
OO第一单元总结
第一单元作业总结
前两次作业基于过程实现,类很少且复杂度高,故不献丑啦,从第三次作业开始总结。
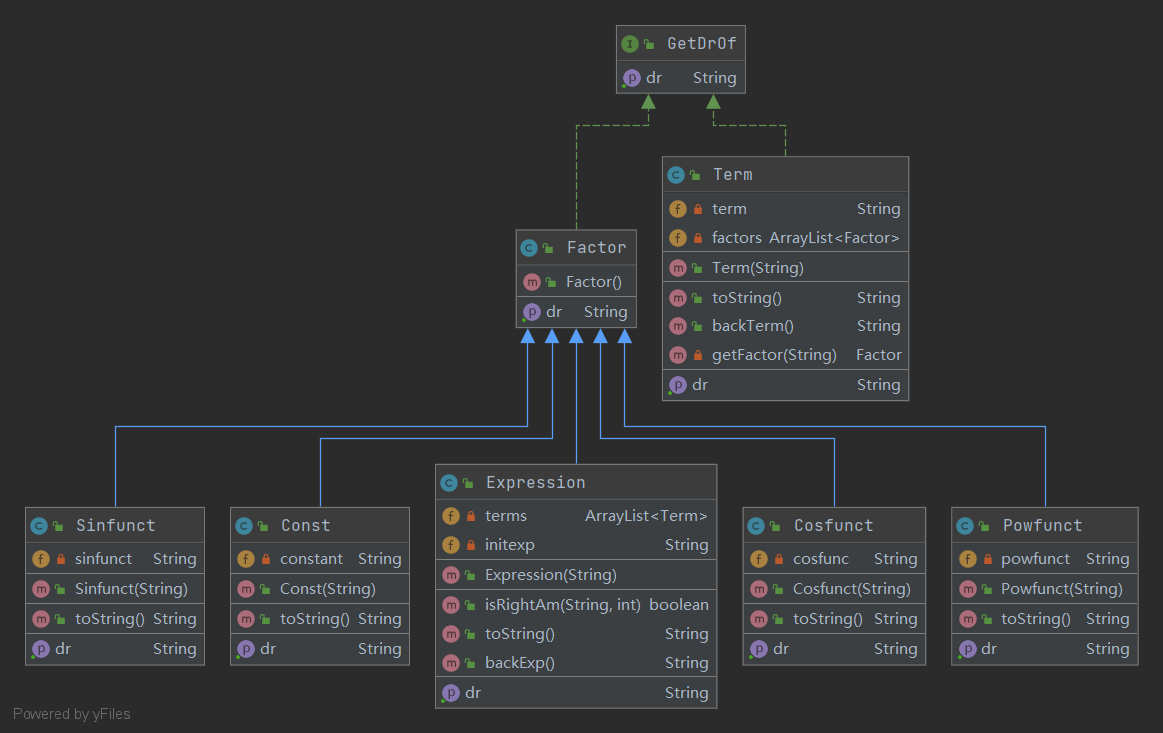
第三次作业
类图

重要类说明
Factor
仅包含求导方法和构造方法,其内不包含任何行为,是形式上的两个方法。
Xitem
继承于Factor类,覆写求导方法和toString方法。包含有覆写的equals和hashCode方法,以便存放入hashmap。(注意:此类的对象指数严格为1)
Const
继承于Factor类,覆写求导方法和toString方法。包含有覆写的equals和hashCode方法,以便存放入hashmap。另外包含去除前导零和无用加号的方法,通过在构造方法中调用实现常量的化简。(注意:这里的equals方法只用判断是不是Const类,以便后续的表达式的合并同类项,这也是Term中常数因子用ArrayList存放的原因)
Trigfunct
继承于Factor类,覆写求导方法和toString方法。包含有覆写的equals和hashCode方法,以便存放入hashmap。另外包含devideTrig方法来分辨三角函数的类别,提取三角函数的base部分,并通过工厂类构造相应对象。(注意:此类的对象指数严格为1)
值得说明的是,此类的求导方法是一层复合函数的求导方法,运用三角函数和因子的求导方法进行。
Powfunct
继承于Factor类,覆写求导方法和toString方法。包含有覆写的equals和hashCode方法,以便存放入hashmap。另外包含devidePow方法来取出幂函数的base部分和exponent部分,并分别通过工厂类构造对象。(注意:此类的对象指数部分不可缺省)
值得说明的是, 此类的求导方法是一层复合函数的求导方法,运用幂函数和因子的求导方法进行。
Term
一个Term对象表示一项,即因子的乘积。覆写toString方法。包含有覆写的equals和hashCode方法,以便存放入hashmap。
包含devideTerm方法来解析每一项,基本思想是通过逐字符读取来找到合适的“*”以分离因子,并将得到的每一个因子用工厂类生成一个Factor的对象,通过sortFactor方法进行分类然后最后通过parseFactor方法合并存放入Factor的数表中。
在构造的过程中进行解析且进行相同因子的合并,基本思想是用ArrayList<Const>,Map<Xitem, BigInteger>,Map<Trigfunct, BigInteger>,ArrayList<Integer> bras实现因子的提取和分类,常数数表存取每一个常数因子,Xitem图来加和基本项x的指数,Trigfunct图来分类合并三角函数的数组,bracket数表来得到可能的分隔符“*”的位置。将每一个因子分类后进行合并操作,常数项作为整个项的系数单独存入field的coe中,其他的因子存入filed的ArrayList中。(注意:若是常数项,ArrayList存放1,不可为空)
包含backTerm方法,用以把Factor的数表合并成项,并将之存入field中的String term中,主要用于最后得到求导结果后可以通过再次调用构造方法进行化简之后,直接取出filed中的term字段作为结果。
包含getDr方法,主要进行乘积求导,把每一个因子分别求导与剩余因子相乘后相加,最后返回一个字符串。
Expression
一个Expression对象表示一个表达式,即项的加减运算。覆写toString方法。包含有覆写的equals和hashCode方法,以便存放入hashmap。
包含devideExp方法来解析表达式并将之拆分成项。基本思想是找寻合适的[+-]来提取项,并将项的字符串通过Term的构造方法生成对象存入Map<Term, BigInteger>中,把符号作为系数存入相应k-v对的value中。对于相同的项,将其系数加和后存入。
包含getDr方法实现求导,本质是加减的求导法则,将项的求导结果通过项的符号连接起来,返回一个字符串。
包含backExp方法,用来将每一个项的字符串通过其之间的符号拼接起来得到一个表达式的字符串,存入field的expression中。这里存在一个化简的想法,在把项存入map前,提前将项的系数和项的自带系数相乘后作为项的系数存入map中。
Factorfactory
该类为工厂类,用来根据输入的字符串,生成所需要的对象并返回。
RegularExp
正则表达式类,存放其它类中常用到的正则表达式。
FormatWrongException
继承Exception类,为实验特别的异常类,覆写toString方法,返回需要打印的字符串。
statics分析

可以看出Term类和Expression类的行数最多,功能过于复杂,需要更加模块化,降低单个类的复杂度。
metrics分析
class
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Const | 1.83 | 3 | 11 |
| Expression | 4.58 | 12 | 55 |
| Factor | 1 | 1 | 2 |
| Factorfactory | 6 | 6 | 6 |
| FormatWrongException | 1 | 1 | 1 |
| Main | 1 | 1 | 1 |
| Powfunct | 2 | 5 | 16 |
| RegularExp | 1 | 1 | 6 |
| Term | 5.25 | 12 | 63 |
| Trigfunct | 2.17 | 6 | 13 |
| Xitem | 1 | 1 | 5 |
可以看出Expression和Term类运行复杂度很高,需要更多的分离功能。
method
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Const.Const(String) | 5 | 2 | 3 | 3 |
| Const.eatZero(String) | 3 | 1 | 2 | 4 |
| Const.equals(Object) | 1 | 2 | 2 | 2 |
| Const.getDr() | 0 | 1 | 1 | 1 |
| Const.hashCode() | 0 | 1 | 1 | 1 |
| Const.toString() | 0 | 1 | 1 | 1 |
| Expression.Expression(String) | 1 | 2 | 1 | 2 |
| Expression.amFront(String,int) | 3 | 1 | 3 | 4 |
| Expression.backExp() | 20 | 4 | 11 | 12 |
| Expression.devideExp(String) | 34 | 1 | 16 | 16 |
| Expression.eatSpace(String,int) | 8 | 4 | 6 | 8 |
| Expression.eatSpaceFront(String,int) | 5 | 2 | 3 | 6 |
| Expression.equals(Object) | 7 | 5 | 4 | 5 |
| Expression.getDr() | 20 | 4 | 11 | 12 |
| Expression.hashCode() | 0 | 1 | 1 | 1 |
| Expression.isRightAm(String,int) | 5 | 3 | 3 | 3 |
| Expression.starFront(String,int) | 2 | 1 | 2 | 3 |
| Expression.toString() | 0 | 1 | 1 | 1 |
| Factor.Factor() | 0 | 1 | 1 | 1 |
| Factor.getDr() | 0 | 1 | 1 | 1 |
| Factorfactory.getFactor(String) | 6 | 6 | 5 | 6 |
| FormatWrongException.toString() | 0 | 1 | 1 | 1 |
| Main.main(String[]) | 1 | 1 | 2 | 2 |
| Powfunct.Powfunct(String) | 0 | 1 | 1 | 1 |
| Powfunct.devidePow(String) | 8 | 4 | 3 | 4 |
| Powfunct.equals(Object) | 2 | 2 | 3 | 3 |
| Powfunct.getBase() | 0 | 1 | 1 | 1 |
| Powfunct.getDr() | 1 | 4 | 3 | 4 |
| Powfunct.getExponent() | 0 | 1 | 1 | 1 |
| Powfunct.hashCode() | 0 | 1 | 1 | 1 |
| Powfunct.toString() | 0 | 1 | 1 | 1 |
| RegularExp.getAddminus() | 0 | 1 | 1 | 1 |
| RegularExp.getInittrigbase() | 0 | 1 | 1 | 1 |
| RegularExp.getPowfunctype() | 0 | 1 | 1 | 1 |
| RegularExp.getSpace() | 0 | 1 | 1 | 1 |
| RegularExp.getSymbolnum() | 0 | 1 | 1 | 1 |
| RegularExp.getTrigtype() | 0 | 1 | 1 | 1 |
| Term.Term(String) | 0 | 1 | 1 | 1 |
| Term.backTerm() | 9 | 3 | 4 | 6 |
| Term.devideTerm(String) | 12 | 1 | 11 | 12 |
| Term.eatSpace(String,int) | 8 | 4 | 6 | 8 |
| Term.eatSpaceFront(String,int) | 4 | 2 | 2 | 5 |
| Term.equals(Object) | 7 | 4 | 4 | 5 |
| Term.getCoe() | 0 | 1 | 1 | 1 |
| Term.getDr() | 19 | 3 | 9 | 11 |
| Term.hashCode() | 0 | 1 | 1 | 1 |
| Term.parseFactors(String,ArrayList<Const>,Map<Xitem, BigInteger>,Map<Trigfunct, BigInteger>) | 11 | 2 | 10 | 10 |
| Term.sortFactor(Factor,ArrayList<Const>,Map<Xitem, BigInteger>,Map<Trigfunct, BigInteger>) | 20 | 8 | 12 | 12 |
| Term.toString() | 0 | 1 | 1 | 1 |
| Trigfunct.Trigfunct(String) | 0 | 1 | 1 | 1 |
| Trigfunct.devideTrig(String) | 15 | 5 | 5 | 6 |
| Trigfunct.equals(Object) | 2 | 2 | 3 | 3 |
| Trigfunct.getDr() | 2 | 2 | 2 | 2 |
| Trigfunct.hashCode() | 0 | 1 | 1 | 1 |
| Trigfunct.toString() | 0 | 1 | 1 | 1 |
| Xitem.Xitem() | 0 | 1 | 1 | 1 |
| Xitem.equals(Object) | 0 | 1 | 1 | 1 |
| Xitem.getDr() | 0 | 1 | 1 | 1 |
| Xitem.hashCode() | 0 | 1 | 1 | 1 |
| Xitem.toString() | 0 | 1 | 1 | 1 |
可以看出方法的复杂度并不高,但大多方法集中在Expression和Term类中,因此应该添加更多的类将关系不紧密的方法分配出去。
个人评价
个人认为整体的层次分的比较清楚,比如每个类的层级和需要做的事情比较明晰和模块化。但每个模块内的方法层次不够清楚,耦合度太高。例如:加减求导法则,乘积求导法则,复合函数求导法则应该单独封装成一个类,而不是内嵌在类中;化简方法不应该内嵌在构造方法里,应该在类中单独实现化简方法,否则构造和化简就耦合在一起,浪费资源也引发意想不到的bug。
出现bug
1、中测中遇到的bug是括号添加的问题,每一个表达式求导之后需要加上括号再返回字符串,因为可能被乘积求导调用。对应方法为Expression类中的getDr方法,圈复杂度较高(20).
2、强测中遇到的bug是在Const类里的常数项化简方法里的,没有考虑到0的情况,处理时会将0全部吃掉,得到空串,从而运行出错。对应方法为Const类里的eatZero方法,圈复杂度不高(3)。
3、互测中遇到的bug是因为合并化简的方法和构造方法嵌合导致的,构造过程中幂指数不能超过50,但是求导过程中生成的幂指数是可以大于50的,直接调用构造方法可能会抛出异常,造成输出错误。对应方法是Term.devideTerm(12)、Term.sortFactor(20)、Term.parseFactor(11),三个方法实际上是一个方法,可见圈复杂度很高。
对比分析得出,前两个bug是细节上的问题,在进行方法交互时出现bug,第三个bug由于把方法嵌套在一起导致复用出错,即方法耦合度高。从圈复杂度来看,显然复杂度越高的方法出错率越高。
发现bug采用的策略
将自己编写程序中测试出的bug作为炮弹攻击别人。没有特别关注他人的代码结构。从结果来看这样的炮弹命中率不高,可见需要分析他人代码结构并有针对性地构造炮弹。
重构经历总结
三次作业,三次重构,下面放出三次作业的简单类图,对比显然。
第一次

第二次
第三次
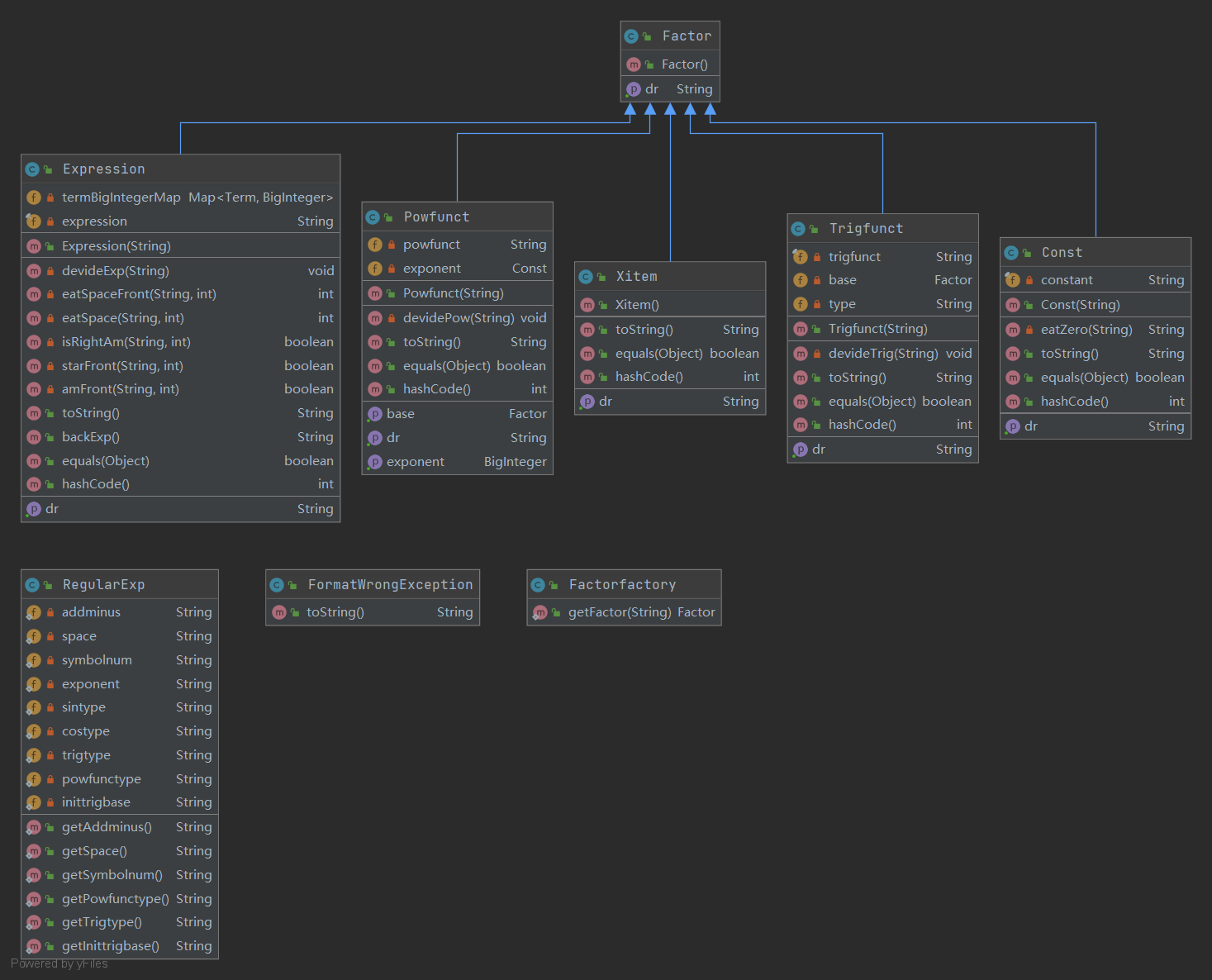
第一次作业纯面向过程编程,类之间分立,单个类复杂。
第二次作业建立了基本的继承关系,但接口和继承仍然关系不够明确,使用冗余,没有使用工厂类将构造对象的方法分离出去。没有使用Map等容器进行同类项的合并,最终结果性能低下。
第三次作业在第二次作业的基础上明晰了接口和继承的使用,新增了工厂类和正则表达式类等辅助类,新使用Map容器进行化简,提升性能。但求导法则没有独立成类,相反是放在各个因子的类中,使得类和求导存在耦合,求导方法复用度低。理想的划分类是求导方法单独成类,而每个因子类在求导方法中调用求导类中方法。存在比较复杂的类主要是因为处理字符时编写的函数,应该将这些字符处理函数也分离成一个类完成相应方法,降低类的复杂度。
心得体会
1、面向对象编程不是简单的将函数分离封装并调用,而是把一个复杂的工程或者项目分层分块去处理,从而让一个项目能够可行。
2、接口和类的区别。接口实际上也是类,所不同的是,接口里面只能包含方法的声明,且实现一个接口必须覆写接口中声明的方法(给声明的方法定义)。接口引用和父类引用都是观察一个对象的窗口,区别在于接口引用是去看这个对象实现的该接口的方法(Override),而父类引用是去看这个对象中和父类共有的属性和方法。关于接口和父类引用的用处在于对对象根据其共性进行分组管理(容器盛放),并通过强制类型转换(换成接口或者对象实际类型)去使用其方法或者观察其属性。
3、JAVA语言很优秀,写程序很方便,无论是调试还是自动补全又或者是各种功能丰富的插件都大大降低了编写程序的工作量。
4、本单元作业设计的很有层次,使我最后不得不面向对象编程,可以快速入门JAVA的基本语法和操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号