
HBase--大数据系统的数据库方案
本文主要围绕以下三方面来讨论HBase:是什么、为什么、怎样做。
1. 什么是HBase
HBase是一个开源的、分布式的、非关系型数据库,其设计思想来源于Google的Big Table。通过集群管理大表(十亿行百万列),提供随机、实时的读写能力。

两个问题需要解释:
1.1 什么是非关系型数据库?
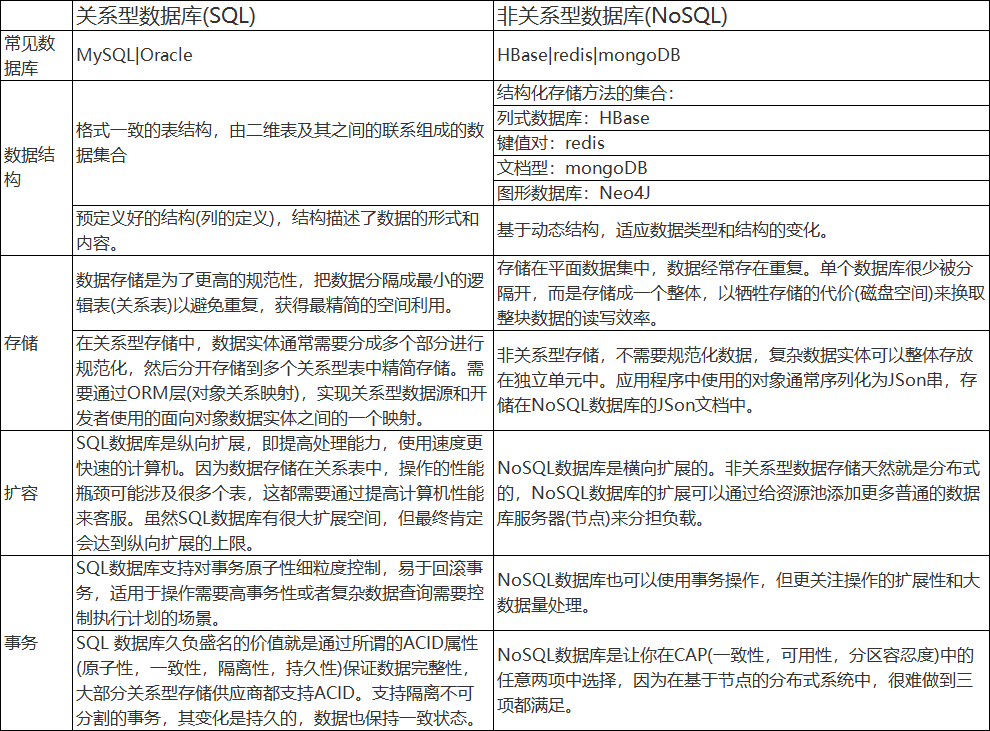
1.2 HBase与HDFS的关系
HDFS为HBase提供物理存储,可简单将HDFS理解成提供海量存储能力的文件系统(管理集群中的硬盘资源, 提供存储空间和数据间的交互能力),HBase是将数据结构化存储的方法(提供数据与结构化数据间的封装能力),具体的数据需要落地在HDFS上。
2. 为什么选用HBase
2.1 海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC集群存储的情况下,能在几十到百毫秒内返回数据。
2.2 列式存储
这里的列式存储其实说的是列族(ColumnFamily)存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
下图为HBase的表格结构,"address","info"为列族,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的,如RowKey为"xiaomming"的"town"为空。

2.3 极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于RegionServer对逻辑存储结构Region的扩展,一个是基于HDFS对物理存储空间的扩展。通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
2.4 高并发
由于Hbase运行在廉价的PC集群上,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
2.5 高可用
HBase依赖Zookeeper实现HMaster的高可用:Zookeeper提供Leader Election机制并存储状态信息,在集群中启动多个Master进程,让它们连接到Zookeeper。其中一个Master进程会被选举为leader处于Active状态,其他的Master会被指定为Standby模式。如果当前的leader Master进程挂掉了,会从Standby Master中选举新leader,恢复旧Master的状态提供服务。
RegionServer自动故障转移:一旦RegionServer发生宕机,HBase都会马上检测到这种宕机,并且在检测到宕机之后会将宕机RegionServer上的所有Region重新分配到集群中其他正常RegionServer上去,再根据HLog进行丢失数据恢复,恢复完成之后就可以对外提供服务,整个过程都是自动完成的,并不需要人工介入。
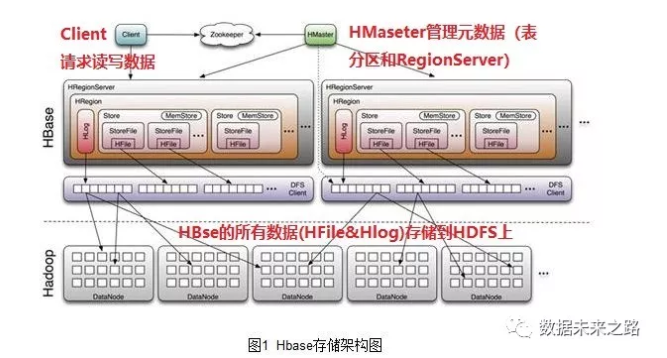
3. 怎样使用HBase
如上图所示,HBase的运行时有三个集群:
-
Zookeeper集群,负责HBase和HDFS集群的协调服务和配置服务。
-
HDFS集群,是一个分布式文件系统,有单一的名字空间。其中的节点有NameNode和DataNode,前者负责存储文件系统的元数据(包括目录名,文件名,等),后则负责存储实际文件的块。
-
HBase集群,其中的节点有Master和RegionServer。
3.1 HBase搭建
搭建集群模式需依赖Zookeeper和HDFS,需要配置运行环境以及Zookeeper与HDFS的节点ip,具体如下 :
|
参数文件 |
配置参数 |
参考值 |
|
.bash_profile |
HBASE_HOME |
/root/training/hbase-1.3.1 |
|
hbase-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
|
HBASE_MANAGES_ZK |
true |
|
|
hbase-site.xml |
hbase.rootdir |
hdfs://ip:port/hbase |
|
hbase.cluster.distributed |
true |
|
|
hbase.zookeeper.quorum |
ip |
|
|
dfs.replication |
2 |
|
|
hbase.master.maxclockskew |
180000 |
|
|
regionservers |
ip1 ip2 |
3.2 HBase集群中数据的存储
3.2.1 RegionServer存储的数据
RegionServer创建Region对象用于存储数据,同时创建一个HLog实例记录更新数据的操作信息,一个RegionServer包含多个Region和一个HLog。
-
Region是HBase中分布式存储和负载均衡的最小单元,但并不是存储的最小单元。
-
Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。
Region写数据之前会先检查MemStore:
1. 如果此Region的MemStore已经有缓存已有写入的数据, 则直接返回;
2. 如果没有缓存, 写入HLog(WAL:预写日志),再写入MemStore,成功后再返回。
3. 当所有之前写入MemStore的数据已经持久化在HDFS,HLog会失效,HLog存在于HDFS之上的文件会删除, HLog的生命周期结束。
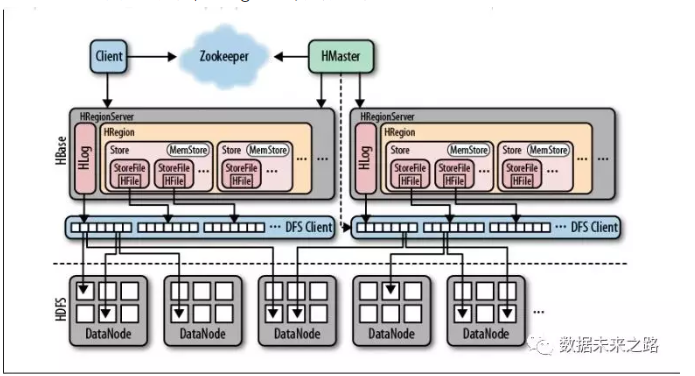
3.2.2 Zookeeper存储额数据
Zookeeper保存了HBase集群的信息:
-
/hbase/root-region-server ,Root region的位置
-
/hbase/table/-ROOT-,根元数据信息
-
/hbase/table/.META.,元数据信息
-
/hbase/master,当选的Mater
-
/hbase/backup-masters,备选的Master
-
/hbase/rs ,RegionServer的信息
-
/hbase/unassigned,未分配的Region
3.3 HBase的访问接口
a. Java编程接口;
b. Hbase的命令行工具,操作指令如下:
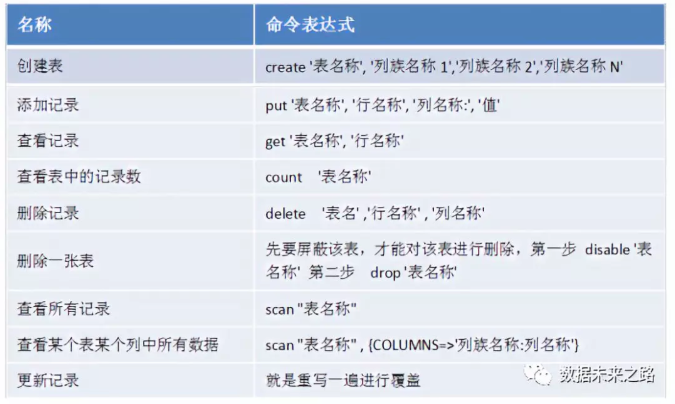
3.4 HBase Rowkey的设计
由于HBase是通过Rowkey查询的,一般Rowkey会存比较关键的检索信息。设计Rowkey时,需要根据应用场景合理设计,使数据均匀分布在多个节点提高并发访问效率。HBase中的数据是按照Rowkey的ASCII字典顺序进行全局排序的。Rowkey的设计原则如下:
-
频繁写的场景,随机Rowkey会获得更好性能;
-
频繁读的场景,有序Rowkey效率更高;
-
对于时间连续的数据,有序的Rowkey更有利于进行分段查询。
3.5 Region热点问题
HBase默认建表时有一个Region,这个Region的rowkey是没有边界的,即没有startkey和endkey,在数据写入时,所有数据都会写入这个默认的Region,随着数据量的不断增加,此Region已经不能承受不断增长的数据量,会进行拆分(split),分成2个Region。在此过程中,会产生两个问题:
1. 数据往一个Region上写,会有写热点问题。Region热点问题是指大量的client直接访问集中在个别RegionServer上,导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用。
2. Region split会消耗宝贵的集群I/O资源。
基于此在建表的时候,创建多个空region,并确定每个Region的起始和终止Rowkey,这样只要Rowkey的设计能均匀的命中各个Region,就不会存在热点问题,自然split的几率也会大大降低。当然随着数据量的不断增长,Region最终还是会拆分。像这样预先创建HBase表分区的方式,称之为预分区,HBase支持命令行及JavaAPI定义预分区策略。
3.6 Region的拆分
如上所述,当Region大小超过设定值时会导致Region的拆分,使HBase拥有良好扩张性。HBase不同版本的默认拆分策略不同,2.0版本默认切分策略依然和待分裂Region所属表在当前RegionServer上的Region个数有关系,如果Region个数等于1,切分阈值为flush size(128M) * 2,否则为MaxRegionFileSize(默认为10G),个人以为此拆分策略应结合预分区策略使用,针对大表和小表定义合理的分区数。
最后提下Phoenix,解决HBase不支持SQL的特点。它作为HBase内嵌的JDBC驱动,Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号