
死锁现象与递归锁 信号量 GIL全局解释器锁 GIL与lock锁的区别 验证计算密集型IO密集型的效率 多线程实现socket通信 进程池, 线程池
死锁现象与递归锁
死锁现象
from threading import Thread, Lock
import time
Lock_A = Lock()
Lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
Lock_A.acquire()
print(f"{self.name}拿到了A锁")
Lock_B.acquire()
print(f"{self.name}拿到了B锁")
Lock_B.release()
print(f"{self.name}释放了B锁")
Lock_A.release()
print(f"{self.name}释放了A锁")
def f2(self):
Lock_B.acquire()
print(f"{self.name}拿到了B锁")
time.sleep(0.1)
Lock_A.acquire()
print(f"{self.name}拿到了A锁")
Lock_A.release()
print(f"{self.name}释放了A锁")
Lock_B.release()
print(f"{self.name}释放了B锁")
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
"""
Thread-1拿到了A锁
Thread-1拿到了B锁
Thread-1释放了B锁
Thread-1释放了A锁
Thread-1拿到了B锁
Thread-2拿到了A锁
...
"""
# 阻塞了, 因为t1运行到f2, 拿到了B锁,要拿A锁. 此时t2开启, 运行f1拿到了A锁要拿B锁, 两者冲突了, 所以阻塞了, 形成了死锁现象
递归锁
递归锁有一个计数的功能, 原数字为0, 上一次锁, 计数+1, 释放一次锁, 计数-1
只要递归锁上面的数字不为零, 其他线程就不能抢锁
from threading import Thread, RLock
import time
Lock_A = Lock_B = RLock()
# 切记 固定格式 不要改动
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
Lock_A.acquire()
print(f"{self.name}拿到了A锁")
Lock_B.acquire()
print(f"{self.name}拿到了B锁")
Lock_B.release()
print(f"{self.name}释放了B锁")
Lock_A.release()
print(f"{self.name}释放了A锁")
def f2(self):
Lock_B.acquire()
print(f"{self.name}拿到了B锁")
time.sleep(0.1)
Lock_A.acquire()
print(f"{self.name}拿到了A锁")
Lock_A.release()
print(f"{self.name}释放了A锁")
Lock_B.release()
print(f"{self.name}释放了B锁")
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
"""
Thread-1拿到了A锁
Thread-1拿到了B锁
Thread-1释放了B锁
Thread-1释放了A锁
Thread-1拿到了B锁
Thread-1拿到了A锁
Thread-1释放了A锁
Thread-1释放了B锁
Thread-2拿到了A锁
Thread-2拿到了B锁
Thread-2释放了B锁
Thread-2释放了A锁
Thread-3拿到了A锁
Thread-3拿到了B锁
Thread-3释放了B锁
Thread-3释放了A锁
Thread-2拿到了B锁
Thread-2拿到了A锁
Thread-2释放了A锁
Thread-2释放了B锁
Thread-3拿到了B锁
Thread-3拿到了A锁
Thread-3释放了A锁
Thread-3释放了B锁
"""
信号量
也是一种锁, 控制并发数量
from threading import Thread, Semaphore, current_thread
import time
import random
sem = Semaphore(5)
def task():
sem.acquire()
print(f"{current_thread().name} 厕所ing")
time.sleep(random.randint(1, 3))
sem.release()
if __name__ == '__main__':
for i in range(20):
t = Thread(target=task)
t.start()
"""
Thread-1 厕所ing
Thread-2 厕所ing
Thread-3 厕所ing
Thread-4 厕所ing
Thread-5 厕所ing
Thread-6 厕所ing
Thread-7 厕所ing
Thread-8 厕所ing
Thread-9 厕所ing
Thread-10 厕所ing
Thread-11 厕所ing
Thread-12 厕所ing
Thread-13 厕所ing
Thread-14 厕所ing
Thread-15 厕所ing
Thread-16 厕所ing
Thread-17 厕所ing
Thread-18 厕所ing
Thread-19 厕所ing
Thread-20 厕所ing
"""
# Semaphore 管理一个内置的计数器
# 每当调用acquire()时内置计数器-1
# 调用release() 时内置计数器+1
# 计数器不能小于0; 当计数器为0时, acquire()将阻塞线程直到其他线程调用release()
GIL全局解释器锁
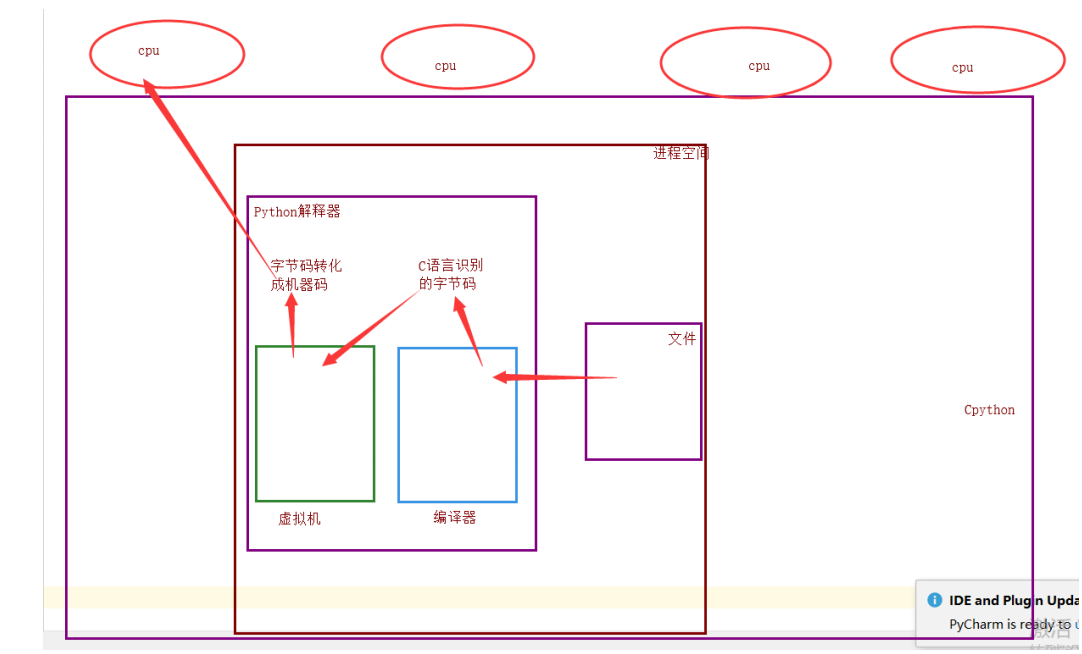
理论上来说: 单个进程的多线程可以利用多核
但是, 开发 Cpython 解释器的程序员, 给进入解释器的线程加了锁
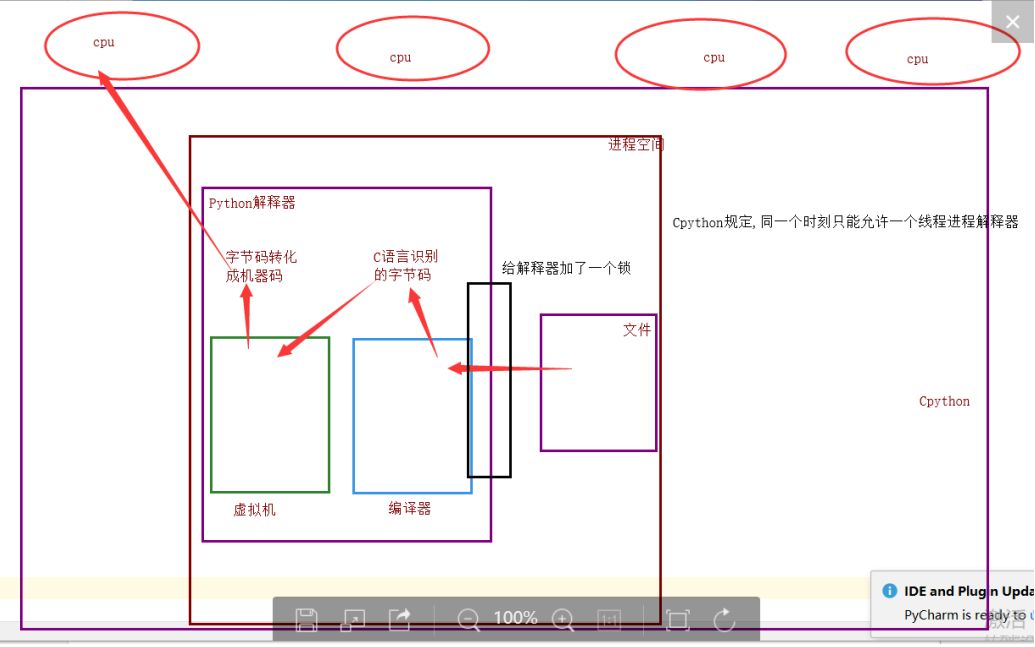
为什么加锁
1.当时都是单核时代, 而且CPU价格昂贵
2.如果不加全局解释器锁, 开发 Cpython 解释器的程序员就会在源码内部各种主动加锁, 解锁, 非常麻烦, 各种死锁现象等等. 他为了省事儿, 直接进入解释器时给线程加一个锁
优点:
保证了Cpython解释器的数据资源的安全
缺点:
单个进程的多线程不能利用多核CPU
现在多核时代, 去掉GIL锁可以么
Jpython 没有GIL锁
PYPY 也没有GIL锁
因为 Cpython 解释器所有的业务逻辑都是围绕着单个线程实现的, 去掉这个GIL锁, 几乎不可能
单个进程的多线程可以并发么
可以, 单个进程的多线程可以并发, 但是不能利用多核,不能并行
多个进程可以并行, 并发
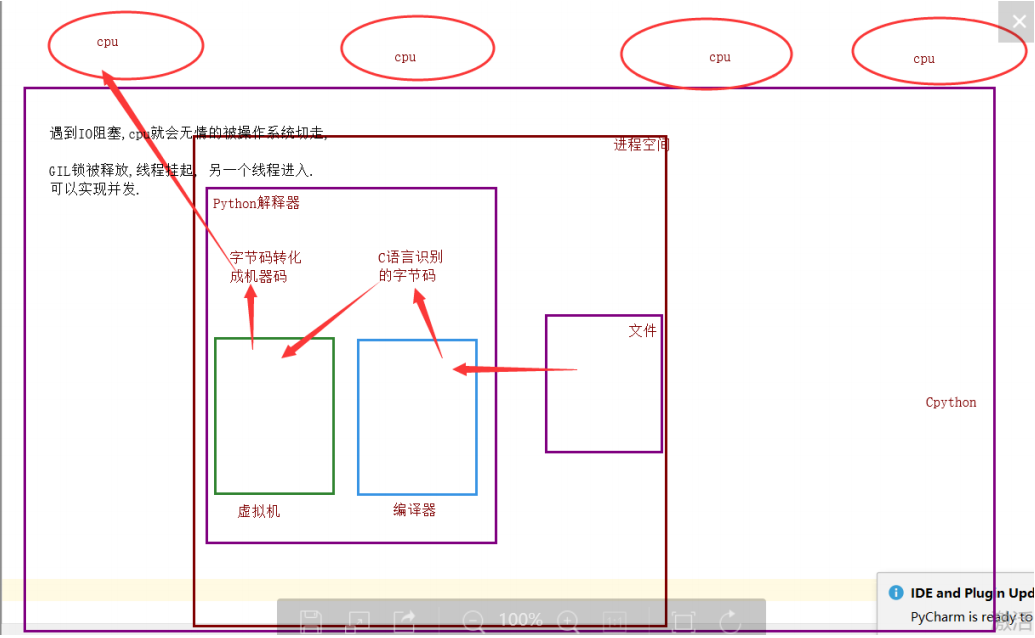
GIL与lock锁的区别
相同点:
都是同种锁
不同点:
GIL锁全局解释器锁, 保护解释器内部的资源数据的安全.
GIL锁 上锁, 释放无需手动操作
自己代码中定义的互斥锁保护进程中的资源数据的安全
自己定义的互斥锁必须自己手动上锁, 释放锁

验证IO密集型与计算密集型的效率
IO密集型
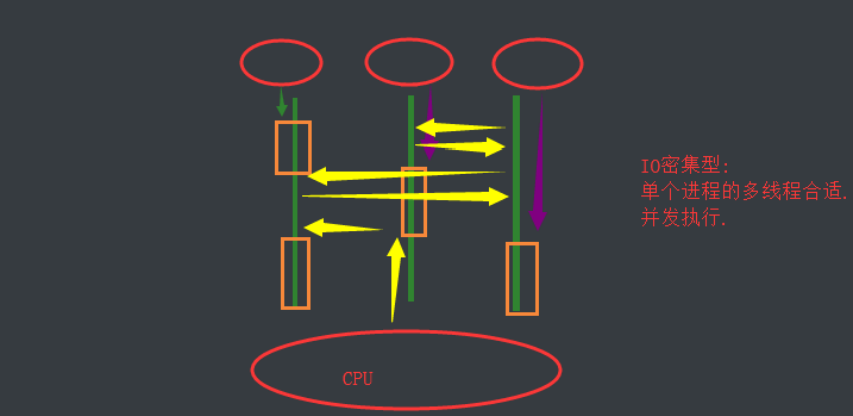
单个进程的多线程并发 vs 多个进程的并发并行
# 单进程的多线程并发
from threading import Thread
import time
import random
def task():
count = 0
time.sleep(random.randint(1, 3))
count +=1
if __name__ == '__main__':
start_time = time.time()
lst = []
for i in range(50):
p = Thread(target=task)
lst.append(p)
p.start()
for p in lst:
p.join()
print(f'执行效率:{time.time() - start_time}')
"""
执行效率:3.0078725814819336
"""
# 多进程的并发并行
from multiprocessing import Process
import time
import random
def task():
count = 0
time.sleep(random.randint(1, 3))
count +=1
if __name__ == '__main__':
start_time = time.time()
lst = []
for i in range(50):
p = Process(target=task)
lst.append(p)
p.start()
for p in lst:
p.join()
print(f'执行效率:{time.time() - start_time}')
"""
执行效率:13.165884733200073
"""
对于IO密集型, 单进程多线程并发效率高
计算密集型

单个进程的多线程并发 vs 多个进程的并发并行
# 单进程所线程并发
from threading import Thread
import time
def task():
count = 0
for i in range(10000000):
count += 1
if __name__ == '__main__':
start_time = time.time()
lst = []
for i in range(4):
p = Thread(target=task)
lst.append(p)
p.start()
for p in lst:
p.join()
print(f'执行效率:{time.time() - start_time}')
"""
执行效率:2.066039800643921
"""
# 多进程的并发并行
from multiprocessing import Process
import time
def task():
count = 0
for i in range(10000000):
count += 1
if __name__ == '__main__':
start_time = time.time()
lst = []
for i in range(4):
p = Process(target=task)
lst.append(p)
p.start()
for p in lst:
p.join()
print(f'执行效率:{time.time() - start_time}')
"""
执行效率:1.614973545074463
"""
对于计算密集型, 多进程的并发并行效率高
多线程实现socket通信
# server服务端
import socket
from threading import Thread
def commuincata(conn, addr):
while 1:
try:
from_client_data = conn.recv(1024).decode("utf-8")
print(f"来自客户端{addr[1]}的信息{from_client_data}")
to_client_data = input(">>>").strip().encode("utf-8")
conn.send(to_client_data)
except Exception:
break
conn.close()
def accept():
server = socket.socket()
server.bind(("127.0.0.1", 8848))
server.listen(5)
while 1:
conn, addr = server.accept()
t = Thread(target=commuincata, args=(conn, addr))
t.start()
if __name__ == '__main__':
accept()
# client客户端
import socket
client = socket.socket()
client.connect(("127.0.0.1", 8848))
while 1:
try:
to_server_data = input(">>>").strip().encode("utf-8")
client.send(to_server_data)
from_server_data = client.recv(1024).decode("utf-8")
print(from_server_data)
except Exception:
break
client.close()
你的计算机允许范围内, 开启的线程进程数量越多越好
进程池, 线程池
进程池/线程池
一个容器, 这个容器限制住你开启进程/线程的数量, 比如4个, 第一次肯定只能并发的处理4个任务, 只要有任务完成, 进程/线程马上就会接下一个任务
以时间换空间
os.cpu_count # CPU数量
from concurrent.futures import ProcessPoolExecutor
import os
import time
import random
def task():
print(f'{os.getpid()} 接客')
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
# 开启进程池
p = ProcessPoolExecutor()
# 默认不写, 进程池里面的进程数默认为CPU个数
for i in range(20):
p.submit(task)
"""
106368 接客
104388 接客
106912 接客
107368 接客
107072 接客
105324 接客
95336 接客
106572 接客
104388 接客
95336 接客
106912 接客
107368 接客
105324 接客
107072 接客
106368 接客
106912 接客
107072 接客
95336 接客
106572 接客
104388 接客
"""
from concurrent.futures import ThreadPoolExecutor
import os
import time
import random
def task():
print(f'{os.getpid()} 接客')
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
# 开启线程池
p = ThreadPoolExecutor()
# 默认不写, 进程池里面的进程数默认为 CPU个数*5
for i in range(20):
p.submit(task)
"""
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
103480 接客
"""
# 因为是同一进程下的多线程, 所以pid相同

 浙公网安备 33010602011771号
浙公网安备 33010602011771号