
ES功能浅析
ES是基于Lucene构建的开源、分布式、RESTful接口全文搜索引擎。同时它还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,便于扩展,能在短时间内搜索和分析大量数据。
Lucene
Lucene是一个Java全文搜索引擎;仅是一个框架,提供代码库和API,并不是完整的应用程序。
倒排索引
倒排索引源于实际应用中需要根据属性值来查找记录。这种索引表中每一项都包括一个属性值和具有该属性值的各记录的地址。倒排索引根据属性值来确定记录的位置,而不是由记录来确定属性值。
倒排索引的关键步骤:
-
取得关键词;对文本进行解析,由Analyzer将文章内容拆分成关键词组。
-
建立倒排索引;建立关键词与文章号的对应关系如下图,三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件(positions)保存,其中词典文件还保存了指向频率文件和位置文件的指针。
![]()
-
压缩算法;
-
对词典文件中关键词进行压缩,关键词压缩为<前缀长度,后缀>,例:当前词为“阿拉伯语”,上一个词为“阿拉伯”,那么“阿拉伯语”压缩为<3,语>。
-
对数字进行压缩,数字只保存与上一个值的差值。例:当前文章号是16389(不压缩需要3个字节保存),上一文章号是16382,压缩后保存7(仅用一个字节)。
-

RESTful接口
介绍
-
RESTful是一种架构的规范与约束、原则,符合这种规范的架构就是RESTful架构。
-
RESTful(Representational state transfer)即资源的表述性状态转移,通过http动词来实现资源的转态转移。
-
资源是REST系统的核心概念,所有的设计都是以资源为中心。
方法
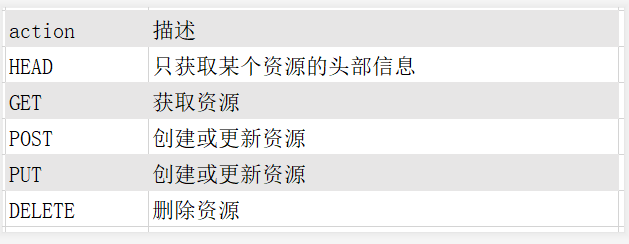
Get /user:列出所有用户
POST /user:新建一个用户
PUT /user:更新指定用户信息
DELETE /user:删除指定用户
工具
-
postman
-
curl
-
kibana
全文搜索
数据分类
-
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
-
对于结构化数据,一般使用关系型数据库(mysql,oracle等)的table方式存储和搜索,也可建立索引。通过b-tree等数据结构快速搜索数据。
-
-
非结构化数据:全文数据,指不定长或无固定格式的数据,文本数据。
-
对于非结构化数据,即全文数据的搜索主要有两种方法:顺序扫描法,全文搜索法。
-
顺序扫描
通过顺序扫描的方式查找特定的关键字,效率低。
全文搜索
全文搜索是指通过扫描文章中的每一个词,对每一个词建立一个索引,指明该次在文章中出现的次数和位置,当用户查询时,根据索引查找。
ElasticSearch存储架构解析
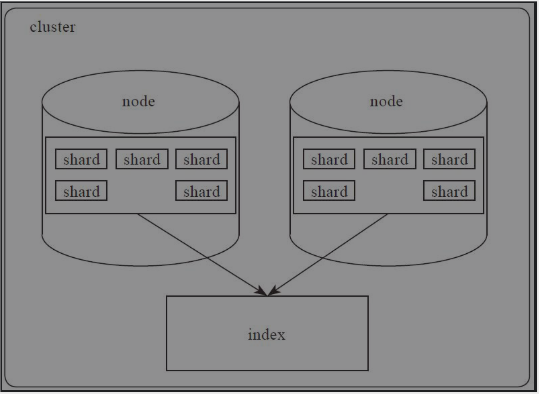
集群(cluster)
一个ElasticSearch集群由一个或多个节点(node)组成,每一个集群都有一个共同的集群名称作为标识,默认是"ElasticSearch"。
节点(node)
-
一个ElasticSearch实例即为一个node,通过node.master、node.data设置节点类型。
-
node.master:表示节点是否能成为主节点
-
true 代表节点能竞选主节点
-
false 代表节点不能竞选主节点
-
-
node.data:表示节点是否存储数据
-
node节点组合
-
主节点加数据节点
node.master:true
node.data:true -
数据节点
node.master:false
node.data:true -
客户端节点
主要应用于海量请求时进行负载均衡。
node.master:false
node.data:false
-
路由(routing)
当存储一个文档时,它会存储在唯一的主分片中,具体哪个分片由路由算法确定。
shard = hash(routing) % number_of_primary_shards
-
routing是一个可变值,默认是文档的 _id,也可以设置成一个自定义的值。routing通过hash函数生成一个数字,数字再对分片的总数(number_of_primary_shards)取余,这个余数就是文档所在分片的位置。
分片(Shard)
分片是单个Lucene实例,索引是指向主分片和副本分片的逻辑空间。分片可以理解为存储数据的最小逻辑单元,每个分片本身是一个全功能的独立单元,可以托管在集群中的任何节点上。
-
每个ElasticSearch分片是一个Lucene的索引,有文档存储数量限制,单一的Lucene索引中最多可存储2147483519(=integer.max_value-128)个文档,可使用 _cat/shards API 查询分片的大小。
一个索引可以存储很大的数据,针对索引进行分片,可以将大数据分片存储到多个节点,提高存储能力和搜索效率。创建索引时可以定义分片数量。
分片的作用:
-
允许水平分割扩展数据。
-
允许分配和并行操作(多节点),提高性能和吞吐量。

主分片(primary shard)
每个文档都存储在一个分片中,写入文档时,系统会先写入到主分片,然后复制到不同的副本中。ElasticSearch7.x版本之后默认一个索引创建一个主分片,7.x版本之前默认创建5个主分片,创建索引时可以指定分片数量,当分片一旦建立主分片数量不能修改(路由规则决定修改已建立的分片数量会导致集群无法定位分片位置),副本分片的数量可以改变。
副本分片(replica shard)
每一个主分片可以有零个或多个副本,默认一个。副本分片的作用:
-
增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
-
提高性能:查询时可以到主分片或者副本分片中进行查询。副本分片不能与主分片部署在同一节点上。
复制(replica)
复制是对分片的拷贝。当新增文档时会根据设定的副本分片数量复制主分片到其他节点;在网络中某个节点出现问题时,复制可以对故障进行转移,保证系统的高可用。
ElasticSearch核心概念介绍
索引词(term)
在ElasticSearch中索引词(term)是一个能被索引的精确值。索引词(term)可以通过term查询进行准确的搜索。
文本(text)
文本是一段普通的非结构化文字。通常,文本会被分析成一个个的索引词,存储在ES的索引库中。为了让文本能够进行搜索,文本字段在存储时需要预先分析;对文本中关键词进行查询时,搜索引擎应该根据搜索条件搜索出原文本。
分析(analysis)
分析是将文本转换为索引词的过程,分析的结果依赖于分词器。
-
常用的内置分词器
-
standard analyzer 默认分词器
-
simple analyzer
-
whitespace analyzer
-
stop analyzer
-
language analyzer
-
pattern analyzer 可以自定义正则规则进行分词
-
-
常见中文分词器
-
smartCN 一个简单的中文或中英文混合文本分词器
-
IK分词器 更智能友好的中文分词器
-
-
ElasticSearch的分词原理
-
写时分词
-
文档写入时会根据字段设置的分词器类型进行分词
-
写时分词器需要在mapping中指定,一旦指定不能修改,若需修改必须重建索引
-
-
读时分词
-
读时分词器默认与写时分词器保持一致
-
读时分词器可以单独设置,若设置的分词器与写时不一致,可能会导致搜索结果难以匹配
-
-
深入分析
![]()
-
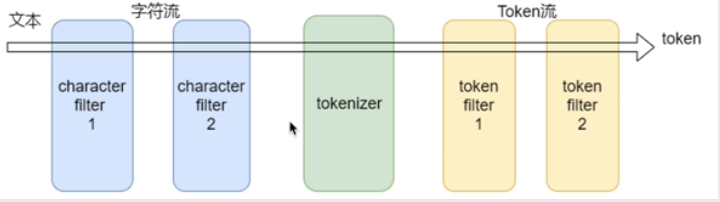
分析器(analyzer)由三部分组成
-
char filter:字符过滤器
-
tokenizer:分词器
-
token filter:token过滤器
-
-
char filter(字符过滤器)
字符过滤器以字符流的形式接收原始文本,并可以通过添加、删除或更改字符来转换该流。一个分析器可能有0个或多个字符过滤器。
-
tokenizer(分词器)
一个分词器接收一个字符流,并将其拆分成单个token(通常是单个单词),并输出一个token流。一个分析器只能有一个分词器。
-
token filter(token过滤器)
一个分词器接收token流,并且可能会添加、删除或更改tokens。比如一个lowercase token filter可以将所有的token转换成小写。一个分析器可能有0个或多个token过滤器,它们按顺序使用。
-
standard分析器
-
tokenizer
Standard tokenizer
-
token filters
-
Standard Token Filter
-
Lower Case Token Filter
-
-
-
-
索引(index)
索引类似于关系数据库中的数据库。索引是具有相同结构的文档集合。例如,可以有一个客户信息的索引,包含一个产品目录的索引,一个订单数据的索引。在系统上索引的名字全部小写,这个名字可以用来执行索引、搜索、更新和删除操作等。在单个集群中,可以定义多个索引。

类型(type)
类型类似于关系数据库中的表。在索引中,可以定义一个或多个类型,类型是索引的逻辑分区。在一般情况下,一种类型被定义为具有一组公共字段的文档。例如,对于一个博客平台,可以把所有的数据存储在一个索引中。在此索引中,可以定义一种类型为用户数据,一种类型为博客数据,一种类型为评论数据。
文档(document)
映射(mapping)
映射类似于关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先定义,也可以在第一次存储文档的时候自动识别。
字段(field)
字段类似于关系数据库中表的列。文档中包含零个或多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或对象的嵌套结构。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段的值。
来源字段(source field)
默认原文档将被存储在_source字段中。
主键(ID)
ID是一个文件的唯一标识,如果在存库的时候未提供ID,系统会自动生成一个ID,文档的index/type/id必须是唯一的。
ElasticSearch核心数据类型
字符串
-
text
-
用于全文索引,该类型字段将通过分词器进行分词
-
-
keyword
-
部分次,只能搜索该字段的完整值
-
数值型
常见数值类型,long,integer,short,byte,double,float,half_float,scaled_float
布尔-boolean
二进制-binary
该类型的字段把值当做经过base64编码的字符串,默认不存储、且不可搜索
范围类型
-
范围类型表示值是一个范围,而不是一个具体的值
-
integer_range,float_range,long_range,double_range,date_range
-
例integer_range,{"gte":"20", "lte":40}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号