
校招前端一面经典react面试题(附答案)
React.forwardRef是什么?它有什么作用?
React.forwardRef 会创建一个React组件,这个组件能够将其接受的 ref 属性转发到其组件树下的另一个组件中。这种技术并不常见,但在以下两种场景中特别有用:
- 转发 refs 到 DOM 组件
- 在高阶组件中转发 refs
跨级组件的通信方式?
父组件向子组件的子组件通信,向更深层子组件通信:
- 使用props,利用中间组件层层传递,但是如果父组件结构较深,那么中间每一层组件都要去传递props,增加了复杂度,并且这些props并不是中间组件自己需要的。
- 使用context,context相当于一个大容器,可以把要通信的内容放在这个容器中,这样不管嵌套多深,都可以随意取用,对于跨越多层的全局数据可以使用context实现。
// context方式实现跨级组件通信
// Context 设计目的是为了共享那些对于一个组件树而言是“全局”的数据
const BatteryContext = createContext();
// 子组件的子组件
class GrandChild extends Component {
render(){
return (
<BatteryContext.Consumer>
{ color => <h1 style={{"color":color}}>我是红色的:{color}</h1>
} </BatteryContext.Consumer>
)
}
}
// 子组件
const Child = () =>{
return (
<GrandChild/>
)
}
// 父组件
class Parent extends Component {
state = {
color:"red"
}
render(){
const {color} = this.state
return (
<BatteryContext.Provider value={color}>
<Child></Child>
</BatteryContext.Provider>
)
}
}
如果用索引值作为key 会出现什么样的问题
-
若对数据进行逆序添加,逆序删除等破坏顺序的操作
则会产生没有必要的真实DOM更新,界面想过看不出区别,但是效力低,性能不好
-
如果结构中还包含输入类的DOM
会产生错误的DOM 更新===》界面会有问题
如果不存在对数据的逆序添加 逆序删除等破坏顺序操作,仅用于渲染展示,用index作为key也没有问题
如何告诉 React 它应该编译生产环境版
通常情况下我们会使用
Webpack的DefinePlugin方法来将NODE_ENV变量值设置为production。编译版本中React会忽略propType验证以及其他的告警信息,同时还会降低代码库的大小,React使用了Uglify插件来移除生产环境下不必要的注释等信息
React实现的移动应用中,如果出现卡顿,有哪些可以考虑的优化方案
- 增加
shouldComponentUpdate钩子对新旧props进行比较,如果值相同则阻止更新,避免不必要的渲染,或者使用PureReactComponent替代Component,其内部已经封装了shouldComponentUpdate的浅比较逻辑 - 对于列表或其他结构相同的节点,为其中的每一项增加唯一
key属性,以方便React的diff算法中对该节点的复用,减少节点的创建和删除操作 render函数中减少类似onClick={() => {doSomething()}}的写法,每次调用render函数时均会创建一个新的函数,即使内容没有发生任何变化,也会导致节点没必要的重渲染,建议将函数保存在组件的成员对象中,这样只会创建一次- 组件的
props如果需要经过一系列运算后才能拿到最终结果,则可以考虑使用reselect库对结果进行缓存,如果props值未发生变化,则结果直接从缓存中拿,避免高昂的运算代价 webpack-bundle-analyzer分析当前页面的依赖包,是否存在不合理性,如果存在,找到优化点并进行优化
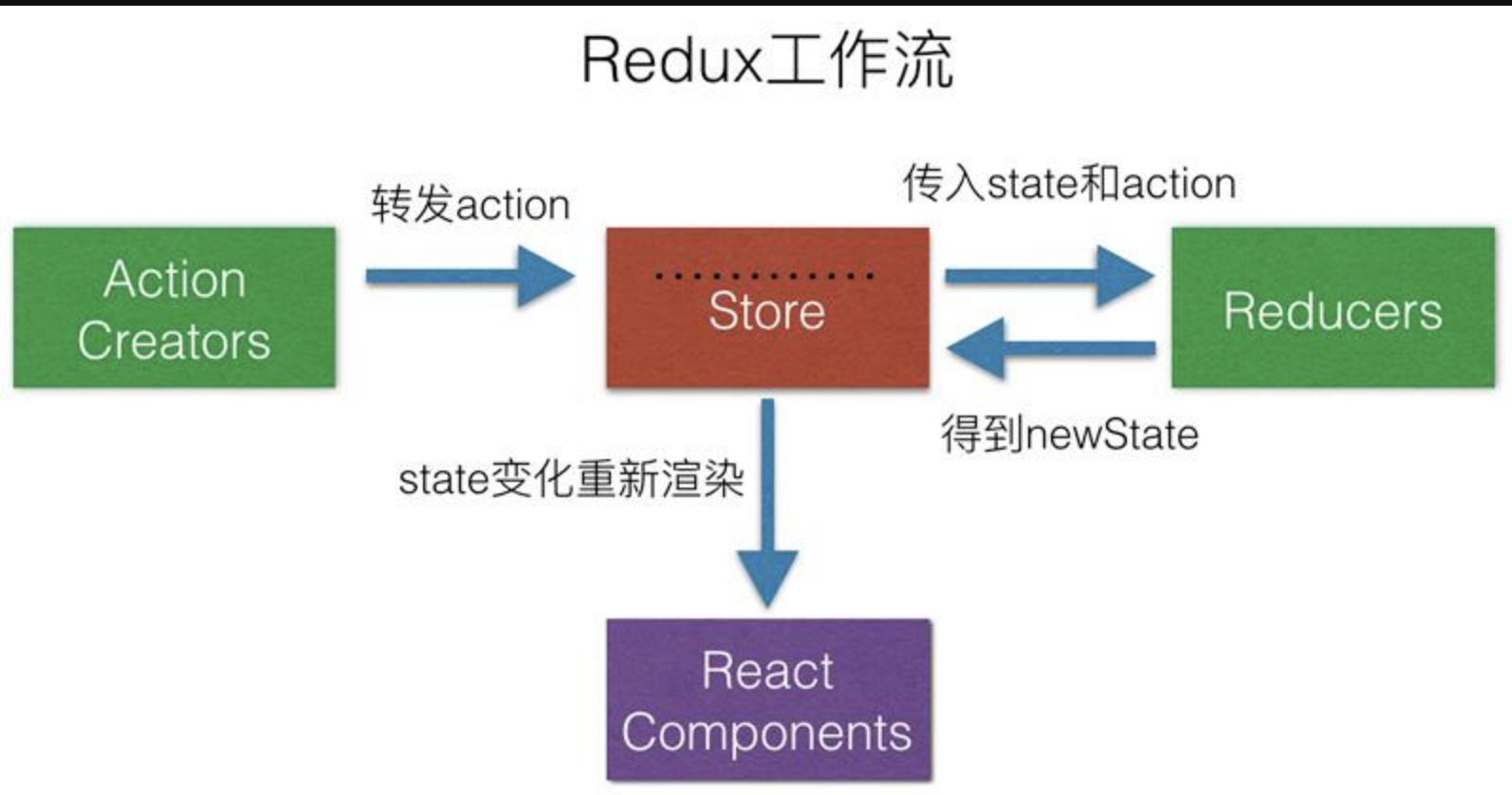
Redux实现原理解析
为什么要用redux
在
React中,数据在组件中是单向流动的,数据从一个方向父组件流向子组件(通过props),所以,两个非父子组件之间通信就相对麻烦,redux的出现就是为了解决state里面的数据问题
Redux设计理念
Redux是将整个应用状态存储到一个地方上称为store,里面保存着一个状态树store tree,组件可以派发(dispatch)行为(action)给store,而不是直接通知其他组件,组件内部通过订阅store中的状态state来刷新自己的视图
Redux三大原则
- 唯一数据源
整个应用的state都被存储到一个状态树里面,并且这个状态树,只存在于唯一的store中
- 保持只读状态
state是只读的,唯一改变state的方法就是触发action,action是一个用于描述以发生时间的普通对象
- 数据改变只能通过纯函数来执行
使用纯函数来执行修改,为了描述
action如何改变state的,你需要编写reducers
Redux源码
let createStore = (reducer) => {
let state;
//获取状态对象
//存放所有的监听函数
let listeners = [];
let getState = () => state;
//提供一个方法供外部调用派发action
let dispath = (action) => {
//调用管理员reducer得到新的state
state = reducer(state, action);
//执行所有的监听函数
listeners.forEach((l) => l())
}
//订阅状态变化事件,当状态改变发生之后执行监听函数
let subscribe = (listener) => {
listeners.push(listener);
}
dispath();
return {
getState,
dispath,
subscribe
}
}
let combineReducers=(renducers)=>{
//传入一个renducers管理组,返回的是一个renducer
return function(state={},action={}){
let newState={};
for(var attr in renducers){
newState[attr]=renducers[attr](state[attr],action)
}
return newState;
}
}
export {createStore,combineReducers};
参考 前端进阶面试题详细解答
createElement 与 cloneElement 的区别是什么
createElement函数是 JSX 编译之后使用的创建React Element的函数,而cloneElement则是用于复制某个元素并传入新的Props
受控组件、非受控组件
- 受控组件就是改变受控于数据的变化,数据变了页面也变了。受控组件更合适,数据驱动是react核心
- 非受控组件不是通过数据控制页面内容
ref是一个函数又有什么好处?
- 方便react销毁组件、重新渲染的时候去清空refs的东西,防止内存泄露
React Portal 有哪些使用场景
- 在以前, react 中所有的组件都会位于 #app 下,而使用 Portals 提供了一种脱离 #app 的组件
- 因此 Portals 适合脱离文档流(out of flow) 的组件,特别是 position: absolute 与 position: fixed的组件。比如模态框,通知,警告,goTop 等。
以下是官方一个模态框的示例,可以在以下地址中测试效果
<html>
<body>
<div id="app"></div>
<div id="modal"></div>
<div id="gotop"></div>
<div id="alert"></div>
</body>
</html>
const modalRoot = document.getElementById('modal');
class Modal extends React.Component {
constructor(props) {
super(props);
this.el = document.createElement('div');
}
componentDidMount() {
modalRoot.appendChild(this.el);
}
componentWillUnmount() {
modalRoot.removeChild(this.el);
}
render() {
return ReactDOM.createPortal(
this.props.children,
this.el,
);
}
}
React Hooks当中的useEffect是如何区分生命周期钩子的
useEffect可以看成是
componentDidMount,componentDidUpdate和componentWillUnmount三者的结合。useEffect(callback, [source])接收两个参数,调用方式如下
useEffect(() => {
console.log('mounted');
return () => {
console.log('willUnmount');
}
}, [source]);
生命周期函数的调用主要是通过第二个参数[source]来进行控制,有如下几种情况:
[source]参数不传时,则每次都会优先调用上次保存的函数中返回的那个函数,然后再调用外部那个函数;[source]参数传[]时,则外部的函数只会在初始化时调用一次,返回的那个函数也只会最终在组件卸载时调用一次;[source]参数有值时,则只会监听到数组中的值发生变化后才优先调用返回的那个函数,再调用外部的函数。
哪个生命周期发送ajax
- componentWillMount在新版本react中已经被废弃了
- 在做ssr项目时候,componentWillMount要做服务端数据的获取,不能被占用
- 所以在componentDidMount中请求
setState
在了解setState之前,我们先来简单了解下 React 一个包装结构: Transaction:
事务 (Transaction)
是 React 中的一个调用结构,用于包装一个方法,结构为: initialize - perform(method) - close。通过事务,可以统一管理一个方法的开始与结束;处于事务流中,表示进程正在执行一些操作
- setState: React 中用于修改状态,更新视图。它具有以下特点:
异步与同步: setState并不是单纯的异步或同步,这其实与调用时的环境相关:
- 在合成事件 和 生命周期钩子 (除 componentDidUpdate) 中,setState是"异步"的;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在生命周期钩子调用中,更新策略都处于更新之前,组件仍处于事务流中,而componentDidUpdate是在更新之后,此时组件已经不在事务流中了,因此则会同步执行;
- 在合成事件中,React 是基于 事务流完成的事件委托机制 实现,也是处于事务流中;
- 问题: 无法在setState后马上从this.state上获取更新后的值。
- 解决: 如果需要马上同步去获取新值,setState其实是可以传入第二个参数的。setState(updater, callback),在回调中即可获取最新值;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在 原生事件 和 setTimeout 中,setState是同步的,可以马上获取更新后的值;
- 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步;
- 批量更新 : 在 合成事件 和 生命周期钩子 中,setState更新队列时,存储的是 合并状态(Object.assign)。因此前面设置的 key 值会被后面所覆盖,最终只会执行一次更新;
- 函数式 : 由于 Fiber 及 合并 的问题,官方推荐可以传入 函数 的形式。setState(fn),在fn中返回新的state对象即可,例如this.setState((state, props) => newState);
- 使用函数式,可以用于避免setState的批量更新的逻辑,传入的函数将会被 顺序调用;
注意事项:
- setState 合并,在 合成事件 和 生命周期钩子 中多次连续调用会被优化为一次;
- 当组件已被销毁,如果再次调用setState,React 会报错警告,通常有两种解决办法
- 将数据挂载到外部,通过 props 传入,如放到 Redux 或 父级中;
- 在组件内部维护一个状态量 (isUnmounted),componentWillUnmount中标记为 true,在setState前进行判断;
key的作用
是给每一个 vnode 的唯一 id,可以依靠 key,更准确,更快的拿到 oldVnode 中对应的 vnode 节点
<!-- 更新前 -->
<div>
<p key="ka">ka</p>
<h3 key="song">song</he>
</div>
<!-- 更新后 -->
<div>
<h3 key="song">song</h3>
<p key="ka">ka</p>
</div>
如果没有 key,React 会认为 div 的第一个子节点由 p 变成 h3,第二个子节点由 h3 变成 p,则会销毁这两个节点并重新构造。
但是当我们用 key 指明了节点前后对应关系后,React 知道 key === "ka" 的 p 更新后还在,所以可以复用该节点,只需要交换顺序。
key 是 React 用来追踪哪些列表元素被修改、被添加或者被移除的辅助标志。
在开发过程中,我们需要保证某个元素的 key 在其同级元素中具有唯一性。在 React diff 算法中,React 会借助元素的 Key 值来判断该元素是新近创建的还是被移动而来的元素,从而减少不必要的元素重新渲染。同时,React 还需要借助 key 来判断元素与本地状态的关联关系。
约束性组件( controlled component)与非约束性组件( uncontrolled component)有什么区别?
在 React中,组件负责控制和管理自己的状态。
如果将HTML中的表单元素( input、 select、 textarea等)添加到组件中,当用户与表单发生交互时,就涉及表单数据存储问题。根据表单数据的存储位置,将组件分成约東性组件和非约東性组件。
约束性组件( controlled component)就是由 React控制的组件,也就是说,表单元素的数据存储在组件内部的状态中,表单到底呈现什么由组件决定。
如下所示, username没有存储在DOM元素内,而是存储在组件的状态中。每次要更新 username时,就要调用 setState更新状态;每次要获取 username的值,就要获取组件状态值。
class App extends Component {
//初始化状态
constructor(props) {
super(props);
this.state = {
username: "有课前端网",
};
}
//查看结果
showResult() {
//获取数据就是获取状态值
console.log(this.state.username);
}
changeUsername(e) {
//原生方法获取
var value = e.target.value;
//更新前,可以进行脏值检测
//更新状态
this.setState({
username: value,
});
}
//渲染组件
render() {
//返回虚拟DOM
return (
<div>
<p>
{/*输入框绑定va1ue*/}
<input type="text" onChange={this.changeUsername.bind(this)} value={this.state.username} />
</p>
<p>
<button onClick={this.showResult.bind(this)}>查看结果</button>
</p>
</div>
);
}
}
非约束性组件( uncontrolled component)就是指表单元素的数据交由元素自身存储并处理,而不是通过 React组件。表单如何呈现由表单元素自身决定。
如下所示,表单的值并没有存储在组件的状态中,而是存储在表单元素中,当要修改表单数据时,直接输入表单即可。有时也可以获取元素,再手动修改它的值。当要获取表单数据时,要首先获取表单元素,然后通过表单元素获取元素的值。
注意:为了方便在组件中获取表单元素,通常为元素设置ref属性,在组件内部通过refs属性获取对应的DOM元素。
class App extends Component {
//查看结果
showResult() {
//获取值
console.log(this.refs.username.value);
//修改值,就是修改元素自身的值
this.refs.username.value = "专业前端学习平台";
//渲染组件
//返回虚拟DOM
return (
<div>
<p>
{/*非约束性组件中,表单元素通过 defaultvalue定义*/}
<input type="text" ref=" username" defaultvalue="有课前端网" />
</p>
<p>
<button onClick={this.showResult.bind(this)}>查看结果</button>
</p>
</div>
);
}
}
虽然非约東性组件通常更容易实现,可以通过refs直接获取DOM元素,并获取其值,但是 React建议使用约束性组件。主要原因是,约東性组件支持即时字段验证,允许有条件地禁用/启用按钮,强制输入格式等。
组件是什么?类是什么?类变编译成什么
- 组件指的是页面的一部分,本质就是一个类,最本质就是一个构造函数
- 类编译成构造函数
描述 Flux 与 MVC?
传统的 MVC 模式在分离数据(Model)、UI(View和逻辑(Controller)方面工作得很好,但是 MVC 架构经常遇到两个主要问题:
数据流不够清晰:跨视图发生的级联更新常常会导致混乱的事件网络,难于调试。
缺乏数据完整性:模型数据可以在任何地方发生突变,从而在整个UI中产生不可预测的结果。
使用 Flux 模式的复杂用户界面不再遭受级联更新,任何给定的React 组件都能够根据 store 提供的数据重建其状态。Flux 模式还通过限制对共享数据的直接访问来加强数据完整性。
使用状态要注意哪些事情?
要注意以下几点。
-
不要直接更新状态
-
状态更新可能是异步的
-
状态更新要合并。
-
数据从上向下流动
在 React 中如何处理事件
为了解决跨浏览器的兼容性问题,SyntheticEvent 实例将被传递给你的事件处理函数,SyntheticEvent是 React 跨浏览器的浏览器原生事件包装器,它还拥有和浏览器原生事件相同的接口,包括 stopPropagation() 和 preventDefault()。
比较有趣的是,React 实际上并不将事件附加到子节点本身。React 使用单个事件侦听器侦听顶层的所有事件。这对性能有好处,也意味着 React 在更新 DOM 时不需要跟踪事件监听器。
diff算法?

- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 选择性子树渲染。开发人员可以重写
shouldComponentUpdate提高diff的性能
redux 有什么缺点
- 一个组件所需要的数据,必须由父组件传过来,而不能像 flux 中直接从 store 取
- 当一个组件相关数据更新时,即使父组件不需要用到这个组件,父组件还是会重新 render,可能会有效率影响,或者需要写复杂的
shouldComponentUpdate进行判断

