开发一款浏览器内核需要学习哪些方面的知识?
开发一款浏览器内核需要学习哪些方面的知识?
最近参加毕业设计,题目选的是《基于Linux平台的网页浏览器设计与实现》。
想认真做一下,所以不准备直接用现成的开源浏览器内核(比如WebKit或者KHTML这些)来做套壳,而是打算自己用C/C++从零开始,裸的写一个简单的浏览器内核,也就是所谓的排版引擎或者网页渲染引擎。考虑到自己的能力,目标暂定为能够支持html1.0。
但是最近几天在网上搜索了一下,国内似乎没有相关的资料或者书籍。所以来知乎问问各位前辈,开发一款浏览器内核需要学习哪些方面的知识?或者在哪里能够找到相关资料?
不胜感激。
=====================================
20130123 1825 更新:
自己能想到的部分是解析html、CSS和JavaScript这些应该会涉及到编译解释方面的知识,其他的部分,比如涉及到网络的方面就不甚了解了。
希望大家原谅我这种算偷懒的行为吧~~
想认真做一下,所以不准备直接用现成的开源浏览器内核(比如WebKit或者KHTML这些)来做套壳,而是打算自己用C/C++从零开始,裸的写一个简单的浏览器内核,也就是所谓的排版引擎或者网页渲染引擎。考虑到自己的能力,目标暂定为能够支持html1.0。
但是最近几天在网上搜索了一下,国内似乎没有相关的资料或者书籍。所以来知乎问问各位前辈,开发一款浏览器内核需要学习哪些方面的知识?或者在哪里能够找到相关资料?
不胜感激。
=====================================
20130123 1825 更新:
自己能想到的部分是解析html、CSS和JavaScript这些应该会涉及到编译解释方面的知识,其他的部分,比如涉及到网络的方面就不甚了解了。
希望大家原谅我这种算偷懒的行为吧~~
按投票排序按时间排序
16 个回答

恭喜你选了一个好题目。你横跨了网页开发,网络,编译原理,图形,网页开发等几个方面。
网页开发:你要知道inline与block有什么不同,什么是box model,ie是怎么实现的,标准的是怎么样的。
网络方面:浏览器会使用URL,表单提交,下载,DNS等一系列知识,深一些的比如说在chrome下面输入chrome://dns,看看什么叫 prefetch DNS,浅一点至少要知道怎么实现表单提交,表单提交分那些格式。在网络那一层要怎么拼。
编译原理:简单的是状态机,具体的是CSS的解析,Javascript的解析。其实光HTML,CSS的解析就够做一个毕设的了,据一个简单的例子,浏览器是边下载边解析,边显示的,这个地方就有不少的坑等着你,光拿一个开源的xml解析器可不行,html的解析中还有图文混排等功能,整个地方又是无数的坑。 就不要说javascript的引擎了,龙书中写的只是一小部分,里面还牵涉到什么JIT等一大堆东西。
图形:硬件加速,你在chrome浏览器中地址栏中输入 chrome://gpu ,里面出现频率最高的就是Hardware accelerated
如果你真要做,准备把所有的时间放在chromium与webkit两个网站上吧,但是就算这样,里面有很多东西也不会说,比如说边下载边解析,这张东西在他们看来太简单了,里面根本就没有文档。URL的转义也是。看标准是一回事,但是有些东西根本在RFC中不会说,比如说URL的长度,整个就没有标准,但是通常浏览器都会是2048以上。
如边疆所说,怎么简化怎么来吧,比如说做个WAP1.0的浏览器,这个木有javascript,木有css,就是URL转义,wap标签显示,表单的提交。
网页开发:你要知道inline与block有什么不同,什么是box model,ie是怎么实现的,标准的是怎么样的。
网络方面:浏览器会使用URL,表单提交,下载,DNS等一系列知识,深一些的比如说在chrome下面输入chrome://dns,看看什么叫 prefetch DNS,浅一点至少要知道怎么实现表单提交,表单提交分那些格式。在网络那一层要怎么拼。
编译原理:简单的是状态机,具体的是CSS的解析,Javascript的解析。其实光HTML,CSS的解析就够做一个毕设的了,据一个简单的例子,浏览器是边下载边解析,边显示的,这个地方就有不少的坑等着你,光拿一个开源的xml解析器可不行,html的解析中还有图文混排等功能,整个地方又是无数的坑。 就不要说javascript的引擎了,龙书中写的只是一小部分,里面还牵涉到什么JIT等一大堆东西。
图形:硬件加速,你在chrome浏览器中地址栏中输入 chrome://gpu ,里面出现频率最高的就是Hardware accelerated
如果你真要做,准备把所有的时间放在chromium与webkit两个网站上吧,但是就算这样,里面有很多东西也不会说,比如说边下载边解析,这张东西在他们看来太简单了,里面根本就没有文档。URL的转义也是。看标准是一回事,但是有些东西根本在RFC中不会说,比如说URL的长度,整个就没有标准,但是通常浏览器都会是2048以上。
如边疆所说,怎么简化怎么来吧,比如说做个WAP1.0的浏览器,这个木有javascript,木有css,就是URL转义,wap标签显示,表单的提交。

<!-- rant: 又是这种(我最讨厌的)罗列性问题,如果你连该做什么都不知道,为什么要选这个题目?问这种问题就是希望别人把知识咀嚼好了喂给你,有意思么? --!>
找不到资料是因为你不会找,找的方向不对,用的关键字不对,用的搜索引擎不对,以及用的语言不对。下面是我觉得有价值的资料: 另外注意现代浏览器渲染引擎结构早就不是为了 HTML 1.0 设计了,支持的语法不是简单的 SGML,还要支持 CSS 和 JavaScript 等许多其他技术。所以你如果只想支持 HTML 1.0 的话现在的渲染引擎结构会过于复杂了,至于怎么做简化得自己摸着石头过河。
找不到资料是因为你不会找,找的方向不对,用的关键字不对,用的搜索引擎不对,以及用的语言不对。下面是我觉得有价值的资料: 另外注意现代浏览器渲染引擎结构早就不是为了 HTML 1.0 设计了,支持的语法不是简单的 SGML,还要支持 CSS 和 JavaScript 等许多其他技术。所以你如果只想支持 HTML 1.0 的话现在的渲染引擎结构会过于复杂了,至于怎么做简化得自己摸着石头过河。

从整个浏览器的工作周期来看:
首先是联网模块
包括域名解析(这个可以忽略)、发起请求,连接线程的管理等(单线程请忽略)
然后是解析模块
包括了html的解析、DOM树的建立等。尤其是html的解析,会涉及到容错方面的考虑,DOM树要考虑各种场景下的效率(好吧毕业设计可以不考虑效率)
接下来是渲染模块
根据你建立的DOM树,按照网页所描述的内容展示字体、色块等,这个没什么好说的。
还有其他,比如网页对象的管理、页面事件的响应(那些OnClick什么的,好吧我不知道这个是不是html1.0里的东西)插件管理(flash和java,好吧这些又不是你的毕设范围了)
有了以上,差不多应该就是一个浏览器内核了。
插句嘴,
只有一个内核估计很难作为毕业设计展示,你还得搭配着写一个简易的浏览器外壳,所以这不是个小工程。
综上,能用webkit写写也不是不可以,做个引擎不是那么简单的事。
发牢骚:
知乎都开始帮人做作业了,是在向百度知道靠拢么
首先是联网模块
包括域名解析(这个可以忽略)、发起请求,连接线程的管理等(单线程请忽略)
然后是解析模块
包括了html的解析、DOM树的建立等。尤其是html的解析,会涉及到容错方面的考虑,DOM树要考虑各种场景下的效率(好吧毕业设计可以不考虑效率)
接下来是渲染模块
根据你建立的DOM树,按照网页所描述的内容展示字体、色块等,这个没什么好说的。
还有其他,比如网页对象的管理、页面事件的响应(那些OnClick什么的,好吧我不知道这个是不是html1.0里的东西)插件管理(flash和java,好吧这些又不是你的毕设范围了)
有了以上,差不多应该就是一个浏览器内核了。
插句嘴,
只有一个内核估计很难作为毕业设计展示,你还得搭配着写一个简易的浏览器外壳,所以这不是个小工程。
综上,能用webkit写写也不是不可以,做个引擎不是那么简单的事。
发牢骚:
知乎都开始帮人做作业了,是在向百度知道靠拢么

我突然也想就这个问题做个解答,因为我毕设也做了这个东西。不过,做的很渣啊……基本功能都没有实现啊……但是我却发现这个东西非常有意思。
首先,毫无疑问,浏览器是个非常复杂的系统。但是任何复杂软件系统都可以通过层层抽象来简化设计,这个也就是我们平常熟悉的自顶向下的设计方式。
那么我们首先就要对浏览器进行拆解。现在的浏览器都有一个叫做浏览器内核的关键部分(也称作排版引擎),而这个部分相对于浏览器本身来说就是一个黑箱,提供接口,给出结果。另外对现代浏览器来说,书签管理等功能则独立于排版引擎而存在。那么你在做的时候,重点也就在排版引擎。
那排版引擎主要做什么功能呢?简单讲就是根据URL获取资源的字节流,然后根据字节流和资源类型交给相关的解析器进行处理。这个时候需要考虑我们到底需要处理几种资源,各种资源如何处理。所谓的资源处理就是将无结构的字节流变成结构化数据。因为计算机能够处理是结构化数据。拿到结构化数据,便可以根据结构化数据继续处理。
那我们先看URL获取的这个部分。你可以通过给内核模块封装一个调用接口,从浏览外壳传递URL字符串到内核接口,然后根据URI的相关标准(http://www.ietf.org/rfc/rfc3986.txt)来处理就好了。因为这里面涉及各种协议,比如file协议,比如http/https协议,你可能还需要封装一个自己的协议,用来获取内核自带的一些资源路径,比如默认的404页面。
处理好URI之后,你就可以根据URI的结构,交给相关网络模块来处理。我在做的时候,直接扔给了libcurl。但是libcurl在iOS上面,不是最好的实现方法,这个时候你可以继续抽象,提供统一的网络接口,对接操作系统提供的网络相关API。
网络模块的主要任务就是抓取字节流,抓取回来字节流之后,这个时候你可以直接处理,但是很容易阻塞。所以你可以去实现一个缓存机制,把抓取到的字节流缓存在本地,形成一个资源池。这个地方的实现我没有具体研究过,原谅我直接使用了静态变量来做……
你把资源抓回来了,你就需要看这个这个资源的类型,是图像的,你可以放在那里等着回头用的之后直接调取,是HTML、CSS或者脚本文件,你可以首先判断文件类型,这个一般根据网络请求的Header中的content-type来决定。
除了判定资源的类型以外,你还需要判断文件的编码格式,是UTF-8呢,还是GB2312呢?这个有多种方法,包括解析Meta标签,或者采取《HTML5规范》中给出的算法来进行判定。参考:
2 Common infrastructure
8 The HTML syntax
那么你现在拿到HTML的源代码了,又知道源代码的编码格式了,那就处理呗。不过为了更好的开发,一般会将HTML的编码转换成UTF-8,反正《HTML5规范》中是这么写的(我只是粗略的读了,可能是我理解错了?)。正如前面的答案给出的,HTML解析就是一个自动机模型,虽然是这么说,但是写起来还是很不容易的。《HTML5规范》中有详细的算法:8 The HTML syntax
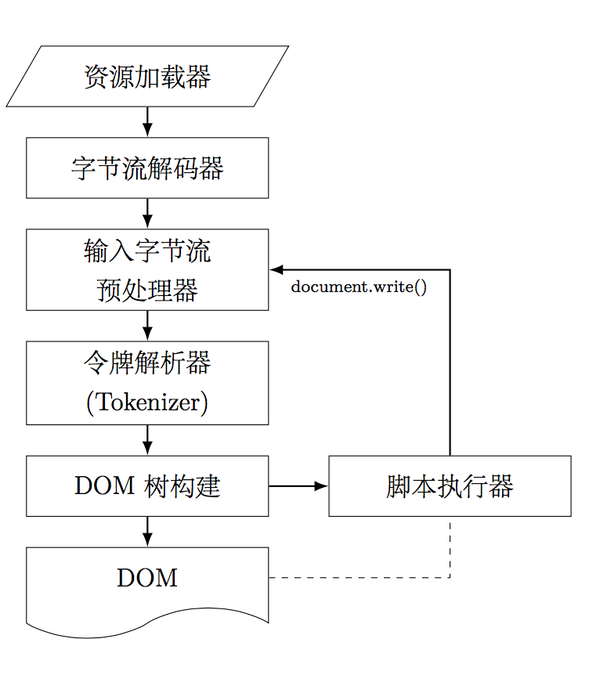
貌似总共有大概232个判断条件?反正我尝试写了一个之后,果断放弃了,而是采用了 google/gumbo-parser · GitHub 。所以如果你感兴趣HTML的解析,可以参考Google的实现,自己写一个也是可以的,只不过要耐心点。Google Gumbo本身给你实现一个类似DOM Tree的数据结构,但是如果自己调用的话貌似有些问题,因为你需要首先清楚他们的数据结构。
补充点不相关的内容:如果你想看Google Gumbo的代码,别去直接看代码了,用doxygen,顺便打开自动生成UML的功能,写论文都靠它了。
DOM Tree是HTML的结构化依托的数据结构,HTML其实可以表示成多种数据结构,但是《HTML 5规范》中直接采用了DOM Tree,或许由于已经成为事实上的标准了。但是,我们都知道《HTML 5规范》并非W3C嫡出……(扯远了)
生成DOM Tree,其实规范中也是有详细算法描述的,参见 8 The HTML syntax 。简单描述就是采用一个栈结构。HTML的解析需要考虑各种不规范的情况……什么嵌套结构有错,标签没有正确闭合等等。好在规范都给出了算法。
DOM Tree也是网页的对外接口。CSS的样式化,JavaScript对于HTML文件的操作都是操作DOM Tree。
至于CSS,看标准呗。Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification 标准中直接给出了CSS的语言描述,可以采用YACC/LEX直接生成。但是我卡在这里了,后面的也就都没有做,只是看了下如何实现的。
至于JavaScript,我都还不会写JavaScript,就不涉及了。不过你可以调用V8嘛!
你获取了DOM结构和CSS的结构,就可以根据CSS的规则,按照CSS的选择器遍历DOM Tree找到相关节点,然后把样式信息写过去。这个时候,CSS是有三层的,一层是浏览器给各类标签定义的默认样式,一般也是用CSS来描述的,一种是网页作者提供的CSS样式,一种是用户定义的样式。这个时候根据优先级,融合这三种CSS,然后对DOM Tree进行样式化。样式话无非就是一个遍历的过程而已。
经过样式化之后,你会得到一个经过样式话的DOM Tree,也就是各个DOM节点带了这个节点的样式信息。这个时候就开始进行布局计算了。布局计算,说白了就是从DOM Tree构建一个子树,我们称为Rendering Tree。Rendering Tree的各个节点都是将来要在屏幕上画出来的,因此一般只涉及<body></body>里面的内容。这个就是渲染过程的开始部分了,所有隐藏的元素其实都是不会进入到Rendering Tree的,例如具有CSS的display:none属性的,都是不会显示的,自然也就无法进入Rendering Tree。对于渲染,可以去读如下的五篇文章,讲的非常好:
Rendering:
Very useful series of posts by Dave Hyatt:
WebCore Rendering I – The Basics
WebCore Rendering II – Blocks and Inlines
WebCore Rendering III – Layout Basics
WebCore Rendering IV – Absolute/Fixed and Relative Positioning
WebCore Rendering V – Floats
Render Layers and The Rendering paths – “WebKit Rendering Basics” section explains it very well.
拿到Rendering Tree之后,就是渲染了,这个时候就可以调用操作系统提供的各种API绘制文字、图片和视频等。各种Form空间就可以绑定到原生控件。然后显示出来。还记得刚开始翻WebKit代码时,就看到貌似采用了一个NSScorllView作为画布,进行绘制。
整个浏览器内核的工作原理也就是这些,说起来容易,写起来,则需要各种考量。自己写一个,不一定能写出多少东西,但是整个研究过程,会学习到很多设计模式的精髓什么的。虽然我的毕设混过去了,但是我准备再好好重构重写这个内核,真的很有趣。(自立Flag)
你做的是浏览器内核,那么最好的参考材料其实是W3C出的各种规范,各种RFC以及现有的浏览器内核的开源实现。印象最深的一句话就是RFC和具体实现其实是相辅相成,互相描述的。
另外,排版引擎的功能不止在这里,写iOS的时候,意识到其实窗口管理器喝各种UI本质上和HTML的排版是类似的,其本质也是利用各种数据结构来记录处理各UI控件之间的关系。
总之,计算机的各层抽象隐藏了很多细节,但是往往这些细节都是优美的,我们看到的往往是水面上的冰山。附上一些做毕设的时候的研究资料,供参考(原谅我直接从论文文献拷贝出来了):
首先,毫无疑问,浏览器是个非常复杂的系统。但是任何复杂软件系统都可以通过层层抽象来简化设计,这个也就是我们平常熟悉的自顶向下的设计方式。
那么我们首先就要对浏览器进行拆解。现在的浏览器都有一个叫做浏览器内核的关键部分(也称作排版引擎),而这个部分相对于浏览器本身来说就是一个黑箱,提供接口,给出结果。另外对现代浏览器来说,书签管理等功能则独立于排版引擎而存在。那么你在做的时候,重点也就在排版引擎。
那排版引擎主要做什么功能呢?简单讲就是根据URL获取资源的字节流,然后根据字节流和资源类型交给相关的解析器进行处理。这个时候需要考虑我们到底需要处理几种资源,各种资源如何处理。所谓的资源处理就是将无结构的字节流变成结构化数据。因为计算机能够处理是结构化数据。拿到结构化数据,便可以根据结构化数据继续处理。
那我们先看URL获取的这个部分。你可以通过给内核模块封装一个调用接口,从浏览外壳传递URL字符串到内核接口,然后根据URI的相关标准(http://www.ietf.org/rfc/rfc3986.txt)来处理就好了。因为这里面涉及各种协议,比如file协议,比如http/https协议,你可能还需要封装一个自己的协议,用来获取内核自带的一些资源路径,比如默认的404页面。
处理好URI之后,你就可以根据URI的结构,交给相关网络模块来处理。我在做的时候,直接扔给了libcurl。但是libcurl在iOS上面,不是最好的实现方法,这个时候你可以继续抽象,提供统一的网络接口,对接操作系统提供的网络相关API。
网络模块的主要任务就是抓取字节流,抓取回来字节流之后,这个时候你可以直接处理,但是很容易阻塞。所以你可以去实现一个缓存机制,把抓取到的字节流缓存在本地,形成一个资源池。这个地方的实现我没有具体研究过,原谅我直接使用了静态变量来做……
你把资源抓回来了,你就需要看这个这个资源的类型,是图像的,你可以放在那里等着回头用的之后直接调取,是HTML、CSS或者脚本文件,你可以首先判断文件类型,这个一般根据网络请求的Header中的content-type来决定。
除了判定资源的类型以外,你还需要判断文件的编码格式,是UTF-8呢,还是GB2312呢?这个有多种方法,包括解析Meta标签,或者采取《HTML5规范》中给出的算法来进行判定。参考:
2 Common infrastructure
8 The HTML syntax
那么你现在拿到HTML的源代码了,又知道源代码的编码格式了,那就处理呗。不过为了更好的开发,一般会将HTML的编码转换成UTF-8,反正《HTML5规范》中是这么写的(我只是粗略的读了,可能是我理解错了?)。正如前面的答案给出的,HTML解析就是一个自动机模型,虽然是这么说,但是写起来还是很不容易的。《HTML5规范》中有详细的算法:8 The HTML syntax
貌似总共有大概232个判断条件?反正我尝试写了一个之后,果断放弃了,而是采用了 google/gumbo-parser · GitHub 。所以如果你感兴趣HTML的解析,可以参考Google的实现,自己写一个也是可以的,只不过要耐心点。Google Gumbo本身给你实现一个类似DOM Tree的数据结构,但是如果自己调用的话貌似有些问题,因为你需要首先清楚他们的数据结构。
补充点不相关的内容:如果你想看Google Gumbo的代码,别去直接看代码了,用doxygen,顺便打开自动生成UML的功能,写论文都靠它了。
DOM Tree是HTML的结构化依托的数据结构,HTML其实可以表示成多种数据结构,但是《HTML 5规范》中直接采用了DOM Tree,或许由于已经成为事实上的标准了。但是,我们都知道《HTML 5规范》并非W3C嫡出……(扯远了)
生成DOM Tree,其实规范中也是有详细算法描述的,参见 8 The HTML syntax 。简单描述就是采用一个栈结构。HTML的解析需要考虑各种不规范的情况……什么嵌套结构有错,标签没有正确闭合等等。好在规范都给出了算法。
DOM Tree也是网页的对外接口。CSS的样式化,JavaScript对于HTML文件的操作都是操作DOM Tree。
至于CSS,看标准呗。Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification 标准中直接给出了CSS的语言描述,可以采用YACC/LEX直接生成。但是我卡在这里了,后面的也就都没有做,只是看了下如何实现的。
至于JavaScript,我都还不会写JavaScript,就不涉及了。不过你可以调用V8嘛!
你获取了DOM结构和CSS的结构,就可以根据CSS的规则,按照CSS的选择器遍历DOM Tree找到相关节点,然后把样式信息写过去。这个时候,CSS是有三层的,一层是浏览器给各类标签定义的默认样式,一般也是用CSS来描述的,一种是网页作者提供的CSS样式,一种是用户定义的样式。这个时候根据优先级,融合这三种CSS,然后对DOM Tree进行样式化。样式话无非就是一个遍历的过程而已。
经过样式化之后,你会得到一个经过样式话的DOM Tree,也就是各个DOM节点带了这个节点的样式信息。这个时候就开始进行布局计算了。布局计算,说白了就是从DOM Tree构建一个子树,我们称为Rendering Tree。Rendering Tree的各个节点都是将来要在屏幕上画出来的,因此一般只涉及<body></body>里面的内容。这个就是渲染过程的开始部分了,所有隐藏的元素其实都是不会进入到Rendering Tree的,例如具有CSS的display:none属性的,都是不会显示的,自然也就无法进入Rendering Tree。对于渲染,可以去读如下的五篇文章,讲的非常好:
Rendering:
Very useful series of posts by Dave Hyatt:
WebCore Rendering I – The Basics
WebCore Rendering II – Blocks and Inlines
WebCore Rendering III – Layout Basics
WebCore Rendering IV – Absolute/Fixed and Relative Positioning
WebCore Rendering V – Floats
Render Layers and The Rendering paths – “WebKit Rendering Basics” section explains it very well.
拿到Rendering Tree之后,就是渲染了,这个时候就可以调用操作系统提供的各种API绘制文字、图片和视频等。各种Form空间就可以绑定到原生控件。然后显示出来。还记得刚开始翻WebKit代码时,就看到貌似采用了一个NSScorllView作为画布,进行绘制。
整个浏览器内核的工作原理也就是这些,说起来容易,写起来,则需要各种考量。自己写一个,不一定能写出多少东西,但是整个研究过程,会学习到很多设计模式的精髓什么的。虽然我的毕设混过去了,但是我准备再好好重构重写这个内核,真的很有趣。(自立Flag)
你做的是浏览器内核,那么最好的参考材料其实是W3C出的各种规范,各种RFC以及现有的浏览器内核的开源实现。印象最深的一句话就是RFC和具体实现其实是相辅相成,互相描述的。
另外,排版引擎的功能不止在这里,写iOS的时候,意识到其实窗口管理器喝各种UI本质上和HTML的排版是类似的,其本质也是利用各种数据结构来记录处理各UI控件之间的关系。
总之,计算机的各层抽象隐藏了很多细节,但是往往这些细节都是优美的,我们看到的往往是水面上的冰山。附上一些做毕设的时候的研究资料,供参考(原谅我直接从论文文献拷贝出来了):
-
朱永盛. WebKit 技术内幕 [M]. 北京 : 电子工业出版社, 2014.
-
GARSIEL T, IRISH P. How Browsers Work: Behind the scenes of modern web
browsers[EB/OL]. [2014-08-28].
How Browsers Work: Behind the scenes of modern web browsers.

HTML 1.0的话,基本还是没有什么难度的。
从前到后几个点:
1、网络方面,HTTP是个基于文本的协议,TCP/IP 80端口走ASCII文本流,干脆暂时不用支持编码好了,随便找个Socket的书读读,写个控制台发GET啥的给服务器看看返回啥很简单。
2、然后是解析HTML,考虑到是HTML 1.0,暂时也不搞什么容错啥的,找个正则的库,然后网上搜一下HTML正则,也就差不多了。当然如果喜欢可以自己写Tokenizer。
3、HTML 1.0是没有CSS、JS之类的东西的,所以排版的唯一问题是图文混排文本加粗什么的。
4、最后就是窗口呈现、选择文本、地址栏、刷新停止按钮,超链接点击处理之类的东西了。
当然,我肯定不会告诉你.NET Framework囊括了所有这些基础部件的(包括HTTP协议实现)。。。。
从前到后几个点:
1、网络方面,HTTP是个基于文本的协议,TCP/IP 80端口走ASCII文本流,干脆暂时不用支持编码好了,随便找个Socket的书读读,写个控制台发GET啥的给服务器看看返回啥很简单。
2、然后是解析HTML,考虑到是HTML 1.0,暂时也不搞什么容错啥的,找个正则的库,然后网上搜一下HTML正则,也就差不多了。当然如果喜欢可以自己写Tokenizer。
3、HTML 1.0是没有CSS、JS之类的东西的,所以排版的唯一问题是图文混排文本加粗什么的。
4、最后就是窗口呈现、选择文本、地址栏、刷新停止按钮,超链接点击处理之类的东西了。
当然,我肯定不会告诉你.NET Framework囊括了所有这些基础部件的(包括HTTP协议实现)。。。。
花三个月看一下WebKit的代码,又不是什么难事。
然后你就知道这个坑有多大了。
Apple都不敢自己弄,拿了KHTML回来改。
Google也不敢自己弄,拿了WebKit回来改。
Opera自己弄了,然后扔了。
IE修修补补,终于决定扔了再写一个。
祝你成功,其实能够拿 gumbo 和 v8封装出来一个支持 JS 操作 DOM 的解析引擎已经很不错了,排版部分还是算了吧。。。
然后你就知道这个坑有多大了。
Apple都不敢自己弄,拿了KHTML回来改。
Google也不敢自己弄,拿了WebKit回来改。
Opera自己弄了,然后扔了。
IE修修补补,终于决定扔了再写一个。
祝你成功,其实能够拿 gumbo 和 v8封装出来一个支持 JS 操作 DOM 的解析引擎已经很不错了,排版部分还是算了吧。。。

我觉得题主可以试一试,定义一个简单的html文本(只支持<html>,<b>黑体,超链接<href>,图片<img>,不支持css,frame,form,div等其他的tag),写个支持的http协议的的简单下载模块(支持简单的http头, 简单的容错,估计500行代码搞定,能下html文本和<img>tag中的图片),写个解析器(支持Dom,但只解析其中的几个tag而已,估计1000行代码内),绘制(我用的是objective-c,里面有coreText这种库,可以实现一些富文本绘制和图文混排的排版效果,估计2000代码搞定,其它语言不了解),把这三个模块串行起来,能适应<b>黑体,超链接<href>,图片<img>这几个tag的任意排列和组合,然后慢慢增加一些tag的解析(折腾文本解析这个模块),然后在解析dom的过程中交叉发起图片的下载和绘制,使性能更好。。
<html>
text<img>text (文本图片任意混排)
</html>
<html>
text<img>text (文本图片任意混排)
</html>


做一个毕业设计的话, 推荐看一下j2me lwuit 的html component. 代码实现比较简单, 符合你只想实现html 1.0 的要求。 你想用c/c++ 重新实现一遍也比较简单, javascript 你想要实现一个效率不高的解释器,不整JIT 什么的没那么复杂。要知道有人在j2me 平台也实现了一个javascript 解释器的,
Links:
Lwuit: Subversion
HTMLComponent
minijoe - Minimal Javascript Object Environement for J2ME
不要嫌这个实现太简单,太小儿科。 也是支持html4.0 和css 1.0的。 正因为简单才比较好理解。 j2me 平台基本上没什么前途了, 但是因为它的memory 限制, 有些idea 和implementation 对其他平台还是有借鉴价值的。
学习编程最好的方法是Read the fxxking code。 但我的建议要从简单直接的code 读起, 一上来就整webkit, gecko, V8, TraceMonkey, 很难找到对自己直接有用的代码, 对培养自信也没好处。
Links:
Lwuit: Subversion
HTMLComponent
minijoe - Minimal Javascript Object Environement for J2ME
不要嫌这个实现太简单,太小儿科。 也是支持html4.0 和css 1.0的。 正因为简单才比较好理解。 j2me 平台基本上没什么前途了, 但是因为它的memory 限制, 有些idea 和implementation 对其他平台还是有借鉴价值的。
学习编程最好的方法是Read the fxxking code。 但我的建议要从简单直接的code 读起, 一上来就整webkit, gecko, V8, TraceMonkey, 很难找到对自己直接有用的代码, 对培养自信也没好处。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号