

Docker背后的内核知识(一)
Docker背后的内核知识
当谈论Docker时,常常会聊到Docker的实现方式。很多开发者都知道,Docker容器本质上是宿主机上的进程。Docker通过namespace实现了资源隔离。通过cgroups实现了资源限制,通过写时复制机制实现了高效的文件操作。但更进一步深入namespace和cgroups等技术细节时,大部分开发者都会感到茫然无措。所以在这里,先带领大家走进Linux内核,了解namespace和cgroups的技术细节。
namespace资源隔离
想要要实现一个资源隔离的容器,应该从哪些方面入手呢?可能有人第一反应可能就是chroot命令,这条命令给用户最直观的感觉就是使用后根目录/的挂载点切换了,即文件系统被隔离了。接着,为了在分布式的环境下进行通信和定位,容器必然需要一个独立的IP、端口、路由等,自然就想到了网络的隔离。同时,容器还需要一个独立的主机名以便在网络中标识自己。想到网络,顺其自然就想到通信,也就想到了进程间通信需要隔离。开发者可能也想到了权限的问题,对用户和用户组的隔离就实现了用户权限的隔离。最后,运行在容器中的应用需要有自己的(PID),自然也需要与宿主机中的PID进行隔离。
由此,基本上完成了一个容器所需要做的六项隔离,Linux内核中就提供了这六种namespace隔离的系统调用,如表1-1所示。
| Namespace | 系统调用参数 | 隔离内容 |
| UTS | CLONE_NEWUTS | 主机名与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
实际上,Linux内核实现namespace的一个主要目的,就是为了实现轻量级虚拟化(容器)服务。在同一个namespace下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,仿佛自己置身于一个独立的系统环境中,以此达到独立和隔离的目的。
1.进行namespace API操作的四种方式
namespace的API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪6项namespace,在使用这些API时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。从表1-1可知,这六个参数分别是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和CLONE_NEWUTS。
通过clone()创建新进程的同时创建namespace
使用clone()来创建一个独立namespace的进程是最常见做法,也是Docker使用namespace最基本的方法,它的调用方式如下:
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
clone()实际上是Linux系统调用fork()的一种更通用的实现方式,它可以通过flags来控制使用多少功能。一共有二十多种CLONE_*的flag(标志位)参数用来控制clone进程的方方面面(如是否与父进程共享虚拟内存等等),下面挑选与namespace相关的四个参数进行说明。
- child_func传入子进程运行的程序主函数。
- child_stack传入子进程使用的栈空间。
- flags表示使用哪些CLONE_*标志位,与namespace相关的主要包括CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和、CLONE_NEWUTS。
- args则可用于传入用户参数。
查看/proc/[pid]/ns文件
从3.8版本的内核开始,用户就可以在/proc/[pid]/ns文件下看到指向不同namespace号的文件,效果如下所示,形如[4026531839]者即为namespace号。
# ls -l /proc/$$/ns #<<-- $$是shell中表示当前运行的进程ID号 total 0 lrwxrwxrwx 1 root root 0 Nov 24 10:18 ipc -> ipc:[4026531839] lrwxrwxrwx 1 root root 0 Nov 24 10:18 mnt -> mnt:[4026531840] lrwxrwxrwx 1 root root 0 Nov 24 10:18 net -> net:[4026531956] lrwxrwxrwx 1 root root 0 Nov 24 10:18 pid -> pid:[4026531836] lrwxrwxrwx 1 root root 0 Nov 24 10:18 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 Nov 24 10:18 uts -> uts:[4026531838]
如果两个进程指向的namespace编号相同,就说明他们在同一个namespace下,否则则在不同namespace里面。/proc/[pid]/ns里设置这些link的另一个作用是,一旦上述link文件被打开,只要打开的文件描述符(fd)存在,那么就算该namespace下的所有进程都已经结束,创建的namespace就会一直存在,后续进程也可以再加入进来。在Docker中,通过文件描述符定位和加入一个存在的namespace是最基本的方式。
另外,把/proc/[pid]/ns目录文件使用--bind挂载起来就可以达到打开文件描述符的效果,命令如下:
# touch ~/uts # mount --bind /proc/27514/ns/uts ~/uts
通过setns()加入一个已经存在的namespace
上面提到,在进程都结束的情况下,也可以通过挂载的形式把namespace保留下来,保留namespace的目的自然是为以后有进程加入做准备。在Docker中,使用docker exec命令在已经运行着的容器中执行一个新的命令,就需要用到该方法。通过setns()系统调用,进程的pid namespace加入某个已经存在的namespace,使用方法如下。
int setns(int fd, int nstype);
- 参数fd表示要加入的namespace的文件描述符。上面提到,它是一个指向/proc/[pid]/ns目录的文件描述符,可以通过直接打开该目录下的链接或者打开一个挂载了该目录下链接的文件得到。
- 参数nstype让调用者可以去检查fd指向的namespace类型是否符合我们实际的要求。该参数为0表示不检查。
通常为了不影响进程的调用者,也为了使新加入的pid namespace生效,会正在setns()函数执行后使用clone()创建子进程继续执行命令,让原先的进程结束运行。
fd = open(argv[1], O_RDONLY); /* 获取namespace文件描述符 */ setns(fd, 0); /* 加入新的namespace */ execvp(argv[2], &argv[2]); /* 执行程序 */
假设编译后的程序名称为setns-test:
# ./setns-test ~/uts /bin/bash # ~/uts 是绑定的/proc/27514/ns/uts
至此,就可以在新的namespace(名字空间)中执行shell命令了,下面会多次使用这种方式来演示隔离的效果。
通过unshare()在原先进程上进行namespace隔离
最后要说明的系统调用是unshare(),它跟clone()很像,不同的是,unshare()运行在原先的进程上,不需要启动一个新进程。
int unshare(int flags);
调用unshare()的主要作用就是,不启动新进程就可以起到隔离的效果,相当于跳出原先的namespace进行操作。这样,就可以在原进程进行一些需要隔离的操作。Linux中自带的unshare命令,就是通过unshare()系统调用实现的。
fork()系统调用
系统调用函数fork()并不属于namespace的API,当程序调用fork()函数时,系统会创建新的进程,为其分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的进程中,只有少量数值与原来的进程值不同,相当于复制了本身。那么程序的后续代码逻辑要如何区分自己是新进程还是父进程呢?
fork()的神奇之处在于它仅仅被调用一次,却能够返回两次(父进程与子进程各返回一次),通过返回值的不同就可以进行区分父进程与子进程。它可能有三种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
下面给出一段实例代码,命名为fork_example.c:
#include <unistd.h>
#include <stdio.h>
int main()
{
pid_t fpid; //fpid表示fork函数返回的值
fpid = fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0)
{
printf("I am child. Process id is %d\n", getpid());
}
else
{
printf("I am parent. Process id is %d\n", getpid());
}
return 0;
}
编译并运行,结果如下:
root@local:~# gcc -Wall fork_example.c && ./a.out I am parent. Process id is 28365 I am child. Process id is 28366
代码执行过程中,在语句fpid=fork()之前,只有一个进程在执行这段代码,在这条语句之后,就变成父进程和子进程同时执行了。这两个进程几乎完全相同,将要执行的下一条语句都是if (fpid < 0),同时fpid = fork()的返回值会依据所属进程返回不同的值。
使用fork()后,父进程有义务监控子进程的运行状态,并在子进程退出后自己才能正常退出,否则子进程就会成为“孤儿”进程。
下面根据Docker内部对namespace资源隔离使用的方式分别对六种namespace进行介绍。
2.UTS namespace
UTS(UNIX Time-sharing System)namespace提供了主机名和域名的隔离,这样每个Docker容器就可以拥有独立的主机名和域名,在网络上可以被视作一个独立的节点,而非宿主机上的一个进程。在Docker中,每个镜像基本都以自身所提供的服务名称来命名镜像的hostname,且不会对宿主机产生任何影响,其原理就是利用了UTS namespace。
下面通过代码来感受一下UTS隔离的效果,首先需要一个程序的骨架,打开编辑器创建uts.c文件,输入如下代码:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char *const child_args[] = {
"/bin/bash",
NULL};
int child_main(void *args)
{
printf("在子进程中!\n");
execv(child_args[0], child_args);
return 1;
}
int main()
{
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE,
CLONE_NEWUTS | SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}
编译并运行上述代码,执行如下命令,效果如下:
root@local:~# gcc -Wall uts.c -o uts.o && ./uts.o 程序开始: 在子进程中! root@local:~# exit exit 已退出 root@local:~#
下面修改代码,加入UTS隔离。运行代码需要root权限,以防止普通用户任意修改系统主机名导致set-user-ID相关的应用运行出错。
int child_main(void *args)
{
printf("在子进程中!\n");
sethostname("NewNamespace", 12);
execv(child_args[0], child_args);
return 1;
}
再次编译运行,可以看到hostname发生了变化:
root@local:~# gcc -Wall namespace.c -o main.o && ./main.o 程序开始: 在子进程中! root@NewNamespace:~# exit exit 已退出 root@local:~#
值得一提的是,也许有读者会尝试不加CLONE_NEWUTS参数运行上述代码,发现主机名也变了,输入exit后主机名也恢复了,似乎没什么区别。实际上不加CLONE_NEWUTS参数进行隔离时,由于使用sethostname函数,已经把宿主机的主机名改掉了。而看到exit退出后还原,是因为bash只在刚登录的时候读取一次UTS,不会实时读取最新的主机名,当你重新登陆或者使用uname命令进行查看时,就会发现产生了变化。
3.IPC namespace
进程间通信(Inter-Process Communication,IPC)涉及到的IPC资源包括常见的信号量、消息队列和共享内存。然而与虚拟机不同的是,容器内部进程间通信对宿主机来说,实际上是具有相同PID namespace中的进程间通信,因此需要一个唯一的标识符来进行区别。申请IPC资源就是申请了一个全局唯一的32位ID,所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统。在同一个IPC namespace下的进程彼此可见,不同IPC namespace下的进程则互相不可见。
IPC namespace在代码上的变化与UTS namespace相似,只是标识位有所变化,需要加上CLONE_NEWIPC参数。主要改动如下,其他部位不变,程序名称改为ipc.c:
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
首先在shell中使用ipcmk -Q命令创建一个message queue:
root@local:~# ipcmk -Q Message queue id: 32769
通过ipcs -q可以查看到已经开启的message queue,序号为32769。
root@local:~# ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages 0x4cf5e29f 32769 root 644 0 0
然后可以编译运行加入了IPC namespace隔离的ipc.c,在新建的子进程中调用的shell中执行ipcs -q查看message queue。
root@local:~# gcc -Wall ipc.c -o ipc.o && ./ipc.o 程序开始: 在子进程中! root@NewNamespace:~# ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages root@NewNamespace:~# exit exit 已退出
从上面显示的结果中可以发现,子进程已经找不到原先声明的message queue,实现了IPC的隔离。
目前使用IPC namespace机制的系统不多,其中比较有名的有PostgreSQL。Docker当前也使用IPC namespace实现了容器与宿主机、容器与容器之间的IPC隔离。
4.PID namespace
PID namespace隔离非常实用,它对进程PID重新标号,即两个不同namespace下的进程可以有同一个PID。每个PID namespace都有自己的计数程序。内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,被称为root namespace。它创建的新PID namespace就称为child namespace(树的子节点),而原先的PID namespace就是新创建的PID namespace的parent namespace(树的父节点)。通过这种方式,不同的PID namespaces会形成一个层级体系。所属的父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。反过来,子节点不能看到父节点PID namespace中的任何内容,由此产生如下结论:
- 每个PID namespace中的第一个进程“PID 1”,都会像传统Linux中的init进程一样拥有特权,起特殊作用。
- 一个namespace中的进程,不可能通过kill或ptrace影响父节点或者兄弟节点中的进程,因为其他节点的PID在这个namespace中没有任何意义。
- 如果你在新的PID namespace中重新挂载/proc文件系统,会发现其下只显示同属一个PID namespace中的其他进程。
- 在root namespace中可以看到所有的进程,并且递归包含所有子节点中的进程。
到这里,有人可能已经想到一种在外部监控Docker中运行程序的方法了,就是监控Docker Daemon所在的PID namespace下的所有进程即其子进程,再进行筛选即可。
下面通过运行代码来感受一下PID namespace的隔离效果。修改上面的代码,加入PID namespace的标识位,并把程序命名为pid.c。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS
| SIGCHLD, NULL);
//[...]
编译运行可以看到如下结果。
root@local:~# gcc -Wall pid.c -o pid.o && ./pid.o 程序开始: 在子进程中! root@NewNamespace:~# echo $$ 1 <<--注意此处看到shell的PID变成了1 root@NewNamespace:~# exit exit 已退出
打印$$可以看到shell的PID,退出后如果再次执行可以看到效果如下。
root@local:~# echo $$ 17542
已经回到了正常状态。可能有人在子进程的shell中执行了ps aux/top之类的命令,发现还是可以看到所有父进程的PID,那是因为我们还没有对文件系统进行隔离,ps/top之类的命令调用的是真实系统下的/proc文件内容,看到的自然是所有的进程。所以,与其他的namespace不同的是,为了实现一个稳定安全的容器,PID namespace还需要进行一些额外的工作才能确保其中的进程运行顺利,下面将逐一介绍。
PID namespace中的init进程
在传统的UNIX系统中,PID为1的进程是init,地位非常特殊。它作为所有进程的父进程,维护一张进程表,不断检查进程的状态,一旦有某个子进程因为父进程错误成为了“孤儿”进程,init就会负责回收这个子进程占用的资源并结束子进程。所以在要实现的容器中,启动的第一个进程也需要实现类似init的功能,维护所有后续启动进程的运行状态。
当系统中存在树状嵌套结构的PID namespace时,若某个子进程成为孤儿进程,收养该子进程的责任就交给了该子进程所属的PID namespace中的init进程。
至此,可能有人已经明白了内核设计的良苦用心。PID namespace维护这样一个树状结构,有利于系统的资源监控与回收。因此,如果确实需要在一个Docker容器中运行多个进程,最先启动的命令进程应该是具有资源监控与回收等管理能力的,如bash。
信号与init进程
内核还为PID namespace中的init进程赋予了其他特权——信号屏蔽。如果init中没有编写处理某个信号的代码逻辑,那么与init在同一个PID namespace下的进程(即使有超级权限)发送给它的该信号都会被屏蔽。这个功能的主要作用是防止init进程被误杀。
那么,父节点PID namespace中的进程发送同样的信号给子节点的init进程会被忽略吗?父节点中的进程发送的信号,如果不是SIGKILL(销毁进程)或SIGSTOP(暂停进程)也会被忽略。但如果发送SIGKILL或SIGSTOP,子节点的init会强制执行(无法通过代码捕捉进行特殊处理),也就是说父节点中的进程有权终止子节点中的进程。
一旦init进程被销毁,同一PID namespace中的其他进程也会随之接收到SIGKILL信号而被销毁。理论上,该PID namespace自然也就不复存在了。但是如果/proc/[pid]/ns/pid处于被挂载或者打开状态,namespace就会被保留下来。然而,保留下来的namespace无法通过setns()或者fork()创建进程,所以实际上并没有什么作用。
当一个容器内存在多个进程时,容器内的init进程可以对信号进行捕获,当SIGTERM或SIGINT等信号到来时,对其子进程做信息保存、资源回收等处理工作。在Docker daemon的源码中也可以看到类似的处理方式,当结束信号来临时,结束容器进程并回收相应资源。
挂载proc文件系统
上面已经提到,如果在新的PID namespace中使用ps命令查看,看到的还是所有的进程,因为与PID直接相关的/proc文件系统(procfs)没有挂载到与原/proc不同的位置。如果只想看到PID namespace本身应该看到的进程,需要重新挂载/proc,命令如下。
root@NewNamespace:~# mount -t proc proc /proc
root@NewNamespace:~# ps a
PID TTY STAT TIME COMMAND
1 pts/1 S 0:00 /bin/bash
12 pts/1 R+ 0:00 ps a
可以看到实际的PID namespace就只有两个进程在运行。
注意:此时我们没有进行mount namespace的隔离,所以这一步操作实际上已经影响了root namespace的文件系统,当你退出新建的PID namespace以后再执行ps a就会发现出错,再次执行mount -t proc proc /proc可以修复错误。后面还会介绍通过mount namespace来隔离文件系统,当我们基于mount namespace实现了容器proc文件系统隔离后,我们就能在Docker容器中使用ps等命令看到与PID namespace对应的进程列表。
unshare()和setns()
之前我们谈到unshare()和setns()这两个API,在PID namespace中使用时,也有一些特别之处需要注意。
unshare()允许用户在原有进程中建立命名空间进行隔离。但是创建了PID namespace后,原先unshare()调用者进程并不进入新的PID namespace,接下来创建的子进程才会进入新的namespace,这个子进程也就随之成为新namespace中的init进程。
类似的,调用setns()创建新PID namespace时,调用者进程也不进入新的PID namespace,而是随后创建的子进程进入。
为什么创建其他namespace时unshare()和setns()会直接进入新的namespace,而唯独PID namespace例外呢?因为调用getpid()函数得到的PID是根据调用者所在的PID namespace而决定返回哪个PID,进入新的PID namespace会导致PID产生变化。而对用户态的程序和库函数来说,它们都认为进程的PID是一个常量,PID的变化会引起这些进程奔溃。
换句话说,一旦程序进程创建以后,那么它的PID namespace的关系就确定下来了,进程不会变更他们对应的PID namespace。在Docker中,docker exec会使用setns()函数加入已经存在的命名空间,但是最终还是会调用clone()函数,原因就在于此。
mount namespace
mount namespace通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个Linux namespace,所以它的标识位比较特殊,就是CLONE_NEWNS。隔离后,不同mount namespace中的文件结构发生变化也互不影响。你可以通过/proc/[pid]/mounts查看到所有挂载在当前namespace中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等等。
进程在创建mount namespace时,会把当前的文件结构复制给新的namespace。新namespace中的所有mount操作都只影响自身的文件系统,对外界不会产生任何影响。这样做法非常严格地实现了隔离,但对某些情况可能并不适用。比如父节点namespace中的进程挂载了一张CD-ROM,这时子节点namespace复制的目录结构是无法自动挂载上这张CD-ROM,因为这种操作会影响到父节点的文件系统。
2006 年引入的挂载传播(mount propagation)解决了这个问题,挂载传播定义了挂载对象(mount object)之间的关系,这样的关系包括共享关系和从属关系,系统用这些关系决定任何挂载对象中的挂载事件如何传播到其他挂载对象。所谓传播事件,是指由一个挂载对象的状态变化导致的其它挂载对象的挂载与解除挂载动作的事件。
- 共享关系(share relationship)。如果两个挂载对象具有共享关系,那么一个挂载对象中的挂载事件会传播到另一个挂载对象,反之亦然。
- 从属关系(slave relationship)。如果两个挂载对象形成从属关系,那么一个挂载对象中的挂载事件会传播到另一个挂载对象,但是反过来不行;在这种关系中,从属对象是事件的接收者。
一个挂载状态可能为如下的其中一种:
- 共享挂载(shared)
- 从属挂载(slave)
- 共享/从属挂载(shared and slave)
- 私有挂载(private)
- 不可绑定挂载(unbindable)
传播事件的挂载对象称为共享挂载(shared mount);接收传播事件的挂载对象称为从属挂载(slave mount);同时兼有前述两者特征的挂载对象称为共享/从属挂载;既不传播也不接收传播事件的挂载对象称为私有挂载(private mount);另一种特殊的挂载对象称为不可绑定的挂载(unbindable mount),它们与私有挂载相似,但是不允许执行绑定挂载,即创建mount namespace时这块文件对象不可被复制。通过图1-1可以更好地了解它们的状态变化:

图1-1 mount各类挂载状态示意图
下面我们以图1-1为例说明常用的挂载传播方式。最上层的mount namespace下的/bin目录与child namespace通过master slave方式进行挂载传播,当mount namespace中的/bin目录发生变化时,发生的挂载事件能够自动传播到child namespace中;/lib目录使用完全的共享挂载传播,各namespace之间发生的变化都会互相影响;/proc目录使用私有挂载传播方式,各mount namespace之间互相隔离;最后的/root目录一般都是管理员所有,不能让其他mount namespace挂载绑定。
默认情况下,所有挂载都是私有的。设置为共享挂载的命令如下。
mount --make-shared <mount-object>
从共享挂载克隆的挂载对象也是共享的挂载;它们相互传播挂载事件。
设置为从属挂载的命令如下。
mount --make-slave <shared-mount-object>
来源于从属挂载克隆的挂载对象也是从属的挂载,它也从属于原来的从属挂载的主挂载对象。
将一个从属挂载对象设置为共享/从属挂载,可以执行如下命令或者将其移动到一个共享挂载对象下。
mount --make-shared <slave-mount-object>
如果想把修改过的挂载对象重新标记为私有的,可以执行如下命令。
mount --make-private <mount-object>
通过执行以下命令,可以将挂载对象标记为不可绑定的。
mount --make-unbindable <mount-object>
这些设置都可以递归式地应用到所有子目录中。
在代码中实现mount namespace隔离与其他namespace类似,加上CLONE_NEWNS标识位即可。让我们再次修改代码,并且另存为mount.c进行编译运行。
//[...] int child_pid = clone(child_main, child_stack+STACK_SIZE, CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL); //[...]
CLONE_NEWS生效之后,子进程进行的挂载与卸载操作都将只作用于这个mount namespace,因为在上面提到的处于单独PID namespace隔离中的进程在加上mount namespace的隔离之后,即使该进程重新挂载了/proc文件系统,当进程退出后,root mount namespace(主机)的/proc文件系统是不会被破坏的。
network namespace
当我们了解完各类namespace,兴致勃勃地构建出一个容器,并在容器中启动一个Apache进程时,却出现了“80端口已被占用”的错误,原来主机上已经运行了一个Apache进程。这时就需要借助network namespace技术进行网络隔离。
network namespace主要提供了关于网络资源的隔离,包括网络设备、IPv4和IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、套接字(socket)等等。一个物理的网络设备最多存在在一个network namespace中,可以通过创建veth pair(虚拟网络设备对:有两端,类似管道,如果数据从一端传入另一端也能接收到,反之亦然)在不同的network namespace间创建通道,以此达到通信的目的。
一般情况下,物理网络设备都分配在最初的root namespace(表示系统默认的namespace)中。如果有多块物理网卡,也可以把其中一块或多块分配给新创建的network namespace。需要注意的是,当新创建的network namespace被释放时(所有内部的进程都终止并且namespace文件没有被挂载或打开),在这个namespace中的物理网卡会返回到root namespace,而非创建该进程的父进程所在的network namespace。
当说到network namespace时,指的未必是真正的网络隔离,而是把网络独立出来,给外部用户一种透明的感觉,仿佛跟另外一个网络实体在进行通信。为了达到这个目的,容器的经典做法就是创建一个veth pair,一端放置在新的namespace中,通常命名为eth0,一端放在原先的namespace中连接物理网络设备,再通过把多个设备接入网桥或者进行路由转发,来实现通信的目的。
也许有人会好奇,在建立起veth pair之前,新旧namespace该如何通信呢?答案是pipe(管道)。以Docker Daemon在启动容器的过程为例。假设容器内初始化的进程称为init。Docker Daemon在宿主机上负责创建这个veth pair,,把一端绑定到docker0网桥上,另一端接入新建的network namespace进程中。这个过程执行期间,Docker Daemon和init就通过pipe进行通信。具体来说,就是在Docker Daemon完成veth pair的创建之前,init在管道的另一端循环等待,直到管道另一端传来Docker Daemon关于veth设备的信息,并关闭管道。init才结束等待的过程,并把它的“eth0”启动起来。整个结构如图1-2所示。
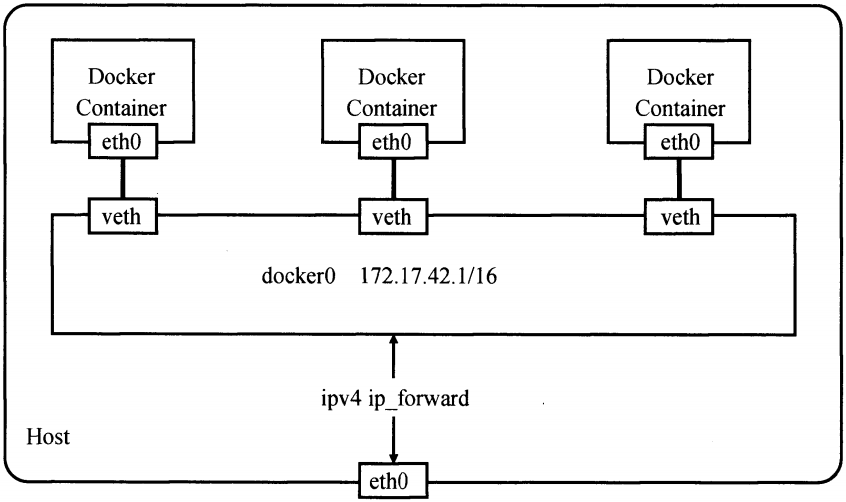
图1-2 Docker网络示意图
跟其他namespace类似,对network namespace的使用其实就是在创建的时候添加CLONE_NEWNET标识位。
user namespace
user namespace主要隔离了安全相关的标识符(identifiers)和属性(attributes),包括用户ID、用户组ID、root目录、key(指密钥)以及特殊权限。通俗地讲,一个普通用户的进程通过clone()创建的新进程在新user namespace中可以拥有不同的用户和用户组。这意味着一个进程在容器外属于一个没有特权的普通用户,但是他创建的容器进程却属于拥有所有权限的超级用户,这个技术为容器提供了极大的自由。
user namespace是目前的六个namespace中最后一个支持的,并且直到Linux内核3.8版本的时候还未完全实现(还有部分文件系统不支持)。因为user namespace实际上并不算完全成熟,很多发行版担心安全问题,在编译内核的时候并未开启USER_NS。Docker在1.10版本中对user namespace进行了支持。只要用户在启动Docker daemon的时候指定了--userns-remap,那么当用户运行容器时,容器内部的root用户并不等于宿主机内的root用户,而是映射到宿主上的普通用户。
Linux中,特权用户的user ID就是0,后面我们将看到user ID非0的进程启动user namespace后user ID可以变为0。使用user namespace的方法跟别的namespace相同,即调用clone()或unshare()时加入CLONE_NEWUSER标识位。修改代码并另存为userns.c,为了看到用户权限(Capabilities),可能你还需要安装一下libcap-dev包。
首先包含以下头文件以调用Capabilities包。
#include <sys/capability.h>
其次在子进程函数中加入geteuid()和getegid()得到namespace内部的user ID,其次通过cap_get_proc()得到当前进程的用户拥有的权限,并通过cap_to_text()输出。
int child_main(void* args) {
printf("在子进程中!\n");
cap_t caps;
printf("eUID = %ld; eGID = %ld; ",
(long) geteuid(), (long) getegid());
caps = cap_get_proc();
printf("capabilities: %s\n", cap_to_text(caps, NULL));
execv(child_args[0], child_args);
return 1;
}
在主函数的clone()调用中加入我们熟悉的标识符:
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWuser | SIGCHLD, NULL);
//[...]
这里要先开启user namespace限制:
# echo 15000 > /proc/sys/user/max_user_namespaces
至此,第一部分的代码修改就结束了,将其另存为userns.c。然后开始编译运行,并进行新建的user namespace,会发现shell提示符前的用户名会变为“nobody”或者“I have no name!”,具体因操作系统而异。首先,我们先打印当前用户的uid和guid,请注意,此时显示的是普通用户:
# id -u 0 # id -g 0 # gcc userns.c -Wall -lcap -o userns.o && ./userns.o 程序开始: 在子进程中! eUID = 65534; eGID = 65534; capabilities: = cap_chown,cap_dac_override,[……],35,36+ep <<--此处省略部分输出,已拥有全部权限 /usr/bin/id: cannot find name for group ID 65534 /usr/bin/id: cannot find name for user ID 65534 [I have no name!@docker]$ id -u 65534 [I have no name!@docker]$ id -g 65534 [I have no name!@docker]$ exit exit 已退出 # id -u 0 # id -g 0
通过验证可以得到以下信息:
- user namespace被创建后,第一个进程被赋予了该namespace中的全部权限,这样该init进程就可以完成所有必要的初始化工作,而不会因权限不足而出现错误。
- 从namespace内部看到的UID和GID已经与外部不同了,默认显示为65534,表示尚未与外部namespace用户映射。此时需要对user namespace内部的这个初始user和它外部namespace某个用户建立映射,这样可以保证当涉及到一些对外部namespace的操作时,系统可以检验其权限(比如发送一个信号或操作某个文件)。同样用户组也要建立映射。
- 还有一点虽然不能从输出中看出来,但却值得注意。用户在新namespace中有全部权限,但它在创建它的父namespace中不含任何权限。就算调用和创建它的进程有全部权限也是如此。所以哪怕是root用户调用了clone()在user namespace中创建出的新用户在外部也没有任何权限。
- 最后,user namespace的创建其实是一个层层嵌套的树状结构。最上层的根节点就是root namespace,新创建的每个user namespace都有一个父节点user namespace以及零个或多个子节点user namespace,这一点与PID namespace非常相似。
从图1-3中可以看到,namespace实际上就是按层次关联起来,每个namespace都发源于最初的root namespace并与之建立映射。
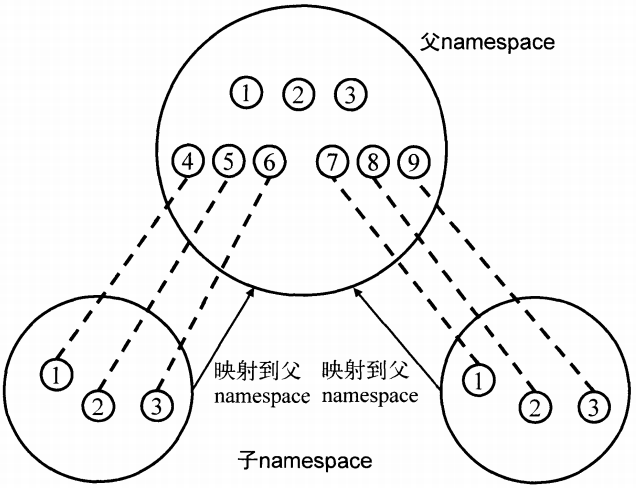
图1-3 namespace映射图
接下来就要进行用户绑定操作,通过在/proc/[pid]/uid_map和/proc/[pid]/gid_map两个文件中写入对应的绑定信息可以实现这一点,格式如下:
ID-inside-ns ID-outside-ns length
写这两个文件需要注意以下几点:
- 这两个文件只允许由拥有该user namespace中CAP_SETUID权限的进程写入一次,不允许修改。
- 写入的进程必须是该user namespace的父namespace或者子namespace。
- 第一个字段ID-inside-ns表示新建的user namespace中对应的user/group ID,第二个字段ID-outside-ns表示namespace外部映射的user/group ID。最后一个字段表示映射范围,通常填1,表示只映射一个,如果填大于1的值,则按顺序建立一一映射。
明白了上述原理,我们再次修改代码,添加设置uid和guid的函数:
void set_uid_map(pid_t pid, int inside_id, int outside_id, int length)
{
char path[256];
sprintf(path, "/proc/%d/uid_map", getpid());
FILE *uid_map = fopen(path, "w");
fprintf(uid_map, "%d %d %d", inside_id, outside_id, length);
fclose(uid_map);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int length)
{
char path[256];
sprintf(path, "/proc/%d/gid_map", getpid());
FILE *gid_map = fopen(path, "w");
fprintf(gid_map, "%d %d %d", inside_id, outside_id, length);
fclose(gid_map);
}
int child_main(void *args)
{
cap_t caps;
printf("在子进程中!\n");
set_uid_map(getpid(), 0, 1500, 1);
set_gid_map(getpid(), 0, 1500, 1);
printf("eUID = %ld; eGID = %ld; ",
(long)geteuid(), (long)getegid());
caps = cap_get_proc();
printf("capabilities: %s\n", cap_to_text(caps, NULL));
execv(child_args[0], child_args);
return 1;
}
这里,我们首先要创建一个ID为1500的用户和用户组,如果上述程序所指定ID所对应的用户和用户组不存在,程序将无法执行成功。另外,这里需要将用户bar将入到root用户组,否则上述程序也无法执行成功
# groupadd -g 1500 bar # useradd -u 1500 bar -g bar
# usermod -a -G root bar
然后,我们登陆bar用户,首先打印关于当前用户的id信息,再编译并运行上述的程序:
[bar@docker ~]$ id uid=1500(bar) gid=1500(bar) groups=1500(bar),0(root) # gcc userns.c -Wall -lcap -o main && ./main 程序开始: 在子进程中! eUID = 0; eGID = 65534; capabilities: = cap_chown,cap_dac_override……<<--此处省略部分输出 [root@docker ~]# id uid=0(root) gid=65534 groups=65534 [root@docker ~]# exit exit 已退出 [bar@docker ~]$
注:这里的gid并没有改动到,具体的原因笔者也在查找,如果有知道原因的大佬,希望能不吝赐教
至此,就已经完成了绑定的工作,可以看到演示全程都是在普通用户下执行的。最终实现了在user namespace中成为了root而对应到外面的是一个uid为1500的普通用户。
如果要把user namespace与其他namespace混合使用,那么依旧需要root权限。解决方案可以是先以普通用户身份创建user namespace,然后在新建的namespace中作为root,在clone()进程加入其他类型的namespace隔离。
讲解完user namespace,再来谈谈Docker。Docker不仅使用了user namespace,还使用了在user namespace中提及的Capabilities机制。从内核2.2版本开始,Linux把原来和超级用户相关的高级权限划分成为不同的单元,称为Capability。这样管理员就可以独立对特定的Capability进行使能或禁止。Docker同时使用user namespace和Capability,这在很大程度上加强容器安全性。
当然,说到安全,namespace的六项隔离看似全面,实际上依旧没有完全隔离Linux的资源,比如SELinux、 Cgroups以及/sys、/proc/sys、/dev/sd*等目录下的资源。关于安全的更多讨论和讲解,会在后面的章节中接着探讨。

