
大数据技术框架浅析
IBM提出大数据的五个特征:Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)、Veracity(真实性)。大数据主要解决两个问题:大数据的计算 & 大数据的存储。随着大数据相关技术的不断成熟,大数据已经广泛应用于各大行业,典型应用如电商网站商品推荐,天气预报,分布式服务架构中的日志分析系统等。
当前数据处理大致分为两类OLTP(On-Line Transaction Processing:联机事物处理)和OLAP(On-Line Analytical Processing:联机分析处理)。
OLTP:传统关系型数据库的主要应用,面向基本的、日常的事物处理,如银行交易。
OLAP:数据仓库(Data WareHouse)系统的主要应用,支持复杂的分析操作,侧重决策支持,如商品推荐。
OLAP多以分布式文件系统作为数据来源,目前应用广泛的HDFS(Hadoop Distributed File System:Hadoop分布式文件系统)是当前流行的大数据存储技术,其思想源于Google的三篇经典论文:
GFS(Google File System:Google文件系统):一个分布式文件系统。
Page Rank(网页排名):根据网页被其他网页引用的次数计算网页的排名,具体实现依赖大表(BigTable)和倒排索引(与根据索引查找内容的操作相反,根据内容查找索引)。
BigTable:Google设计用于处理海量数据、分布式的、非关系型数据库。用一张大表来存储数据,通过空间的扩展提高数据查询效率,以空间换时间。
Hadoop主要解决大数据的存储问题,提供离线大数据处理方案(Map Reduce),支持Spark、Impala等数据处理方案。实时大数据处理方案以Storm为代表,数据在内存数据库(如Redis)中保存。大数据平台从下往上可分为五层:数据来源、数据采集、数据处理、数据挖掘、大数据应用。本文以下图为据简述大数据中的典型技术方案。
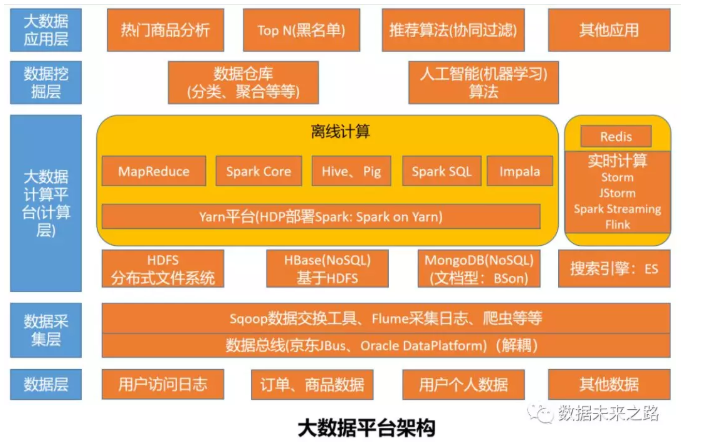
数据来源:系统中可以采集到的数据,如用户数据、业务数据等,也包含系统运行时产生的日志数据等。
数据采集:不同数据源生成数据类型格式存在差异,在数据采集前可能增加数据总线(如京东JBus)对业务进行解耦,Sqoop和Flume是常用的数据采集工具。
Sqoop:用于和关系型数据库进行交互,使用SQL语句在Hadoop和关系型数据库间传送数据,Sqoop使用JDBC连接关系型数据库。
Flume:一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。一个Flume代理由三个部分组成:Source、Channel和Sink。Source类似于接受缓冲器,将接收的事件存储在一个或多个Channel中。Channel被动存储事件,直到事件被Sink使用。Sink从Channel提取事件将其传给HDFS或者下一个Flume代理。Flume使用不同的Source接收不同的网络流,如使用Avro Flume接收Avro(一种数字序列化格式)事件。其支持的流行网络