


Redis高可用集群
Redis集群方案比较
在Redis3.0以前的集群一般是借助哨兵sentinel工具来监控主节点的状态,如果主节点异常,则会做主从切换,将某一台slave作为master。哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,集群会需要十几秒甚至几十秒的时间用于判断主节点下线,并选举一个从节点成为新的主节点。在某宝双11这样高并发的场景如果出现Redis主节点访问瞬断是一件非常可怕的事,这意味着几千万的商品、订单查询请求将直接请求数据库,数据库很可能因为大批量的查询请求而崩溃。
哨兵模式通常只有一个主节点对外提供服务,没法支持很高的并发,假设一个Redis节点允许支持10W的并发,但面对双11几千万的并发量还是捉襟见肘的,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率。
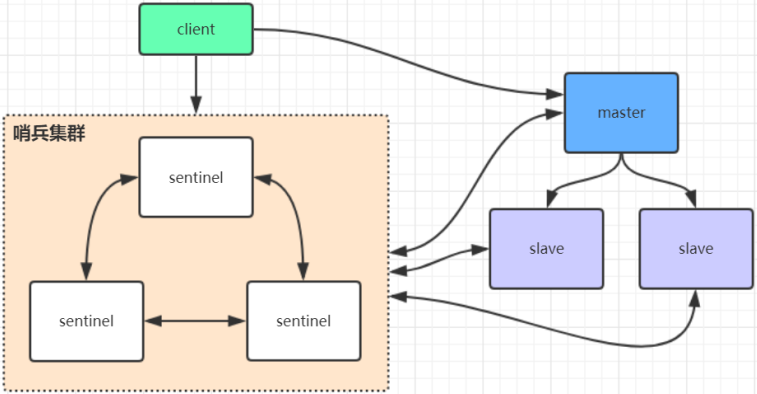
哨兵模式
Redis高可用集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能,只需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。Redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置简单。高可用集群相较于哨兵集群,至少不会出现主节点下线后,整个集群在一段时间内处于不可用状态,直到选举出主节点。因为高可用集群有多个主节点,当我们需要向整个Redis服务写入大批量数据时,数据会根据写入的key算出一个hash值,将数据落地到不同的主节点上,所以当一个主节点下线后,落地到其他主节点的写请求还是正常的。
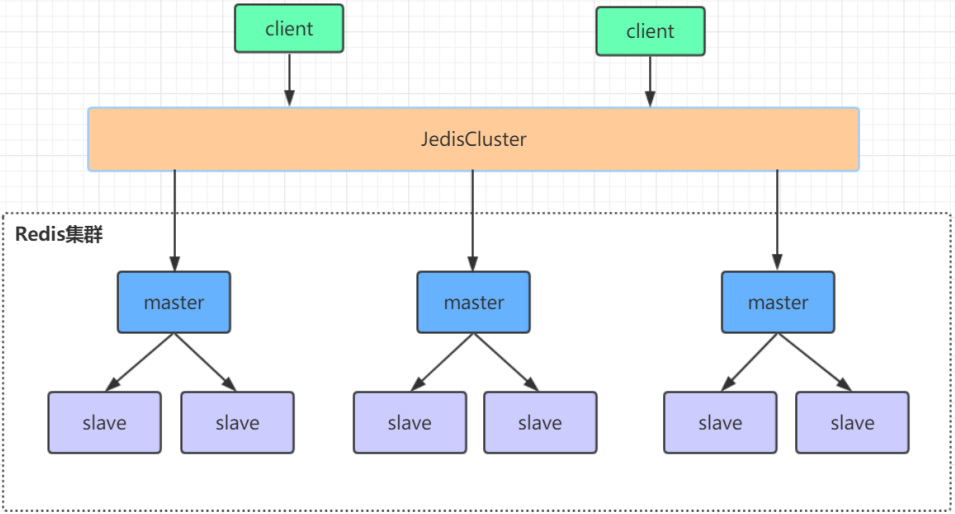
高可用集群模式
Redis高可用集群搭建
Redis集群需要至少三个主节点,我们这里搭建三个主节点,并且给每个主节点再搭建一个从节点,总共6个Redis节点,端口号从8001~8006,这里笔者依旧是在一台机器上部署六个节点,搭建步骤如下:
配置1-1
#在Redis安装目录下创建一个config和data目录,并将redis.conf文件拷贝到config目录下并更名为redis-8001.conf进行配置修改。有部分配置再之前的主从&哨兵集群有讲解过,这里便不再赘述。 port 8001 protected-mode no daemonize yes pidfile "/var/run/redis-8001.pid" logfile "8001.log" dir "/home/lf/redis-6.2.1/data" dbfilename "dump-8001.rdb" #bind 127.0.0.1 -::1 appendonly yes appendfilename "appendonly-8001.aof" requirepass "123456" #设置集群访问密码 masterauth 123456 #启动集群模式 cluster-enabled yes #集群节点信息文件,这里800x最好和port对应上 cluster-config-file nodes-8001.conf #设置节点超时时间,单位:毫秒 cluster-node-timeout 15000
修改完毕redis-8001.conf配置后,我们复制该配置并更名为redis-8002.conf、redis-8003.conf、redis-8004.conf、redis-8005.conf、redis-8006.conf,然后我们将文件里的8001分别替换成8002、8003、8004、8005、8006,可以批量替换:
:%s/源字符串/目的字符串/g
注意,如果集群是搭建在不同的服务器上,大家还要在每台服务器上执行下面的命令关闭下防火墙,避免出现因为防火墙导致不同服务器的Redis进程无法互相访问:
systemctl stop firewalld # 临时关闭防火墙 systemctl disable firewalld # 禁止开机启动
之后,我们单独修改redis-8001.conf的配置:
min-replicas-to-write 1
这个配置可以让我们在向主节点写数据时,主节点必须至少同步到一个从节点才会返回,如果配3则主节点必须同步到3个节点才会返回,这个配置可以在主节点下线,从节点切换为主节点时减少数据的丢失,但这个配置也不能完全规避在主节点下线时数据的丢失,并且存在性能的损耗,因为主节点必须确认数据同步到一定量的从节点,才能将客户端的请求返回。
现在,我们依次启动端口为8001~8006的Redis服务:
[root@master redis-6.2.1]# src/redis-server config/redis-8001.conf [root@master redis-6.2.1]# src/redis-server config/redis-8002.conf [root@master redis-6.2.1]# src/redis-server config/redis-8003.conf [root@master redis-6.2.1]# src/redis-server config/redis-8004.conf [root@master redis-6.2.1]# src/redis-server config/redis-8005.conf [root@master redis-6.2.1]# src/redis-server config/redis-8006.conf
之前创建的6个Redis服务还是独立的服务,下面我们来看下将这6个服务组成一个集群的命令:
[root@master redis-6.2.1]# src/redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #组成集群的Redis服务的IP和端口
--cluster-replicas <arg> #集群副本数量,填N代表每个主节点有N个从节点
……
现在,我们按照上面的命令将6个Redis服务组成一个集群,我们有6个Redis服务,所以会有3个主节点,3个从节点,--cluster-replicas的参数我们应该填1:
#创建集群 [root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster create --cluster-replicas 1 192.168.6.86:8001 192.168.6.86:8002 192.168.6.86:8003 192.168.6.86:8004 192.168.6.86:8005 192.168.6.86:8006 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.6.86:8005 to 192.168.6.86:8001 Adding replica 192.168.6.86:8006 to 192.168.6.86:8002 Adding replica 192.168.6.86:8004 to 192.168.6.86:8003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master #<1> M: 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001 slots:[0-5460] (5461 slots) master M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002 slots:[5461-10922] (5462 slots) master M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003 slots:[10923-16383] (5461 slots) master S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004 replicates baf630fe745d9f1db7a58ffb96e180fab1047c79 S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005 replicates 115a626ee6d475076b096181ab10d3ab6988cc04 S: aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006 replicates 28ad6b59866832b13dbd58dd944e641862702e23 Can I set the above configuration? (type 'yes' to accept): yes #<2> >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join >>> Performing Cluster Check (using node 192.168.6.86:8001) #<3> M: 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006 slots: (0 slots) slave replicates 28ad6b59866832b13dbd58dd944e641862702e23 M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005 slots: (0 slots) slave replicates 115a626ee6d475076b096181ab10d3ab6988cc04 M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004 slots: (0 slots) slave replicates baf630fe745d9f1db7a58ffb96e180fab1047c79 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
我们节选创建集群的部分返回来解析,下面有3个M和3个S,分别代表主节点master和从节点slave,之后是节点的ID、IP+端口,集群默认会使用我们输入的前三个服务作为主节点,根据我们之前输入的参数,端口号8001、8002、8003的服务作为主节点。主节点还会有该节点所对应的槽位,Redis会将数据划分为16384个槽位(slots),每个节点负责存储一部分槽位,比如8001对应的槽位是[0,5460],8002对应的槽位是[5461,10922],8003对应的槽位是[10923,16383],当我们要存储或读取一个key值时,Redis客户端会根据key的hash值去对应槽位的主节点执行命令。我们再来看下从节点,从节点的格式大部分和主节点类似,除了槽位那部分,从节点可以根据replicates {masterID}查询该节点对应的主节点ID,比如8004从节点对应主8002主节点,8005从节点对应8003主节点,8006从节点对应主节点8001。
#<1> M(主节点): 28ad6b59866832b13dbd58dd944e641862702e23(节点ID) 192.168.6.86:8001(节点的IP和端口) slots:[0-5460] (5461 slots) master(节点槽位,key的hash值在0~5460会落地到该节点) M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002 slots:[5461-10922] (5462 slots) master M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003 slots:[10923-16383] (5461 slots) master S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004 replicates baf630fe745d9f1db7a58ffb96e180fab1047c79 S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005 replicates 115a626ee6d475076b096181ab10d3ab6988cc04 S(从节点): aa6ce37e876660161403a801adb8fc7a79a9d876(节点ID) 192.168.6.86:8006(节点的IP和端口) replicates 28ad6b59866832b13dbd58dd944e641862702e23(该从节点对应主节点的ID)
如果同意Redis集群的主从划分,则在<2>处输入yes并回车。<3>处则是真实划分,如果没有意外内容应该跟<1>处大致类似。之前,我们把所有的节点都搭建在一台服务器上,如果我们把节点部署在多台服务器上,那么Redis在划分主从时,会刻意将主从节点划分到不同的服务器上,这是因为Redis期望如果一台服务器挂了,不会导致一整个主从集群都不可用,将主从划分到不同机器上,可以保证如果主节点所在的服务器挂了,从节点能切换成主节点。
如果我们想查看集群信息,可以连接到任意一个节点,执行CLUSTER NODES或者CLUSTER INFO命令:
[root@master redis-6.2.1]# src/redis-cli -a 123456 -c -p 8001 127.0.0.1:8001> CLUSTER NODES aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618317182151 1 connected baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618317187163 2 connected 5461-10922 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618317186161 3 connected 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618317184000 3 connected 10923-16383 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618317186000 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 myself,master - 0 1618317184000 1 connected 0-5460 127.0.0.1:8001> CLUSTER INFO cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_ping_sent:61 cluster_stats_messages_pong_sent:62 cluster_stats_messages_sent:123 cluster_stats_messages_ping_received:57 cluster_stats_messages_pong_received:61 cluster_stats_messages_meet_received:5 cluster_stats_messages_received:123
执行CLUSTER NODES可以看到集群的主从划分,主节点所管理的槽位,从节点对接的主节点,以及各个节点的连接数。这里要注意一点,如果集群所有的服务器都崩溃了,待服务器启动时如果我们想重启整个集群,不需要再用redus-cli --cluster create命令去创建集群,只要启动每个8001~8006的Redis节点,整个集群便会恢复,因为集群一旦创建成功,集群的节点信息会被写入之前配置的nodes-800X.conf文件中。
现在我们来测试集群,我们分别设置两个键值对<python,flask>、<java,spring>:
[root@master redis-6.2.1]# src/redis-cli -a 123456 -c -p 8001 127.0.0.1:8001> SET python flask -> Redirected to slot [7252] located at 192.168.6.86:8002 OK 192.168.6.86:8002> SET java spring -> Redirected to slot [858] located at 192.168.6.86:8001 OK 192.168.6.86:8001> GET java "spring" 192.168.6.86:8001> GET python -> Redirected to slot [7252] located at 192.168.6.86:8002 "flask"
根据上面的输出结果我们可以看到,在设置<python,flask>键值对时,Redis计算出python对应的hash值为7252,处于8002节点所管辖的槽位[5461-10922],会帮我们重定向到8002节点。当我们在8002主节点设置<java,spring>,Redis服务算出java对应的hash值为858,处于8001节点所管辖的槽位[0-5460],又会帮我们重定向到8001.同理执行GET命令时也会帮助我们重定向。
现在,我们再来杀死8001的从节点8006进程,测试之前单独配置给8001的min-replicas-to-write是否能生效,之前我们配置8001必须将写入的数据同步到至少一个从节点才能返回,现在我们再往端口8001的Redis服务设置<java,tomcat>键值对:
[root@master redis-6.2.1]# ps -ef | grep redis root 44661 22426 0 19:50 pts/0 00:00:00 grep --color=auto redis root 108814 1 0 Apr13 ? 00:13:24 src/redis-server *:8002 [cluster] root 108820 1 0 Apr13 ? 00:13:31 src/redis-server *:8003 [cluster] root 108826 1 0 Apr13 ? 00:13:14 src/redis-server *:8004 [cluster] root 108835 1 0 Apr13 ? 00:13:43 src/redis-server *:8005 [cluster] root 108923 1 0 Apr13 ? 00:13:21 src/redis-server *:8001 [cluster] root 109206 1 0 Apr13 ? 00:13:28 src/redis-server *:8006 [cluster] root 109315 1 0 Apr13 ? 00:13:43 src/redis-server *:8007 [cluster] root 109324 1 0 Apr13 ? 00:13:20 src/redis-server *:8008 [cluster] root 109963 103945 0 Apr13 pts/1 00:00:00 src/redis-cli -a 123456 -c -p 8001 #杀死8006端口的Redis服务 [root@master redis-6.2.1]# kill -9 109206 #连接到8001Redis服务后,尝试设置<java,tomcat>键值对,可以看到报错:没有足够的从节点写入。 192.168.6.86:8001> SET java tomcat (error) NOREPLICAS Not enough good replicas to write.
从上面的的结果我们可以确定,min-replicas-to-write N确实可以保证在向Redis主节点写入数据时至少同步到N个从节点后才会返回,如果我们重启8006从节点,8006节点会自动重新加入集群,于是8001主节点又可以正常设置键值对:
[root@master redis-6.2.1]# src/redis-server config/redis-8006.conf 192.168.6.86:8001> SET java tomcat OK
Redis集群节点间的通信机制
Redis Cluster节点间采取gossip协议进行通信,维护集群的元数据(集群节点信息,主从角色,节点数量,各节点共享的数据等)有两种方式:集中式和gossip
集中式:
- 优点在于元数据的更新和读取具有良好的时效性,一旦元数据出现变更立即就会更新到集中式的存储中,其他节点读取的时候可以立即感知到;不足的是所有元数据的更新压力全部集中在一个地方,可能导致元数据的存储压力。很多中间件都会借助zookeeper集中式存储元数据。
gossip:
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
- meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信。
- ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等);
- pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新;
- fail:某个节点判断另一个节点下线后,就发送fail给其他节点,通知其他节点指定的节点宕机了。
gossip协议的优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续传输到所有节点上,降低了压力,但存在一定的延时,可能导致集群的一些操作存在滞后。每个节点都有一个专门用于节点间gossip通信的端口,就是自己提供服务的端口号+10000,比如8001,那么用于节点间通信的端口就是18001端口。每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping消息之后返回pong消息。
网络抖动
线上的机房网络往往并不总是风平浪静的,经常会发生各种各样的问题。比如网络抖动就是很常见的现象,突然间部分连接变得不可访问,过段时间又恢复正常了。
为解决这种问题,Redis Cluster提供了一个选项cluster-node-timeout,表示当某个节点持续timeout的时间失联时,才可以判定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
Redis集群选举原理分析
当从节点发现自己的主节点变为fail状态时,便尝试进行failover,以期成为新的主节点。由于挂掉的主节点可能会有多个从节点,从而存在多个从节点竞争成为主节点的过程,其过程如下:
- 从节点发现自己的主节点变为fail。
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST信息。
- 其他节点收到该信息,只有主节点响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack。
- 尝试failover的从节点收集其他主节点返回的FAILOVER_AUTH_ACK。
- 从节点收到超过半数主节点的ack后变成新主节点(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
- 从节点广播pong消息通知其他集群节点,从节点并不是在主节点一进入fail状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待fail状态在集群中传播,从节点如果立即尝试选举,其它主节点尚未意识到fail状态,可能会拒绝投票。
延迟计算公式:DELAY = 500ms + random(0~500ms)+SALVE_RANK*1000ms
SALVE_RANK表示此从节点从主节点复制数据的总量的rank。rank越小代表已复制的数据越新。这种方式下,持有最新数据的从节点将会首先发起选举。
集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
对于类似MSET,MGET这样可以操作多个key的命令,Redis集群只支持所有key落在同一slot的情况,如果有多个key一定要用类似MSET命令在Redis集群上批量操作,则可以在key的前面加上{XX},这样数据分片hash计算的只会是大括号里的值,可以确保不同的key能落到同一slot里去,示例如下:
#user:1:name和user:2:name两个key会落地到不同的槽位,所以不能用类似MSET批量操作key的命令
192.168.6.86:8002> MSET user:1:name Tom user:2:name Amy
(error) CROSSSLOT Keys in request don't hash to the same slot
#如果用{XX}前缀,可以保证{user}:1:name和{user}:2:name落地到同一个槽位
192.168.6.86:8002> MSET {user}:1:name Tom {user}:2:name Amy
-> Redirected to slot [5474] located at 192.168.6.86:8001
OK
192.168.6.86:8001> MGET {user}:1:name {user}:2:name
1) "Tom"
2) "Amy"
哨兵leader选举流程
当一个主节点服务器被某哨兵视为下线状态后,该哨兵会与其他哨兵协商选出哨兵的leader进行故障转移工作。每个发现主节点下线的哨兵都可以要求其他哨兵选自己为哨兵的leader,选举是先到先得。每个哨兵每次选举都会自增选举周期,每个周期中只会选择一个哨兵作为的leader。如果所有超过一半的哨兵选举某哨兵作为leader。之后该哨兵进行故障转移操作,在存活的从节点中选举出新的主节点,这个选举过程跟集群的主节点选举很类似。
哨兵集群哪怕只有一个哨兵节点,在主节点下线时也能正常选举出新的主节点,当然那唯一一个哨兵节点就作为leader选举新的主节点。不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个主节点类似。
新增/删除节点
到此为止,我们学习了如何创建集群、如何向集群设置键值对,我们还差了解如何往集群里加入节点和删除节点。这里笔者会带大家一起往集群加入一对8007和8008端口的Redis主从节点,然后再将这对主从从集群里移除。我们按照之前的步骤复制redis.conf到config目录下,更名为redis-8007.conf和redis-8008.conf,并按照配置1-1将原先8001替换成8007和8008,然后启动8007和8008两个Redis服务:
[root@master redis-6.2.1]# src/redis-server config/redis-8007.conf [root@master redis-6.2.1]# src/redis-server config/redis-8008.conf
然后我们执行redis-cli --cluster help查看如何将新节点加入集群:
[root@master redis-6.2.1]# src/redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check host:port
--cluster-search-multiple-owners
info host:port
fix host:port
--cluster-search-multiple-owners
--cluster-fix-with-unreachable-masters
reshard host:port
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance host:port
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
--cluster-only-masters
--cluster-only-replicas
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-from-user <arg>
--cluster-from-pass <arg>
--cluster-from-askpass
--cluster-copy
--cluster-replace
backup host:port backup_directory
help
- create:创建一个集群环境host1:port1 ... hostN:portN。
- call:可以执行redis命令。
- add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port。
- del-node:移除一个节点。
- reshard:重新分片。
- check:检查集群状态。
现在,我们将8007Redis服务加入到集群,这里需要我们填入两个参数,一个是新加入的节点IP和端口,一个是已存在在集群的IP和端口,分别是192.168.6.86:8007和192.168.6.86:8001:
[root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster add-node 192.168.6.86:8007 192.168.6.86:8001 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. >>> Adding node 192.168.6.86:8007 to cluster 192.168.6.86:8001 >>> Performing Cluster Check (using node 192.168.6.86:8001) M: 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006 slots: (0 slots) slave replicates 28ad6b59866832b13dbd58dd944e641862702e23 M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005 slots: (0 slots) slave replicates 115a626ee6d475076b096181ab10d3ab6988cc04 M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004 slots: (0 slots) slave replicates baf630fe745d9f1db7a58ffb96e180fab1047c79 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Send CLUSTER MEET to node 192.168.6.86:8007 to make it join the cluster. [OK] New node added correctly.
加入节点时,会重新打印一遍集群原先的主从划分,最后提示:[OK] New node added correctly,代表节点加入成功。
按照上面的步骤,我们把8008也加入到集群,可以发现这次打印的集群信息,相比上次多了一个主节点8007:
[root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster add-node 192.168.6.86:8008 192.168.6.86:8001 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. >>> Adding node 192.168.6.86:8008 to cluster 192.168.6.86:8001 >>> Performing Cluster Check (using node 192.168.6.86:8001) M: 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006 slots: (0 slots) slave replicates 28ad6b59866832b13dbd58dd944e641862702e23 M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005 slots: (0 slots) slave replicates 115a626ee6d475076b096181ab10d3ab6988cc04 M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007 slots: (0 slots) master S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004 slots: (0 slots) slave replicates baf630fe745d9f1db7a58ffb96e180fab1047c79 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Send CLUSTER MEET to node 192.168.6.86:8008 to make it join the cluster. [OK] New node added correctly.
如果我们打印集群信息,会发现8007和8008两个节点都是主节点,而且集群并没有给这两个节点划分槽位,这是正常的,新加入到集群的节点都是主节点,两个节点的主从关系,以及节点管理的槽位需要我们手动去划分:
192.168.6.86:8001> CLUSTER NODES aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618318693000 1 connected baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618318692000 2 connected 5461-10922 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618318693725 3 connected 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618318695730 3 connected 10923-16383 5cd842f76c141eddf5270218b877a54a0c202998 192.168.6.86:8008@18008 master - 0 1618318690000 0 connected 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007@18007 master - 0 1618318694728 7 connected 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618318691000 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 myself,master - 0 1618318692000 1 connected 0-5460
我们先连接到8008节点,让8008节点成为8007的从节点,这里我们用CLUSTER REPLICATE {masterID}命令,可以指定一个新加入的主节点,成为另一个主节点的从节点,这里masterID我们用8007的ID:
[root@master redis-6.2.1]# src/redis-cli -a 123456 -c -p 8008 127.0.0.1:8008> CLUSTER REPLICATE 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 OK #查看节点信息可以看到,8008已经成为8007的从节点 127.0.0.1:8008> CLUSTER NODES baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618318835003 2 connected 5461-10922 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007@18007 master - 0 1618318835000 7 connected 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618318834000 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 master - 0 1618318832000 1 connected 0-5460 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618318832999 3 connected 10923-16383 5cd842f76c141eddf5270218b877a54a0c202998 192.168.6.86:8008@18008 myself,slave 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 0 1618318833000 7 connected 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618318832000 3 connected aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618318836006 1 connected
在划分好新的主从后,我们要为新主从分配槽位,这里我们要用--cluster reshard命令:
[root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster reshard 192.168.6.86:8001
>>> Performing Cluster Check (using node 192.168.6.86:8001)
M: 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006
slots: (0 slots) slave
replicates 28ad6b59866832b13dbd58dd944e641862702e23
M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005
slots: (0 slots) slave
replicates 115a626ee6d475076b096181ab10d3ab6988cc04
M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 5cd842f76c141eddf5270218b877a54a0c202998 192.168.6.86:8008
slots: (0 slots) slave
replicates 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367
M: 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007
slots: (0 slots) master
1 additional replica(s)
S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004
slots: (0 slots) slave
replicates baf630fe745d9f1db7a58ffb96e180fab1047c79
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
#从8001移出600个槽位给别的主节点
How many slots do you want to move (from 1 to 16384)? 600
#输入8007主节点的ID,会将8001主节点管理的600个槽位移给8007
What is the receiving node ID? 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367
Please enter all the source node IDs.
#输入all会从每个主节点(8001、8002、8003)取600个槽位分配给目标主节点(8007)管理
Type 'all' to use all the nodes as source nodes for the hash slots.
#输入done则指定从哪些节点取槽位分配给目标主节点管理
Type 'done' once you entered all the source nodes IDs.
#这里我们输入all,让集群自动帮我们去各个主节点取槽位,由于要取600个,这里输出会很多,只节选部分,可以看到最高到8003主节点的11121
Source node #1: all
……
Moving slot 11119 from 115a626ee6d475076b096181ab10d3ab6988cc04
Moving slot 11120 from 115a626ee6d475076b096181ab10d3ab6988cc04
Moving slot 11121 from 115a626ee6d475076b096181ab10d3ab6988cc04
#输入yes,让Redis开始执行槽位分配。
Do you want to proceed with the proposed reshard plan (yes/no)? yes
槽位分配完毕后,我们再来看看各个主节点的槽位划分,可以8001、8002、8003现在管理的槽位已经和原先不同,而8007则管理三个槽位,分别是从8001、8002、8003分配过来的[0,198] 、[5461,5661]、 [10923,11121]:
127.0.0.1:8001> CLUSTER NODES aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618319470349 1 connected baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618319472353 2 connected 5662-10922 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618319469347 3 connected 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618319471351 3 connected 11122-16383 5cd842f76c141eddf5270218b877a54a0c202998 192.168.6.86:8008@18008 slave 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 0 1618319469000 7 connected 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007@18007 master - 0 1618319470000 7 connected 0-198 5461-5661 10923-11121 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618319468345 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 myself,master - 0 1618319470000 1 connected 199-5460
我们来尝试移除节点,我们先移除8008从节点,这里我们使用--cluster del-node {host}:{port} {nodeID}从集群移除从节点:
[root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster del-node 192.168.6.86:8008 5cd842f76c141eddf5270218b877a54a0c202998 >>> Removing node 5cd842f76c141eddf5270218b877a54a0c202998 from cluster 192.168.6.86:8008 >>> Sending CLUSTER FORGET messages to the cluster... >>> Sending CLUSTER RESET SOFT to the deleted node.
我们再移除8007主节点,由于8007节点已经分配了槽位,直接移除会报错,这里我们要先把8007的槽位归还给各个主节点,这里我们依旧使用
--cluster reshard将8007现有的节点重新划分:
#重新划分8007主节点的槽位
[root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster reshard 192.168.6.86:8007
>>> Performing Cluster Check (using node 192.168.6.86:8007)
M: 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007
slots:[0-198],[5461-5661],[10923-11121] (599 slots) master
M: 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001
slots:[199-5460] (5262 slots) master
1 additional replica(s)
S: 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004
slots: (0 slots) slave
replicates baf630fe745d9f1db7a58ffb96e180fab1047c79
M: baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002
slots:[5662-10922] (5261 slots) master
1 additional replica(s)
M: 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003
slots:[11122-16383] (5262 slots) master
1 additional replica(s)
S: aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006
slots: (0 slots) slave
replicates 28ad6b59866832b13dbd58dd944e641862702e23
S: 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005
slots: (0 slots) slave
replicates 115a626ee6d475076b096181ab10d3ab6988cc04
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
#原先划分给8007节点有600个槽位,现在要重新划分出去
How many slots do you want to move (from 1 to 16384)? 600
#填写接受槽位节点,这里填8001
What is the receiving node ID? 28ad6b59866832b13dbd58dd944e641862702e23
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
#填写8007节点ID
Source node #1: 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367
#输入done生成槽位迁移计划
Source node #2: done
……
Moving slot 11119 from 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367
Moving slot 11120 from 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367
Moving slot 11121 from 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367
#输入yes开始槽位迁移,根据下面的输出我们可以看到11119、11120、11121被迁移到8001主节点
Do you want to proceed with the proposed reshard plan (yes/no)? yes
……
Moving slot 11119 from 192.168.6.86:8007 to 192.168.6.86:8001:
Moving slot 11120 from 192.168.6.86:8007 to 192.168.6.86:8001:
Moving slot 11121 from 192.168.6.86:8007 to 192.168.6.86:8001:
8007主节点将槽位重新分配后,并不意味着8001、8002、8003管理的槽位会回到最初,可以看到,8001管理两个槽位[0,5661]、[10923,11121],和最初8001管理[0-5460]已经不一样了,这里就不再对比8002和8003,大家可以自行对比:
192.168.6.86:8001> CLUSTER NODES aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618651357467 8 connected baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618651357000 2 connected 5662-10922 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618651356000 3 connected 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618651355000 3 connected 11122-16383 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618651355463 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 myself,master - 0 1618651354000 8 connected 0-5661 10923-11121
在重新分配完槽位后,我们再来看看节点信息:
127.0.0.1:8001> CLUSTER NODES aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618320346264 8 connected baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618320345000 2 connected 5662-10922 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618320345000 3 connected 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618320345261 3 connected 11122-16383 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 192.168.6.86:8007@18007 master - 0 1618320347267 7 connected 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618320343256 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 myself,master - 0 1618320343000 8 connected 0-5661 10923-11121
确定8007已经不再管理任何槽位后,我们将8007节点移出集群:
[root@master redis-6.2.1]# src/redis-cli -a 123456 --cluster del-node 192.168.6.86:8007 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 >>> Removing node 5846d4b7785447b9d7b1c08a0ed74c5e68f2f367 from cluster 192.168.6.86:8007 >>> Sending CLUSTER FORGET messages to the cluster... >>> Sending CLUSTER RESET SOFT to the deleted node.
此时,重新查看集群信息,可以看到不再有8007节点了:
127.0.0.1:8001> CLUSTER NODES aa6ce37e876660161403a801adb8fc7a79a9d876 192.168.6.86:8006@18006 slave 28ad6b59866832b13dbd58dd944e641862702e23 0 1618360351136 8 connected baf630fe745d9f1db7a58ffb96e180fab1047c79 192.168.6.86:8002@18002 master - 0 1618360350000 2 connected 5662-10922 9c6f93c3b5329e60032b970b57e599b98961cba6 192.168.6.86:8005@18005 slave 115a626ee6d475076b096181ab10d3ab6988cc04 0 1618360350132 3 connected 115a626ee6d475076b096181ab10d3ab6988cc04 192.168.6.86:8003@18003 master - 0 1618360348127 3 connected 11122-16383 54b6c985bf0f41fa1b92cff7c165c317dd0a30c7 192.168.6.86:8004@18004 slave baf630fe745d9f1db7a58ffb96e180fab1047c79 0 1618360351000 2 connected 28ad6b59866832b13dbd58dd944e641862702e23 192.168.6.86:8001@18001 myself,master - 0 1618360350000 8 connected 0-5661 10923-11121
至此,笔者带大家大致了解了下Redis高可用集群相比主从&哨兵集群的优缺点,以及如何搭建集群、往集群添加/删除节点,这里笔者贴上链接,如果大家在搭建的时候有疑问,也可以对照着链接里的Redis高可用配置文件。

