使用python批量爬取wallhaven.cc壁纸站壁纸
偶然发现https://wallhaven.cc/这个壁纸站的壁纸还不错,尤其是更新比较频繁,用python写个脚本爬取
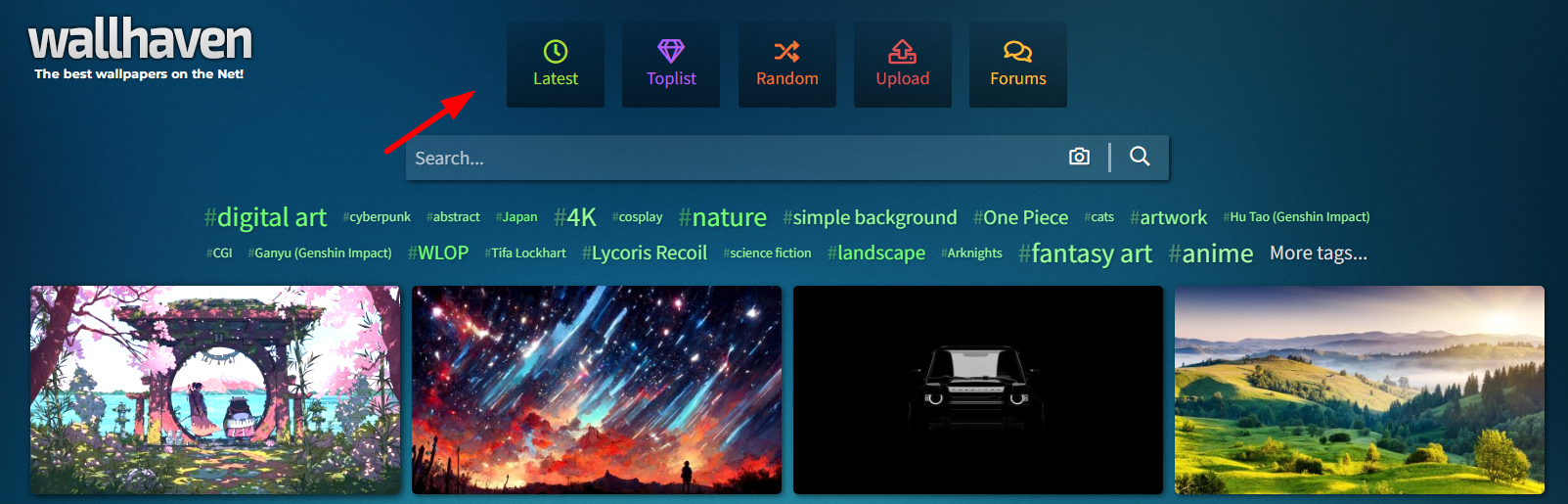
点latest,按照更新先后排序,获得新地址,发现地址是分页展示的,每一页24张
本案例使用xpath爬虫爬取数据,先分析网页,使用浏览器查看元素工具,快速定位到图片元素所在位置,且存在规律性
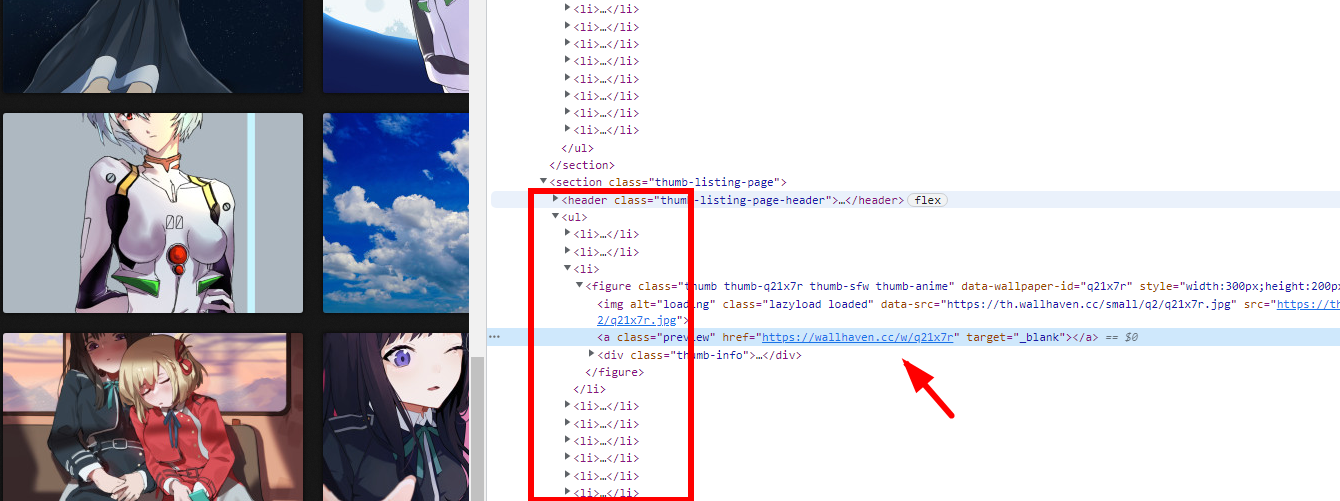
首先爬取一级页面获取图片页面地址(点了上图箭头的地址会打开图片详细页,并非图片真实地址),xpath提取数据的代码如下
html = requests.get(url=url1, headers=headers, timeout=5.0).text data = etree.HTML(html) li_list = data.xpath('.//div[@id="thumbs"]//@href')
执行后爬取出一连串的地址信息

对里面包含“latest”的地址进行剔除,这个地址非图片地址,然后再循环请求图片地址,获取真实图片地址
for li in li_list: if 'latest' in li: continue else: html_li = requests.get(url=li, headers=headers, timeout=5.0).text data = etree.HTML(html_li) li_add = data.xpath('//*[@id="wallpaper"]//@src') li_add = li_add[0] print(li_add)
执行后输出真实图片地址
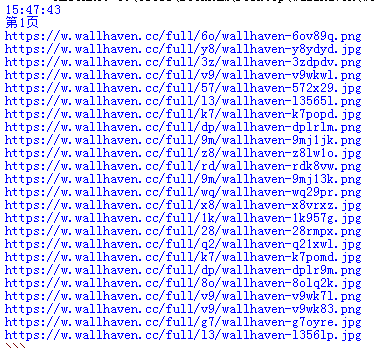
把这些地址写到一个txt文本内,然后通过迅雷去下载,效率会高一些,当然也可以爬取后执行使用python下载,单线程下蛮久的。先上保存到txt内的全部代码
# -*- codeing = utf-8 -*- import requests from lxml import etree import time import random import time def getBZ(): url='https://wallhaven.cc/latest?page={}' # 翻页10页 for page in range(1, 10): headers = { # 'referer': 'https://wallhaven.cc/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } print(time.strftime("%H:%M:%S")) print("第{}页".format(page)) url1 = url.format(page) print(url1) # 一级页面请求 html = requests.get(url=url1, headers=headers).text data = etree.HTML(html) li_list = data.xpath('.//div[@id="thumbs"]//@href') for li in li_list: if 'latest' in li or 'top'in li: continue else: print(li) html_li = requests.get(url=li, headers=headers) print(html_li.status_code) if html_li.status_code == 404 or html_li.status_code == 429:#判断,如果响应失败跳过这次数据抓取 continue else: data = etree.HTML(html_li.text) li_add = data.xpath('//*[@id="wallpaper"]//@src') li_add = li_add[0] with open('1538.txt', 'a',encoding='utf-8') as w: w.write(li_add+'\n') w.close() b = random.randint(1,2)#随机从1到2内取一个整数值 print("等待"+str(b)+"秒") time.sleep(b)#把随机取出的整数值传到等待函数中 getBZ()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号