
如何爬取异步加载的数据(以腾讯新闻为例)
众所周知,最基本的记载方式分为两种。一种为同步,一种为异步。
那么该如何区分同步和异步呢???
教一个简单的方式。看一下左上角的刷新按钮,如果他动了就是同步,没变化就是异步(自己的认识方式)。
那么以腾讯新闻为例,她是一个妥妥的一个异步加载,并且返回的对象是一个json字符串格式。
打开抓包工具,选则响应模块,诶,你就会惊奇的发现,里面压根就没有你想要的的数据。那不是凉了。别急,这个时候就是XHR出马的时候啦,点击之后,选择与连接有点相似的数据包点击查看数据。

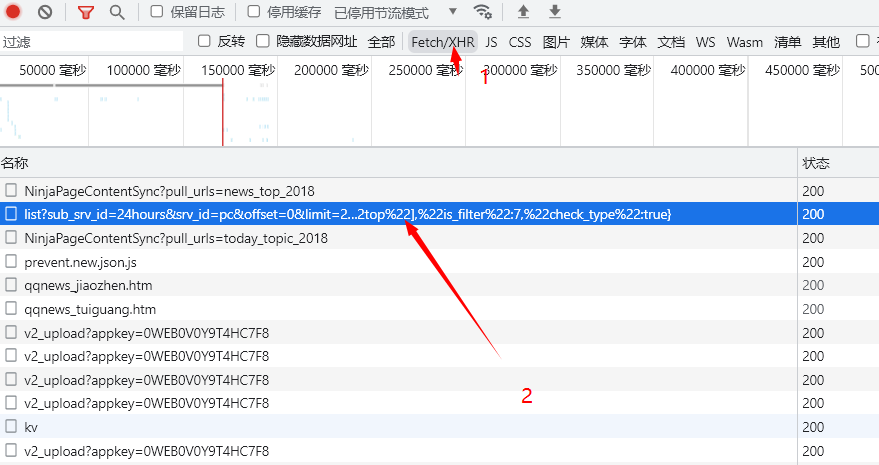
点击之后,可以在预览部分查看会否有需要的数据。如果有就说明数据包没有找错。
当你不断往下滑刷新页面后,这时就会出现上面2中,类似的url地址,只不过他的offset会发生变化
下面就是代码部分
url有所不同
import requests
from jsonpath import jsonpath # pip install jsonpath
from openpyxl import workbook
import sys
import random
from fake_useragent import UserAgent # pip install fake_useragent
ua = UserAgent() # 实例化对象
# print(ua.chrome)
# print(ua.random)
def get_data(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
r = requests.get(url, headers=headers)
data_json = r.json()
return data_json
def parse_data(data):
title = jsonpath(data, '$..title')
media_name = jsonpath(data, '$..media_name')
url = jsonpath(data, '$..url')
for titles, media_names, urls in zip(title, media_name, url):
print(titles)
print(media_names)
print(urls)
print('==' * 10)
save(titles, media_names, urls)
def save(title, media_name, url):
list = [title, media_name.url]
ws.append(list)
wb.save()
if __name__ == '__main__':
url = 'https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list'
wb = workbook.Workbook()
ws = wb.active
ws.append(['新闻', '媒体', '链接'])
for i in range(1, 11):
print('==正在下载参数为{}页=='.format(i))
data1 = {
'sub_srv_id': '24hours',
'srv_id': 'pc',
'offset': '{}'.format(i),
'limit': '20',
'strategy': '1',
'ext': '{"pool":["top"],"is_filter":7,"check_type":true}',
}
data = get_data(url)
parse_data(data)
#以上代码可用于练手。老手别弄了,怕你看不起我。。也可以不用函数式编程,自由切换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号