
awk除去重复行
awk去除重复行,思路是以每一行的$0为key,创建一个hash数组,后续碰到的行,如果数组里已经有了,就不再print了,否则将其print
测试文件:

用awk:
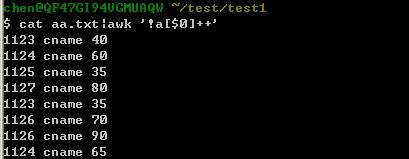
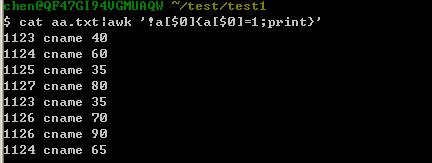
用sort+uniq好像出错了:
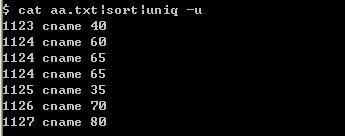
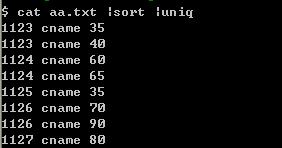
到底是为什么uniq出错了呢?不知道,但是awk真的很强大。两者的差异还在于,awk保持了文件中原本的每行的顺序,而sort必须排序,这样就变成按字母或某种其他规则的排序了。
PS:uniq出错好像是因为\r\n的问题。
PS:错了。有的教程上,uniq -u就跟uniq是一样的。我用cygwin,uniq- u只显示不重复行,uniq则显示所有行,只不过去除重复。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号