python爬虫(BeautifulSoup)爬取B站视频字幕
比如“https://www.bilibili.com/video/BV1zU4y1p7L3”这个视频,有1.2万条弹幕
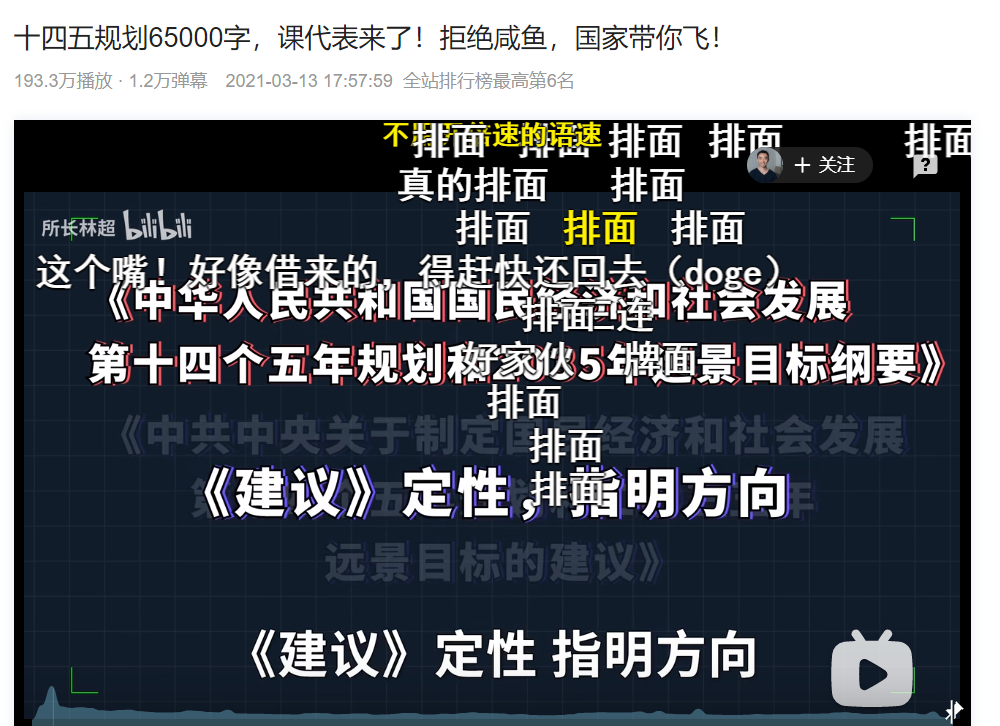
首先,B站视频的弹幕是有专门的接口传递数据的:http://comment.bilibili.com/***.xml,中间的*号是播放视频的id,怎么获取?
播放视频的时候按F12键,选择找到heartbeat,拉到最下方formdata内有cid字样即视频id
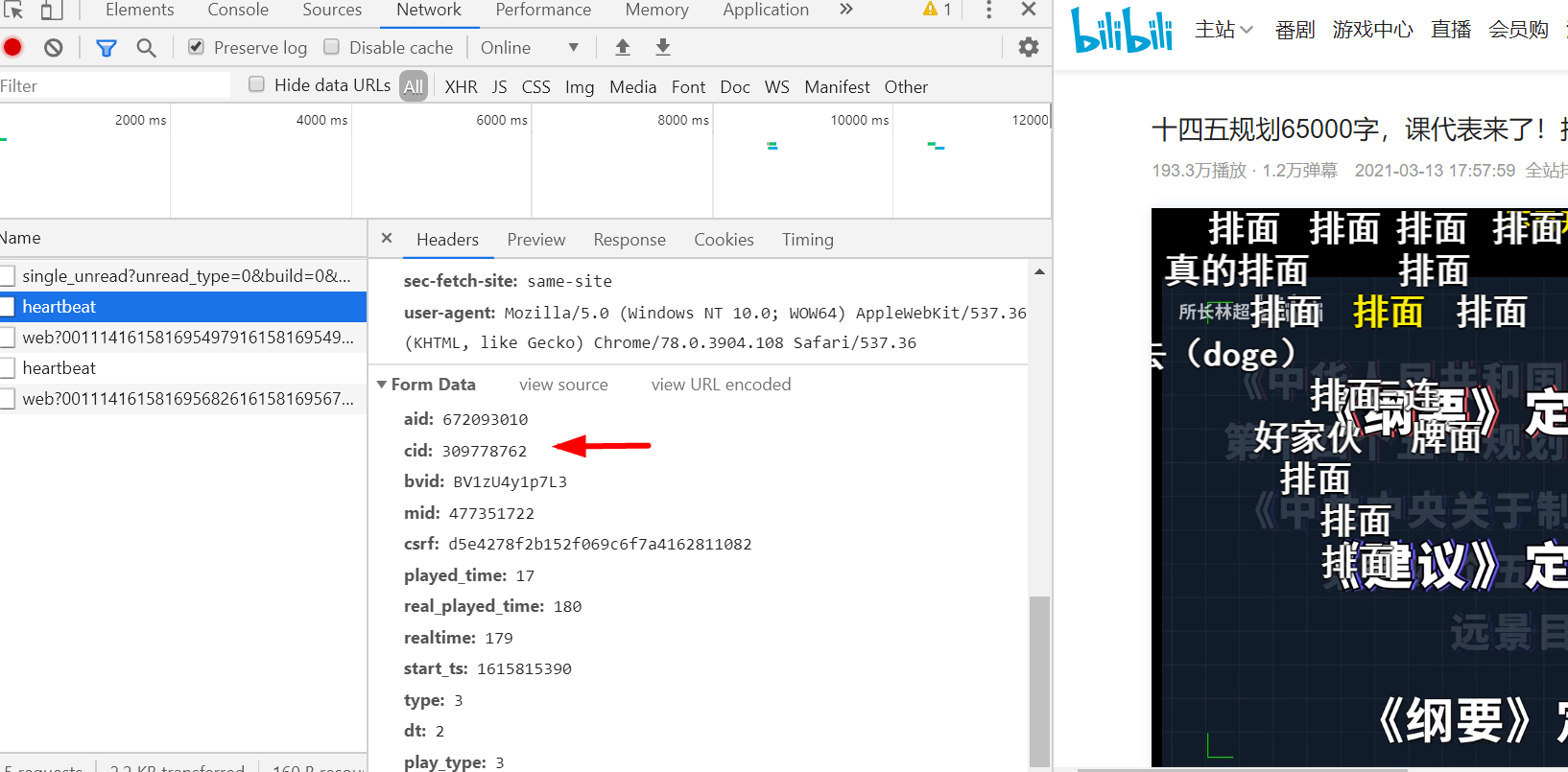
访问地址,http://comment.bilibili.com/309778762.xml拿到弹幕,但是这个接口只提供1000多条弹幕数据

接下来,我们将数据全部爬取下来,本次就不使用xpath爬虫来提取数据,使用BeautifulSoup来提取数据
网上安装BeautifulSoup教程很多,这里不表,导入BeautifulSoup库
from bs4 import BeautifulSoup import requests import re
爬取数据部分
url = 'http://comment.bilibili.com/309778762.xml' html = requests.get(url) html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml') results = soup.find_all('d')
前面4行理解起来问题不大,常规步骤,关键在最后一行find内,可以表述问,查找文内所有标签“d”的内容
因为弹幕的内容都存放在标签d内

关于find_all的解析,请参看:https://www.cnblogs.com/keye/p/7868059.html,讲的很清楚
然后就是对获取数据的处理,只需要保留弹幕内容
for i in results: i = str(i) i = re.findall('">(.*?)</d>', i, re.S)[0] print(i)
全部脚本如下
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests import re url = 'http://comment.bilibili.com/309778762.xml' html = requests.get(url) html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml') results = soup.find_all('d') for i in results: i = str(i) i = re.findall('">(.*?)</d>', i, re.S)[0] print(i)
打印输出
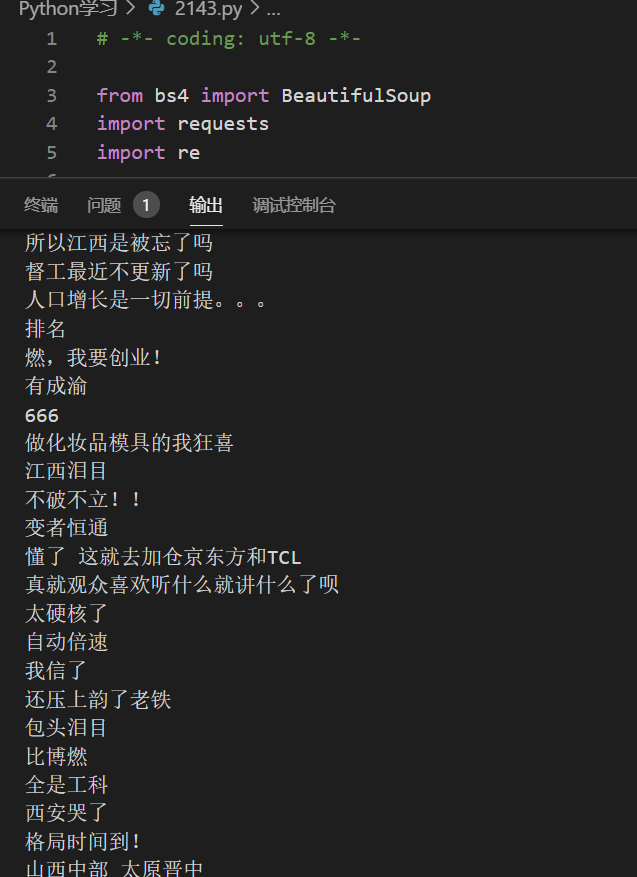
至于爬出来的数据怎么用,可以统计字频,获取做成词云(下图),那是后面研究的了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号