info ][gc,init] Parallel Workers: 8 [0.016s][info ][gc,init] Concurrent Workers: 2 [0.016s][info ][gc,init] Concurrent Refinement Workers: 8 [0.016s][info ][gc,init] Periodic GC: Disabled [0.017s][info ][gc,metaspace] CDS archive(s) mapped at: [0x0000000800000000-0x0000000800bd0000-0x0000000800bd0000), size 12386304, SharedBaseAddress: 0x0000000800000000, ArchiveRelocationMode: 0. [0.017s][info ][gc,metaspace] Compressed class space mapped at: 0x0000000800c00000-0x0000000840c00000, reserved size: 1073741824 [0.017s][info ][gc,metaspace] Narrow klass base: 0x0000000800000000, Narrow klass shift: 0, Narrow klass range: 0x100000000 [0.160s][info ][gc,task ] GC(0) Using 3 workers of 8 for full compaction [0.160s][info ][gc,start ] GC(0) Pause Full (System.gc()) [0.160s][info ][gc,phases,start] GC(0) Phase 1: Mark live objects [0.161s][info ][gc,phases ] GC(0) Phase 1: Mark live objects 1.343ms [0.161s][info ][gc,phases,start] GC(0) Phase 2: Prepare for compaction [0.162s][info ][gc,phases ] GC(0) Phase 2: Prepare for compaction 0.297ms [0.162s][info ][gc,phases,start] GC(0) Phase 3: Adjust pointers [0.163s][info ][gc,phases ] GC(0) Phase 3: Adjust pointers 0.794ms [0.163s][info ][gc,phases,start] GC(0) Phase 4: Compact heap [0.163s][info ][gc,phases ] GC(0) Phase 4: Compact heap 0.744ms [0.164s][info ][gc,heap ] GC(0) Eden regions: 6->0(3) [0.164s][info ][gc,heap ] GC(0) Survivor regions: 0->0(0) [0.164s][info ][gc,heap ] GC(0) Old regions: 0->4 [0.164s][info ][gc,heap ] GC(0) Archive regions: 0->0 [0.164s][info ][gc,heap ] GC(0) Humongous regions: 0->0 [0.164s][info ][gc,metaspace ] GC(0) Metaspace: 518K(704K)->518K(704K) NonClass: 487K(576K)->487K(576K) Class: 30K(128K)->30K(128K) [0.164s][info ][gc ] GC(0) Pause Full (System.gc()) 5M->2M(14M) 4.341ms [0.164s][info ][gc,cpu ] GC(0) User=0.00s Sys=0.00s Real=0.01s [0.166s][info ][gc,heap,exit ] Heap [0.166s][info ][gc,heap,exit ] garbage-first heap total 14336K, used 2894K [0x0000000082600000, 0x0000000100000000) [0.166s][info ][gc,heap,exit ] region size 1024K, 1 young (1024K), 0 survivors (0K) [0.166s][info ][gc,heap,exit ] Metaspace used 538K, committed 704K, reserved 1056768K [0.166s][info ][gc,heap,exit ] class space used 33K, committed 128K, reserved 1048576KJDK8运行结果:

感觉还是jdk8运行结果清晰明了,下面一律采用jdk8来运行
通过打印GC的信息可以明显的看出来堆中内存的分配:

这里不细总结,后面总结jvm的时候再说。
e


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现