
scrapy爬取校花网信息
校花网的信息资源都可以在我们打印出来的响应对象中找到,所以说,校花网的加载方式是属于静态加载的,所以,我们就可以直接在scrapy框架中的爬虫文件档中将我们所需要的信息全部爬取下来。
1.新建一个scrapy项目文件
在我们的pycharm当中有一个Terminal,我们点击他,就回出现以下。
这里呢,我自己建了一个文件,名字叫做爬虫实战案列,用来存放项目。而在我的这个文件夹中,我再次建立了一个文件以便区分项目位置。如果你没有这个文件夹,就可以直接建立scrapy项目,在这里我还需要cd pc进入下一个文件夹位置才能创建。
那么下载就可以创建scrapy项目文件。
我们在上述的终端窗口,输入scrapy startproject myspider(项目名称)就会创建一个新的scrapy项目
然后我们就要进入项目myspider创建我们的爬虫文件
cd myspider
cd genspider xiaohua(爬虫名字) www.com(域名)
然后就会在spider中出现我们的爬虫文件
以下就是我们爬虫文件内部的内容
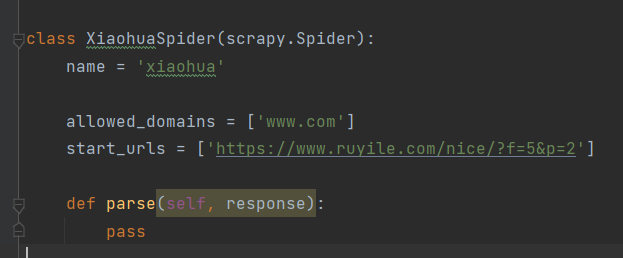
allowed_domains是我们的域名,用我自己的话来说就是爬取模块的首页地址
start_urls就是我们爬取板块的首页地址url。
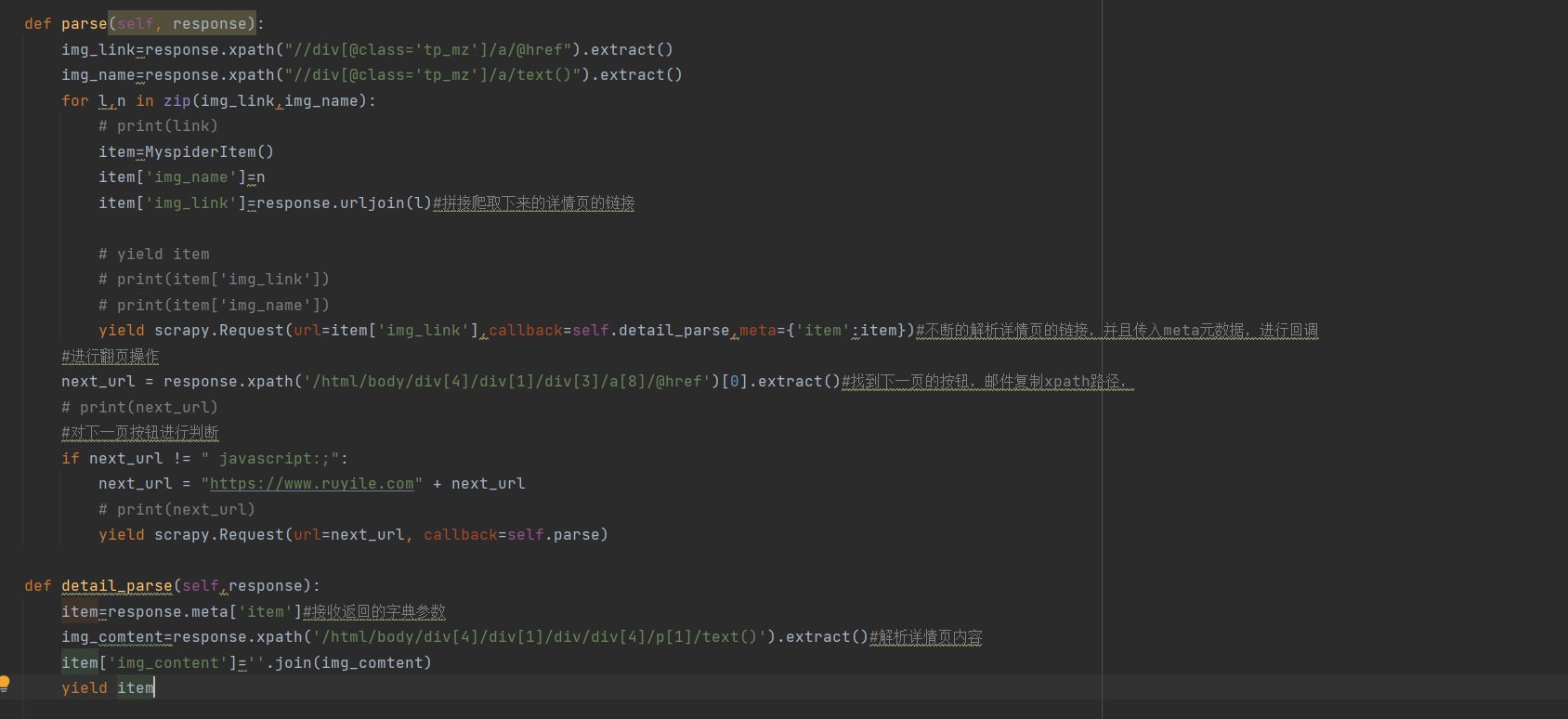
2.现在就要根据我们的需要爬取想要的内容,那么这里,我们是要爬取,每个页面任务的名字以及详情页的链接和详情页的内容。
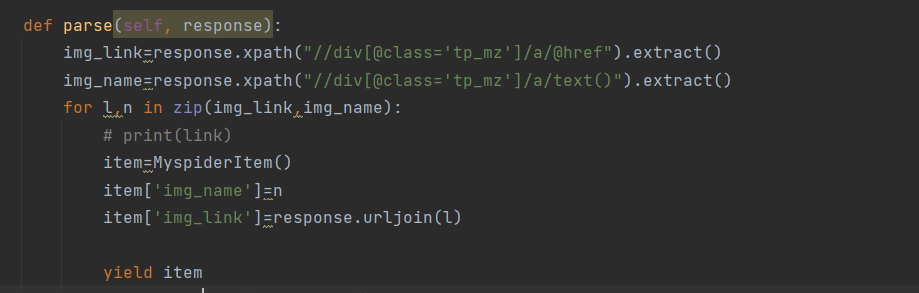
item=Myspider()是调用items.py的类来实例化一个字典用来存贮数据,所以还需要导入

下面就是完整代码过程
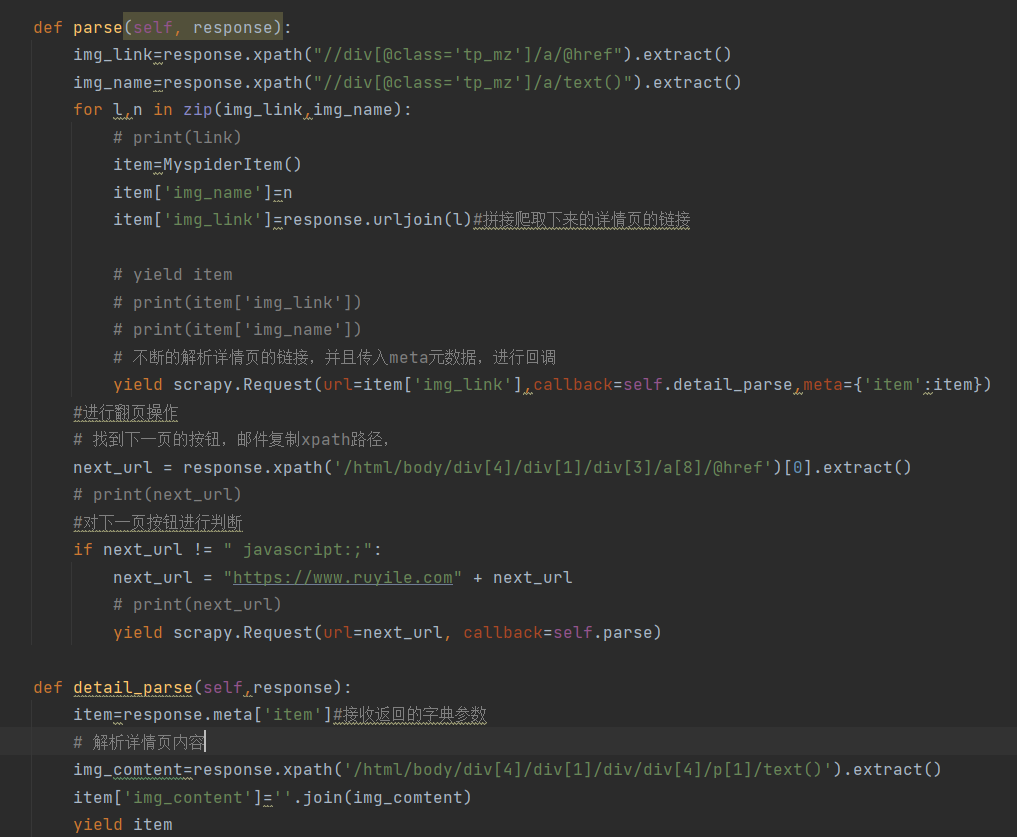
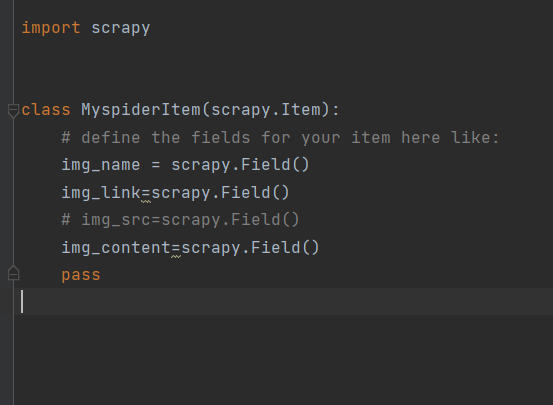
以下试讲爬取的内容保存在json中,
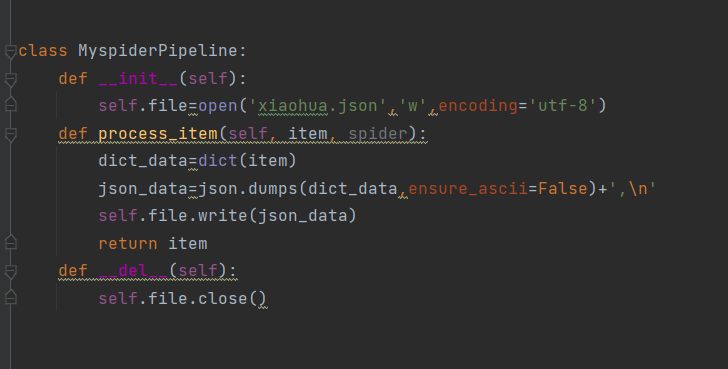
在setting.py设置一下管道


在终端进入我们的项目输入
scrapy crawl xiaohua
你就会发现,json文件中啥都没有,因为前面的域名,没有设置
所以需要将域名设置一下

然后就会发现,有东西了
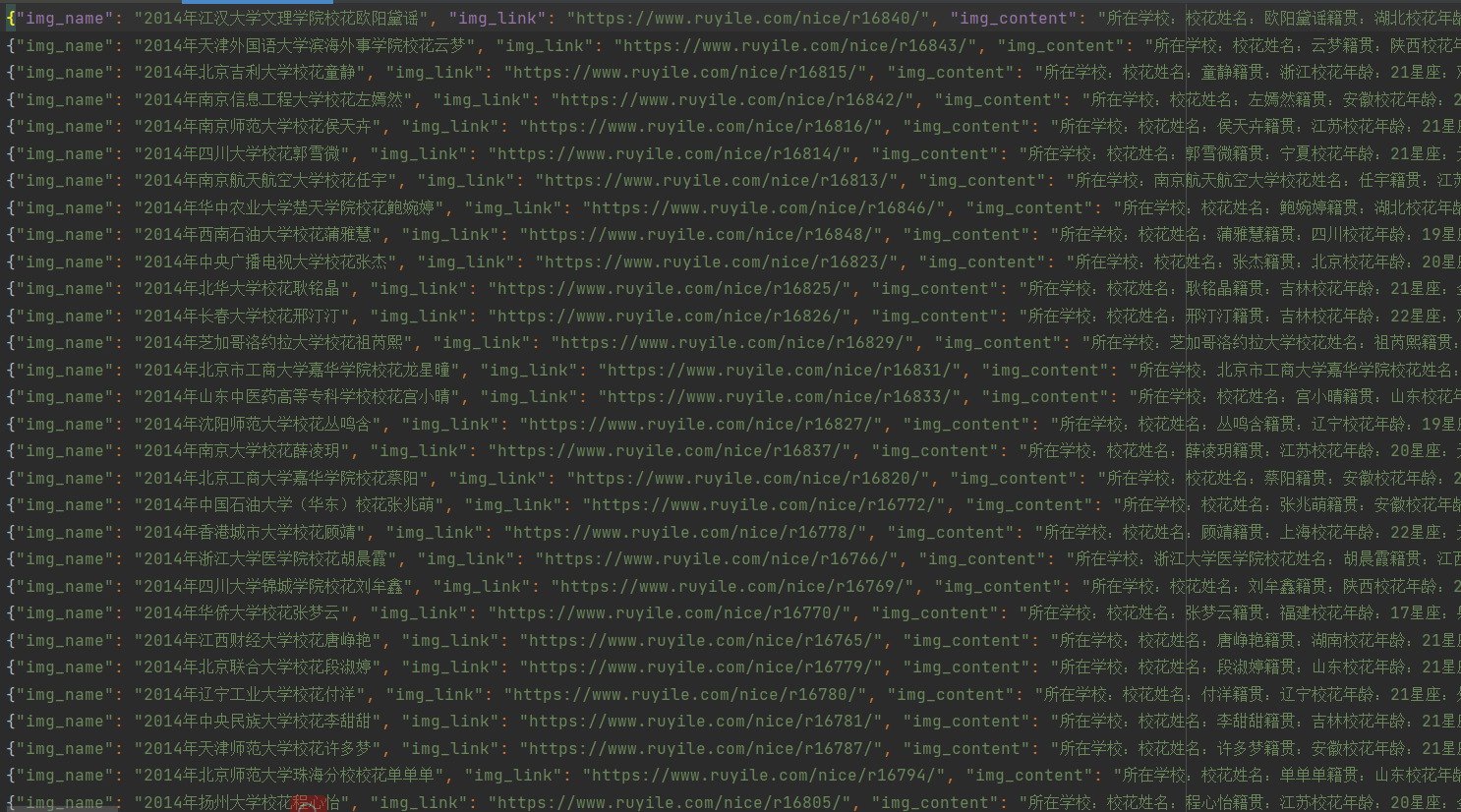
,今天就这样结束了,。小白所写,不喜勿喷。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号