

并发编程之JMM&Volatile(三)
volatile原理
Java虚拟机规范中定义了Java内存模型(Java Memory Model,即JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,以实现Java程序在各个平台下都能达到一致的并发效果。
Java内存模型中规定所有的变量都存储在主内存,每个线程都有自己独立的工作内存,线程的工作内存中保存了该线程所需要用到的本地变量,以及从主内存中拷贝到工作内存的副本。线程对于变量的读、写都必须在工作内存中进行,线程不能直接读、写主内存的变量。同时,线程的工作内存的变量也无法被别的线程访问,必须通过主内存完成。
下图展示了JMM模型和多核CPU架构模型,对比这两个模型,我们可以发现是十分相似的。假设Java没有提供volatile关键字,如果线程A和线程B在各自的内存里共享主存的同一变量,当线程A修改变量值,线程B将无法感知到变量的值已改变。而在多核CPU模型中,如果没有缓存一致性协议,CPU1和CPU2在各自的缓存拷贝了主存中某一变量的副本,当CPU1修改了副本的值,CPU2也是无法感知此时自己缓存中的副本已失效。于是,我们不禁开始思考:volatile是怎样做到与缓存一致性协议相似的功能?当被volatile标记的变量被一个线程修改时,通知其他线程放弃该变量的副本。

现在让我们看下,一个变量是否被volatile标记,在汇编指令中会有怎样的表现:
package org.example.ch1;
public class TestVolatile {
private static volatile int a = 1;
private static int b = 1;
public static void test() {
a = 2;
b = 3;
}
public static void main(String[] args) {
TestVolatile.test();
}
}
我们添加JVM参数:-Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*TestVolatile.test 运行TestVolatile的代码,可以看到TestVolatile.test()的汇编输出:
……
0x000000000319a6ad: lock add dword ptr [rsp],0h ;*putstatic a
; - org.example.ch1.TestVolatile::test@1 (line 8)
0x000000000319a6b2: mov dword ptr [rsi+6ch],3h ;*putstatic b
; - org.example.ch1.TestVolatile::test@5 (line 9)
……
由于输出结果篇幅的原因,这里只节选了部分,TestVolatile.test()方法很简单,有两个静态变量a和b,初始值都为1,在这个方法中分别对两个字段赋值为2和3,如果对Java字节码熟悉的人也可以看到后面的putstatic a和putstatic b,putstatic在Java字节码的作用就是为静态变量赋值,而a和b就是我们定义的静态变量。我们关键来看字节码前面的汇编指令,其中add dword ptr [rsp],0h和mov dword ptr [rsi+6ch],3h都是常见的汇编指令,一般堆栈里的数据是以双字(dword,8bit)存放的,add dword ptr [rsp],0h意思是:将寄存器rsp栈顶指针+0。mov dword ptr [rsi+6ch],3h意思是:从将3h(3的十六进制表示)存放到寄存器rsi+6ch(288的十六进制表示)的位置,即在rsi+6ch和rsi+6dh存入0000 0000 0000 0011b(3的二进制表示)。除此之外,我们还注意到用volatile标记的变量a还有个lock指令,而正是lock指令,保证了静态变量a的可见性。
lock指令可以对总线或者缓存加锁,然后执行之后的指令,释放锁的时候会把缓存中的数据刷新回主内存,并让其他CPU对回写数据的拷贝失效,重新去主存加载最新的数据,从而保证了当一个线程修改volatile变量的值,其他线程能放弃工作内存的拷贝,重新去主存加载。lock指令不是内存屏障,却实现了类似内存屏障的功能,阻止屏障两边的指令重排序,因此volatile关键字还有禁止两边指令重排序的功能。lock指令后面还可以跟着ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令。
到这里,我们应该了解为何volatile关键字能保证可见性,又能阻止重排序。
现在,我们再来了解下volatile重排序规则,对于什么样的操作,volatile允许指令重排序,什么样的操作,volatile不允许指令重排序:
| 是否能重排序 | 第二个操作 | ||
| 第一个操作 | 普通读/写 | volatile读 | volatile写 |
| 普通读/写 | NO | ||
| volatile读 | NO | NO | NO |
| volatile写 | NO | NO | |
根据上面的表格,我们可以做出如下归纳:
- 第二个操作是volatile写,不管第一个操作是什么都不会重排序。
- 第一个操作是volatile读,不管第二个操作是什么都不会重排序。
- 第一个操作是volatile写,第二个操作是volatile读,也不会发生重排序。
现在我们来分析下上面的规则,为什么volatile要做出这样的限制?首先我们要明确volatile读/写的内存语义:
- 当读一个volatile变量时,JMM会把当前线程用到的所有共享变量(不单单被volatile修饰的变量)从主存重新加载。
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的所有共享变量值刷回到主内存。
所以,无论是volatile读/写,都会刷新本地内存的所有共享变量,不单单是volatile变量。
我们假设execToThead1()被线程1执行,execToThread2()被线程2执行,从下面的代码我们可以看出线程1对变量a和b写数据,线程2读取变量a和b的数据:
volatile int a = 0;
int b = 1;
public void execToThead1() {
b = 2;//1 普通写
a = 1;//2 volatile写
}
public void execToThread2() {
while (a == 0) {
continue;
}
if (b == 2) {
//do something...
}
}
按照之前的规则,第二个操作是volatile写时,不管第一个操作是什么都不允许指令重排序,所以我们知道当线程1执行步骤2volatile写时,变量a连同共享变量b的数据会刷回到主存。因此线程2检查到变量a不为0时跳出循环,而且共享变量b为2,执行if分支里的逻辑。
如果volatile写不影响指令的排序,步骤1和步骤2没有依赖关系,那么步骤2可能先步骤1执行,变量a在主存的值从0变为1。线程2检查到变量a不再为0后跳出循环,但此时主存里的b仍然为1,线程2即便每次读取a时都会刷新本地内存,但依旧无法执行if分支里的判断,这是因为允许volatile写时重排序,导致把变量值刷回到主存的时机提前了,漏掉volatile写前的对共享变量的修改。
因此,这里就引出我们第一条规则:第二个操作是volatile写时,不管第一个操作是什么都不允许指令重排序。
下面,我们再来解释第二条规则,execToThead1()被线程1执行,对变量a和b赋值,execToThread2()较之前有些许变化,但依旧是读取变量a和b的值。
volatile int a = 0;
int b = 1;
public void execToThead1() {
b = 2;//1 普通写
a = 1;//2 volatile写
}
public void execToThread2() {
while (a == 0) {//3 volatile读
continue;
}
int c = b;//4 普通写
}
按照第二条规则,第一个操作是volatile读,不管第二个操作是什么都不能重排序,所以线程1执行完毕,线程2的步骤3就会跳出循环,此时共享变量b的值为2,将b的值赋值给本地变量c,所以c的值也为2。
假设允许volatile读和之后的指令重排序,那么步骤3和步骤4实际上没有依赖性关系,那么指令序列可能优化成,先读取b的值(此时b为1)将其放入缓冲区,然后执行while循环,知道线程1执行完毕,volatile变量a的值为1,线程2跳出while循环,将缓冲区中b的值取出赋值给变量c,但此时主存中的变量b为2,这明显不是我们想要的结果。
由此引出第二条规则:第一个操作是volatile读,不管第二个操作是什么都不能重排序。
而volatile变量间的读写不能重排就不再举例了。
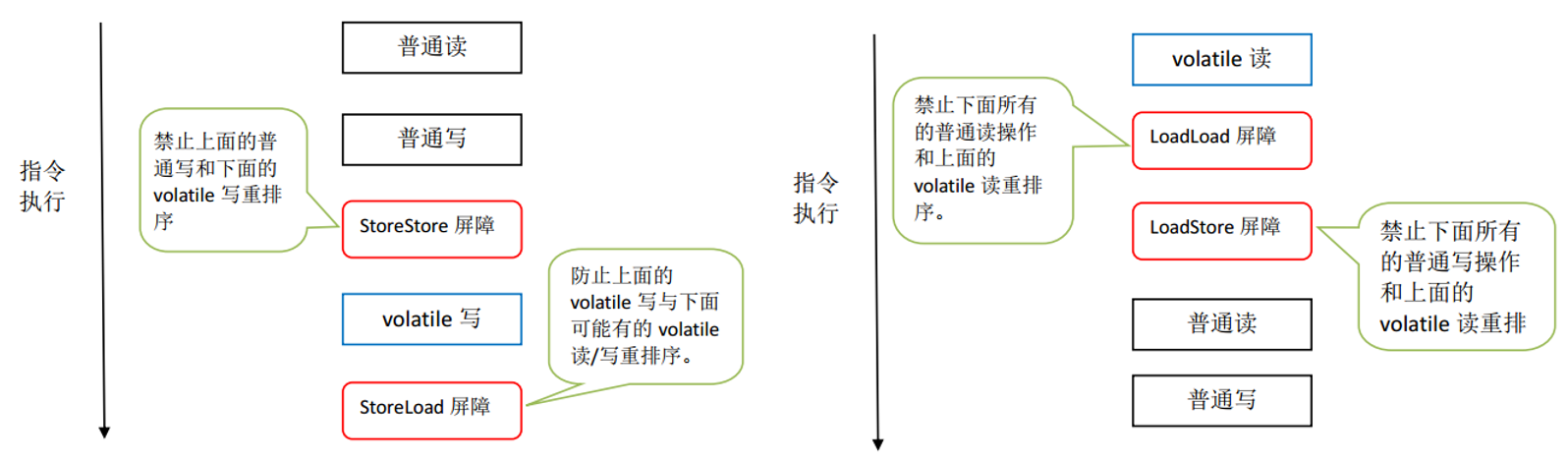
JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
| 屏障类型 | 指令示例 | 说明 |
| LoadLoadBarrier | Load1;LoadLoad;Load2 | 确保Load1数据的装载先于Load2及所有后续装载指令的装载。 |
| StoreStoreBarrier | Store1;StoreStore;Store2 | 确保Store1数据对其他处理器可见(刷新到内存)先于Store2及所有后续存储指令的存储。 |
| LoadStoreBarrier | Load1;LoadStore;Store2 | 确保Load1数据的装载先于Store2及所有后续的存储指令刷新到内存。 |
| StoreLoadBarrier | Store1;StoreLoad;Load2 | 确保Store1数据对其他处理器变得可见(指刷新到内存)先于Load2及所有后序装载指令的装载。StoreLoadBarrier会使该屏障之前的所有内存访问指令(存储和装载指令)完成后,才执行屏障之后的内存访问指令。 |
