书籍-大数据技术入门笔记
0.前沿
PS:大数据的相关技术
框架:hadoop、spark
集群管理:Mapreduce、yarn、mesos
开发语言:java、Python、scala、pig、hive、spark SQL
数据库:NoSQL、HBase、Cassandra、impala
搜索系统:Elastic Search
采集系统:flume、sqoop、kafka
流式处理:spark Streaming、storm
发行版:horton works、cloudera、MapR
管理系统:Ambari、大数据管理平台
机器学习:Spark MLlib 、Mahout
1.大数据时代
PS:大数据最后也是为人服务的,根据数据预测分析未来
PS:云计算为计算资源的底层,支撑着上层的大数据处理
PS:大数据分析=数据+算法
2.大数据软件架构
HDFS
PS:Hadoop框架是java编写,核心是hdfs与MapReduce
PS:Secondary NameNode的作用
https://blog.csdn.net/remote_roamer/article/details/50675059
MapReduce
PS:看看MapReduce的处理示例
首先是切割数据,对指定数据进行键值对的操作,按照键值排序,reduce按所有的值统计
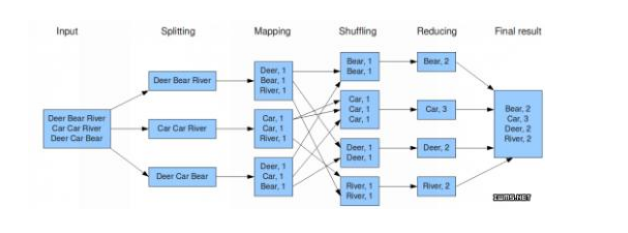
MapReduce进程示例
PS:jobTracker:是主节点,只有一个,管理所有的作业。老板
tasktracker:负责maptask、reducetask、shuffle等操作。 包工头、包身工
sort会对键值进行排序,shuffle会把键值相同元素发给同一个reduce函数
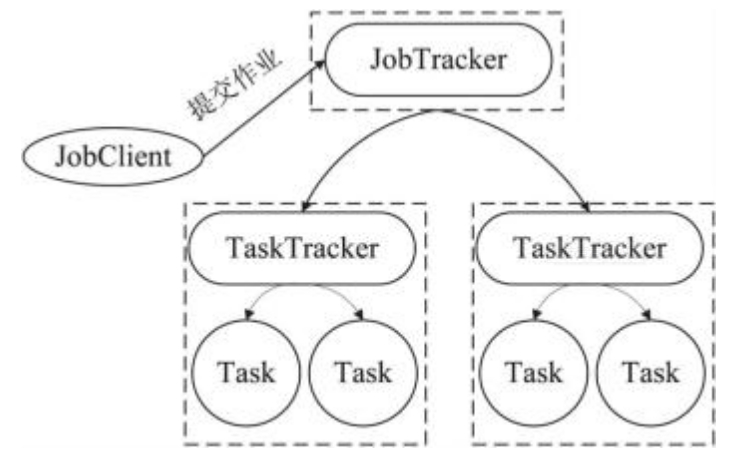
PS:现在已经用MapReduce写并行程序了,通常都是用spark等工具来写
Yarn(另一种资源协调者)
PS:在早期,MapReduce是上图的那种情况,用着还不错。但是hadoop 2出来后,情况就改变了,传统的架构模式无法胜任,就出现了yarn。最初是为了修复MapReduce的不足。 他把老的jobtracker核心任务分为 resource manager(全局资源管理)和app Master
PS:resource manager就是一个调度器
node manager是没太机器的代理,执行应用程序的容器
app master是一个框架库,从上面两者协同运行与监控任务
cantainer是yarn为了资源隔离提出的一个框架
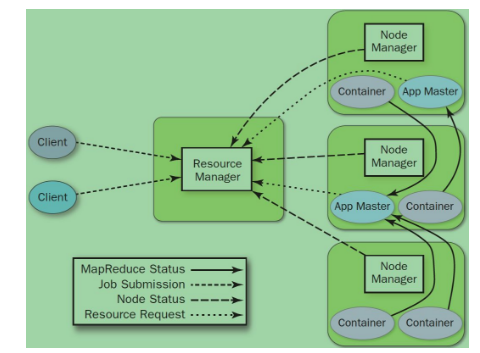
总之,yarn可以说是一个云操作系统,她负责集群的资源管理。 Spark也是支持yarn 的
Zookeeper统一分布式系统的状态
PS:Zookeeper是一个集中式的服务,主要负责分布式任务调度,它用来完成 配置管理,名字服务,分布式锁以及集群管理等工作。
Ambari
PS:他是一种基于web的hadoop管理工具
Spark(内存计算框架) 实时
PS:Spark是类似于Hadoop的Mapreduce。不同在于1.输出结果保存在内存中,(mapreduce->HDFS);2.速度快;3.spark对内存要求非常高,
一个节点通常要24g
PS:Hadoop使用数据复制来实现容错性;Spark使用RDD(resilient distributed datasets,弹性分布式数据集)数据模型来实现数据的容错性。
PS:特别支持scala编写程序,特别适合机器学习。 下图是spark的组件
![]()
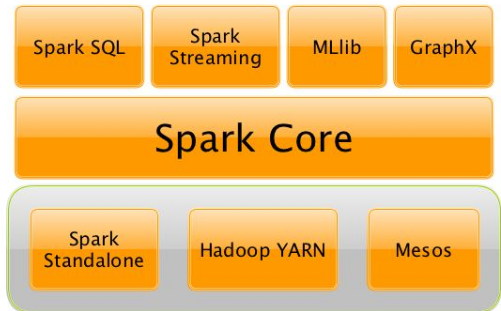
PS:spark很牛逼。但是批处理能力还是不如MapReduce;
spark sql和hive sql还是有差距;
spark的统计功能和r语言没有可比性
Scala
PS:Spark是用scala开发的。scala把源文件编译成class文件,运行在jvm上,并且
兼容现有的java程序,可以调用java中的类库。
PS:回头可以看看《Scala编程思想》
Spark SQL
PS:考虑到大家还是习惯用sql访问数据,设计人员给予HDFS现有的RDD执行SQL查询;他的发展是基于hive和shark
Spark Streaming
PS:是基于Spark引擎对数据流进行不断的处理。
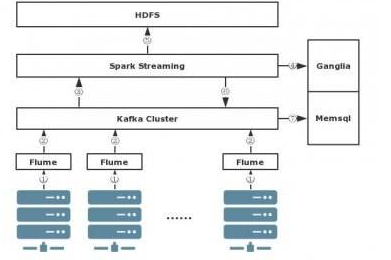
PS:下图为spark Streaming的案例。
flume采集日志数据,然后kafka集群(以高可靠性收集与缓冲数据),然后再从kafka集群中不断的拉数据,最后解析日志。
![]()
3.安装与配置大数据软件
PS:Hadoop有很多的发行版,主要有三个。Apache、cloudera、还有hortonworks(我们用的就是这个cenos6.5)
PS:在给服务器安装配置hadoop的时候,还要保持主机时间的同步,就需要NTP
4.大数据存储:文件系统
HDFS文件格式
1.SequenceFile
PS:他是一种二进制文件,以key,value形式序列化到文件中。
2.TextFile(文本格式)
PS:文本文件、xml、json都是文本格式,速度没有二进制的快
3.RCFile
PS:列存储,hive就是这样做的
4.Avro
PS:是一种支持数据密集型的二进制文件
5.大数据存储:数据库
NoSql
PS:not only SQL,泛指 非关系数据库;Nosql之一的HBase比较在大数据领域比较常用。
HBase是非常好的实时查询框架
PS:HBase使用key-value存储,HDFS作为存储支持,使用MapReduce提供计算能力。
PS:HBase与RDBMS的区别
https://www.cnblogs.com/wishyouhappy/p/3715566.html
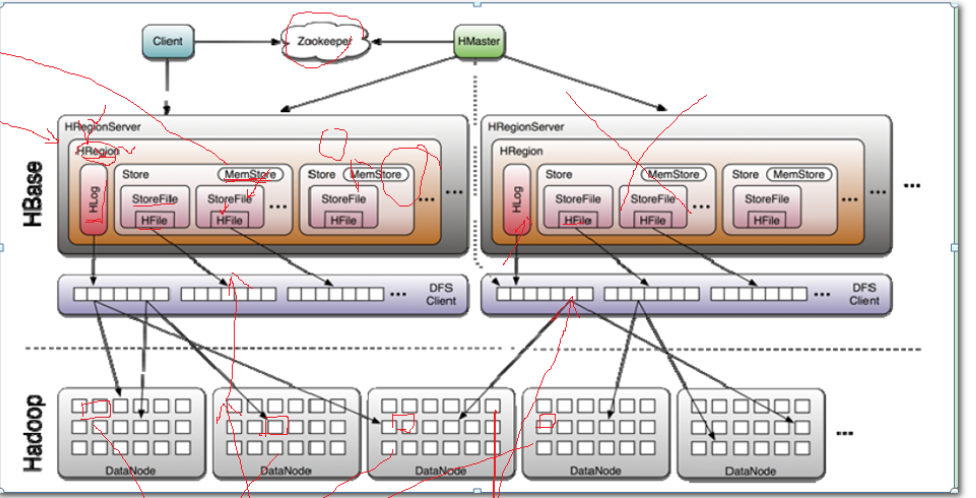
PS:HBase架构
1.client、HMaster、HRegionServer通过内部的RPC通信协议进行通信。
2.HMaster主要负责Table和Region的管理工作,可以有多个
3.HRegionServer主要负责相应用户io请求,向HDFS读写数据,是HBase中的核心模块。HReginServer又是由多个Hregion对象组成
4.HRegion每个HRegion对应着Table中的一个Region。每个Hregion由多个HStore组成。
5.HStore:每个HStore对应着Table里的Column Family。他是存储的核心,由两部分组成,一个是MemStore,另一个是StoreFiles.
当有数据写入的时候,会先到MemStore,当MemStore满了以后会flush成一个StoreFiles(MemStore就是一个临时存放点);当StoreFiles
达到一定的个数的时候会合并成一个。
6.Hlog是在数据在写入MemStore的时候,同时也会在Hlog 中放置一份。当出现宕机的是时候,会从Hlog中取数据,保证数据不被丢失
PS:HBase编程
整个数据模型Schema->Table->Column Family->Column->RowKey-》TimeStamp->Value
6.大数据访问:SQL引擎层
Phoenix
PS:因为HBase访问比较麻烦,还是列式,有专用的访问方法。那么Phoenix就出现了,他是一个中间层。专门用来JDBC API来创建查询表,比较方便。
他会把JDBC API转化成 HBase的scan和服务端的过滤器,执行后生成标准的JDBC结果返回。
就是让开发任用SQL和JDBC访问Hbase。
Hive 非实时、面向批处理
PS:因为Mapreduce写起来比较麻烦,所以使用Hive运行类似SQL的语言来执行MapReduce程序。
PS:hive查询有一定的延时性,通常用来静态(离线)的数据分析和挖掘。
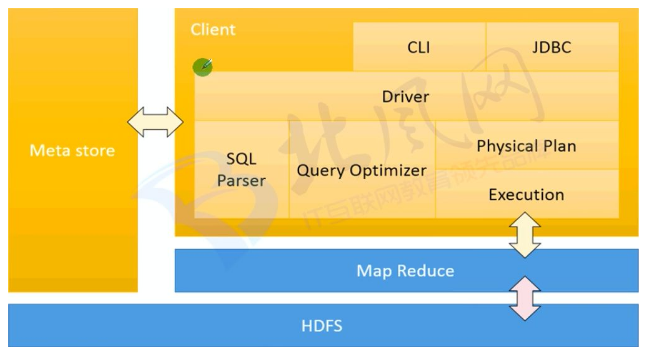
Hive架构图 ;
1.JDBC是编程接口
2.驱动器对输入进行编译、优化和执行
3.MetaStore(元数据存储)是一个独立的RDBMS,默认是Derby。对于生产系统推荐使用mysql
PS:如果需要实时查询可以将HBase和Hive结合在一起使用Tez
PS:Hive只用查询、分析和聚集数据(无增删改)
PS:通过hive可以将hdfs上的数据映射到数据库中
Hive的数据类型
https://blog.csdn.net/xiaoqi0531/article/details/54667393
PS:支持高度定置化,满足各种需求,不用借助外部方式就能够完成自己工作。
Pig
PS:和Hive提供功能类似,简单的对比
https://blog.csdn.net/dashujuedu/article/details/53538609
ElasticSearch(全文搜索引擎)
PS:是基于Lucene的实时的分布式搜索分析引擎
7.大数据采集和导入
任何完整的大数据平台,都是以下过程:
数据采集、数据存储、数据管理、数据处理、数据展现
PS:通常都是采集网站中的日志,采集的工具使用Flume和kafka
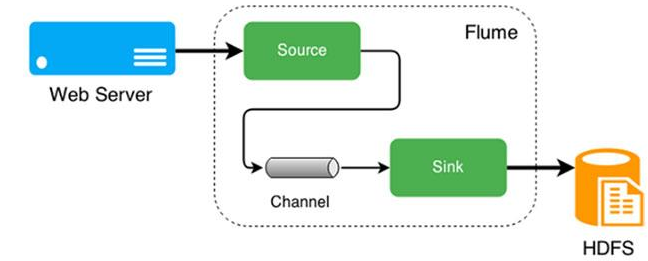
Flume
PS:她将数据从产生、传输、处理并最终写入目标路径的过程抽象为数据流。
PS:事件是flume传递的一个数据单元
kafka(分布式消息队列)
PS:用在不同系统之间传递数据
PS:Kafka架构---依赖于zookeeper
Broker:Kafka集群包含一个或者多个服务器,该服务器被称为broker
Producer:在消息保存的时候,会对topic进行分类,发送消息的叫做producer,接受者叫consumer
Topic:集群中的消息都有一个类别,叫做topic;一个topic的消息保存在一个或者多个broker上面;消息是按照topic组织的,每个topic又分为多个partition(为了负载均衡)
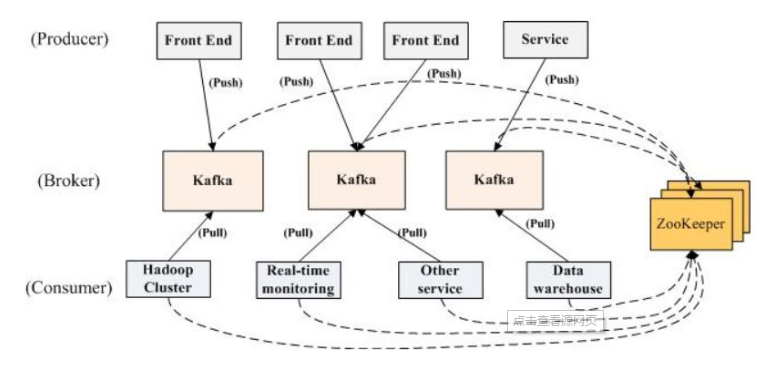
Sqoop(SQL to Hadoop)
PS:他是数据库导入导出工具,HDFS<->关系型数据库;使用MapReduce实现的;通常用在linux环境中。
Storm实时计算
http://www.cnblogs.com/bee-home/p/8591302.html

splunk
PS:使用splunk可以搜集、索引和分析所用应用程序所生成的实时数据。
8.大数据管理平台
PS:
9.Spark技术
PS:Spark主要是替换Mapreduce计算模型而已; Spark应用程序,他建立在同一抽象的RDD之上
PS:主程序(叫做Driver)中的sparkcontext对象协调spark应用程序。sparkcontext对象首先连接到多种集群管 理器(如:yarn),
然后在集群点上获得Executor。sparkcontext把 应用代码发给executor,exe cutor负责应用程序的计算和数据存储。
每个应用程序都有自己Executor.Executor为应用程序提供一个隔离的运行环境,以task 的形式执行任务。
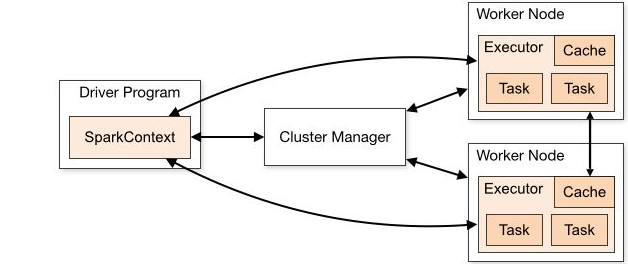
PS:文本在被读入的过程中,会被RDD分区,然后分发到集群中并行化操作。RDD支持两种类型的操作。
**action: 在数据集上运行计算后返回结果值
**transformations:转换。从现有的RDD创建一个新的RDD
PS:RDD(弹性分布式数据集)
分区(partiion):一个RDD由多个分区partition组成
算子(compute):用于说明在RDD上执行何种计算,可以理解为函数。;算子是RDD中定义的函数,Spark在运行过程中通过算子对RDD进行创建、转换和行动。
依赖(dependency):计算每个RDD对父RDD的依赖列表
PS:下面按照数据处理步骤描述各个算子
1.输入:在spark程序运行中,数据从hdfs或parallelize方法输入scala集合或者数据到spark创建RDD,数据进入spark空间。
2.运行:在spark输入数据形成RDD后便可以通过变换算子,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发spark提交作业。如果数据需要复用,可以通过cache算子,
将数据缓存到内存。
3.输出:程序运行结束后,数据会存储到分布式存储中(如saveASTextFile输出到HDFS),或scala数据或集合中(collect输出到scala集合,count返回scala int型数据)
PS:Spark SQL
PS:Spark Streaming
PS:GraphX图计算模型
10.大数据分析
主要包含
1.数据挖掘算法 2.大数据预测性分析 3.可视化分析
PS:
posted on 2018-03-29 10:04 biyangqiang 阅读(2101) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号