
python爬虫,beatifulsop获取标签属性值(取值)案例
前面的案例里,均采用正则匹配的方式取值
title = re.findall('">(.*?)</a>', i, re.S)[0]#标题 url = re.findall('="(.*?)" target', i, re.S)[0]#地址
这么写的容错能力有限,爬取的数据越多,越容易出现匹配不到内容的情况
这次采用获取属性值的方式取值,除非属性变化,否则基本不会出现错误
爬取下图内链接红色框内文章标题和链接
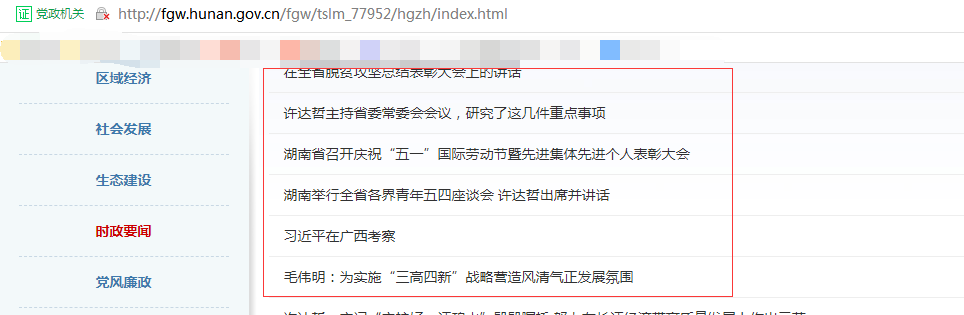
目标内容html结构如下图
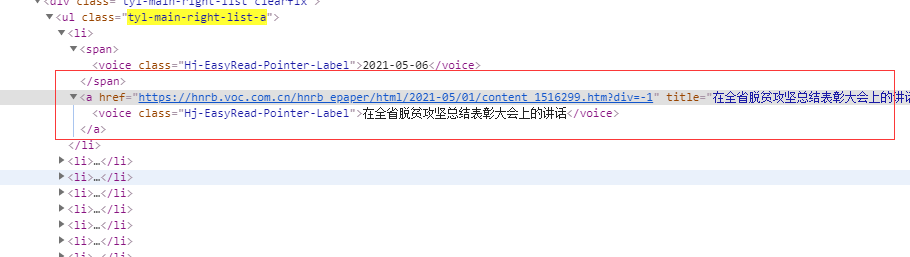
可见,href的值是链接,title的值是标题,所以,获取对应内容的写法如下
title = i.get("title")#地址 url = i.get("href")#地址
因为目标数据是通过匹配所有“a”标签来获取的,所有有一部分数据并不是本次案例需要的,为了使爬取的内容更加精简,所以对soup.find_all的匹配规则进行的补充
以前是直接写成“results = soup.find_all('a')”,后发现目标数列里有共同的“target='_blank'”内容,其他“a”内没有,所可以写成“results = soup.find_all('a', target='_blank')”

上面两处修改,使脚本爬取更加精准有效,容错能力得到提升
附全部代码
from bs4 import BeautifulSoup import requests import time fgwurl = 'http://fgw.hunan.gov.cn/fgw/tslm_77952/hgzh/index.html' def fgw(fgwurl): response = requests.get(fgwurl) response.encoding='utf-8' soup = BeautifulSoup(response.text,'lxml') results = soup.find_all('a', target='_blank')for i in results: h=str(i) if "title" in h: #title = i.get_text()#标题 title = i.get("title")#地址 url = i.get("href")#地址 print(title +" "+ "详情请点击" + " " + url) else: None fgw(fgwurl)
参考链接:
https://blog.csdn.net/jaray/article/details/106604362
https://www.cnblogs.com/kaibindirver/p/9927297.html
http://blog.sina.com.cn/s/blog_166ae58120102xomk.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号