
软工实践|结对第二次—文献摘要热词统计及进阶需求
格式描述 ----------- - 这个作业属于哪个课程:[软件工程实践](https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W) - 这个作业要求在哪里:[作业要求](https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W/homework/2688) - 结对学号: [221600434吴何](https://www.cnblogs.com/beifeng5620/p/10493547.html) [221500318陈一聪](https://www.cnblogs.com/qq705599500/p/10498436.html) - github: [221600434&221500318基本需求](https://github.com/beifeng5620/PairProject1-Java) [221600434&221500318进阶需求](https://github.com/beifeng5620/PairProject2-Java) - 这个作业的目标: **一、基本需求:实现一个能够对文本文件中的单词的词频进行统计的控制台程序。** **二、进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器。**
一、WordCount基本需求 -------------------------------- ###1.思路分析 - 读取字符采用逐个读取文件流,判断是否符合要求(根据题目要求选择不读CR(ASCII码值为13))再计数。或者按行读取后再转化为chararray数组后逐个判断?(这种方式会省略换行) - 因为要读取单词,所以使用正则表达式来匹配单词,并过滤掉非法字符,以单词-频率作为键值对保存在TreeMap中,TreeMap会根据键的字典序自动升序排列,所以后面只要再实现按照频率优先的排序算法即可。 - 行数统计直接按行读取后使用trim()去掉空白字符后,再进行判断计数即可。
2.设计过程
分为多个函数块,各自实现一部分功能,对于统计单词总数和统计单词频率可以合并在一个函数里。
计划分割为:CharactersNum(file)实现字符统计,linesNum(file)实现行数统计,wordsNum(file)实现单词和频率统计,writeResult(infile,outfile)实现输出。
对于每个函数模块,首先实现基本的功能,再考虑边缘条件,逐步优化函数。
在对函数进行接口封装时,发现如果统计单词总数和统计单词频率放在一起,则粒度太大,不好按格式输出,也无法使用其中之一功能,所以后面拆为wordsNum(file)统计单词总数,wordMap(file)保存每个单词的频率,再用writeMostWords(file)按照<word>: num格式输出结果。虽然增加了一次文件读入,但降低了耦合度,是可以接受的。
-
基本需求类图

-
主要函数wordMap流程图
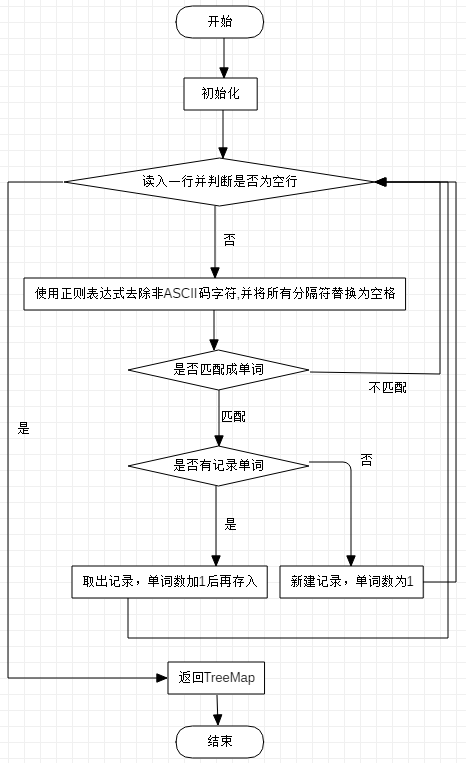
2.关键代码
- 统计文件的字符数
public static int charactersNum(String filename) throws IOException {
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
int value = -1;
while ((value = br.read()) != -1) {
if (value > 0 && value < 128 && value != 13) {
num ++;
}
}
br.close();
return num;
}
- 统计文件的有效行数
public static int linesNum(String filename) throws IOException {
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
String line = null;
while ((line = br.readLine()) != null) {
if (line.trim().length() != 0) {
num ++;
}
}
br.close();
return num;
}
- 统计文件的单词个数
public static int wordsNum(String filename) throws IOException {
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
String separator = "[^A-Za-z0-9]";//分隔符
String regex = "^[A-Za-z]{4,}[0-9]*$"; // 正则判断每个数组中是否存在有效单词
Pattern p = Pattern.compile(regex);
Matcher m = null;
String line = null;
String[] array = null;
while ((line = br.readLine()) != null) {
line = line.replaceAll("[(\\u4e00-\\u9fa5)]", "");// 过滤汉字
line = line.replaceAll(separator, " "); // 用空格替换分隔符
array = line.split("\\s+"); // 按空格分割
for (int i = 0;i<array.length;i++) {
m = p.matcher(array[i]);
if (m.matches()) {
num++;
}
}
}
br.close();
return num;
}
- 统计文件的热词数
public static TreeMap<String, Integer> wordMap(String filename) throws IOException {
// 第一种方法遍历
// 使用entrySet()方法生成一个由Map.entry对象组成的Set,
// 而Map.entry对象包括了每个元素的"键"和"值".这样就可以用iterator了
// Iterator<Entry<String, Integer>> it = tm.entrySet().iterator();
// while (it.hasNext()) {
// Map.Entry<String, Integer> entry =(Map.Entry<String, Integer>) it.next();
// String key = entry.getKey();
// Integer value=entry.getValue();
//
// System.out.println("<" + key + ">:" + value);
// }
TreeMap<String, Integer> tm = new TreeMap<String, Integer>();
BufferedReader br = new BufferedReader(new FileReader(filename));
String separator = "[^A-Za-z0-9]";//分隔符
String regex = "^[A-Za-z]{4,}[0-9]*$"; // 正则判断每个数组中是否存在有效单词
Pattern p = Pattern.compile(regex);
String str = null;
Matcher m = null;
String line = null;
String[] array = null;
while ((line = br.readLine()) != null) {
line = line.replaceAll("[(\\u4e00-\\u9fa5)]", "");// 过滤汉字
line = line.replaceAll(separator, " "); // 用空格替换分隔符
array = line.split("\\s+"); // 按空格分割
for (int i = 0;i<array.length;i++) {
m = p.matcher(array[i]);
if (m.matches()) {
str = array[i].toLowerCase();
if (!tm.containsKey(str)) {
tm.put(str, 1);
} else {
int count = tm.get(str) + 1;
tm.put(str, count);
}
}
}
}
br.close();
return tm;
}
- 单词排序输出
public static void writeMostWords(String infilename,String outfilename) throws IOException {
String outpath = new File(outfilename).getAbsolutePath();
FileWriter fw = new FileWriter(outpath, true);
TreeMap<String, Integer> tm = wordMap(infilename);
if(tm != null && tm.size()>=1)
{
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(tm.entrySet());
// 通过比较器来实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
//treemap默认按照键的字典序升序排列的,所以list也是排过序的,在值相同的情况下不用再给键升序排列
// 按照值降序排序
return o2.getValue().compareTo(o1.getValue());
}
});
int i = 1;
String key = null;
Integer value = null;
for (Map.Entry<String, Integer> mapping : list) {
key = mapping.getKey();
value = mapping.getValue();
System.out.print("<" + key + ">: " + value + '\n');
fw.write("<" + key + ">: " + value + '\n');
//只输出前10个
if (i == 10) {
break;
}
i++;
}
}
fw.close();
}
3.测试分析
可以看到按行读取花费时间较长
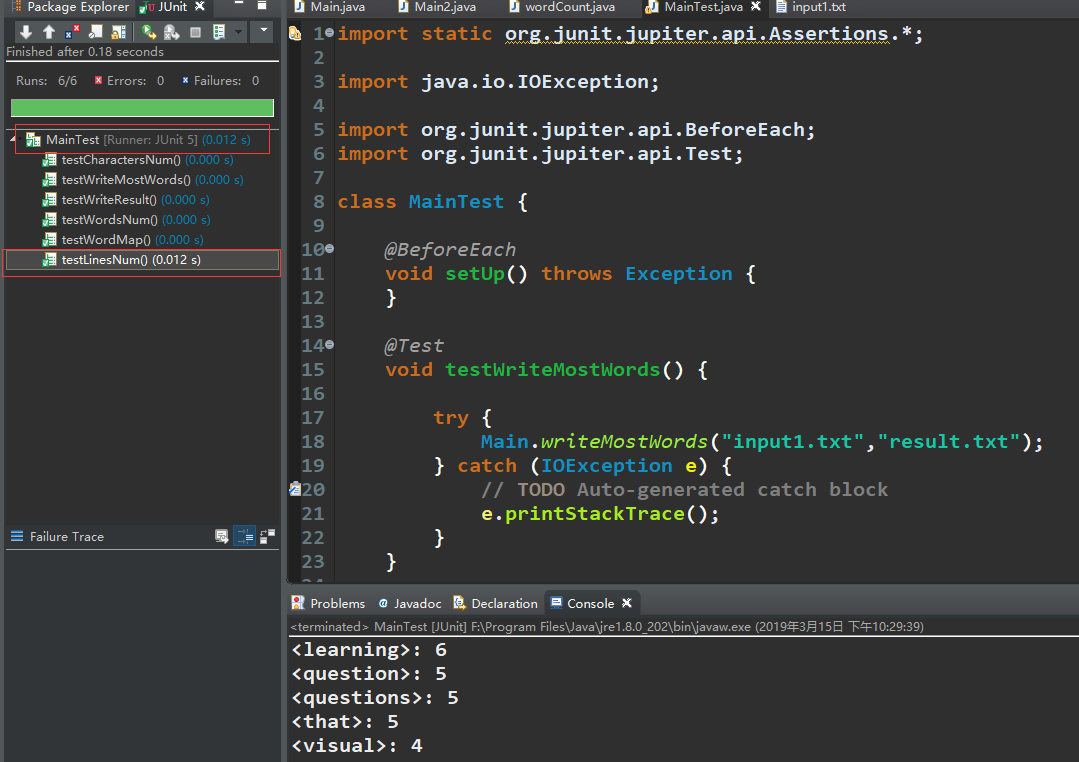
4.困难与解决
- 统计文件字符数时,原本是打算按行读取后直接用line.Length来计算字符数,后来发现比测试样例要少,原因是readLine()不读取行末换行,采用read()逐个读取后问题解决。
- 单词排序时,对于TreeMap<String,Integer>类型没有找到对应的排序接口Comparator<Entry<String, Integer>>(),后面将TreeMap保存到list中使用Collections接口调用排序得以解决。
- 使用命令行编译时,由于一开始的项目在SRC目录下有包,.java文件在包里,所以javac 命令要进入到.java文件目录也就是最里层才可以,生成的.class文件和.java文件在同一目录。而使用java命令时,则要进到SRC目录下,包名作为前缀名来使用,并且名称不带后缀,格式如:java 包名.java文件名 才可以运行。后面项目使用默认包名不需要包名前缀。
- 如果项目使用了别的.jar包,则要BuildPath->Add to buildPath到Referenced Libraries文件夹,才可以在IDE下编译运行,在命令行下按照上述方式会出现错误: 程序包xxx不存在,查资料后说要使用-classpath 选项添加.jar文件路径或者-cp选项添加添加.jar文件路径才能解决,尝试了多次都不行,后面只好用IDE自带的命令行参数输入工具来模拟输入。
- 统计文件的有效行数
public static int linesNum(String filename) throws IOException {
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
String regex = "[0-9]*"; // 匹配数字编号行
Pattern p = Pattern.compile(regex);
Matcher m = null;
String line = null;
while ((line = br.readLine()) != null) {
m = p.matcher(line);
if (line.trim().length() != 0 && !m.matches()) {
num ++;
}
}
br.close();
return num;
}
- 统计文件的单词个数
public static int wordsNum(String filename,boolean w) throws IOException {
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
String separator = "[^A-Za-z0-9]";//分隔符
String regex = "^[A-Za-z]{4,}[0-9]*$"; // 正则判断每个数组中是否存在有效单词
String titleRegex = "Title: .*";
String abstractRegex = "Abstract: .*";
Pattern p = Pattern.compile(regex);
Pattern tp = Pattern.compile(titleRegex);
Pattern ap = Pattern.compile(abstractRegex);
Matcher m = null;
Matcher titleMacher = null;
Matcher abstractMacher = null;
String line = null;
String[] array = null;
boolean intitle = false;
while ((line = br.readLine()) != null) {
titleMacher = tp.matcher(line);
abstractMacher = ap.matcher(line);
if (titleMacher.matches()) {
line = deleteSubString(line,"Title: ");
intitle = true;
}
if (abstractMacher.matches()) {
line = deleteSubString(line,"Abstract: ");
}
line = line.replaceAll("[(\\u4e00-\\u9fa5)]", "");// 过滤汉字
line = line.replaceAll(separator, " "); // 用空格替换分隔符
array = line.split("\\s+"); // 按空格分割
for (int i = 0;i<array.length;i++) {
m = p.matcher(array[i]);
if (m.matches()) {
num = (w && intitle)?(num+10):(num+1);
}
}
intitle = false;
}
br.close();
return num;
}
- 统计文件的热词数
public static TreeMap<String, Integer> wordMap(String filename,boolean w) throws IOException {
TreeMap<String, Integer> tm = new TreeMap<String, Integer>();
BufferedReader br = new BufferedReader(new FileReader(filename));
String separator = "[^A-Za-z0-9]";//分隔符
String regex = "^[A-Za-z]{4,}[0-9]*$"; // 正则判断每个数组中是否存在有效单词
String titleRegex = "Title: .*";
String abstractRegex = "Abstract: .*";
Pattern p = Pattern.compile(regex);
Pattern tp = Pattern.compile(titleRegex);
Pattern ap = Pattern.compile(abstractRegex);
Matcher m = null;
Matcher titleMacher = null;
Matcher abstractMacher = null;
String str = null;
String line = null;
String[] array = null;
boolean intitle = false;
while ((line = br.readLine()) != null) {
titleMacher = tp.matcher(line);
abstractMacher = ap.matcher(line);
if (titleMacher.matches()) {
line = deleteSubString(line,"Title: ");
intitle = true;
}
if (abstractMacher.matches()) {
line = deleteSubString(line,"Abstract: ");
}
line = line.replaceAll("[(\\u4e00-\\u9fa5)]", "");// 用空格替换汉字
line = line.replaceAll(separator, " "); // 用空格替换分隔符
array = line.split("\\s+"); // 按空格分割
for (int i = 0;i<array.length;i++) {
m = p.matcher(array[i]);
if (m.matches()) {
str = array[i].toLowerCase();
if (!tm.containsKey(str)) {
tm.put(str, w&&intitle?10:1);
} else {
int count = tm.get(str) + (w&&intitle?10:1);
tm.put(str, count);
}
}
}
intitle = false;
}
br.close();
return tm;
}
- 单词排序输出
public static void writeMostWords(String infilename,String outfilename,boolean w,int n) throws IOException {
String outpath = new File(outfilename).getAbsolutePath();
FileWriter fw = new FileWriter(outpath, true);
TreeMap<String, Integer> tm = wordMap(infilename,w);
if(tm != null && tm.size()>=1)
{
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(tm.entrySet());
// 通过比较器来实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
//treemap默认按照键的字典序升序排列的,所以list也是排过序的,在值相同的情况下不用再给键升序排列
// 按照值降序排序
return o2.getValue().compareTo(o1.getValue());
}
});
int i = 1;
String key = null;
Integer value = null;
for (Map.Entry<String, Integer> mapping : list) {
if (n == 0) {
break;
}
key = mapping.getKey();
value = mapping.getValue();
System.out.print("<" + key + ">: " + value + '\n');
fw.write("<" + key + ">: " + value + '\n');
//只输出前n个
if (i == n) {
break;
}
i++;
}
}
fw.close();
}
- 裁剪字符串
public static String deleteSubString(String str1,String str2) {
StringBuffer sb = new StringBuffer(str1);
while (true) {
int index = sb.indexOf(str2);
if(index == -1) {
break;
}
sb.delete(index, index+str2.length());
}
return sb.toString();
}
- 实现命令行参数任意顺序组合输入
public static void main(String[] args) throws Exception {
CommandLineParser parser = new GnuParser();
Options options = new Options();
options.addOption("i",true,"读入文件名");
options.addOption("o",true,"输出文件名");
options.addOption("w",true,"单词权重");
options.addOption("m",true,"词组词频统计");
options.addOption("n",true,"频率最高的n行单词或词组");
CommandLine commandLine = parser.parse(options, args);
if (commandLine.hasOption("i") && commandLine.hasOption("o") && commandLine.hasOption("w")) {
String infilename = commandLine.getOptionValue("i");
String outfilename = commandLine.getOptionValue("o");
String w = commandLine.getOptionValue("w");
if (commandLine.hasOption("n")) {
String n = commandLine.getOptionValue("n");
if (isNumeric(n)) {
if (w.equals("1")) {
writeResult(infilename,outfilename,true,Integer.valueOf(n));
}
else {
writeResult(infilename,outfilename,false,Integer.valueOf(n));
}
}
else {
System.out.println("-n [0<=number<=100]");
}
}
else {
if (w.equals("1")) {
writeResult(infilename,outfilename,true,10);
}
else {
writeResult(infilename,outfilename,false,10);
}
}
}
else {
System.out.print("必须有-i -o -w选项和参数");
}
}
- 其他函数
public static boolean isNumeric(String str){
Pattern pattern = Pattern.compile("[0-9]*");
return pattern.matcher(str).matches();
}
public static void initTxt(String string) throws IOException {
String path = new File(string).getAbsolutePath();
FileWriter fw = new FileWriter(path, false);
fw.write("");
fw.flush();
fw.close();
}
public static void writeResult(String infilename,String outfilename,boolean w,int n) throws IOException {
File file = new File(infilename);
if (file.exists()) {
initTxt(outfilename);
String outpath = new File(outfilename).getAbsolutePath();
FileWriter fw = new FileWriter(outpath, true);
int charactersNum = charactersNum(infilename);
int wordsNum = wordsNum(infilename,w);
int linesNum = linesNum(infilename);
System.out.print("characters: " + charactersNum + '\n');
System.out.print("words: " + wordsNum + '\n');
System.out.print("lines: " + linesNum + '\n');
fw.write("characters: " + charactersNum + '\n');
fw.write("words: " + wordsNum + '\n');
fw.write("lines: " + linesNum + '\n');
fw.flush();
writeMostWords(infilename,outfilename,w,n);
if (fw != null) {
fw.close();
}
}
else {
System.out.println(infilename + "文件不存在!");
}
}
3.测试分析
与基础需求一致,主要是读行和读字符开销大
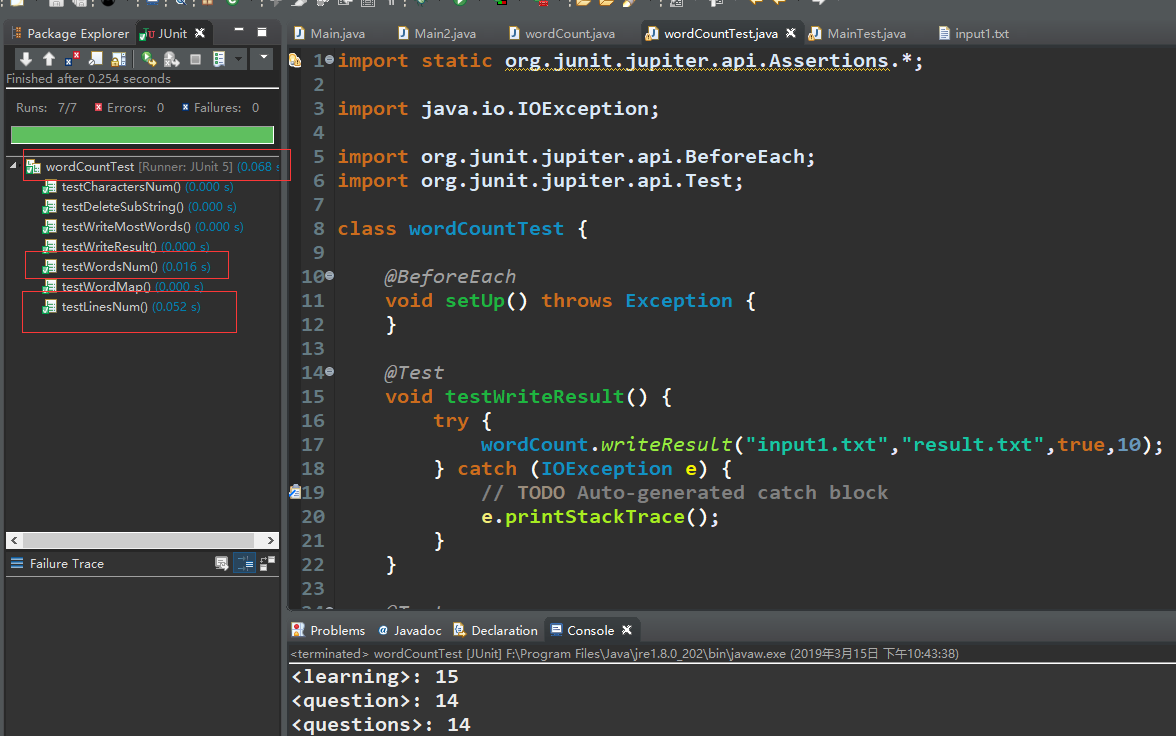
4.困难与解决
爬取的论文数据有非ascii码字符导致显示和统计不正确,使用正则表达式[^\x00-\xff]过滤后解决。使用单线程爬取速度太慢,多线程爬取这位同学已解决。
三、心得总结和评价
221600434吴何
虽然要求实现的东西也简单,但是也花了不少时间,有时候被一些小细节问题打扰,为了解决问题,查了不少资料,从而影响到整个的编码的流畅度,特别是花了不少时间而问题又没有解决时,简直是一种折磨。不过还好,想法最终都得以顺利实现。也学到了额外的知识,比如爬虫工具jsoup的使用,github的代码管理以及单元测试等。
不得不说的是,感觉自身的理解能力还不太行,花了比较多时间才大致明白了要实现的功能。
评价队友:有比较强的学习动力,也乐于交流,求知欲强。
221500318陈一聪
当最终所有问题顺利解决时,看到自己提交完成的作业也特别有成就感,遇到不懂的问题最后也一一解决,学到了很多知识。
花了很多时间才最后完成,觉得自己还有很多进步的空间,也比较庆幸有一个队友,帮助我理解和编程。
评价队友:有比较强的编程能力,有耐心,有进取心。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 610 | 630 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 90 |
| • Design Spec | • 生成设计文档 | 20 | 10 |
| • Design Review | • 设计复审 | 20 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 120 | 250 |
| • Coding | • 具体编码 | 640 | 720 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 10 | 15 |
| • Size Measurement | • 计算工作量 | 15 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 25 |
| 合计 | 975 | 1240 | |
