
python爬虫爬取B站视频字幕,简单的数据处理(pandas将字幕写入到CSV文件中)
上文,我们爬取到B站视频的字幕:https://www.cnblogs.com/becks/p/14540355.html
这篇,讲讲怎么把爬到的字幕写到CSV文件中,以便用于后面的分析
本文主要用到“pandas”这个库对数据进行处理
import pandas as pd
首先需要对爬取到的内容进行数据提取
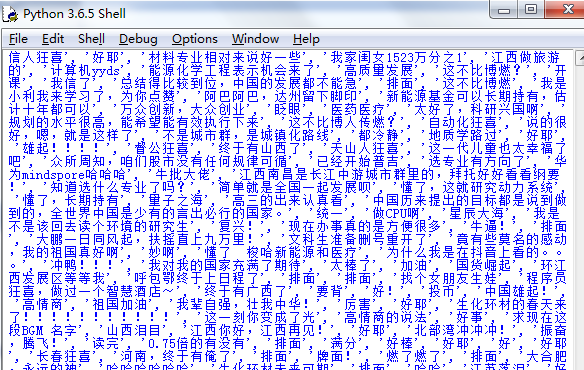
comments = [comment.text for comment in results]#从爬取的数据中取出弹幕数据,返回文本内容
执行后如下图
然后生成字典
comments_dict = {'comments': comments}#创建字典,把字幕内容装入字典
处理数据,使数据以表格形式展示
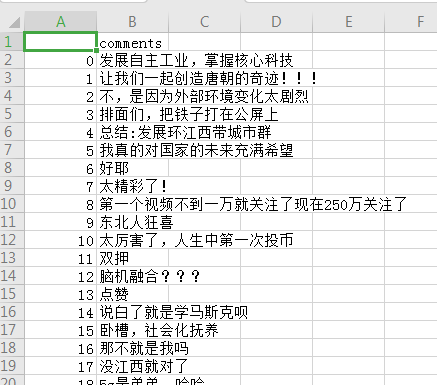
df = pd.DataFrame(comments_dict)#格式化字幕字典,将字幕内容已表格格式显示
效果如下图

把格式化后的数据,存到CSV文件中
df.to_csv('B站字母.csv', encoding='utf-8-sig')#格式化后的字幕内容写入到CSV文件中
执行后,会在脚本同目录下生成CSV文件,文件内容如下图
全部脚本
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests import re import pandas as pd url = 'http://comment.bilibili.com/309778762.xml' html = requests.get(url) html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml') results = soup.find_all('d') comments = [comment.text for comment in results]#从爬取的数据中取出弹幕数据,返回文本内容 comments_dict = {'comments': comments}#创建字典,把字幕内容装入字典 df = pd.DataFrame(comments_dict)#格式化字幕字典,将字幕内容已表格格式显示 df.to_csv('B站字母.csv', encoding='utf-8-sig')#格式化后的字幕内容写入到CSV文件中
格式化数据“pd.DataFrame”函数的用法可以参考,https://www.cnblogs.com/andrew-address/p/13040035.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号