
AI-2.梯度下降算法
上节定义了神经网络中几个重要的常见的函数,最后提到的损失函数的目的就是求得一组合适的w、b
先看下损失函数的曲线图,如下
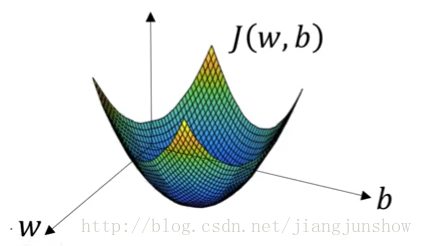

即目的就是求得最低点对应的一组w、b,而本节要讲的梯度下降算法就是会一步一步地更新w和b
通过公式w’ = w – r * dw 改变w的值
梯度下降算法就是重复的执行上面的公式来不停的更新w的值,新的w的值(w’)等于旧的w减去学习率r与偏导数dw的乘积。r表示学习步进/学习率(learning rate),假设w是10,又假设dw为1,r为4时,那么在第一次梯度下降后,w’的值将变成6,而当r为2时,那么第一次下降后,w’将是8,从10变成了8比起从10变成6,变化得没有那么大,因为变化率r比较小。r是我们用来控制w的变化步进的参数。dw是参数w关于损失函数J的偏导数,偏导数说白了就是斜率。斜率就是变化比例,即当w改变一点点后J会相应的改变多少。看上图中的黄色的小三角,在w的初始值(假设为6)的位置的偏导数/斜率/变化比例就是小三角的高除以低边(J的变化除以w的变化),也就是在当w为6时J函数的变化与w的变化之比,曲线越陡,那么三角形越陡,那么斜率越大,那么当w的值改变一丁点后(例如减1)那么J相应的改变就会越大(假设会减小3),在下面那个小三角的位置(假设那里的w是4),这个位置的曲线不是那么的陡,即斜率比较小,那么在那里w的值改变一点后(例如也减小1)但J相应的改变却没有那么大了(可能只减小1.5)。这个斜率dw就是J的变化与w的变化的比例,就是说,我们按照这个比例去使w越来越小那么它相应的J也会越来越小,最终达到我们的目的,找到J最小值时w的值是多少。损失函数J的值越小,表示预测越精准。神经网络就是通过这种方法来进行学习的,通过梯度下降算法来一步一步改变w和b的值,使损失函数越来越小,使预测越来越精准。
要解释下这里的r,用它来控制w改变的步进,避免错过w的最佳值,所以选对一个r很重要,至于如何选择,后续介绍啦~

