python捕获异常及方法总结
调试Python程序时,经常会报出一些异常,异常的原因一方面可能是写程序时由于疏忽或者考虑不全造成了错误,这时就需要根据异常Traceback到出错点,进行分析改正;另一方面,有些异常是不可避免的,但我们可以对异常进行捕获处理,防止程序终止。
1 异常类型
1.1 Python内置异常
Python的异常处理能力是很强大的,它有很多内置异常,可向用户准确反馈出错信息。在Python中,异常也是对象,可对它进行操作。BaseException是所有内置异常的基类,但用户定义的类并不直接继承BaseException,所有的异常类都是从Exception继承,且都在exceptions模块中定义。Python自动将所有异常名称放在内建命名空间中,所以程序不必导入exceptions模块即可使用异常。一旦引发而且没有捕捉SystemExit异常,程序执行就会终止。如果交互式会话遇到一个未被捕捉的SystemExit异常,会话就会终止。
内置异常类的层次结构如下:
BaseException # 所有异常的基类
+-- SystemExit # 解释器请求退出
+-- KeyboardInterrupt # 用户中断执行(通常是输入^C)
+-- GeneratorExit # 生成器(generator)发生异常来通知退出
+-- Exception # 常规异常的基类
+-- StopIteration # 迭代器没有更多的值
+-- StopAsyncIteration # 必须通过异步迭代器对象的__anext__()方法引发以停止迭代
+-- ArithmeticError # 各种算术错误引发的内置异常的基类
| +-- FloatingPointError # 浮点计算错误
| +-- OverflowError # 数值运算结果太大无法表示
| +-- ZeroDivisionError # 除(或取模)零 (所有数据类型)
+-- AssertionError # 当assert语句失败时引发
+-- AttributeError # 属性引用或赋值失败
+-- BufferError # 无法执行与缓冲区相关的操作时引发
+-- EOFError # 当input()函数在没有读取任何数据的情况下达到文件结束条件(EOF)时引发
+-- ImportError # 导入模块/对象失败
| +-- ModuleNotFoundError # 无法找到模块或在在sys.modules中找到None
+-- LookupError # 映射或序列上使用的键或索引无效时引发的异常的基类
| +-- IndexError # 序列中没有此索引(index)
| +-- KeyError # 映射中没有这个键
+-- MemoryError # 内存溢出错误(对于Python 解释器不是致命的)
+-- NameError # 未声明/初始化对象 (没有属性)
| +-- UnboundLocalError # 访问未初始化的本地变量
+-- OSError # 操作系统错误,EnvironmentError,IOError,WindowsError,socket.error,select.error和mmap.error已合并到OSError中,构造函数可能返回子类
| +-- BlockingIOError # 操作将阻塞对象(e.g. socket)设置为非阻塞操作
| +-- ChildProcessError # 在子进程上的操作失败
| +-- ConnectionError # 与连接相关的异常的基类
| | +-- BrokenPipeError # 另一端关闭时尝试写入管道或试图在已关闭写入的套接字上写入
| | +-- ConnectionAbortedError # 连接尝试被对等方中止
| | +-- ConnectionRefusedError # 连接尝试被对等方拒绝
| | +-- ConnectionResetError # 连接由对等方重置
| +-- FileExistsError # 创建已存在的文件或目录
| +-- FileNotFoundError # 请求不存在的文件或目录
| +-- InterruptedError # 系统调用被输入信号中断
| +-- IsADirectoryError # 在目录上请求文件操作(例如 os.remove())
| +-- NotADirectoryError # 在不是目录的事物上请求目录操作(例如 os.listdir())
| +-- PermissionError # 尝试在没有足够访问权限的情况下运行操作
| +-- ProcessLookupError # 给定进程不存在
| +-- TimeoutError # 系统函数在系统级别超时
+-- ReferenceError # weakref.proxy()函数创建的弱引用试图访问已经垃圾回收了的对象
+-- RuntimeError # 在检测到不属于任何其他类别的错误时触发
| +-- NotImplementedError # 在用户定义的基类中,抽象方法要求派生类重写该方法或者正在开发的类指示仍然需要添加实际实现
| +-- RecursionError # 解释器检测到超出最大递归深度
+-- SyntaxError # Python 语法错误
| +-- IndentationError # 缩进错误
| +-- TabError # Tab和空格混用
+-- SystemError # 解释器发现内部错误
+-- TypeError # 操作或函数应用于不适当类型的对象
+-- ValueError # 操作或函数接收到具有正确类型但值不合适的参数
| +-- UnicodeError # 发生与Unicode相关的编码或解码错误
| +-- UnicodeDecodeError # Unicode解码错误
| +-- UnicodeEncodeError # Unicode编码错误
| +-- UnicodeTranslateError # Unicode转码错误
+-- Warning # 警告的基类
+-- DeprecationWarning # 有关已弃用功能的警告的基类
+-- PendingDeprecationWarning # 有关不推荐使用功能的警告的基类
+-- RuntimeWarning # 有关可疑的运行时行为的警告的基类
+-- SyntaxWarning # 关于可疑语法警告的基类
+-- UserWarning # 用户代码生成警告的基类
+-- FutureWarning # 有关已弃用功能的警告的基类
+-- ImportWarning # 关于模块导入时可能出错的警告的基类
+-- UnicodeWarning # 与Unicode相关的警告的基类
+-- BytesWarning # 与bytes和bytearray相关的警告的基类
+-- ResourceWarning # 与资源使用相关的警告的基类。被默认警告过滤器忽略。
详细说明请参考:https://docs.python.org/3/library/exceptions.html#base-classes
1.2 requests模块的相关异常
在做爬虫时,requests是一个十分好用的模块,所以我们在这里专门探讨一下requests模块相关的异常。
要调用requests模块的内置异常,只要“from requests.exceptions import xxx”就可以了,比如:
from requests.exceptions import ConnectionError, ReadTimeout
或者直接这样也是可以的:
from requests import ConnectionError, ReadTimeout
requests模块内置异常类的层次结构如下:
IOError
+-- RequestException # 处理不确定的异常请求
+-- HTTPError # HTTP错误
+-- ConnectionError # 连接错误
| +-- ProxyError # 代理错误
| +-- SSLError # SSL错误
| +-- ConnectTimeout(+-- Timeout) # (双重继承,下同)尝试连接到远程服务器时请求超时,产生此错误的请求可以安全地重试。
+-- Timeout # 请求超时
| +-- ReadTimeout # 服务器未在指定的时间内发送任何数据
+-- URLRequired # 发出请求需要有效的URL
+-- TooManyRedirects # 重定向太多
+-- MissingSchema(+-- ValueError) # 缺少URL架构(例如http或https)
+-- InvalidSchema(+-- ValueError) # 无效的架构,有效架构请参见defaults.py
+-- InvalidURL(+-- ValueError) # 无效的URL
| +-- InvalidProxyURL # 无效的代理URL
+-- InvalidHeader(+-- ValueError) # 无效的Header
+-- ChunkedEncodingError # 服务器声明了chunked编码但发送了一个无效的chunk
+-- ContentDecodingError(+-- BaseHTTPError) # 无法解码响应内容
+-- StreamConsumedError(+-- TypeError) # 此响应的内容已被使用
+-- RetryError # 自定义重试逻辑失败
+-- UnrewindableBodyError # 尝试倒回正文时,请求遇到错误
+-- FileModeWarning(+-- DeprecationWarning) # 文件以文本模式打开,但Requests确定其二进制长度
+-- RequestsDependencyWarning # 导入的依赖项与预期的版本范围不匹配
Warning
+-- RequestsWarning # 请求的基本警告
详细说明及源码请参考:http://www.python-requests.org/en/master/_modules/requests/exceptions/#RequestException
下面是一个简单的小例子,python内置了一个ConnectionError异常,这里可以不用再从requests模块import了:
import requests
from requests import ReadTimeout
def get_page(url):
try:
response = requests.get(url, timeout=1)
if response.status_code == 200:
return response.text
else:
print('Get Page Failed', response.status_code)
return None
except (ConnectionError, ReadTimeout):
print('Crawling Failed', url)
return None
def main():
url = 'https://www.baidu.com'
print(get_page(url))
if __name__ == '__main__':
main()
1.3 用户自定义异常
此外,你也可以通过创建一个新的异常类拥有自己的异常,异常应该是通过直接或间接的方式继承自Exception类。下面创建了一个MyError类,基类为Exception,用于在异常触发时输出更多的信息。
在try语句块中,抛出用户自定义的异常后执行except部分,变量 e 是用于创建MyError类的实例。
class MyError(Exception):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
try:
raise MyError('类型错误')
except MyError as e:
print('My exception occurred', e.msg)
2. 异常捕获
当发生异常时,我们就需要对异常进行捕获,然后进行相应的处理。python的异常捕获常用try...except...结构,把可能发生错误的语句放在try模块里,用except来处理异常,每一个try,都必须至少对应一个except。此外,与python异常相关的关键字主要有:
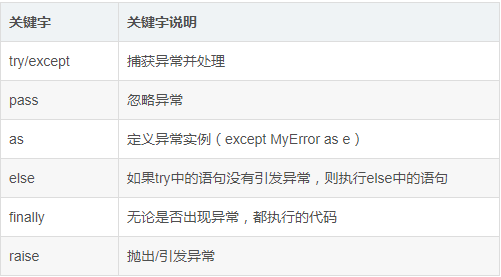
2.1 捕获所有异常
包括键盘中断和程序退出请求(用sys.exit()就无法退出程序了,因为异常被捕获了),因此慎用。
try:
<语句>
except:
print('异常说明')
2.2 捕获指定异常
try:
<语句>
except <异常名>:
print('异常说明')
万能异常:
try:
<语句>
except Exception:
print('异常说明')
一个例子:
try:
f = open("file-not-exists", "r")
except IOError as e:
print("open exception: %s: %s" %(e.errno, e.strerror))
2.3 捕获多个异常
捕获多个异常有两种方式,第一种是一个except同时处理多个异常,不区分优先级:
try:
<语句>
except (<异常名1>, <异常名2>, ...):
print('异常说明')
第二种是区分优先级的:
try:
<语句>
except <异常名1>:
print('异常说明1')
except <异常名2>:
print('异常说明2')
except <异常名3>:
print('异常说明3')
该种异常处理语法的规则是:
执行try下的语句,如果引发异常,则执行过程会跳到第一个except语句。
如果第一个except中定义的异常与引发的异常匹配,则执行该except中的语句。
如果引发的异常不匹配第一个except,则会搜索第二个except,允许编写的except数量没有限制。
如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。
2.4 异常中的else
如果判断完没有某些异常之后还想做其他事,就可以使用下面这样的else语句。
try:
<语句>
except <异常名1>:
print('异常说明1')
except <异常名2>:
print('异常说明2')
else:
<语句> # try语句中没有异常则执行此段代码
2.5 异常中的finally
try...finally...语句无论是否发生异常都将会执行最后的代码。
try:
<语句>
finally:
<语句>
看一个示例:
str1 = 'hello world'
try:
int(str1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
else:
print('try内没有异常')
finally:
print('无论异常与否,都会执行我')
2.6 raise主动触发异常
可以使用raise语句自己触发异常,raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中Exception是异常的类型(例如ValueError),参数是一个异常参数值。该参数是可选的,如果不提供,异常的参数是"None"。最后一个参数是跟踪异常对象,也是可选的(在实践中很少使用)。
看一个例子:
def not_zero(num):
try:
if num == 0:
raise ValueError('参数错误')
return num
except Exception as e:
print(e)
not_zero(0)
2.7 采用traceback模块查看异常
发生异常时,Python能“记住”引发的异常以及程序的当前状态。Python还维护着traceback(跟踪)对象,其中含有异常发生时与函数调用堆栈有关的信息。记住,异常可能在一系列嵌套较深的函数调用中引发。程序调用每个函数时,Python会在“函数调用堆栈”的起始处插入函数名。一旦异常被引发,Python会搜索一个相应的异常处理程序。如果当前函数中没有异常处理程序,当前函数会终止执行,Python会搜索当前函数的调用函数,并以此类推,直到发现匹配的异常处理程序,或者Python抵达主程序为止。这一查找合适的异常处理程序的过程就称为“堆栈辗转开解”(StackUnwinding)。解释器一方面维护着与放置堆栈中的函数有关的信息,另一方面也维护着与已从堆栈中“辗转开解”的函数有关的信息。
格式如下:
try:
block
except:
traceback.print_exc()
举个例子:
try:
1/0
except Exception as e:
print(e)
如果我们这样写的话,程序只会报“division by zero”错误,但是我们并不知道是在哪个文件哪个函数哪一行出的错。
下面使用traceback模块,官方参考文档:https://docs.python.org/2/library/traceback.html
import traceback
try:
1/0
except Exception as e:
traceback.print_exc()
这样就会帮我们追溯到出错点:
Traceback (most recent call last):
File "E:/PycharmProjects/ProxyPool-master/proxypool/test.py", line 4, in <module>
1/0
ZeroDivisionError: division by zero
另外,traceback.print_exc()跟traceback.format_exc()有什么区别呢?
区别就是,format_exc()返回字符串,print_exc()则直接给打印出来。即traceback.print_exc()与print(traceback.format_exc())效果是一样的。print_exc()还可以接受file参数直接写入到一个文件。比如可以像下面这样把相关信息写入到tb.txt文件去。
traceback.print_exc(file=open('tb.txt','w+'))
原文:https://blog.csdn.net/polyhedronx/article/details/81589196

 浙公网安备 33010602011771号
浙公网安备 33010602011771号