
Redis实现之整数集合
整数集合
整数集合(insert)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。举个栗子,如果我们创建一个只包含五个元素的集合键,并且集合中的所有元素都是整数值,那么这个集合键的底层实现就会是整数集合:
127.0.0.1:6379> SADD numbers 1 3 5 7 9 (integer) 5 127.0.0.1:6379> SMEMBERS numbers 1) "1" 2) "3" 3) "5" 4) "7" 5) "9" 127.0.0.1:6379> OBJECT ENCODING numbers "intset"
整数集合的实现
整数集合(insert)是Redis用于保存整数值的集合抽象数据结构,它可以保存类型为int16_t、int32_t或者int64_t的整数值,并且保证集合中不会出现重复元素。
intset.h
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
contents数组是整数集合的底层实现:整数集合的每个元素都是contents数组中的一个数组项,各个项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。length属性记录了整数集合包含的元素数量,也即是contents数组的长度。虽然intset结构将contents属性声明为int8_t类型的数组,但实际上contents数组并不保存任何int8_t类型的值,contents数组的真正类型取决于encoding属性的值:
- 如果encoding属性的值为为INTSET_ENC_INT16,那么contents就是一个int16_t类型的数组了,数组里的每个项都是一个int16_t类型的整数值(最小值为-32 768,最大值为32 767)
- 如果encoding属性的值为INTSET_ENC_INT32,那么contents就是一个int32_t类型的数组了,数组里的每个项都是一个int32_t类型的整数值(最小值为-2 147 483 648,最大值为2 147 483 647)
- 如果encoding属性的值为INTSET_ENC_INT64,那么contents就是一个int64_t类型的数组了,数组里的每个项都是一个int64_t类型的整数值(最小值为-9 223 372 036 854 775 808,最大值为9 223 372 036 854 775 807)。
图1-1展示了一个整数集合示例:
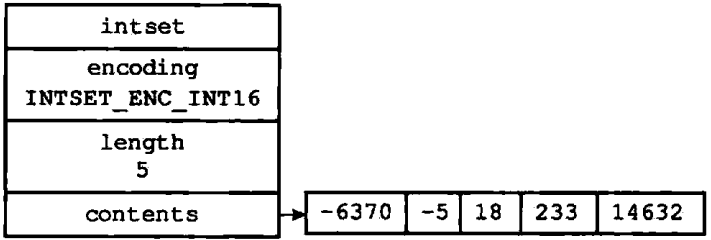
图1-1 一个包含五个int6_t类型整数值的整数集合
- 如果encoding属性的值为为INTSET_ENC_INT16,表示整数集合的底层实现为int16_t类型的数组,而集合保存的都是int16_t类型的整数值
- length属性为5,表示整数集合包含5个元素
- contents数组按从小到大的顺序保存着集合中的五个元素
- 因为每个集合元素都是int16_t类型的整数值,所以contents数组的大小等于sizeof(int16_t)*5=16*5=80位
图1-2展示了另一个整数集合示例:
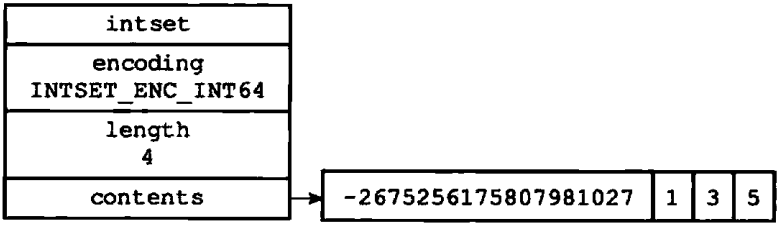
图1-2 一个包含四个int16_t类型整数值的整数集合
- encoding属性的值为INTSET_ENC_INT64,表示整数集合的底层实现为int64_t类型的数组,而数组中保存的都是int64_t类型的整数值
- length属性的值为4,表示整数集合包含四个元素
- contents数组按从小到大的顺序保存着集合中的四个元素
- 因为每个集合元素都是int64_t类型的整数值,所以contents数组的大小为sizeof(int64_t)*4=64*4=256位
虽然contents数组保存的四个整数值中,只有-2 675 256 175 807 981 027是真正需要用int64_t类型来保存的,而其他的1、3、5三个值都可以用int16_t类型来保存,不过根据整数集合的升级规则,当向一个底层为int16_t数组的整数集合添加一个int64_t类型的整数值时,整数集合已有的所有元素都会被转换成int64_t类型,所以contents数组保存的四个整数值都是int64_t类型的,不仅仅是 -2 675 256 175 807 981 027
升级
每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有所有元素的类型要长时,整数集合需要先进行升级(upgrade),然后才能将新元素添加到整数集合里面。升级整数集合并添加新元素共分为三步进行:
- 根据新元素的类型,扩展整数集合底层数组对的空间大小,并为新元素分配空间
- 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放到正确的位置上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变
- 将新元素添加到底层数组里面
举个栗子,假设现在有一个INTSET_ENC_INT16编码的整数集合,集合中包含三个int16_t类型的元素,如图1-3所示
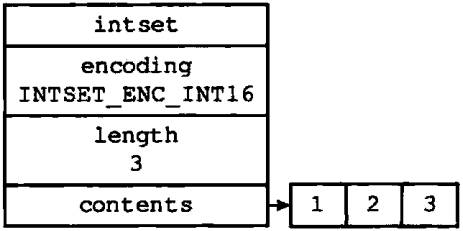
图1-3 一个包含三个int16_t类型的元素的整数集合
因为每个元素都占用16位空间,所以整数集合底层数组的大小为3*16=48位,图1-4展示了整数集合的三个元素在这48位里的位置
现在,假设我们要将类型为int32_t的整数值65 535添加到整数集合里面,因为65 535的类型int32_t比整数集合当前所有元素要长,所以在将65 535添加到整数集合之前,程序需要先对整数集合进行升级。升级首先要做的是,根据新类型的长度,以及集合元素的数量(包括要添加的新元素在内),对底层数组进行空间重分配
整数集合目前有三个元素,再加上新元素65 535,整数集合需要分配四个元素的空间,因为每个int32_t整数值需要占用32位空间,所以在空间重分配之后,底层数组的大小将是32*4=128位,如图1-5所示。虽然程序对底层数组进行了空间重分配,但数组原有的三个元素1、2、3仍然是int16_t类型,这些元素还保存在数组的前48位里面,所以程序接下来要做的就是将这三个元素转换成int32_t类型,并将转换后的元素放置到正确的位上面,而且在放置元素的过程中,需要维持底层数组的有序性质不变

图1-5 进行空间重分配之后的数组
首先,因为元素3在1、2、3、65535四个元素中排名第三,所以它将被移动到contents数组的索引2位置上,也即是数组64位至95位的空间内,如图1-6所示

图1-6 对元素3进行类型转换,并保存在适当的位置上
接着,因为元素2在1、2、3、65535四个元素中排名第二,所以它将被移动到contents元素的索引1的位置上,也即是数组的32位至63位的空间内,如图1-7

图1-7 对元素2进行类型转换,并保存在适当的位上
之后,因为元素1在1、2、3、65536四个元素中排名第一,所以它将被移动到contents数组的索引0位置上,即数组的0位至31位空间内,如图1-8所示

图1-8 对元素1进行类型转换,并保存在适当的位置上
然后,因为元素65535在1、2、3、65535四个元素中排名第四,所以它将被添加到contents数组的索引3位置上,也即时数组的96位至127位的空间内,如图1-9所示

如图1-9 添加65535到数组
最后,程序将整数集合encoding属性的值从INTSET_ENC_INT16改为INTSET_ENC_INT32,并将length属性的值从3改为4,设置完成之后的整数集合如图1-10所示
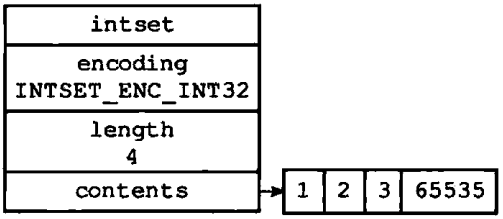
图1-10 完成添加操作之后的整数集合
因为每次向整数集合添加新元素都可能会引起升级,而每次升级都需要对底层数组中已有的元素进行类型转换,所以向整数集合添加新元素的时间复杂度为O(N)。其他类型的升级操作,比如从INTSET_ENC_INT16编码升级为INTSET_ENC_INT64编码,或从INTSET_ENC_INT32编码升级为INTSET_ENC_INT64编码,升级的过程都和上面展示的升级过程类似
升级的好处
整数集合的升级策略有两个好处,一个是提升整数集合的灵活性,另一个是尽可能地节约内存
提升灵活性
因为C语言是静态类型语言,为了避免类型错误,我们通常不会将两种不同类型的值放在同一数据结构里面。例如,我们一般只用int16_t类型的数组来保存int16_t类型的值,只使用int32_t类型的数组来保存int32_t类型的值,诸如此类。但是,因为整数集合可以通过自动升级底层数组来适应新元素,所以我们可以随意地将int16_t、int32_t或int64_t类型的整数添加到集合中,而不必担心出现类型错误
节约内存
要让一个数组可以同时保存int16_t、int32_t、int64_t三种类型的值,最简单的做法就是直接使用int64_t类型的数组作为整数集合的底层实现。不过这样一来,部分可以用int16_t、int32_t来存储的值因使用int64_t类型来存储,会造成内存的浪费。而整数集合现在的做法既可以让集合能同时保存三种不同类型的值,又可以确保升级操作只会在有需要的时候进行,这可以尽量节省内存
降级
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。举个栗子,对于图1-11所示的整数集合来说,即使我们将集合里唯一一个真正需要使用int64_t类型来保存的元素4 294 967 295删除了,整数集合的编码仍然会维持使用int64_t,底层数组也仍然会使int64_t类型,如图1-12所示
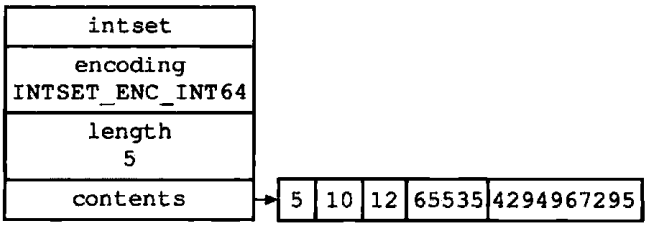
图1-11 数组编码为INTSET_ENC_INT64的整数集合
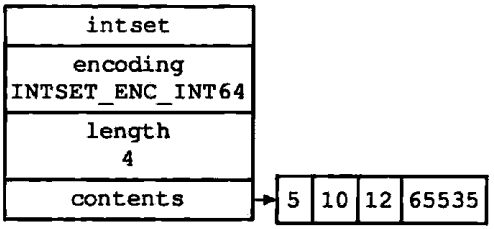
图1-12 删除4 294 967 295的整数集合
整数集合API
表1-1列出了整数集合的操作API
| 函数 | 作用 | 时间复杂度 |
| intsetNew(void) | 创建一个新的整数集合 | O(1) |
| intsetAdd(intset *is, int64_t value, uint8_t *success) | 将给定元素添加到整数集合里面 | O(N) |
| intsetRemove(intset *is, int64_t value, int *success) | 从整数集合中移除给定元素 | O(N) |
| intsetFind(intset *is, int64_t value) | 检查给定值是否存在于集合 | 因为底层数组有序,查找可以通过二分查找法来进行,所以复杂度为O(logN) |
| intsetRandom(intset *is) | 从整数集合中随机返回一个元素 | O(1) |
| intsetGet(intset *is, uint32_t pos, int64_t *value) | 取出底层数组在给定索引上的元素 | O(1) |
| intsetLen(intset *is) | 返回整数集合包含的元素个数 | O(1) |
| intsetBlobLen(intset *is) | 返回整数集合占用的内存字节数 | O(1) |
使用场景
Redis的集合可以帮助我们实现类似抽奖的功能,我们我们将1~10号员工的id放在一个集合中:
127.0.0.1:6379> SADD employee 1 2 3 4 5 6 7 8 9 10 (integer) 10 127.0.0.1:6379> SMEMBERS employee 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" 6) "6" 7) "7" 8) "8" 9) "9" 10) "10"
现在我们要实现从这十位员工中,抽取一个一等奖、两个二等奖、三个三等奖,且已经中奖的员工不能再参与抽奖,我们可以使用SPOP key [count],这个命令可以从指定的集合中随机选出count个元素,并从集合中移除:
127.0.0.1:6379> SPOP employee 1 1) "10" 127.0.0.1:6379> SPOP employee 2 1) "1" 2) "6" 127.0.0.1:6379> SPOP employee 3 1) "5" 2) "7" 3) "8" 127.0.0.1:6379> SMEMBERS employee 1) "2" 2) "3" 3) "4" 4) "9"
如果奖品的价值较小,需求允许抽中的员工允许再次抽奖,我们也可以用SRANDMEMBER key [count],这个命令同样是从给定的集合中随机选取count个元素,但不从集合中移除:
127.0.0.1:6379> SADD employee 1 2 3 4 5 6 7 8 9 10 (integer) 6 127.0.0.1:6379> SRANDMEMBER employee 1 1) "1" 127.0.0.1:6379> SRANDMEMBER employee 2 1) "8" 2) "1" 127.0.0.1:6379> SRANDMEMBER employee 3 1) "7" 2) "2" 3) "8" 127.0.0.1:6379> SMEMBERS employee 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" 6) "6" 7) "7" 8) "8" 9) "9" 10) "10"
从上面的结果可以看到员工1和员工8重复中奖。
Redis的集合数据结构,除了可以用来做抽奖,还可以用来做新浪微博的共同关注和我关注的人也关注了他。
我们在Redis上以attention::{id}的方式来存储用户的关注,可以看到1001用户关注了1005、1006、1007;1002用户关注了1006,SINTER key [key ...]可以从给定的集合key中选出交集的部分,因此执行SINTER attention::1001 attention::1002可以选出1001和1002共同关注的用户,即1006。
127.0.0.1:6379> SADD attention::1001 1005 1006 1007 (integer) 3 127.0.0.1:6379> SADD attention::1002 1006 (integer) 1 127.0.0.1:6379> SINTER attention::1001 attention::1002 1) "1006"
如果我们要查找我关注的人也关注了他呢?既然Redis可以存储我关注了谁,也可以存储谁关注了我,我们用fans::{id}的方式来存储一个用户被哪些用户关注。假定1002号用户被1005、1007用户关注,我们想查看1001用户所关注的用户中,哪些人还关注了1002,就可以用SINTER attention::1001 fans::1002:
127.0.0.1:6379> SADD fans::1002 1005 1007 (integer) 2 127.0.0.1:6379> SINTER attention::1001 fans::1002 1) "1005" 2) "1007"
需要说明的一点是,SINTER attention::{id1} fans::{id2}有个弊端是:如果id1关注了1万个用户,而这一万个用户又都关注了id2,虽然Redis做两个集合的交集计算很快,但返回结果的IO开销很大,并且如果我们是新浪微博的开发人员,也不会一次性把一万个都显示出来。因此为了避免这种极端情况,我们还可以使用SISMEMBER key member命令,这个命令是判断member元素是否在key这个集合里:
127.0.0.1:6379> SISMEMBER fans::1002 1005 (integer) 1 127.0.0.1:6379> SISMEMBER fans::1002 1006 (integer) 0 127.0.0.1:6379> SISMEMBER fans::1002 1007 (integer) 1
为了计算1001关注的用户哪些关注了1002,我们可以依次取出1001关注的用户,判断是否在1002的粉丝列表里。当然,我们也可以判断1002用户是否在1001所关注用户的关注集合里,即:SINTER attention::1005 1002、SINTER attention::1006 1002……。
使用集合数据结构实现我可能认识的人这一功能,比如现在很多APP都会读取手机联系人,从A用户有B用户的手机号,B用户有C用户的手机号,由此推断A是否认识C,这个功能我们可以用差集来实现。假定1001用户关注了1005、1006、1007,而1007用户关注了1006、1008、1009,我们可以由1007集合减去1001集合,由此推断这些1001尚未关注的用户可能是1001用户认识的人。
127.0.0.1:6379> SMEMBERS attention::1001 1) "1005" 2) "1006" 3) "1007" 127.0.0.1:6379> SMEMBERS attention::1007 1) "1006" 2) "1008" 3) "1009" 127.0.0.1:6379> SDIFF attention::1007 attention::1001 1) "1008" 2) "1009"
SINTER除了可以实现共同关注、我关注的人也关注了他,还可以实现电商商品筛选。比如我们可以以下列标签为key,将不同的手机集合存储到key中,如果要筛选满足多个条件的手机,将不同的key做一个交集即可。

我们将不同手机的型号存储在不同的集合key中,当我们需要筛选品牌为HUAWEI、ROM为64G、RAM为1G的手机时,直接从这三个集合中做交集即可。
127.0.0.1:6379> SADD HUAWEI HUAWEI-1 HUAWEI-2 HUAWEI-3 (integer) 3 127.0.0.1:6379> SADD ROM-64G HUAWEI-2 VIVO-1 (integer) 2 127.0.0.1:6379> SADD RAM-1GB HUAWEI-2 XIAOMI-1 VIVO-1 (integer) 3 127.0.0.1:6379> SINTER HUAWEI ROM-64G RAM-1GB 1) "HUAWEI-2"

