
HTTP报文
报文结构
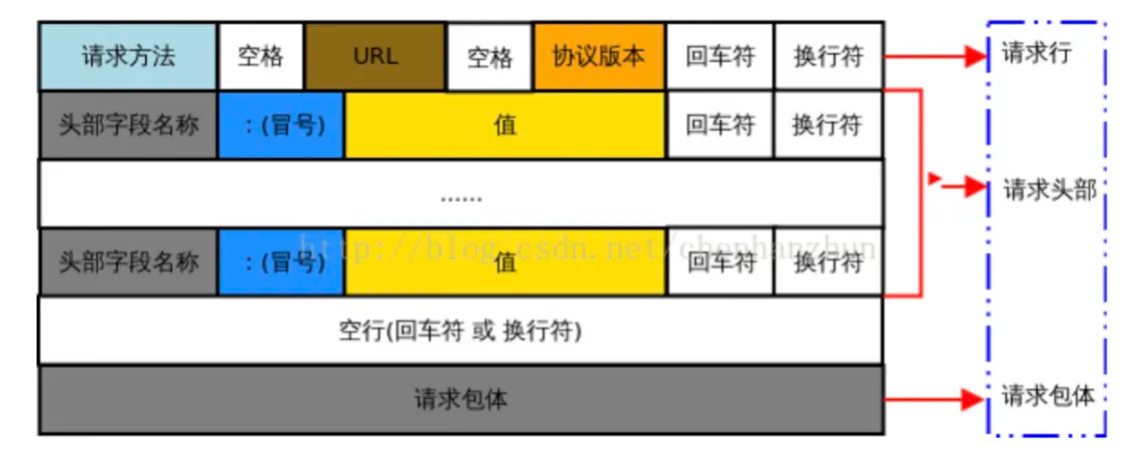
请求报文
-
请求行
用来说明请求类型,要访问的资源以及所使用的HTTP版本。 -
请求头部
紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息- HOST:给出请求资源所在服务器的域名
- User-Agent:HTTP客户端程序的信息,该信息由你发出请求使用的浏览器来定义,并且在每个请求中自动发送
- Accept:说明用户代理可处理的媒体类型。
- Accept-Encoding:说明用户代理支持的内容编码。
- Accept-Language:说明用户代理能够处理的自然语言集
- Content-Type:说明请求数据的媒体类型
- Content-Length:说明请求数据的大小,GET为0,POST为非0
- Connection:连接管理,可以是 Keep-Alive 或 close
-
空行
-
请求数据
也叫主体,可以添加任意的其他数据
以下给出一个请求报文的例子:
// 请求行
POST /user HTTP/1.1
// 请求头
Host: www.user.com
Content-Type: application/x-www-form-urlencoded
Connection: Keep-Alive
User-agent: Mozilla/5.0.
// 空行分割header和请求内容
(此处必须有一空行
// 请求体(可选)
name=world
在传来的HTTP请求报文中,每一行的数据由 \r\n 作为结束字符,空行则是仅仅是字符 \r\n 。因此,可以通过查找 \r\n 将报文拆解成单独的行进行解析
响应报文
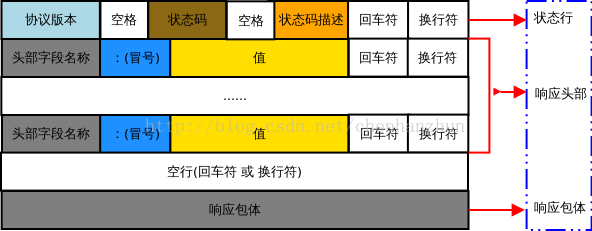
- 常见状态代码、状态描述
200 OK:客户端请求成功
400 BadRequest:客户端请求有语法错误,不能被服务器所理解
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden:服务器收到请求,但是拒绝提供服务
404 Not Found:请求资源不存在,举个例子:输入了错误的URL
500 Internal Server Error:服务器发生不可预期的错误
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常
以下给出一个响应报文的例子:
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
<html>
<head>
<title>Wrox Homepage</title>
</head>
<body>
<!-- body goes here -->
</body>
</html>
解析http请求报文
此处只给出解析请求行的例子,解析请求头以及请求体方法与此类似
前置知识
char *strpbrk(const char *str1, const char *str2)
字符串 str1 中第一个匹配字符串 str2 中字符的字符,不包含空结束字符。也就是说,依次检验字符串 str1 中的字符,当被检验字符在字符串 str2 中也包含时,则停止检验,并返回该字符位置。未找到则返回 NULLsize_t strspn(const char *str1, const char *str2)
该函数返回 str1 中第一个不在字符串 str2 中出现的字符下标。
比如在下例中 len = 4
const char str1[] = "ABCDEFG019874"; const char str2[] = "ABCD"; len = strspn(str1, str2);
解析请求行
//BAD_REQUEST 语法错误 //NO_REQUEST 请求不完整 int parse_request_line(char *text) { m_url = strpbrk(text, " \t"); //找到 第一处空格 或者 \t if (!m_url) { return BAD_REQUEST; } //用\0空字符来划分每一行具体信息 //方便后续操作 因为字符串函数都以空字符作为划分 *m_url++ = '\0'; char *method = text; if (strcasecmp(method, "GET") == 0) m_method = GET; else if (strcasecmp(method, "POST") == 0) m_method = POST; else return BAD_REQUEST; m_url += strspn(m_url, " \t"); //跳过剩余的 空格和\t 因为可能不止用一个空格和\t来分隔 m_version = strpbrk(m_url, " \t"); if (!m_version) return BAD_REQUEST; *m_version++ = '\0'; m_version += strspn(m_version, " \t"); //到此为止 m_url、m_version都指向对应位置的开头 //仅支持HTTP//1.1 if (strcasecmp(m_version, "HTTP/1.1") != 0) return BAD_REQUEST; //对请求资源前7个字符进行判断 //这里主要是有些报文的请求资源中会带有http://,这里需要对这种情况进行单独处理 if (strncasecmp(m_url, "http://", 7) == 0) { m_url += 7; m_url = strchr(m_url, '/'); } //同样增加https情况 if (strncasecmp(m_url, "https://", 8) == 0) { m_url += 8; m_url = strchr(m_url, '/'); } //一般的不会带有上述两种符号,直接是单独的/或/后面带访问资源 if (!m_url || m_url[0] != '/') return BAD_REQUEST; //当url为/时,显示判断界面 if (strlen(m_url) == 1) strcat(m_url, "judge.html"); return NO_REQUEST; }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步