会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
Beavers
博客园
首页
新随笔
联系
订阅
管理
2015年8月21日
数据挖掘之关联分析七(非频繁模式)
摘要: #非频繁模式**非频繁模式**,是一个项集或规则,其支持度小于阈值minsup.绝大部分的频繁模式不是令人感兴趣的,但其中有些分析是有用的,特别是涉及到数据中的负相关时,如一起购买DVD的顾客多半不会购买VCR,反之亦然,这种负相关模式有助于识别竞争项(competing item),即可以相互替代...
阅读全文
posted @ 2015-08-21 13:43 Beavers
阅读(6567)
评论(0)
推荐(2)
2015年8月20日
数据挖掘之关联分析六(子图模式)
摘要: ##子图模式**频繁子图挖掘**(frequent subgraph mining):在图的集合中发现一组公共子结构。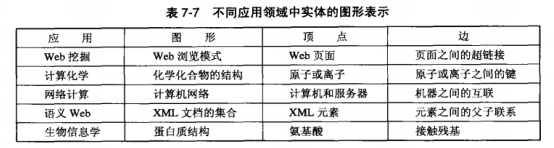###图和子图图是一种用来表示实体...
阅读全文
posted @ 2015-08-20 16:12 Beavers
阅读(13957)
评论(0)
推荐(4)
2015年8月19日
数据挖掘之关联分析五(序列模式)
摘要: 购物篮数据常常包含关于商品何时被顾客购买的时间信息,可以使用这种信息,将顾客在一段时间内的购物拼接成事务序列,这些事务通常基于时间或空间的先后次序。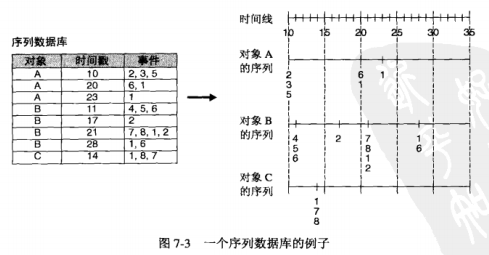##...
阅读全文
posted @ 2015-08-19 19:41 Beavers
阅读(14002)
评论(3)
推荐(2)
2015年8月18日
数据挖掘之关联分析三(规则的产生)
摘要: #规则产生忽略那些前件和后件为空的规则,每个频繁k项集能够产生$2(2^k-1)$个关联规则。将频繁项集Y划分为两个非空子集X和Y-X,使得$X \to Y-X$能满足置信度阈值,就可以得到满足条件的规则。在计算规则的置信度时并不需要再次扫描事务数据集,因为产生规则的频繁项集和它们的子集也都是频繁项...
阅读全文
posted @ 2015-08-18 22:20 Beavers
阅读(6008)
评论(0)
推荐(1)
数据挖掘之关联分析二(频繁项集的产生)
摘要: #频繁项集的产生**格结构**(lattice structure)常常用来表示所有可能的项集。发现频繁项集的一个原始方法是确定格结构中每个候选项集的支...
阅读全文
posted @ 2015-08-18 21:58 Beavers
阅读(26115)
评论(0)
推荐(2)
数据挖掘之关联分析一(基本概念)
摘要: 许多商业企业运营中的大量数据,通常称为购物篮事务(market basket transaction)。表中每一行对应一个事务,包含一个唯一标识TID。
评论(0)
推荐(1)
数据挖掘之关联分析四(连续属性处理)
摘要: #处理连续属性挖掘连续属性可能揭示数据的内在联系,包含连续属性的关联规则通常称**作量化关联规则**(quantitative association rule)。主要讨论三种对连续数据进行关联分析的方法1. 基于离散化的方法2. 基于统计学的方法3. 非离散化方法##基于离散化方法离散化是处理连续...
阅读全文
posted @ 2015-08-18 20:39 Beavers
阅读(8799)
评论(0)
推荐(1)
2015年8月17日
Python学习随笔(2)之词汇语法约定
摘要: [Python简介](http://www.cnblogs.com/beaver-sea/p/4735192.html)#行结构和缩进在Python中,分号是可选的,当使用分号时,可以将多条语句写在一行上,否则,程序的每条语句都是以换行符结束,可以使用斜杠\另起一行,将长语句分为几行```In [1...
阅读全文
posted @ 2015-08-17 21:19 Beavers
阅读(548)
评论(0)
推荐(0)
2015年8月16日
Python学习随笔(1)之Python简介
摘要: Python初探,学习Python手册,了解一些基本的Python知识
阅读全文
posted @ 2015-08-16 22:37 Beavers
阅读(724)
评论(0)
推荐(0)
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号