
各种排序算法的快速了解
冒泡排序
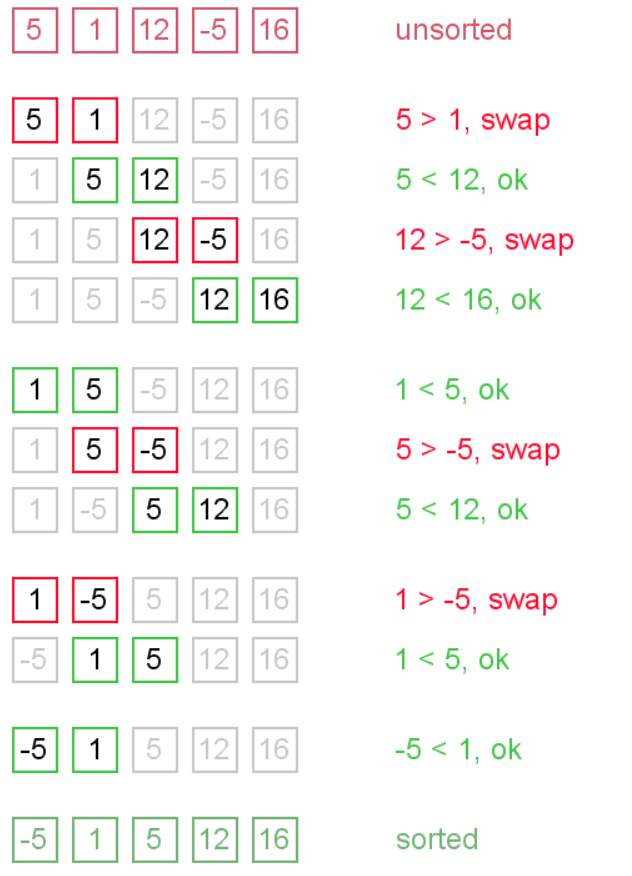
算法描述
重复地比较要排序的数列,一次比较两个元素,如果后者较小则与前者交换元素。
- 比较相邻的元素,如果前者比后者大,则交换两个元素。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。
- 针对所有的元素重复以上的步骤,除了最后一个。
快速排序
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
1、首先设定一个分界值,通过该分界值将数组分成左右两部分。
2、将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
3、然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4、重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。

动画观看联了解 点击 快速排序
选择排序
选择排序算法通过选择和交换来实现排序,其排序流程如下:
- (1)首先从原始数组中选择最小的1个数据,将其和位于第1个位置的数据交换。
- (2)接着从剩下的n-1个数据中选择次小的1个元素,将其和第2个位置的数据交换
- (3)然后,这样不断重复,直到最后两个数据完成交换。最后,便完成了对原始数组的从小到大的排序。
假如给定初始数据:(118,101,105,127,112)
一次排序:101,118,105,127,112
二次排序:101,105,118,127,112
三次排序:101,105,112,127,118
四次排序:101,105,112,118,127
红色为交换的数
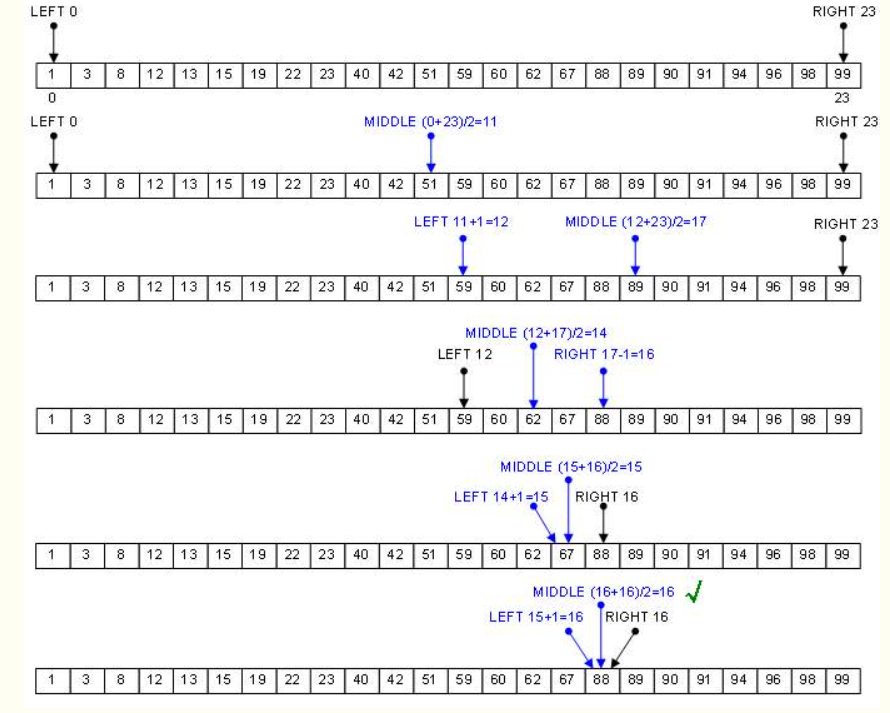
二分法
二分法排序其实是一种改进的插入排序,也是通过查找待插入位置来实现排序,这和插入排序是类似的。
算法思想,在插入第i个元素时,对前面的0~i-1元素进行折半,先跟他们中间的那个元素比,如果小,则对前半部分再进行折半,否则对后半进行折半,
直到left<right,然后再把第i个元素前1位与目标位置之间的所有元素后移,再把第i个元素放在目标位置上。
二分法实际上没有进行排序,只进行了有查找。所以当找到要插入的位置时,必须从移动最后一个记录开始,向后移动一位,再移动倒数第2位,直到要插入的位置的记录移后一位。
下面的图展示了二分法排序的工作原理,看图
插入排序
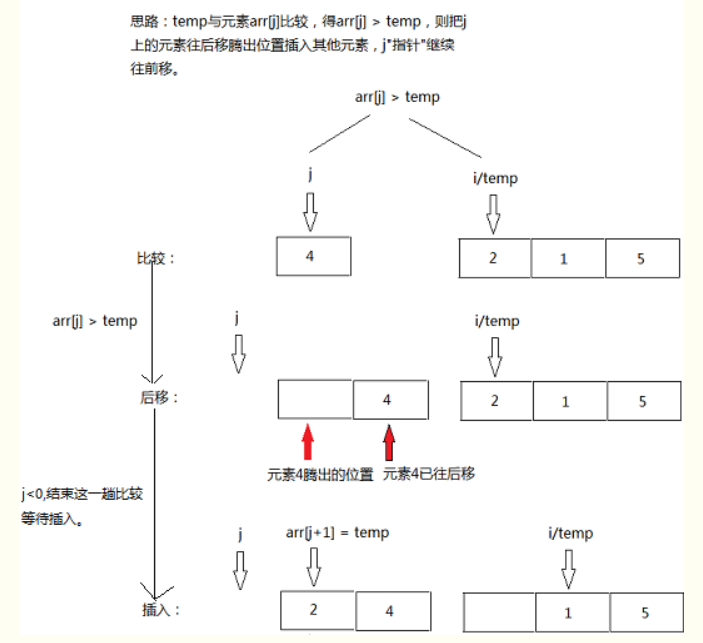
1.从数组的第二个数据开始往前比较,即一开始用第二个数和他前面的一个比较,如果 符合条件(比前面的大或者小,自定义),则让他们交换位置。
2.然后再用第三个数和第二个比较,符合则交换,但是此处还得继续往前比较,比如有 5个数8,15,20,45, 17,17比45小,需要交换,但是17也比20小,也要交换,当不需 要和15交换以后,说明也不需要和15前面的数据比较了,肯定不需要交换,因为前 面的数据都是有序的。
3.重复步骤二,一直到数据全都排完。
希尔排序
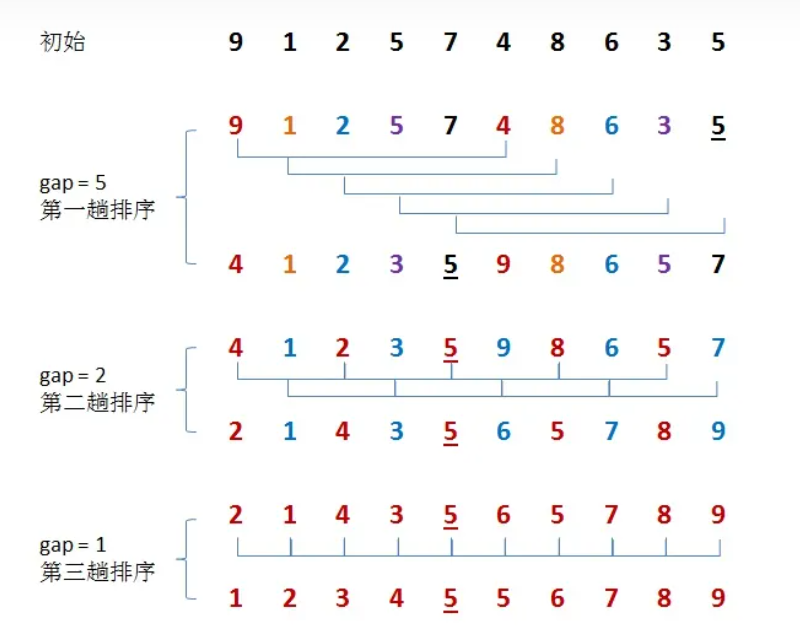
初始时,有一个大小为 10 的无序序列。
(1)在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。
(2)接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。
(3)按照直接插入排序的方法对每个组进行排序。
(4)在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。
(5)按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
堆排序
堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
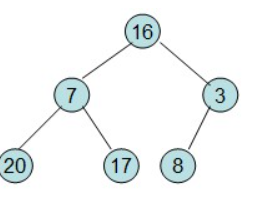
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:
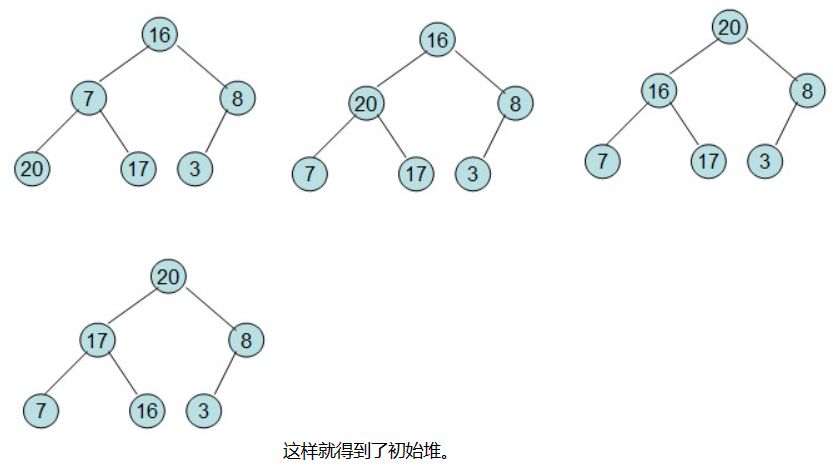
即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。

这样整个区间便已经有序了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号