CrashCourse CS 速成课笔记
 更新至第4集-二进制
更新至第4集-二进制
1. 计算机早期历史
-
算盘 >> 步进计算器 >> 差分机 >> 分析机 >> 打孔卡片制表机
-
Charles Babbage, Ada Loyelace
-
最早的计算设备是算盘。
-
Computer从指代职业变成指代机器
-
机器里有名的是:步进计算器,第一个可以做加减乘除的机器
-
炮弹为了精准,要计算弹道,二战是查表来做。但每次改设计了就需要做一张新表
-
Charles Babbage提出了“差分机”,在构造差分机期间,想出了分析机,分析机是通用计算机
-
Lovelace给分析机写了假想程序,因此成为了第一位程序员
-
人口普查10年一次。Herman Hollerith的打孔卡片制表机大大提升了效率
2. 电子计算机
- 继电器>>真空管>>晶体管
- 20世纪的发展要求更强的计算能力。柜子大小的计算机发展到房间大小
- 哈佛 Mark 1 号。IBM 1944年做的
- 继电器,继电器一秒最多50次开关
- 继电器出 bug
- 1904年,热电子管出现。第一个真空管。改进后变成和继电器的功能一样
- “巨人1号”计算机在英国 布莱切利园 管次大规模使用真空管。但编程麻烦。还要配置
- 1946年宾夕法尼亚大学的 ENIAC 是第一个通用可编程计算机
- 1947年,贝尔实验室做出了晶体管。晶体管有诸多好处。IBM很快全面转向晶体管
- 硅谷的典故:很多晶体管和半导体的开发都是这里做的。而生产半导体最常见的材料是硅
- 肖克利半导体>>仙童半导体>>英特尔
3. 布尔逻辑 和 逻辑门
-
什么是二进制,为什么用二进制,布尔逻辑
两种状态,二进制 Binary,为了控制信号避免干扰,布尔代数的应用
电路闭合,电流流过,代表“真”,true,1
电路断开,无电流通过,代表“假”,false,0
-
3个基本操作:NOT, AND, OR
-
解释3个基本操作
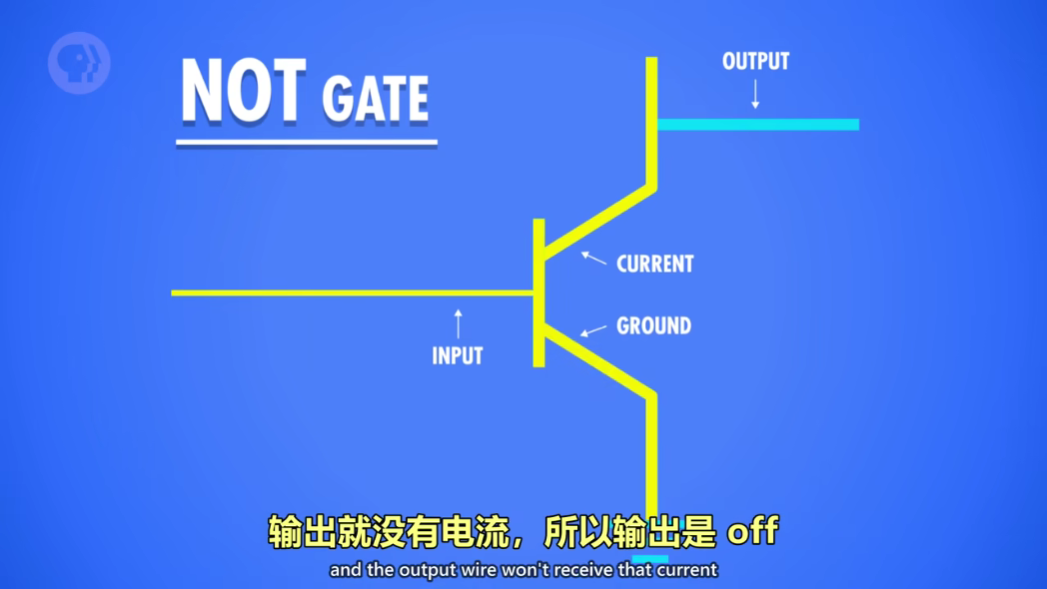
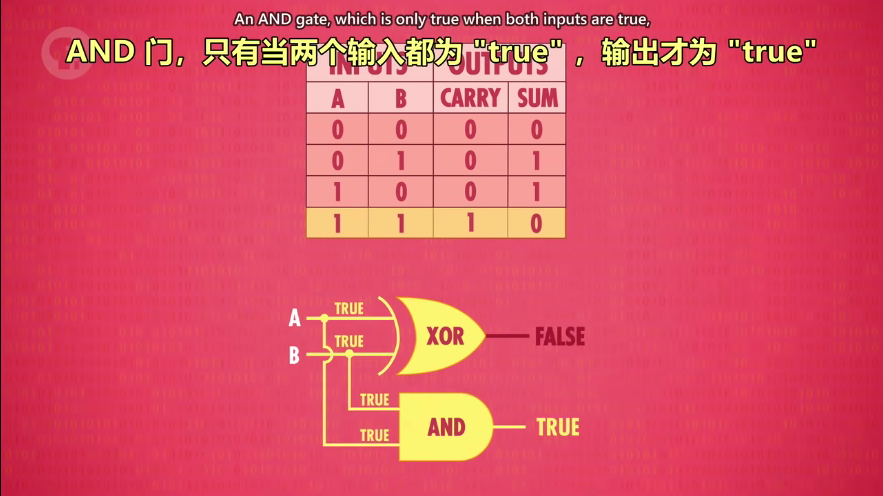
非门:类似打开输入(true)就接地,电流无法流过输出,输出为 false
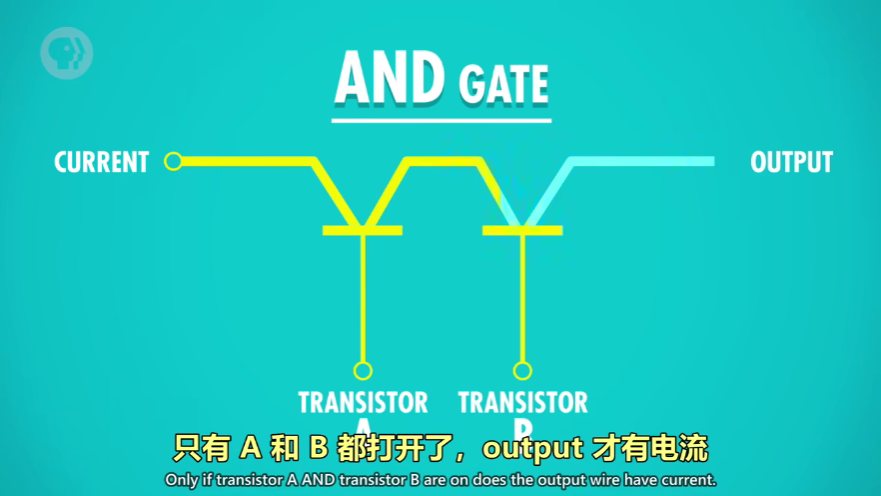
与门:串联电路,一假即假,永远为假
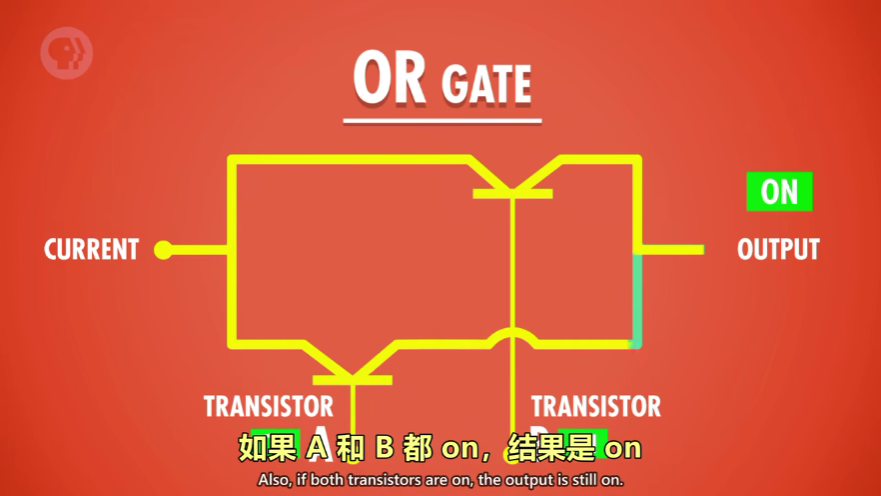
或门:并联电路,一真即真,永远为真
-
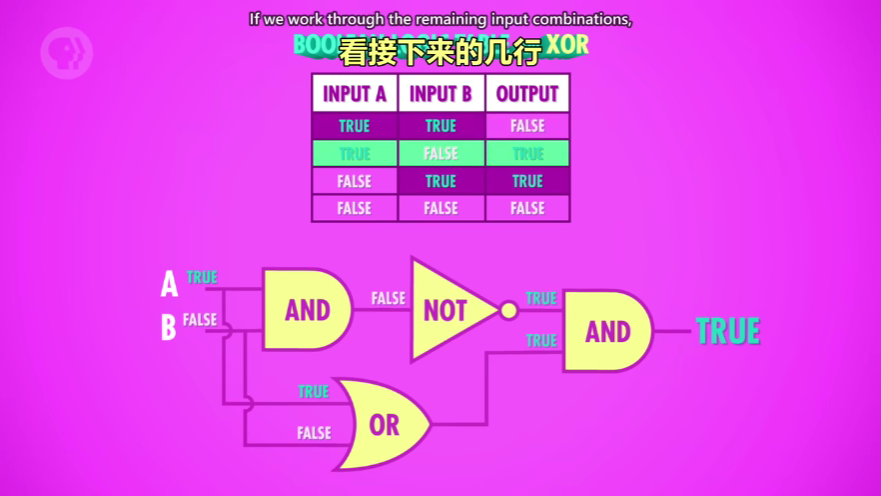
XOR 异或
异或门:二者不可兼得,有真有假即为真

4. 二进制
-
用十进制举例二进制的原理,演示二进制加法。存储单位MB GB TB等(MiB GiB?)
Bits:位/比特。一个 1 或 0 叫一“位”
Bytes:字节。8位 = 1字节
-
正数,负数,整数,浮点数的表示
小数点可以在数字之间浮动,称为浮点数。一般用科学计数法存储(IEEE 754标准)。
\(625.9\) 表示为 \(0.6259×10^3\),“其中.6259”是“有效位数”(significance),“3”是指数(exponent)
存储数值时,第一位(最左边)表示正负,0为正
在32位计算机中,用8位存指数,23位存有效位数

-
美国信息交换标准代码 - ASCII,用来表示字符(7位,足够存128个不同值,即使8位,汉字也不够用)
-
UNICODE 1992 年诞生,是字符编码标准,解决 ASCII 不够表达所有语言的问题,常见16位足够)
5. 算术逻辑单元 - ALU
-
简单介绍ALU,英特尔 74181
-
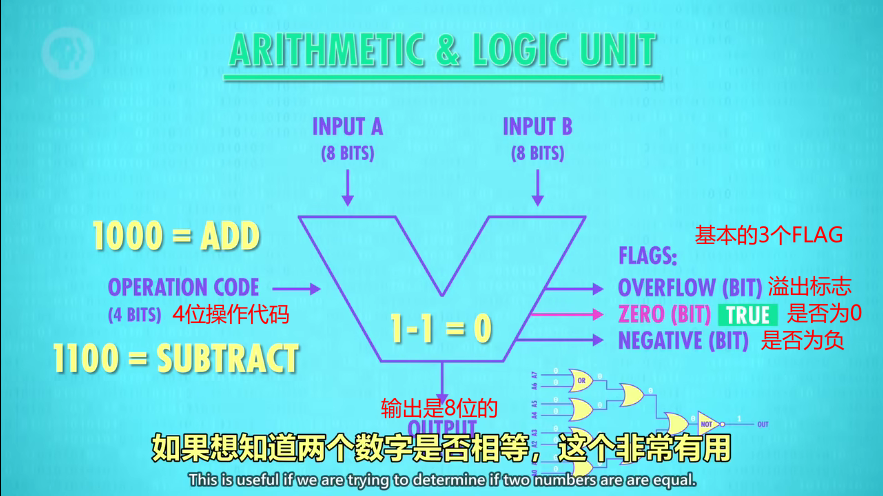
ALU 有2个单元。1个算术单元和1个逻辑单元
-
算术单元
-
半加器(处理1个 bit,2个输入)
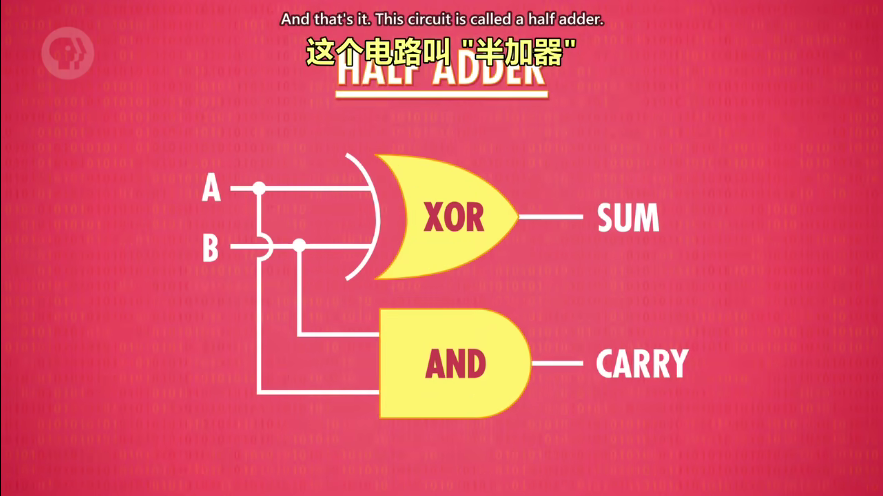
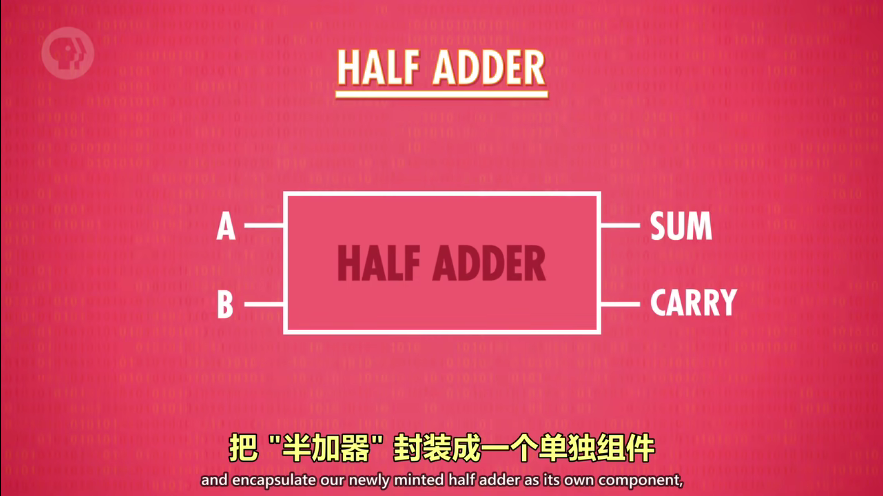
-
全加器(处理1个 bit,3个输入)

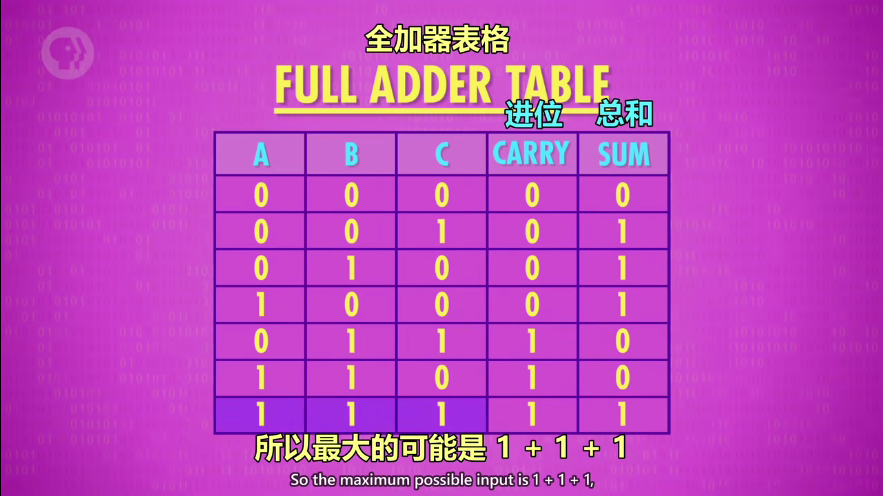
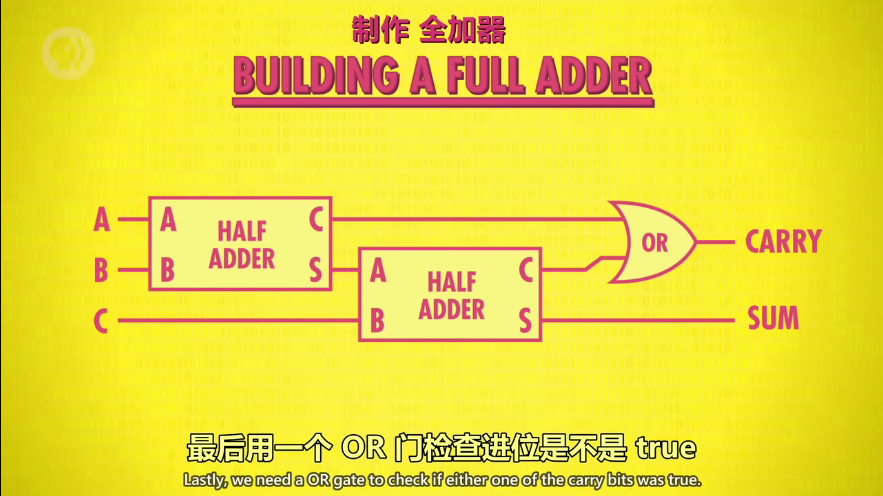
ps: OR gate 作用是检查是否进位,事实上经过两次半加,CARRY不可能都为true
-
8bit加法(1个半加器,7个全加器)

-
溢出的概念,吃豆人的例子

相加超过了用来表示的位数,导致错误,8位游戏吃豆人最多256关
-
乘法除法
简单的 ALU 没有乘除(遥控器和微波炉等),乘法用多次加法来实现,除法同理。

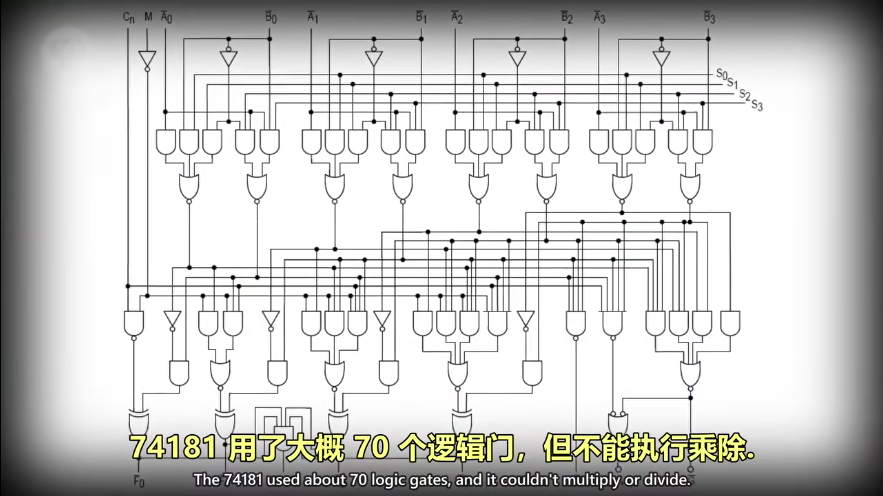
而手机电脑则有专门做乘除法的算术单元。
-
-
逻辑单元
-
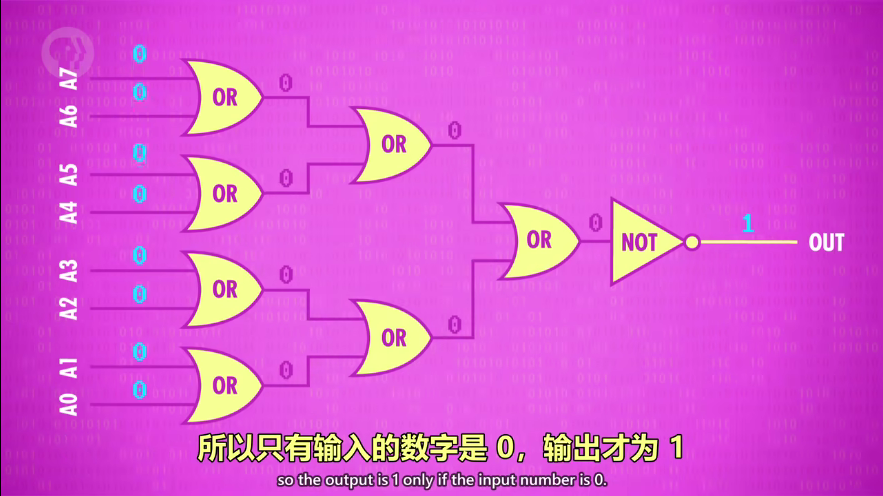
检测数字是否为0的电路(一堆 OR 门最后加个 NOT门)
-
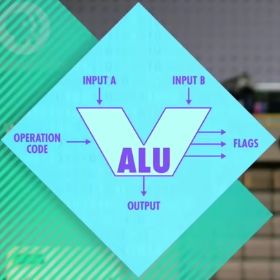
ALU 抽象成一个 V 符号
-
Flag 标志(是否相等,是否小于,是否溢出等等)
-
6. 寄存器和内存
-
重点是 Memory(存储 / 内存两种含义)
- RAM:Random Access Memory,随机存取存储器
- 存储:指持久存储(persistent memory),也叫 memory
-
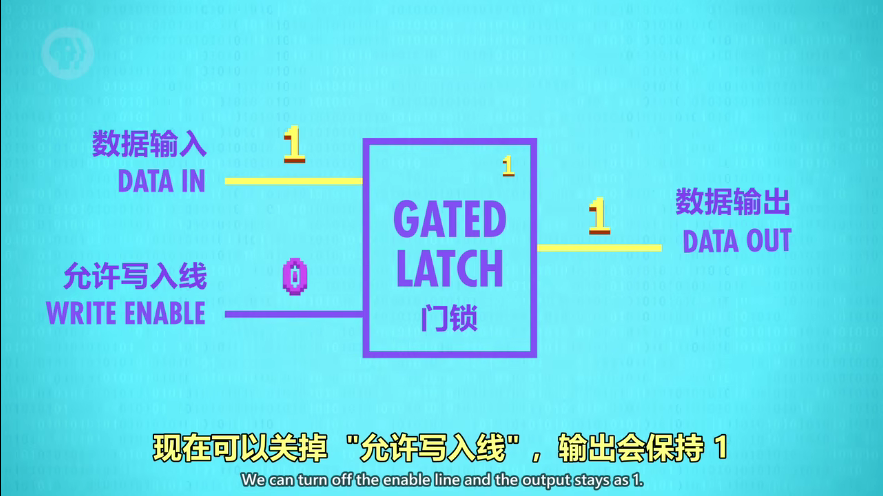
存 1 位(Gated Latch - 锁存器)
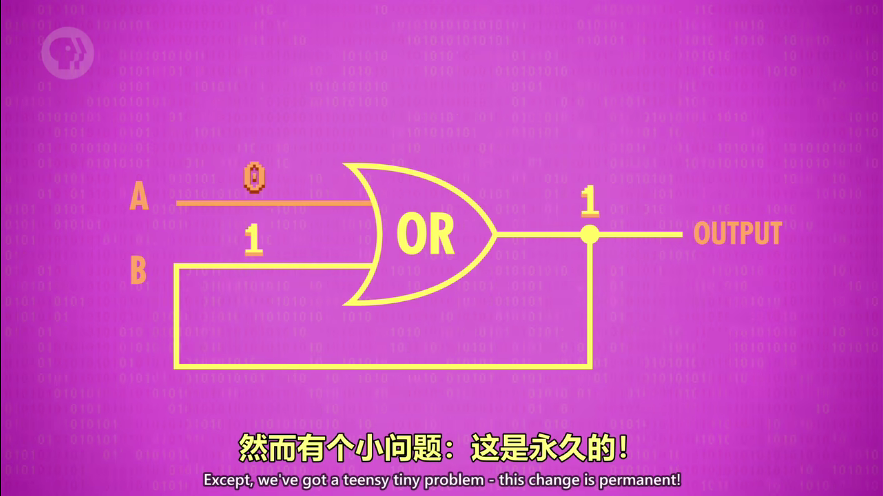
OR 门的回流:可以永久存1
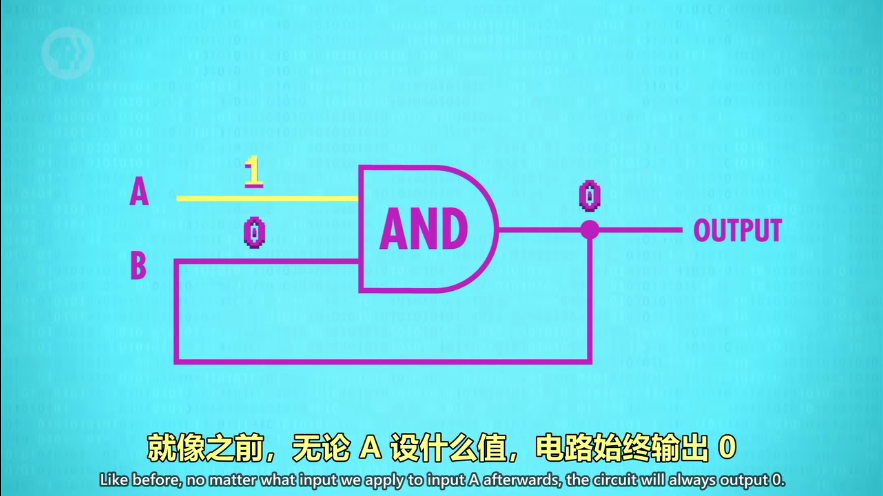
AND 门的回流:可以永久存0
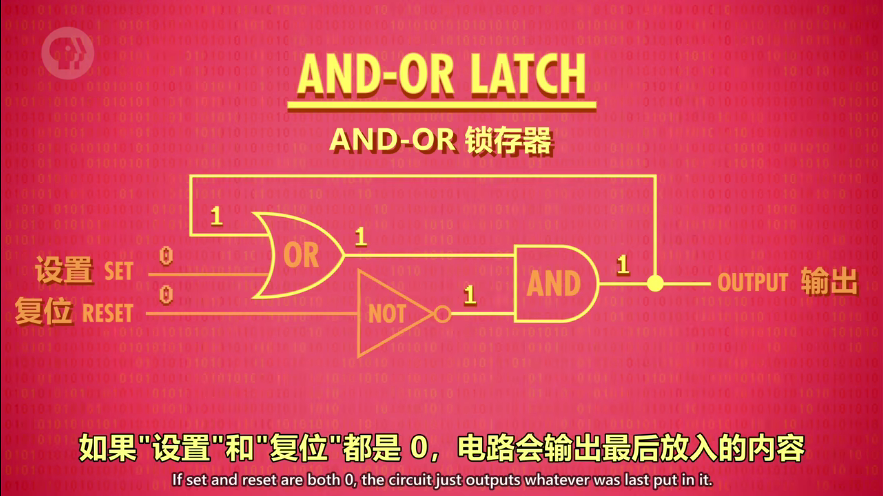
AND-OR 锁存器:有两个输入,通过 SET/设置 输入,把输出变成1;RESET/复位输入,把输出变成0
如果“设置”和“复位”都是0,电路会输出最后放入的内容,这样就存储了1位信息
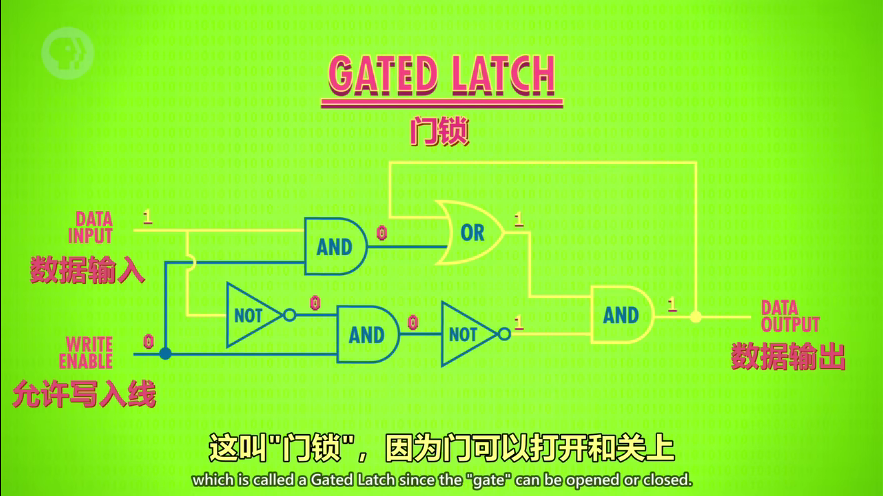
门锁(Gated Latch):通过数据输入,能存一个bit;通过允许写入线,控制是否写入,实现了开关!
-
存 8 位(Register - 寄存器)
寄存器(Register):一组锁存器组成,寄存器能存一个数字,这个数字有多少位,叫“位宽”,早期有8位宽寄存器,后来有16位,32位,如今有64位宽寄存器,使用寄存器,首先要开启所有的锁存器。

-
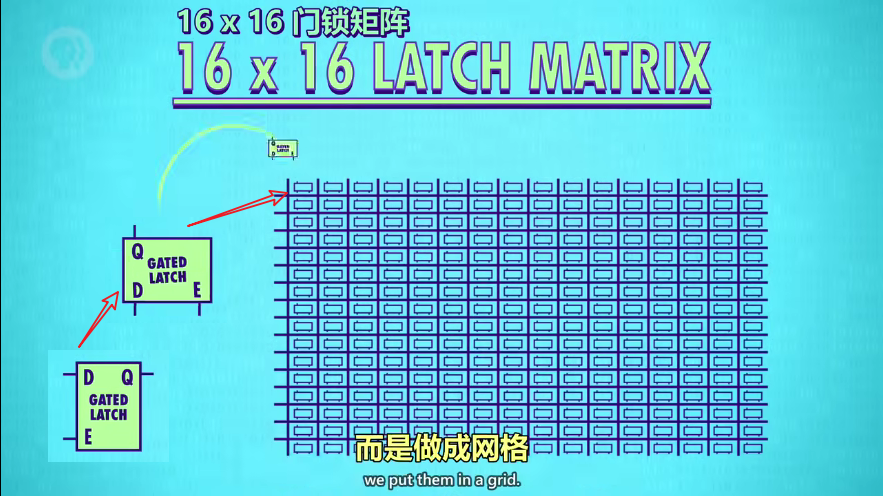
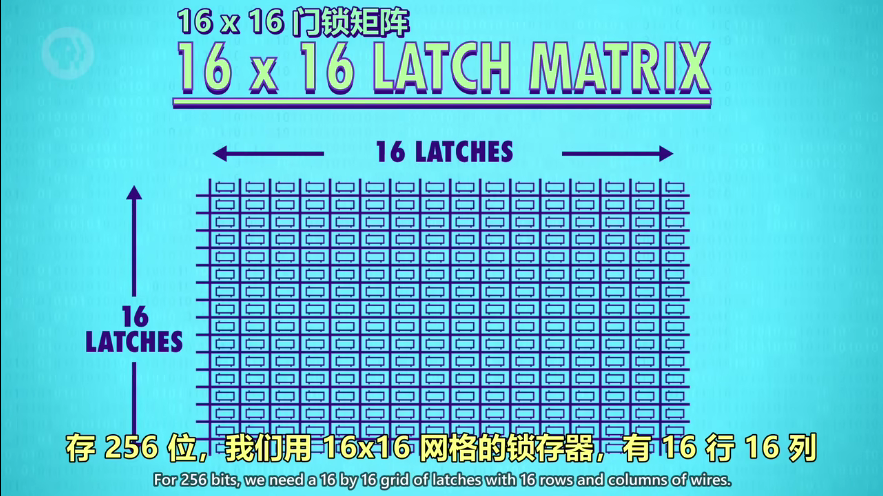
16x16的矩阵存 256 位
锁存器很多,为避免接线太多繁杂,不将锁存器并列排放,而是做成门锁矩阵
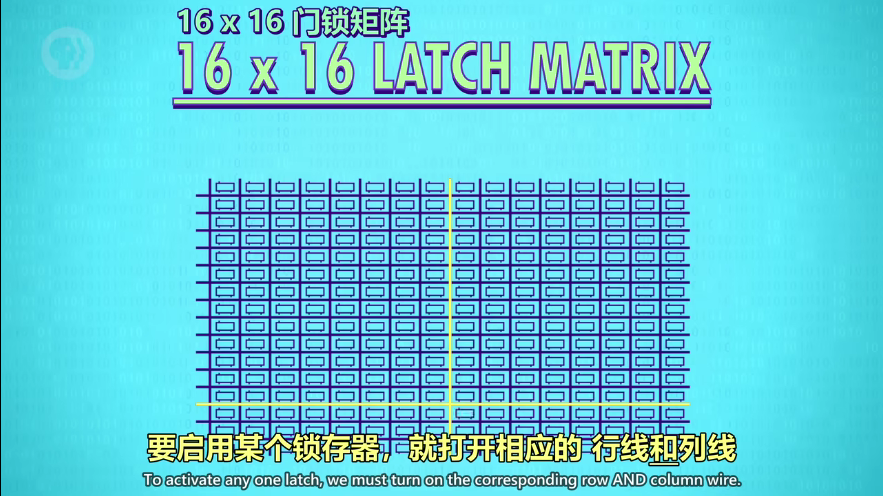
放大到单个锁存器,行线和列线的交叉处(也就是所谓的地址)
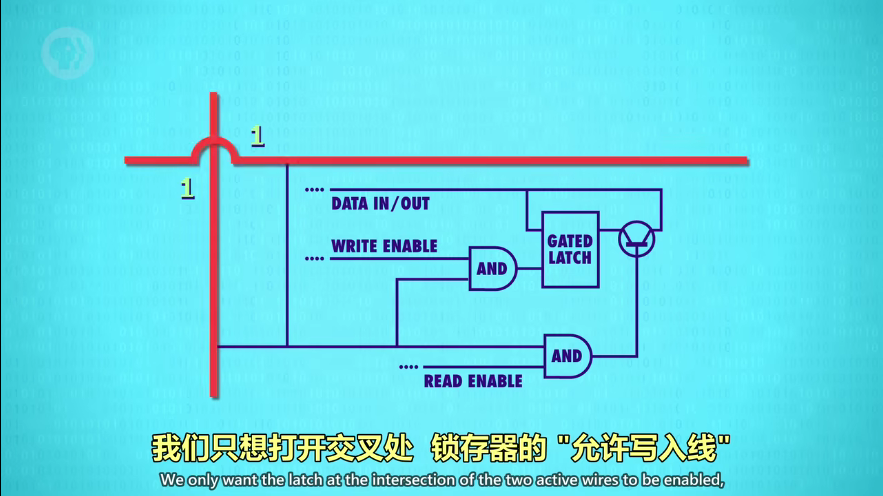
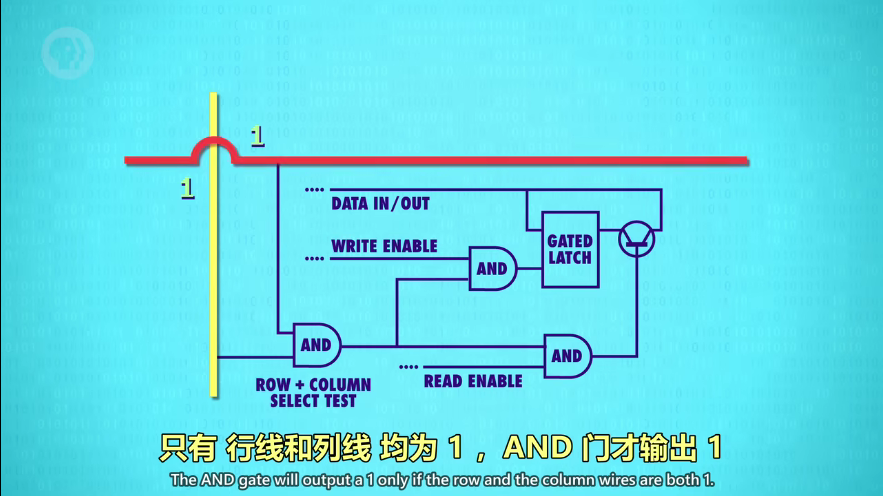
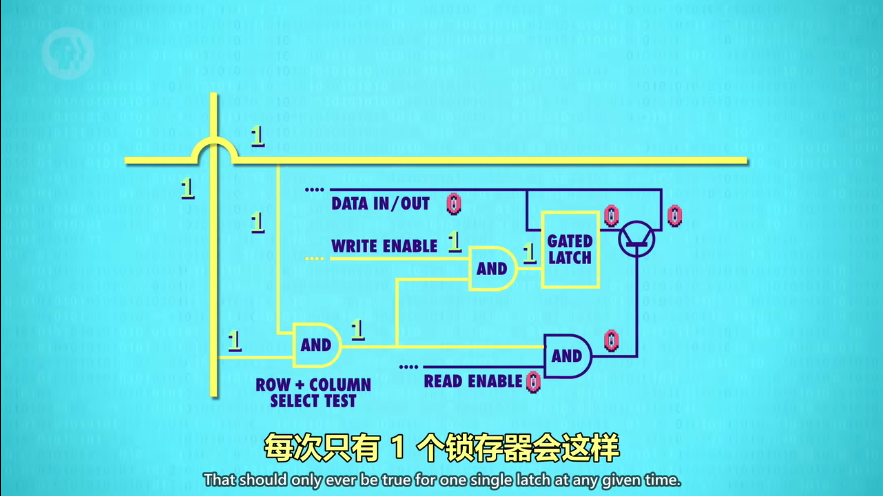
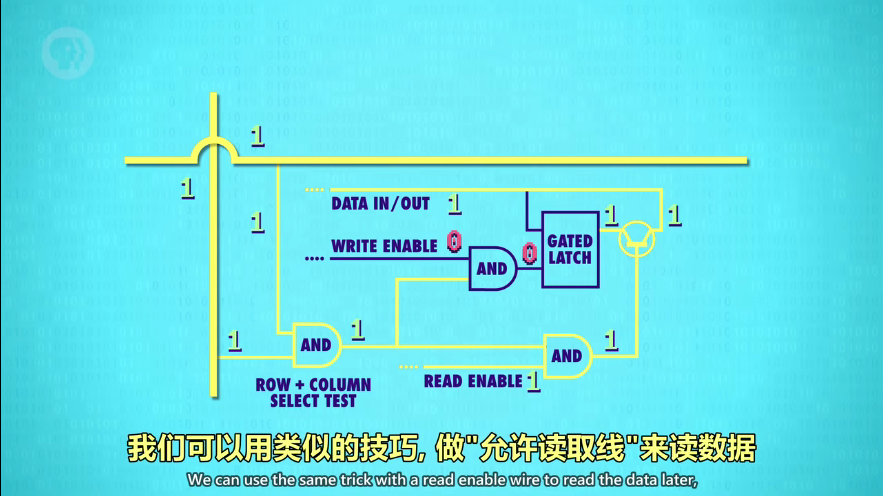
打开相应的行线 AND 列线,就启用了一个锁存器。因为一个锁存器只有一个行列交叉点(坐标地址),所以所有锁存器可以共用允许写入线、允许读取线、数据线,分别用 1 条线,把256个锁存器串起来。因为把行列地址作为开关,所以即便都允许写入/读取,其他锁存器也会被忽略。(就像所有学生把作业本打开,只有老师走到某位同学面前才算检查一份作业)
256位的门锁矩阵,只需 32(16行+16列线)+1(数据线)+1(允许写入线)+1(允许读取线)=35条线
-
交叉点是Memory Address(存储地址)
-
因为最多16行16列,用4位来表示就足够了
-
第12行用1100表示,第8列用1000表示,第12行8列地址表示为11001000
-
-
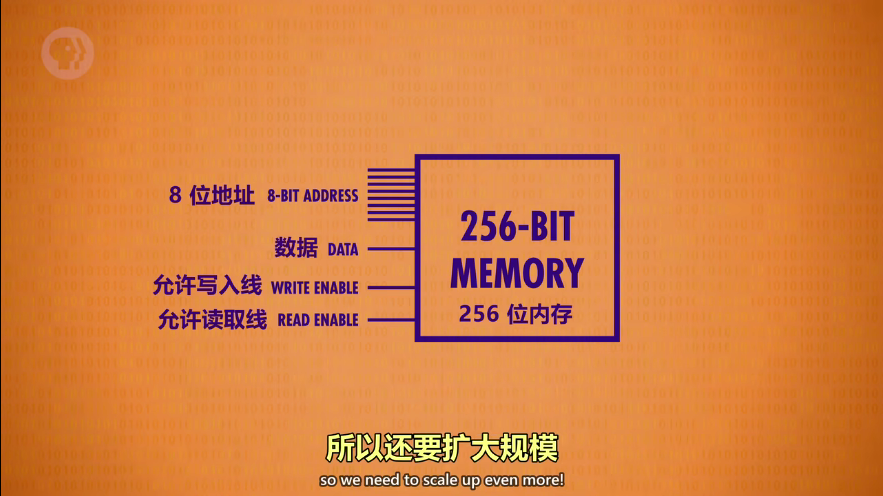
数据选择器/多路复用器(Multiplexer)解码 8 位地址,定位到单个锁存器(找地址的)
2个多路复用器,只要输入4位数字让多路复用器找到行/列地址。4位代表行,4为代表列,每行每列都有0000到1111共16路。

-
组合 256 位内存 + 多路复用器
包装抽象成一个256位内存。
-
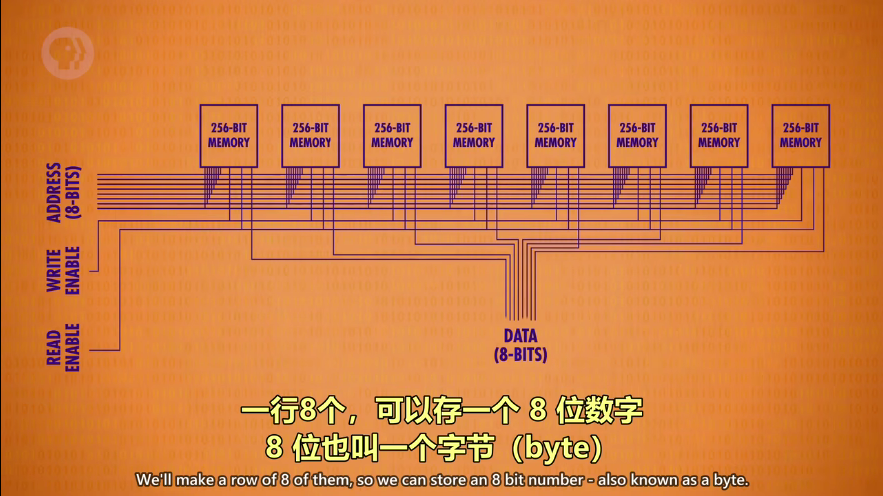
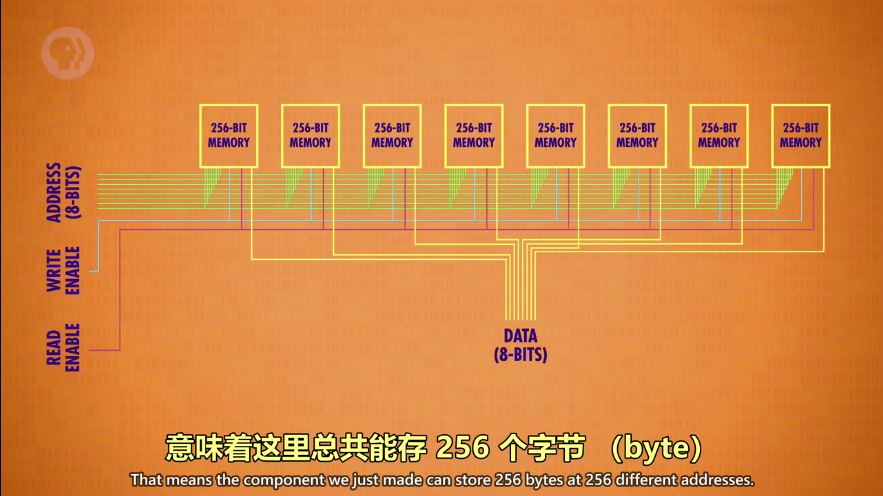
可寻址的 256 字节内存
- 这是由8个“256内存”(简称小方块,下同)组成的一排内存组
- 一个小方块里共有256个地址,由于地址是8位数字=8bit=1字节,所以一个小方块有256个字节
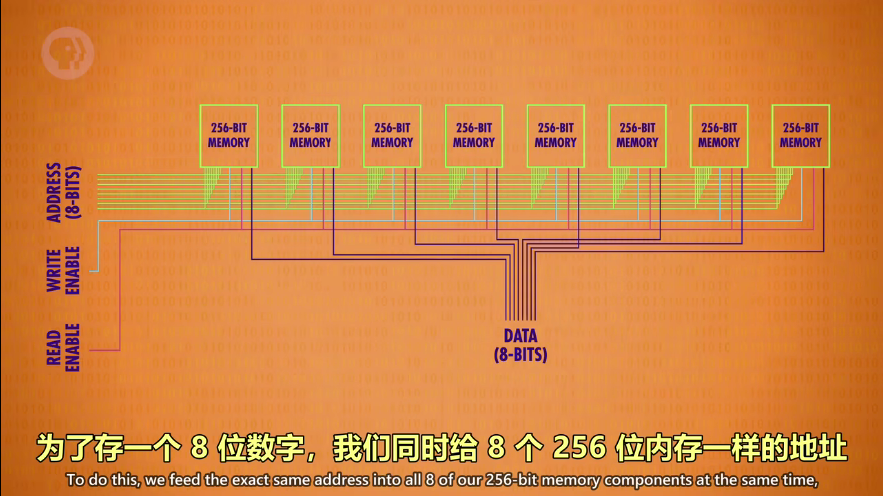
- 给1个地址存值,首先,8个“256位内存”同时找到一样的地址
- 比如11001000,大家都是找到各自的第12行第8列
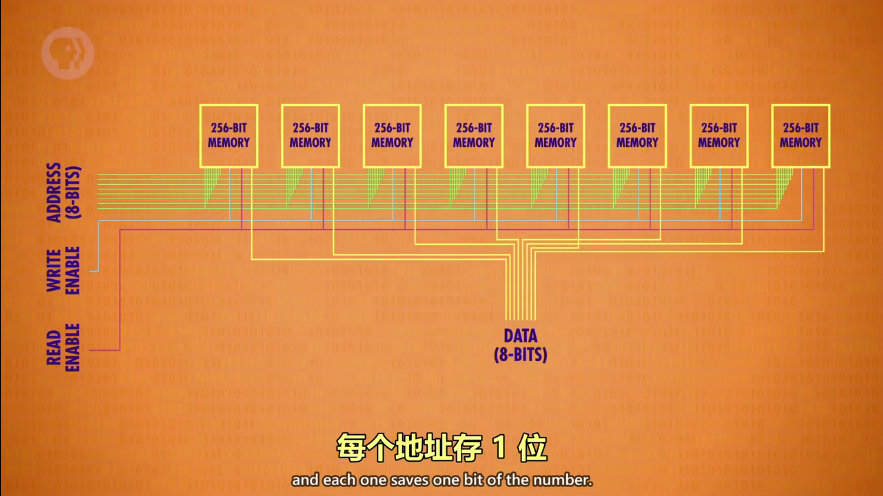
- 然后,将输入的数据(8位),一一分配到每个小方块的地址所在,每个存一位值
- 8个“256内存”读取/写入的地址一样,而分到的 bit 不一样
- 这样一个地址可以读或写一个8位值(可以说,读写的数据有多少位取决于小方块有多少个)
- “256内存”,意味着地址有256个,总共256个地址
- 一个地址可以读写8位(1字节),那么256个地址也就是256字节(byte)
-
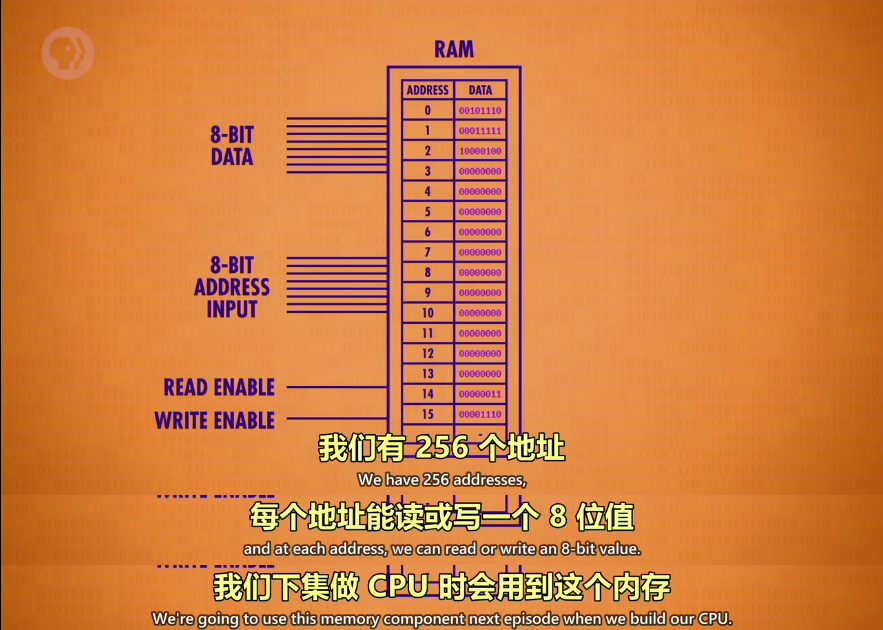
一条1980年代的内存,1M大小
- 8个模块。每个模块有32个小方块


- 每个小方块有4个小块,每个小块是128位 x 64位的矩阵,共8192位


- 整个内存条800万位,约1M
- 现在的计算机内存,兆字节(MB)megabyte,千兆(GB)gigabytes,地址也扩充到32位,内存的一个重要特性是:可以随时访问任何位置,这也是RAM(RANDOM ACCESS MEMORY)的由来,而以前存储用的磁带只能手动转动到想要的位置读写
此次我们用锁存器做了一块 SRAM(静态随机存取存储器,S是Static),但是还有其他类型的 RAM,如DRAM,闪存(Flash memory)和NVRAM,用在不同逻辑门,电容器,电荷捕获或忆阻器等等。总之都是抽象和包装。
总结
-
寄存器是一组锁存器,寄存器能存一个数字,这个数字有多少位,叫位宽。
-
RAM就是内存,内存多大,RAM就多大。内存可以随时访问任何位置,因此叫“随机存取存储器”,简称RAM。
7. 中央处理器(CPU)
-
CPU(Central Processing Unit)包括:RAM + 寄存器(Register) +ALU
- 操作过程:取指令(fetch) >> 解码(decode) >> 执行(execute),遍历循环
- 加上时钟才能构成 CPU
- 超频提升性能,降频省电
-
CPU 组成
- ALU:输入二进制,会执行计算
- 寄存器:很小的一块内存,能存一个值
- RAM:一大块内存,能在不同地址存大量数字
- 时钟:控制 CPU 处理频率


-
一些概念
-
指令(Instruction):CPU 负责执行程序,程序是由一个个操作组成,这些操作叫”指令“,如数字指令(加/减),内存指令(读/写)
-
微体系架构(Microarchitecture):抽象地表示构件和功能,不考虑底层电路实现
-
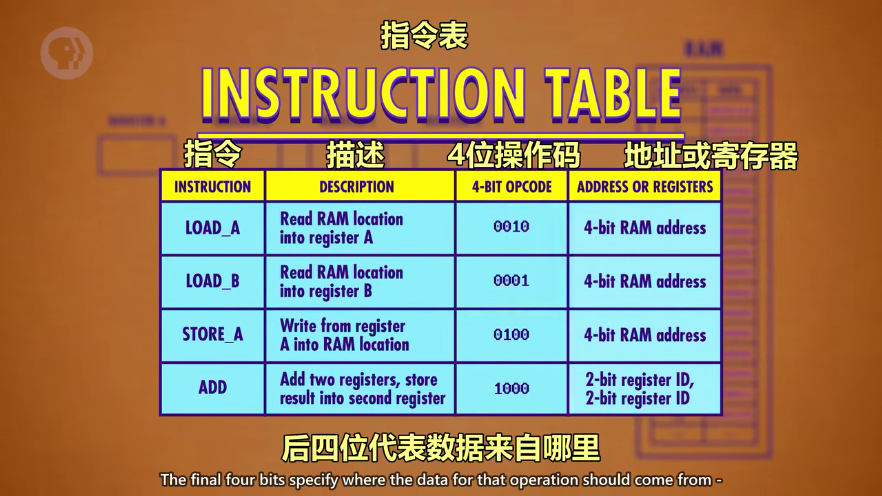
指令有对应的前4位操作码(opcode)和后4位地址码(或代表寄存器的码)
-
指令地址:用来追踪程序运行到哪,存的是当前指令的内存地址
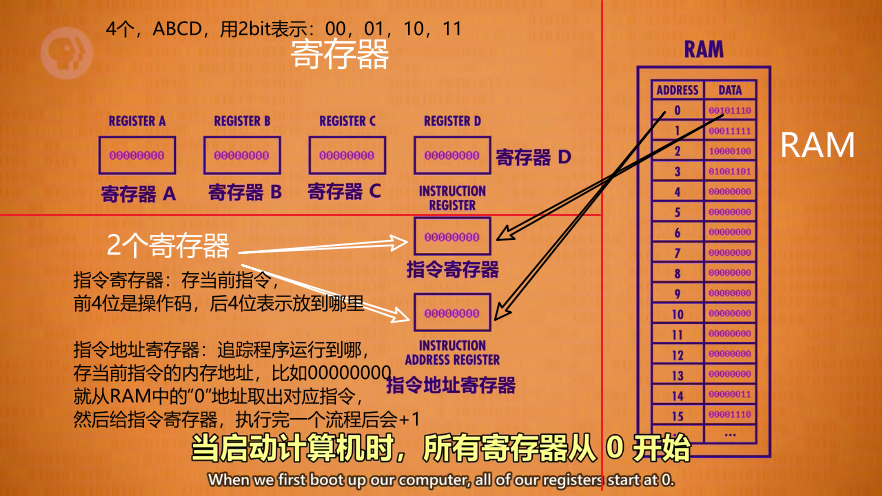
-
当启动计算机时,所有寄存器从0开始
-
-
CPU 怎么执行命令(以A加B指令为例)
-
取指令阶段(FETCH PHASE):指令地址寄存器{00000000} >> RAM{找到地址0,复制取出对应操作码00101110} >> 指令寄存器

-
解码阶段(DECODE PHASE):通过指令表,检查操作码前4位后4位。
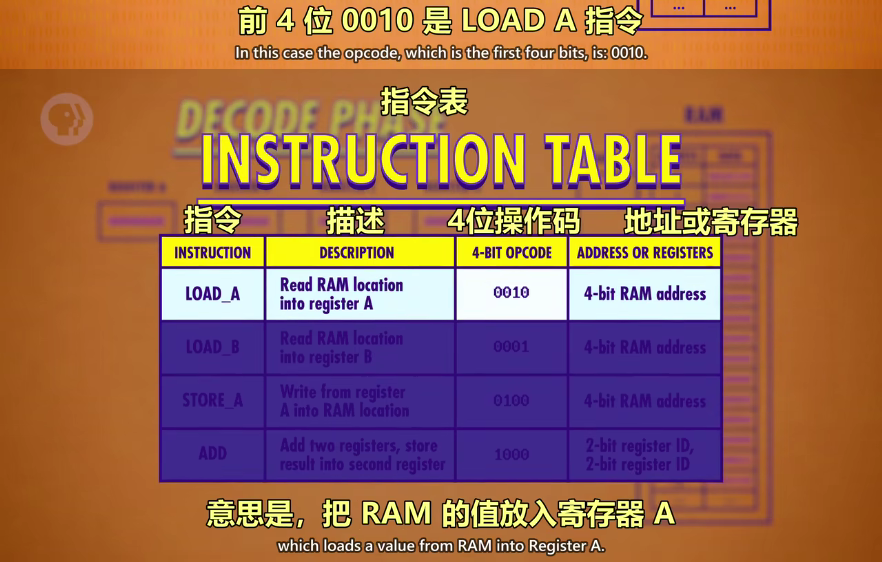
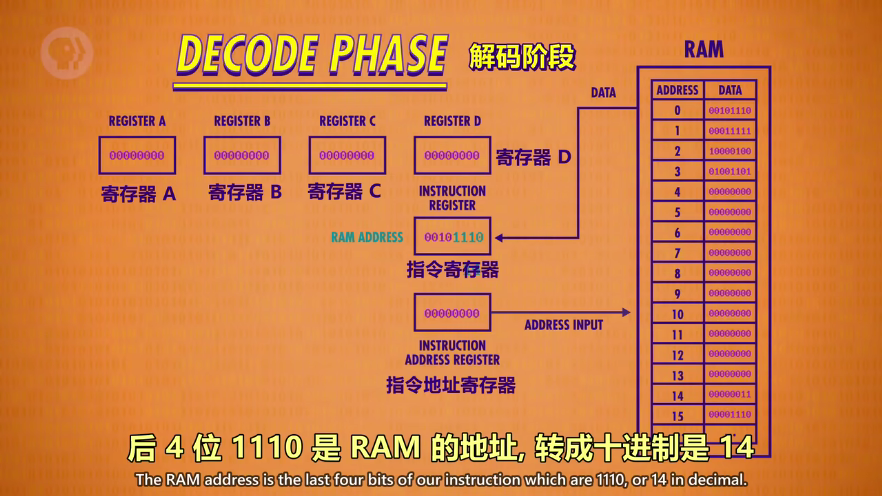
将前4位(opcode)通过控制电路(逻辑门)检查到对应的指令,确定指令后就可以执行了
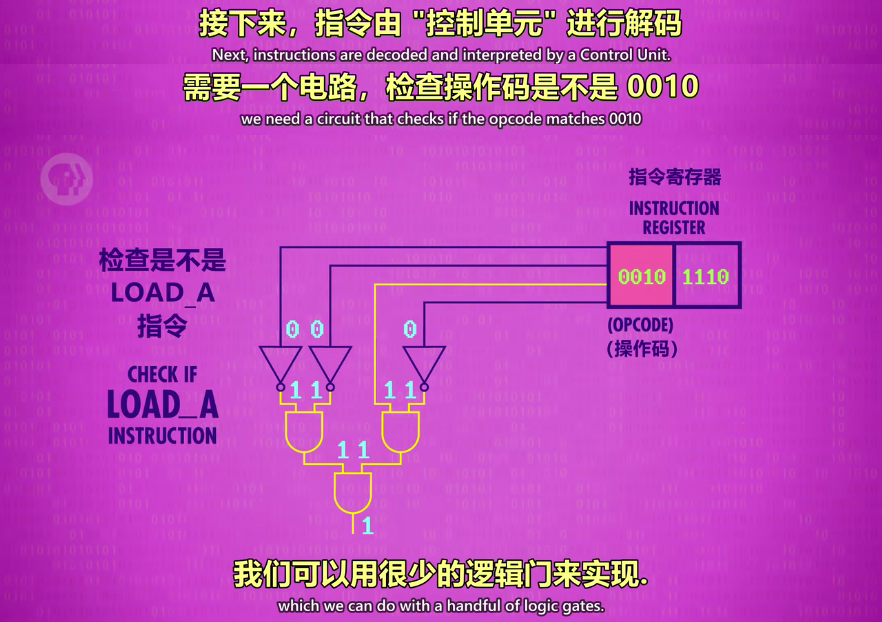
-
执行阶段(EXECUTE PHASE)
指令寄存器 >> 检查LOAD_A指令的电路 >> RAM >> 检查LOAD_A指令的电路 >> 寄存器A

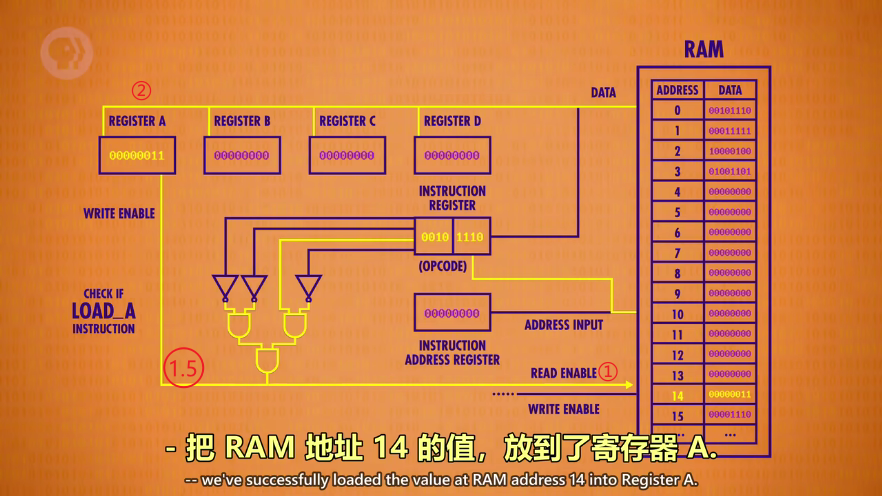
指令完成后,关掉所有线路,指令地址寄存器+1,取下一条指令,执行阶段结束
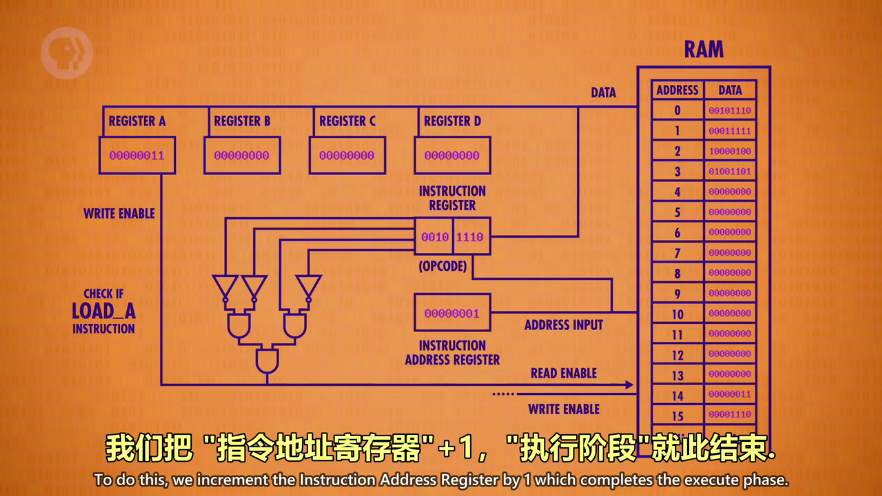
-
包装抽象
LORD_B的执行同LORD_A,这样就加载了A、B数据
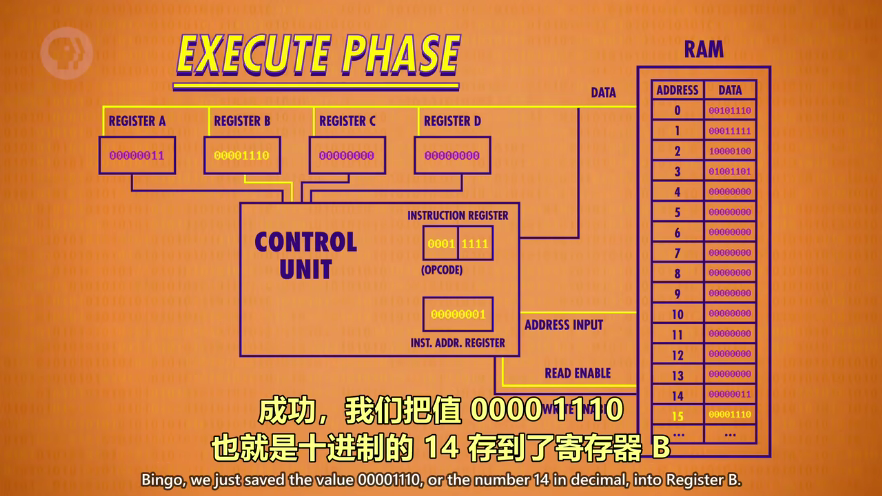
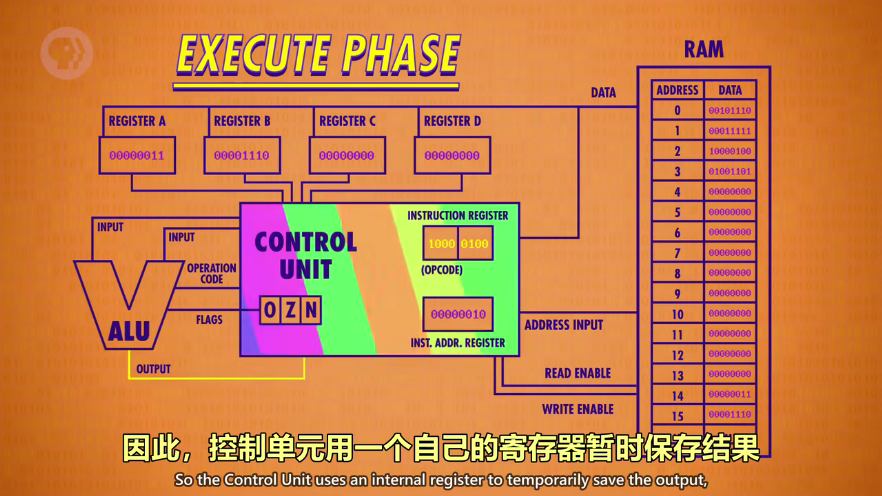
然后开始第三条指令:相加,因此需要ALU。ADD指令:将AB两个寄存器的值相加,结果写入到A。opcode的后4位0100分成01和00,表示寄存器B和A(4个寄存器,ABCD对应00-01-10-11),由于结果要存到寄存器A,但是不能写入(会造成新值不断和自己相加),因此控制单元用一个自己的寄存器暂时保存结果,然后关闭ALU,再把值写入正确的寄存器
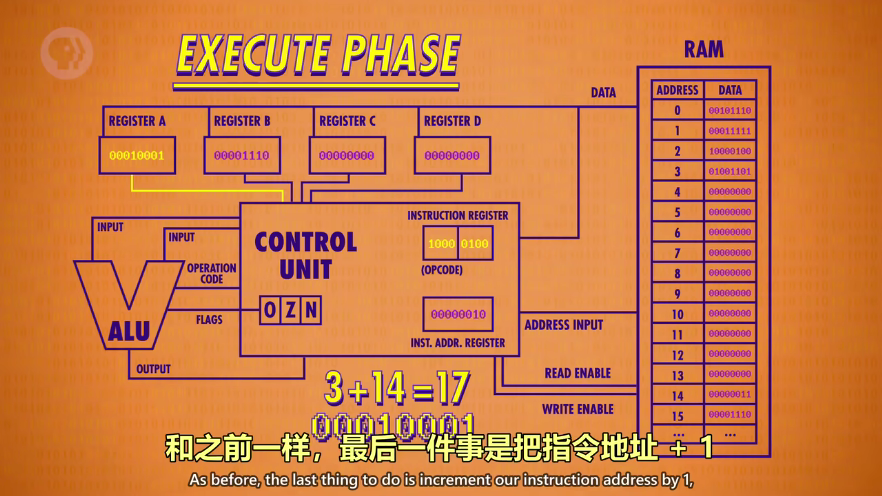
最后是Store_A将结果存储到RAM中

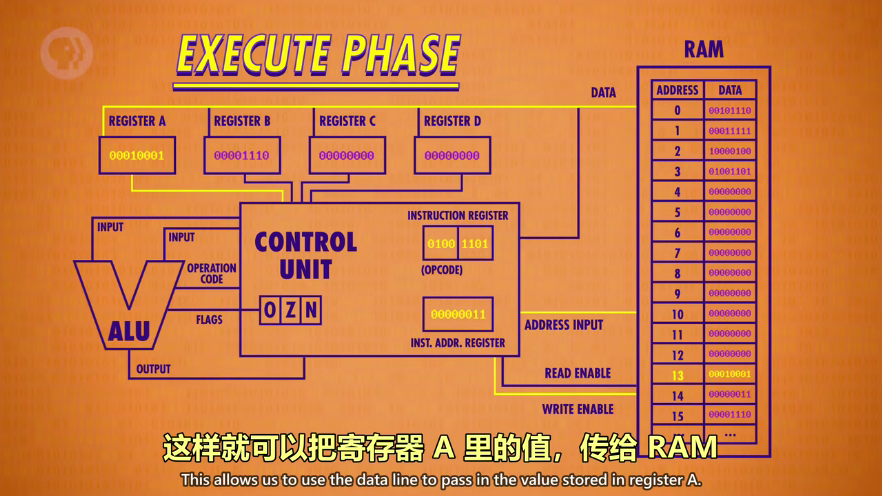
-
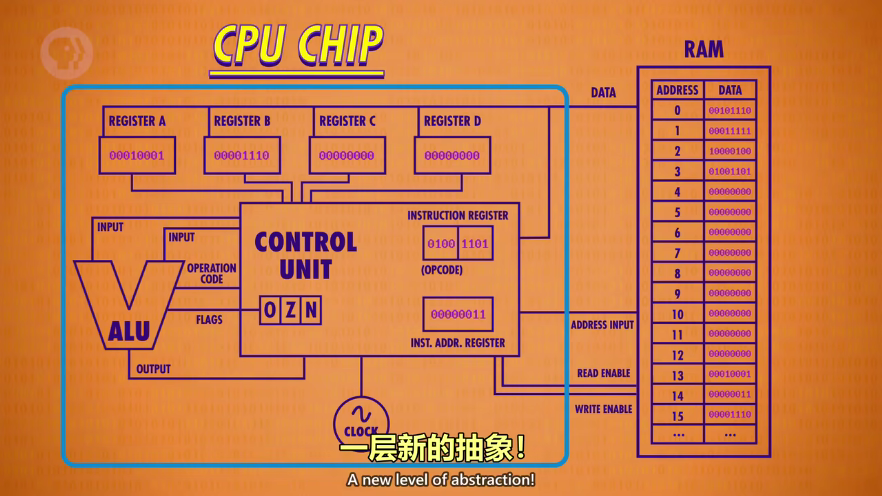
时钟(clock)
CPU”取指令--解码--执行“的速度叫”CLOCK APEED“(时钟速度),用频率赫兹(Hz)表示,一秒多少个周期。 现在计算机几千兆赫意味着一秒几十亿次时钟周期
超频意思是加快时钟速度,使CPU更快运行,降频即可省电
加上时钟后的CPU才是完整的
-
-
RAM是CPU外面的独立组件,CPU 和RAM之间用“地址线”“数据线”“允许读/写先”进行通信
8. 指令和程序
-
指令集
CPU 根据不同指令会执行不同任务,CPU是硬件,可以被软件控制
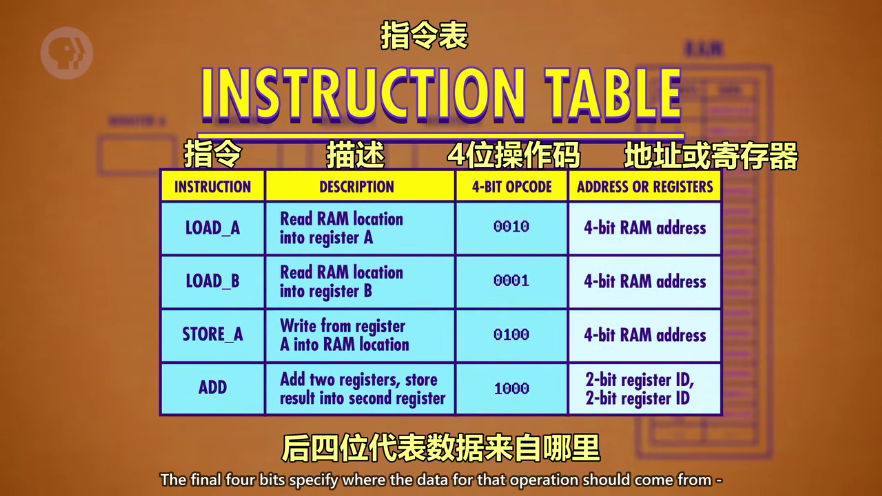
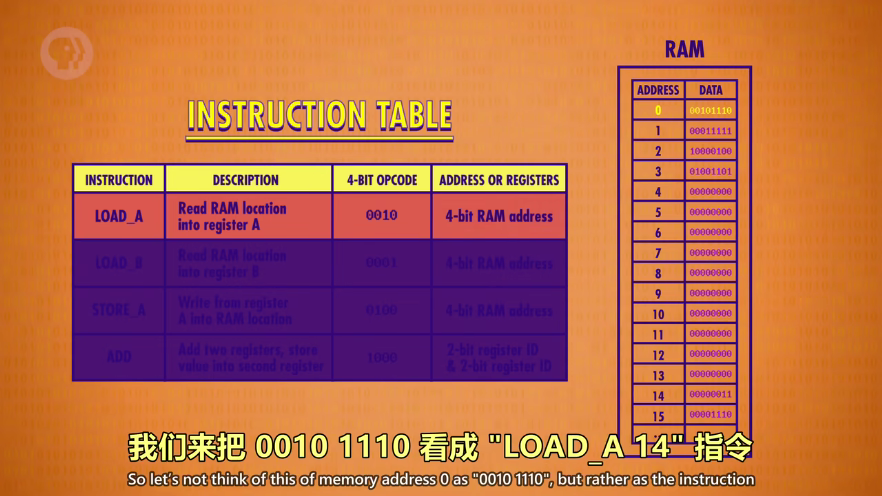
RAM 内存中每个地址可以存 8 位数据,前四位是操作码(opcode),后四位指定一个地址,可以是内存地址或寄存器,前四位操作码也就是指令,可以通过指令表(INSTRUCTION TABLE)查看操作
ps:这里假设的 CPU 很基础,所有指令都是8位,操作码最多4位,最多只有16个指令,16个地址
-
常见指令
LORD_A:读取 RAM 一个地址中的一个值放到寄存器 A
STORE_A:把寄存器 A 的值写入到 RAM的一个地址中
ADD:把两个寄存器的值相加,结果存到第二个寄存器中,如“ADD B A”(A+B)最后结果写入到 A 中
SUB:把两个寄存器的值相减,结果存到第二个寄存器中,如“SUB B A”(A-B)最后结果写入到 A 中
JUMP:跳转,更新指令地址寄存器,指令地址跳转到新地址,以此跳转执行某一指令
JUMP_NEG:带条件跳转,如果 ALU 计算结果为负,执行 JUMP更新指令地址到新地址,否则不执行 JUMP
JUMP_IF_EQUAL:如果相等,跳转
JUMP_IF_GREATER:如果更大,跳转
HALT:程序停止
-
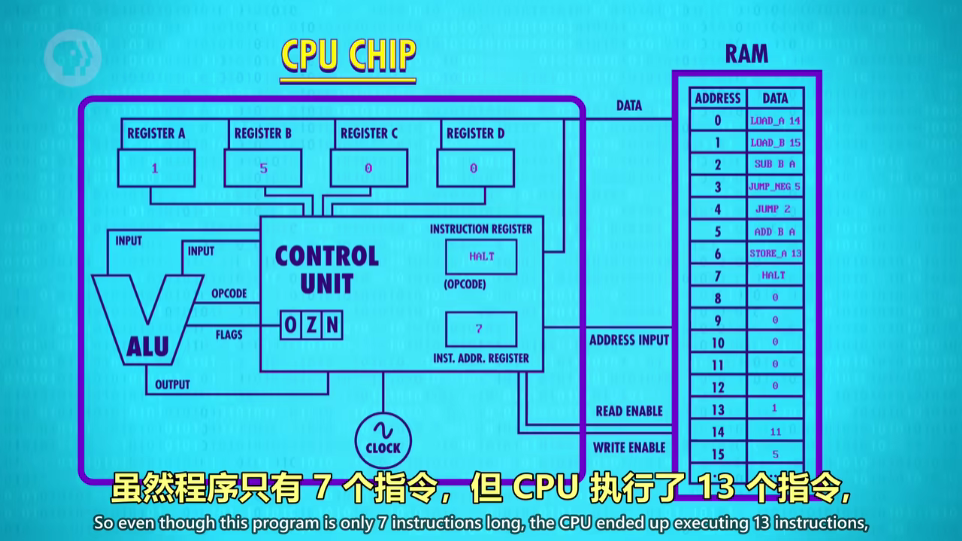
示例(算余数,11除以5余1)
ps:指令和数据都是存在同一个内存里的,ALU有基本的FLAG判断,OZN(是否溢出、零、负)
地址0、1:寄存器 A B 分别拿到值 11、5
地址2:A - B,结果 A = 6
地址3:A 非负,不执行
地址4:跳转到地址2
地址2:A - B,结果 A = 1
地址3:A 非负,不执行
地址4:跳转到地址2
地址2:A - B,结果 A = -4
地址3:A 负,跳转到地址5
地址5:A + B,结果 A = 1
地址6:A 值存到地址13
地址7:结束
-
现代CPU指令集
- 用更多位,比如32位或64位,加长指令长度
- 使用可变指令长度,指令可以是任意长度,JUMP 后面的值叫“立即值”(immediate values)
- 1971年,英特尔 4004 处理器是第一个芯片CPU,支持46个指令,足够做一台电脑
- 现代CPU,英特尔酷睿 i7,有上千个指令和指令变种,长度从1到15字节
9. 高级GPU设计
-
早期 CPU 通过减少晶体管切换时间来提升速度,但是有瓶颈
-
ALU 以减法代替除法导致时钟周期多,计算慢。给 CPU 专门的除法电路,ALU 变得更大更复杂;增加其他电路来做复杂操作,比如游戏,视频解码
-
随着兼容旧指令集 ,指令也越来越多,超快时钟,因为距离远, RAM 处理跟不上 CPU
-
给 CPU 加 CACHE(缓存),RAM 传输一批而不是一个数据给 CACHE,大大提高数据存取速度
-
如果想要的数据已经在缓存中,叫“CACHE HIT”(缓存命中),反之叫“CACHE MISS”(缓存未命中)
-
缓存可以存一些长/复杂运算的中间值
-
脏位(Dirty bit)
- 随着运行,缓存和内存的数据不一致,需要同步数据。当缓存满了而 CPU 又要缓存时,就会发生同步
- 在清理缓存腾出空间之前,先检查“脏位”,如果是“脏”的,那么在加载新数据之前,先把数据写回 RAM
-
并行处理(parallelize)
-
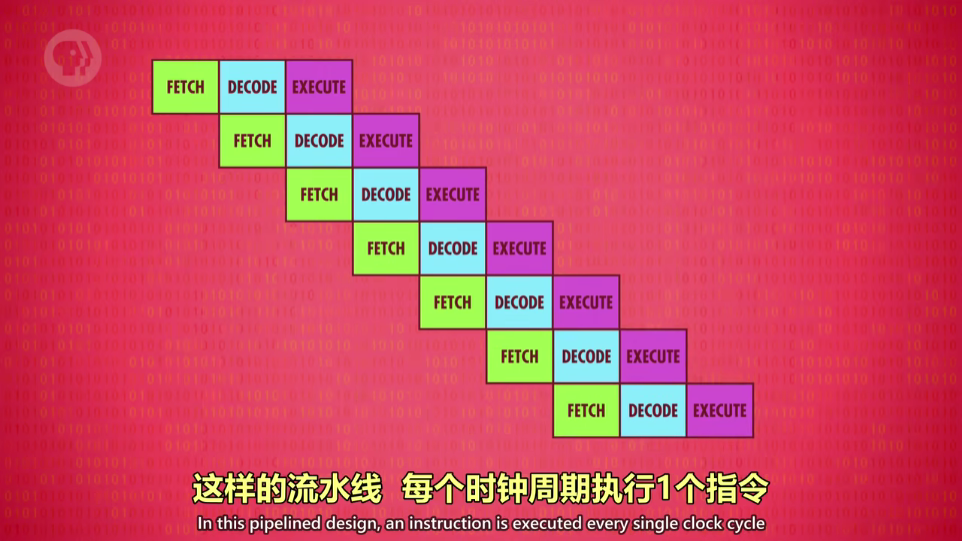
指令流水线 (Instruction Pipelining)
-
取址 - 解码 - 执行,三个时钟周期,但程序每个阶段用的是 CPU 的不同部分,所以可以并行处理,在执行过程同时解码,读取下一个指令,达到一个时钟周期三个指令,提高了吞吐量
-
-
乱序执行(out-of-order execution)
数据依赖性问题。你正在读某个数据,而数据在执行更新,这就要求 CPU 动态排序有依赖关系的指令,最小化流水线的停工时间
-
推测执行(speculative execution)
条件跳转问题。带有 JUMP 指令会改变程序的执行流,导致延迟。CPU 通过推测 JUMP 路线,提前把指令放进流水线。如果 JUMP 的结果被 CPU 猜对了,流水线已经塞满了正确指令,可以马上运行;如果猜错了,则清空流水线(Pipeline Flush)
-
分支预测(branch prediction)
为了减少清空流水线的次数,开发了分支预测方法,现代 CPU 正确率超过 90%
-
多个 CPU
加多个完全相同的 CPU,里面完全相同的 ALU,可以同时执行多个数学运算
-
多核(Core)
多个指令流,双核(dual core)、四核(quad core)。
一个 CPU 芯片里,有多个独立处理单元,可以共享一些资源,比如缓存
-
多个独立 CPU
-
超级计算机,中国的“神威 太湖之光“
40960个 CPU,每个 CPU 有 256 个核心,每个核心频率 1.45GHz,每秒可以进行 9.3亿亿次浮点数运算
10. 早期的编程方式
-
打孔纸卡 >> 插线板 >> 面板拨开关
-
早期程序如何进入计算机:打孔纸卡/纸带
-
打孔纸卡(Punched card)
- 纺织:大多数认为雅卡尔织布机是最早的编程
- 人口普查:1890年美国人口普查使用穿孔纸卡,纸卡用来存数据,并非程序


-
插线板(Plugboard)
只能存放数据的穿孔纸板得到增强,可进行加减乘除,需要某种控制面板,插线板应运而生。面板上有很多插孔,插好电线让机器的不同部分互相传数据和信号。后来发展成可拔插,让机器做不同功能的计算,但是功能越多,电线越乱。


到1940年代晚期1950年代初,内存变得可行,价格下降,容量上升。程序不必存在插线板,而是存放在内存中,更易于修改,方便 CPU 快速读取。用内存存储程序的计算机,叫“Stored-Program Computer”(存储程序计算机)
-
冯诺依曼架构(Von Neumann Architecture)
-
程序和数据(包括程序计算出来的)都存储在同一地方,叫冯诺依曼架构
-
冯诺依曼计算机的标志是,一个处理器(包含算术逻辑单元)+ 数据寄存器 + 指令寄存器 + 指令地址寄存器 + 内存(负责存数据和指令)
-
第一台冯诺依曼架构的“储存程序计算机”,由曼彻斯特大学于1948年建造完成,绰号“宝宝”
-
尽管有内存可以存放程序和数据,但是输入仍然只能用带孔卡片(或类似),输出也是在空白卡片打孔,1980年代的计算机使用穿孔纸卡读取器,卡堆要小心避免顺序弄乱,有个小技巧是,在卡片侧面画对角线
-
除了带孔卡片,还有穿孔纸带等


-
-
面板编程(Panel programming)
用开关和按钮代替插线,早期家用计算机大量使用了面板开关,因为穿孔纸卡读取器这样的外围设备昂贵

-
Altair 8800 是第一款取得商业成功的家用计算机

-
编程依然困难复杂,还要懂底层结构,所以要发展编程语言
11. 编程语言发展史
编程:二进制 >> 助记符(汇编器)>> A-0(编译器) >> FORTRAN
-
二进制写程序,先纸上写伪代码(Pseudo-Code),手工转二进制,很快就烦了
-
助记符(Mnemonics,后面紧跟 Operands,比如 LOAD_A 14),为了把助记符转二进制,汇编器(Assembler)诞生,汇编器读取用汇编语言写的程序,然后转成机器码
汇编的其中一个好功能:自动分析 JUMP 地址,不必担心地址更新问题
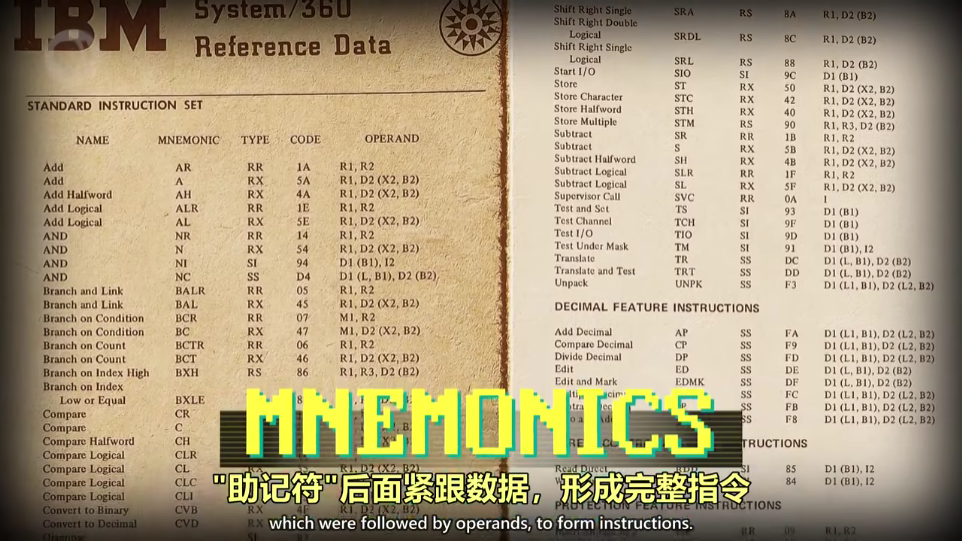

汇编语言与机器指令一一对应,汇编器仍然要手动选择寄存器和内存地址
-
葛丽丝·霍普(Grace Hopper)- 哈佛1号(Harvard Mark 1)计算机首批程序员,海军军官
Mark 1号非常原始,打孔纸带输入程序,没有 JUMP 指令,只能把纸带首尾相连做成循环

-
Grace 设计了编程语言 A-0(Arithmetic Language Version 0),于 1952 年做了第一个编译器(Compiler),实现 A-0,编译器专门把高级语言转成低级语言,比如汇编或机器码(CPU可以直接执行机器码),先前没有人愿意用编译器,认为计算机不能编程,只能计算。A-0 的代码没有遗留下来
-
变量(Variables)
程序员可以创建代表内存地址的抽象,叫变量,取个名字就行
-
FORTRAN
意思是“Formula Translation”(公式翻译),IBM于 1957 年发布,成为早期最流行编程语言
但是并不通用,只能在单一机器环境下使用
-
COBOL
“Common Business-Oriented Language”(普通面向商业语言),政府发布,Grace担任顾问。用 COBOL 编译器兼容不同底层硬件,就可以write once, run anywhere(一次编写,到处运行)
-
新语言
- 1960年代:ALGOL,LISP,BASIC
- 1970年代:Pascal,C,Smalltalk
- 1980年代:C++,Objective-C,Perl
- 1990年代:Python,Ruby,Java
- 千禧年:Swift,C#,Go
12. 编程基础 - 语句和函数
-
变量
变量名代表内存地址,取名要让人看得懂,只要不重复
-
赋值语句
比如 a = 1,从等号右边开始
-
Grace Hopper 拍虫子游戏
-
if 条件判断
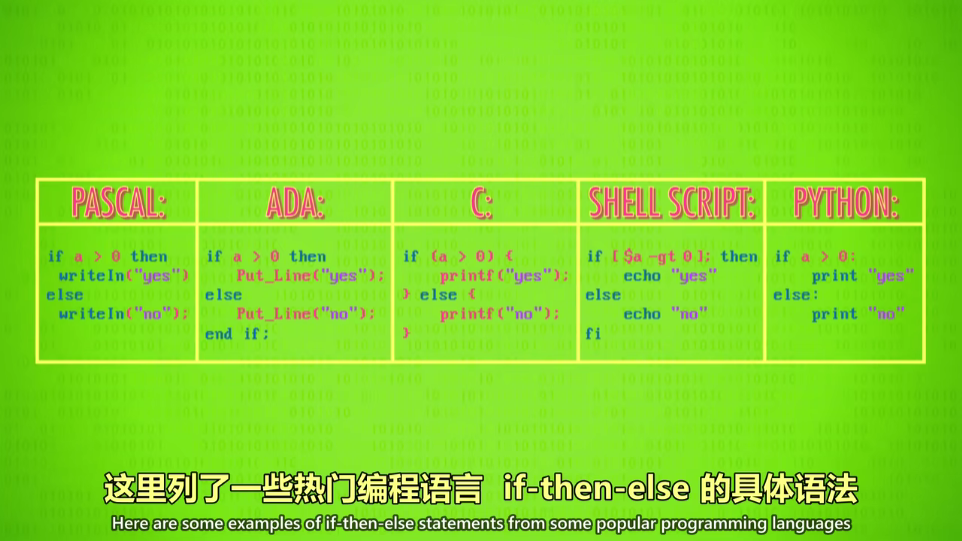
-
while 条件循环
条件为真,进入Loop循环体,条件为假,跳出循环体
-
for 循环
更侧重循环次数,而不是条件
-
函数
少即是多,隐藏复杂度
编程语言的。函数集合:库(Libraries)
13. 算法入门
-
选择排序(Selections Sort)
-
大 O 表示法(Big O notation)
-
归并排序(Merge sort)
先分后归并,复杂度 O(n(logn)) 比选择排序更低,更有效率
-
Dijkstra 算法(图搜索问题)
改进后的迪杰斯特拉算法:从 \(O(n^2)\) 到 \(O(nlogn + I)\),\(I\) 是线数

14. 数据结构
-
数组(Arrays)
-
也叫列表(list)或向量(Vector)
-
连续的一组内存地址,下标 0 存的是第一个数
-
排序函数经常用到数组
-
创建时就有固定大小,不能动态增加大小
-
有顺序限制,在中间插入删除一个值很难
-
-
字符串(Strings)
- 字符组成的数组
- 在内存里以二进制 0 结尾,表示 \(null\)
-
矩阵(Matrix)
-
数组的数组
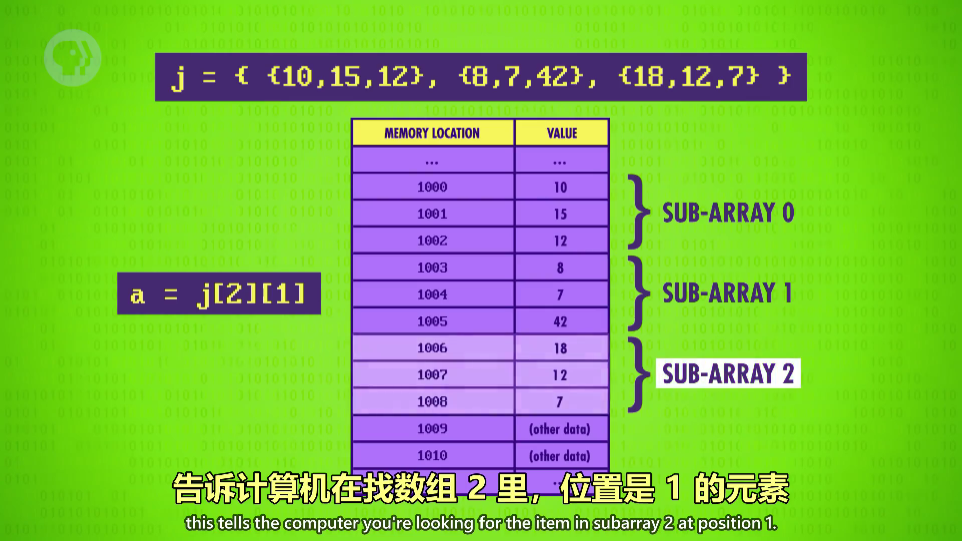
-
不止二维,任何维度都可以,比如\(a=j[2][0][2][4]\)
-
-
结构体(Struct)
-
把多个变量打包在一起,存放多个不同类型的数据,叫结构体 Struct
-
可以做一个数组,里面放很多结构体,这些数据在内存里会自动打包在一起

-
更复杂的结构体,利用指针可以消除数组的限制,比如节点,用节点可以做链表等等
-
-
指针(Pointer)
- 特殊变量,指向一个内存地址
-
节点(Node)
-
存放一个变量和一个指针(next)

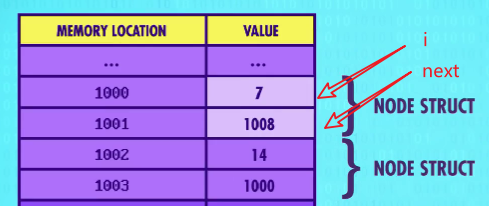
-
-
链表(Linked list)
-
一种灵活的数据结构,能存很多个节点
-
灵活性是通过每个节点指向下一个节点
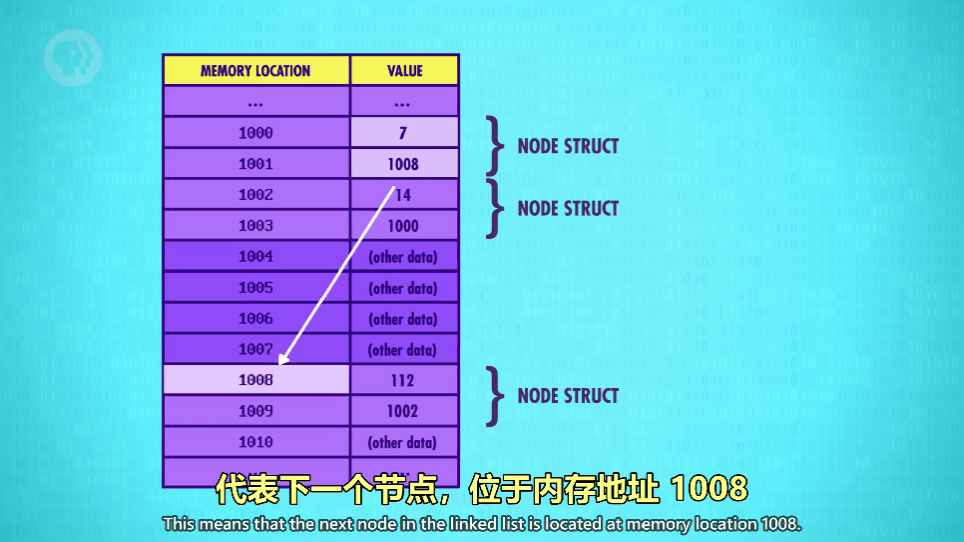
-
最后一个节点指向的地址是第一个节点,那么为循环链表(Circular)
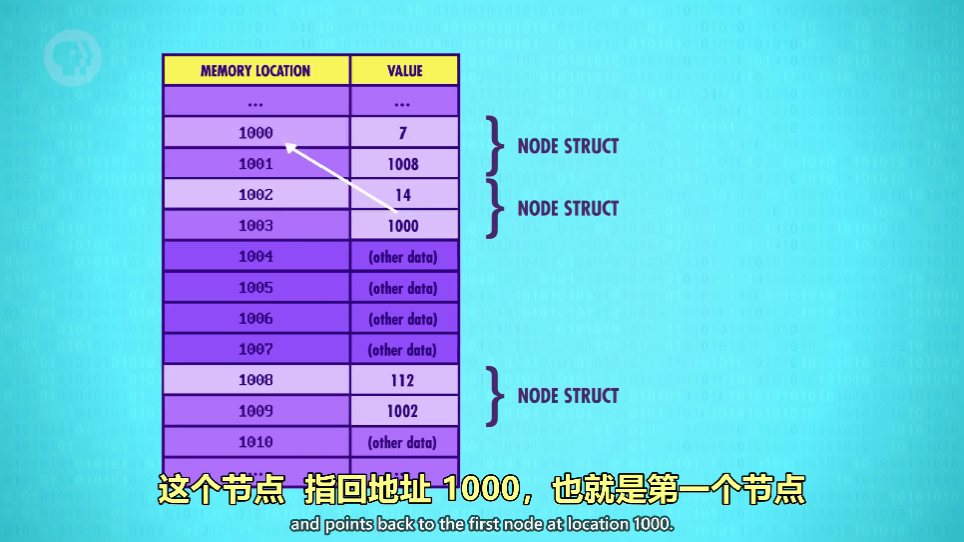
-
最后一个节点的指针变量是 0,也就是 \(null\),那么链表非循环
-
链表可以动态增减长度
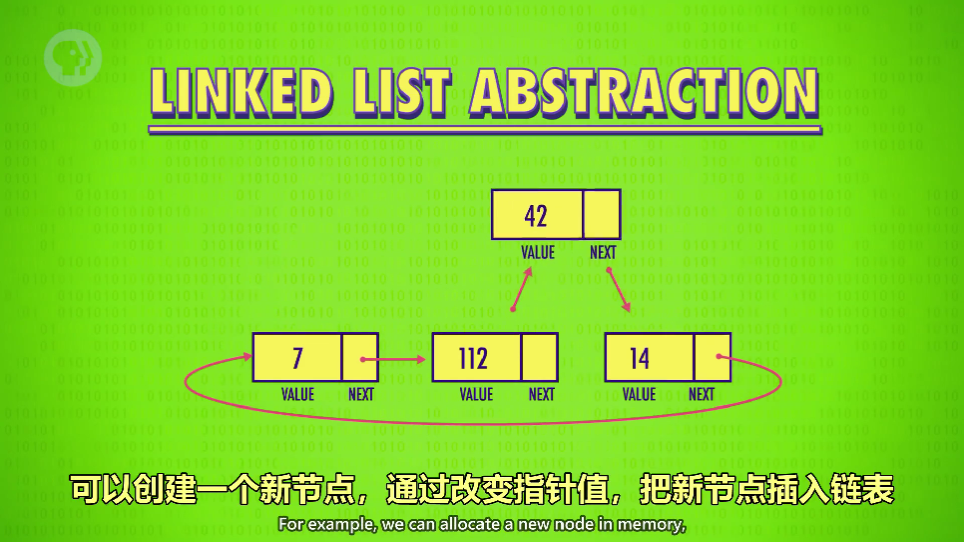
-
链表也很容易重新排序(re-ordered),两端缩减(trimmed),分割(split),倒序(reversed)等,所以很多复杂数据结构都用链表,比如队列和栈
-
-
队列(Queue)
- 一种链表,排队。入队出队(enqueue,dequeue)
- 先来的,排前面。先进先出(FIFO),FIRST IN FIRST OUT
- 队列新增:遍历整个链表到结尾,把结尾的指针指向新节点
-
栈(Stack)
- 一种链表,叠饼。入栈出栈(push,pop)
- 后进先出(LIFO),LAST IN FIRST OUT
-
树(Tree)
-
把节点改成 2 个指针(nextLeft,nextRight)

-
最高的节点为根节点(Root node)
-
根节点下的所有节点,都叫子节点(children node)
-
任何子节点的直属上层节点,叫母节点(parent node)
-
没有任何子节点的节点,也是树结束的地方,叫叶节点(leaf node)
-
树的节点也可以有更多的节点
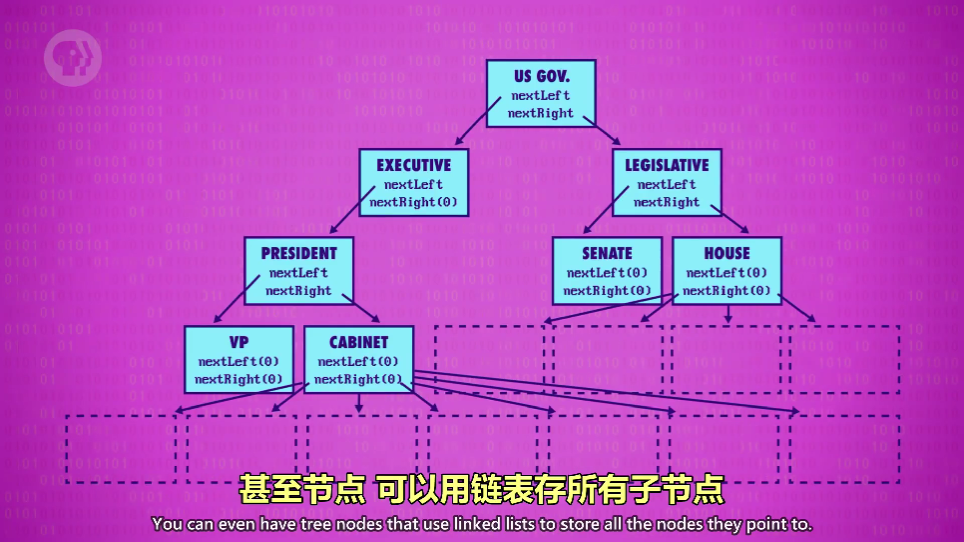
-
树的一个重要特性是:根到叶是单向的,根不会连到叶,叶不会连到根
-
-
二叉树(Binary tree)
- 节点至多有 2 个子节点,为二叉树(binary tree)
-
图(Graph)
- “可以随意连接的树”
- 节点有多个指针,没有根节点父节点子节点之说
-
红黑树(Red-Black Tree)
-
堆(Heap)
-
C++有 STL 库,Java 有 Class 库,预先存有很多数据结构
15. 阿兰·图灵
-
阿兰·图灵(Alan Turing)
计算机科学之父
-
可判定问题(decision problem)
德国数学家大卫·希尔伯特提出的问题:是否存在一种算法,输入正式逻辑语句,输出准确的“是”或“否”答案
-
Lambda 算子
美国数学家阿隆佐·丘奇(图灵的老师),开发了一个叫“Lambda Calculus”的数学表达系统,证明了“可判定问题”这样的算法不存在,Lambda 算子能表示任何计算,但使用的数学技巧难以理解和使用
-
图灵机(Turing Machine)
英国的图灵也想出了一个可以解决“可判定问题”的假想计算机,图灵机。图灵机比之Lambda 算子计算能力相同,但更简单
-
图灵机是一台理论计算设备
-
有无限长的纸带,纸带可以存储符号
-
一个读写头,可以读取和写入纸带上的符号
-
一个状态(STATE)变量,保存当前状态
-
一组规则(RULES),根据当前状态 + 读写头看到的符号,决定机器做什么:结果可能是在纸带写一个符号,或改变状态,或把读写头移动一格,或执行这些动作的组合
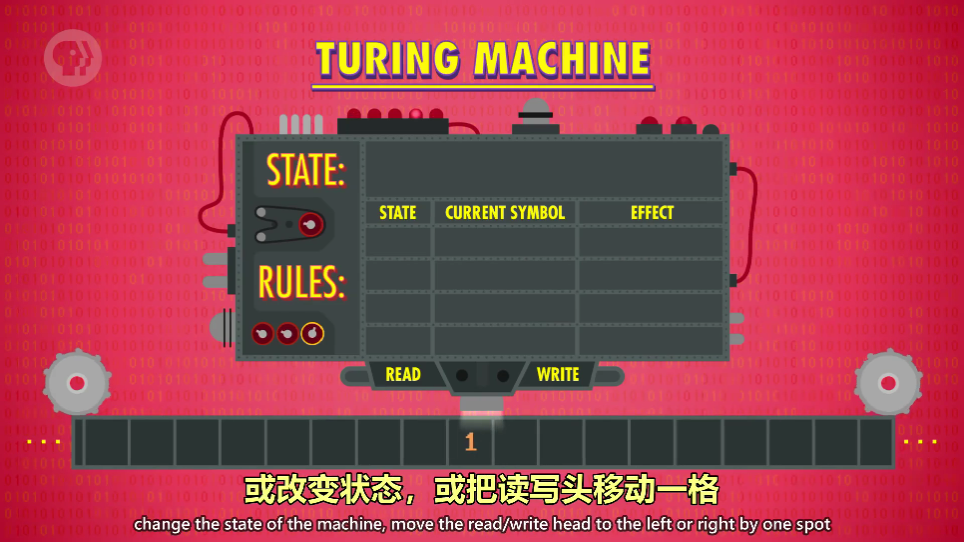
-
-
例如,让图灵机读一个以 0 结尾的字符串,并计算 1 的出现次数是不是偶数,是在纸带上写“1”,不是则写“0”

- 定义规则:如果当前状态是偶数,当前符号是1,那么把状态更新为奇数,把读写头向右移动;如果当前状态是偶数,当前符号是0,那么在纸带上写一个“1”,并且把状态更新为停机(halt),同理定义两条当前状态是奇数的规则。规则定好了,再设置初始状态,这里设置为偶数
- 输入:把“110”放在纸带上
- 读写头读取到”1“,执行规则,状态更新为奇数,读写头向右移动;读写头读取到”1“,执行规则,状态更新为偶数,读写头向右移动;读取到”0“,此时状态为偶数,执行规则,在只带上写一个”1“,表示结果为真为偶数,然后停机
-
图灵机证明了只要有足够时间和内存,就可以执行任何计算(足够的规则,状态和纸带,可以创造任何东西),因为简单,所以图灵机是很强大的计算模型
-
图灵完备(Turing complete):日常用到的设备,从微波炉到电脑,都属于图灵完备
-
-
停机问题(Halting Problem)
- 给定图灵机描述和输入纸带,是否有算法可以确定机器会永远算下去,还是到某一点会停机
- 图灵用图灵机证明停机问题无法解决
- 假设有个叫“H”的图灵机可以判断是否会停机,回答可以和不可以解决,那么可以有一台反着来的图灵机叫“异魔”,它有着“H”的判断机制,但是如果会停机它就永远不停机,如果不停机就立马停机。如果把“异魔”本身作为输入,那么当“H”判断“异魔”不会停机,“异魔”将输出不会停机,然后立马停机。这是一个悖论,意味着停机问题不能用图灵机解决,不是所有问题都能用计算解决,即使有无限时间和内存
- 开启了可计算性理论,也就是“丘奇-图灵论题”
-
破解德军英格玛加密机Bombe
破解密码的组合会有数十亿种。做了一个机器,利用了字母解密后不是本身这一突破口,如果出现解密后一致的字母,那么放弃这一组合
-
图灵测试
一个计算机能让人相信它是人类,才算智能,这样的测试就是图灵测试。利用图灵测试,验证码可以防止机器人发送垃圾信息
-
图灵个人生活和图灵奖
- 图灵因为是同性恋,当时的法律判他违法,图灵为了事业工作等原因不得已服药,后来性格发生变化于1954年服毒自尽,年仅41岁
- 计算机领域最高奖,图灵奖
16. 软件工程
-
对象(Object)
把函数打包成层级(hierarchy),把相关代码都放在一起,打包成对象
-
面向对象编程(Object Oriented Programming)
面向对象的核心是隐藏复杂度,选择性公布功能,C++,C#,Objective-C,Python,Java
-
API (Application Programming Interface)
-
开发团队需要文档(Document),帮助理解代码都做什么,以及定义好的程序编程接口,简称 API
-
API 帮助不同程序员合作,而不用知道具体细节
-
-
public 和 private
private:只有同一个对象内的其他函数能调用它,反之 public 其他对象也可使用
-
集成开发环境,IDE - Intergrated Development Environments
集成了很多功能,帮助开发者写代码,整理,调试等等
-
调试(debug)
大多数时间在 debug,而不是写代码
-
文档和注释(readme,comment)
知道代码是做什么的,非常重要,提高复用性
-
版本控制(Version control)
-
也叫源代码管理(Source Control),比如 GIT,SVN
-
把写好的有用代码放到代码仓库(Repository),当改一段代码,可以 check out,可以在 IDE 里 commit(提交)
-
防止更新后的代码提交了,别的团队调用出现错误,master(主版本)应保持编译正常,尽可能少 bug
-
可以 roll back(回滚)到之前的稳定版
-
源代码管理,也记录了更改者提交记录等
-
-
质量控制(Quality Assurance testing 即 QA)
严格测试软件的方方面面,模拟各种情况,找软件的 bug
-
Beta,Alpha
beta:没有 100% 测试过的版本,发布公众(免费的 QA 团队),以帮助发现问题
alpha:一般只在内部测试,很粗糙,错误很多的版本
17. 集成电路与摩尔定律
重点:晶圆的制作流程:光刻
-
分立元件(Discrete components)
1940-1960年代,计算机的部件是独立的。分立元件就是指只有一个电路元件的组件,比如电阻、电容、电感这些被动的,或是晶体管、真空管这些主动的
不同组件再用线连在一起
ENIAC 有 17000 多个真空管,70000 多个电阻,10000 个电容器,7000 个二极管,500 万个手工焊点
-
数字暴政(Tyranny of Numbers)
1960 年代工程师遇到的问题。如果想加强电脑性能,就需要更多不减,导致更多线路复杂化
晶体管小、快、便宜,替代了电子管,晶体管标志着计算机迎来第二次发展。但仍然是分立元件,元件越多,设计越复杂
-
集成电路(IC,Integrated Circuits)
把多个组件打包在一起,成为一个新的组件,用硅制成的仙童半导体
Noyce 被公认为现代集成电路之父,开创了电子时代,创造了硅谷(Fairchild 所在地)
-
PCB(printed circuit board,印刷电路板)
蚀刻金属线来连接零件,而不是用电线
把 PCB 和 IC 结合起来,大幅减少了独立组件和电线
小、便宜、可靠
-
光刻(Photolithography)
先前的 IC 封装的晶体管还是体积较大。光刻是指用光把复杂电路蚀刻进硅片上做 IC
-
晶圆(Wafer)
很薄的硅片,集成电路绝佳的半导体
-
光刻胶(Photoresist)
在硅片上加的氧化层用来保护。氧化层之上的光刻胶,被光照射后可溶
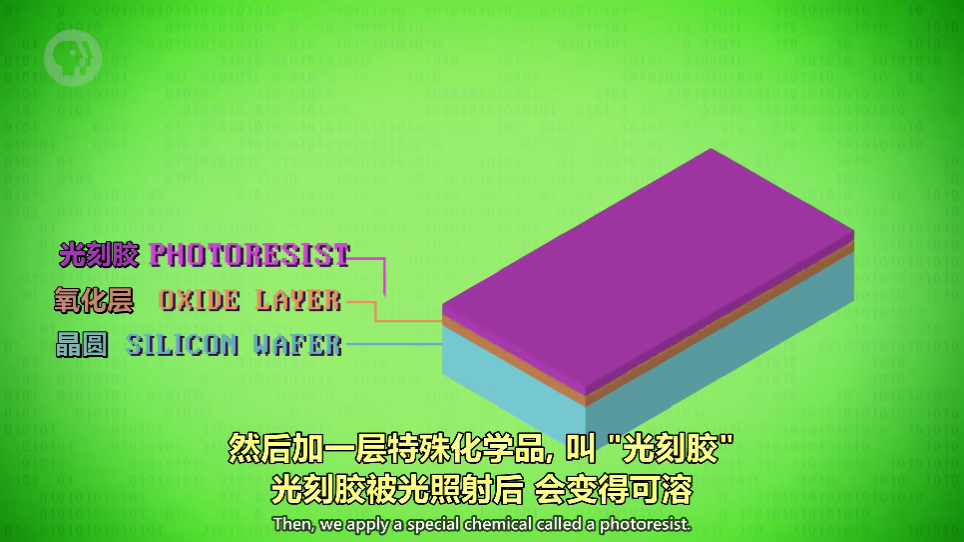
-
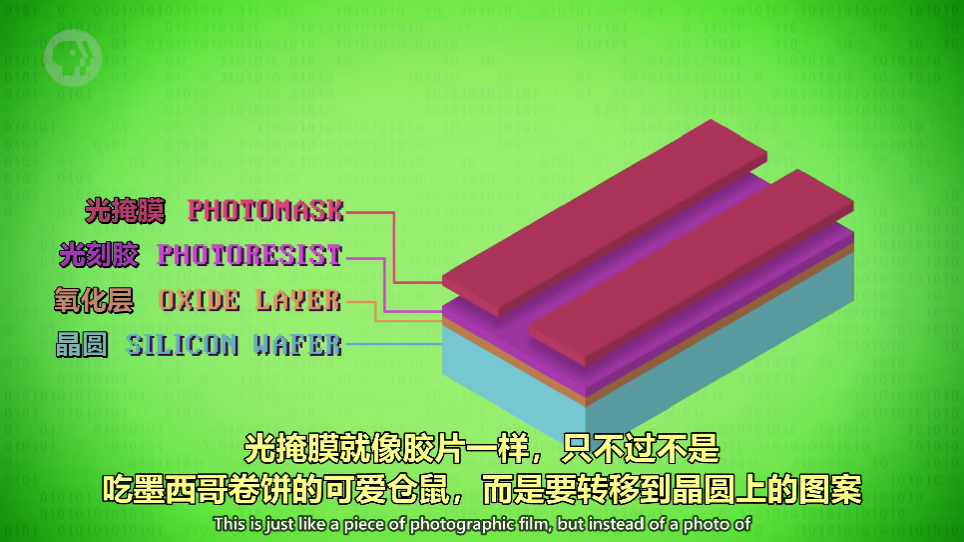
光掩膜(Photomask)
用来挡住光和引导光照下的图案。光照下后,光刻胶发生化学变化(掩膜部分不会)。清洗掉光刻胶,暴露出氧化层,再用酸清洗掉氧化层,蚀刻到硅层
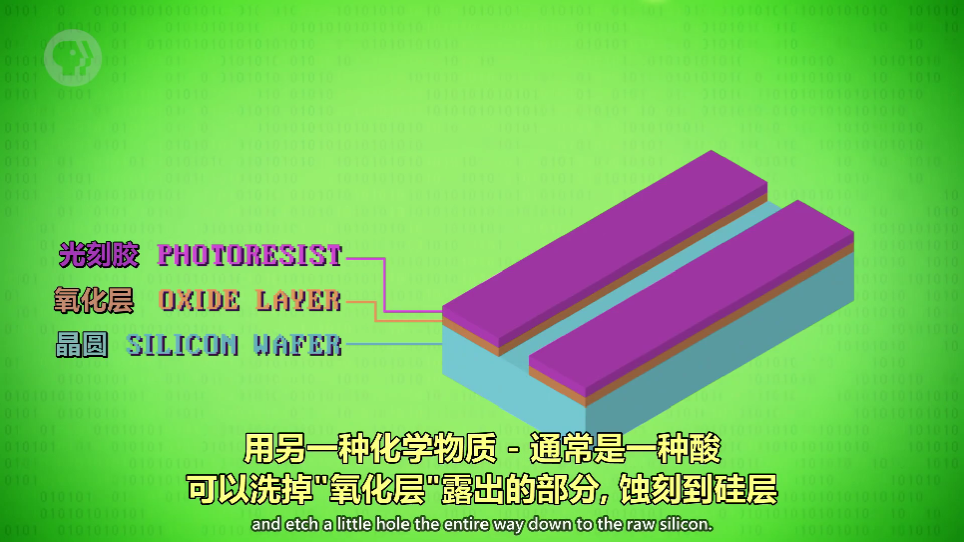
蚀刻完毕后再洗掉光刻胶
-
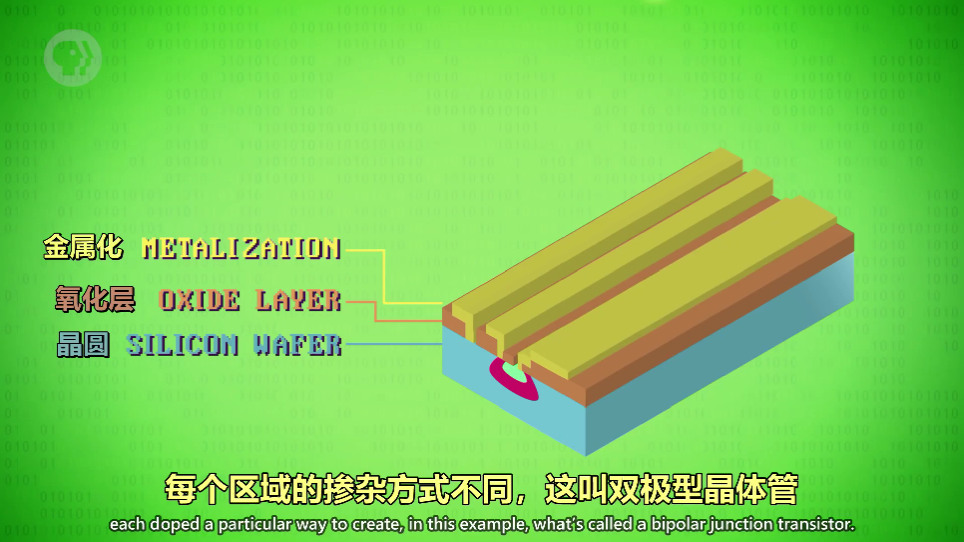
掺杂(Doping)
高温气体渗透进暴露的硅,改变电学性质

前前后后使用了多次加层和清洗,使用不一样的高温气体改变半导体性质,控制深度和时机
蚀刻细小通道在金属上(铝铜),以便晶体管之间的连接
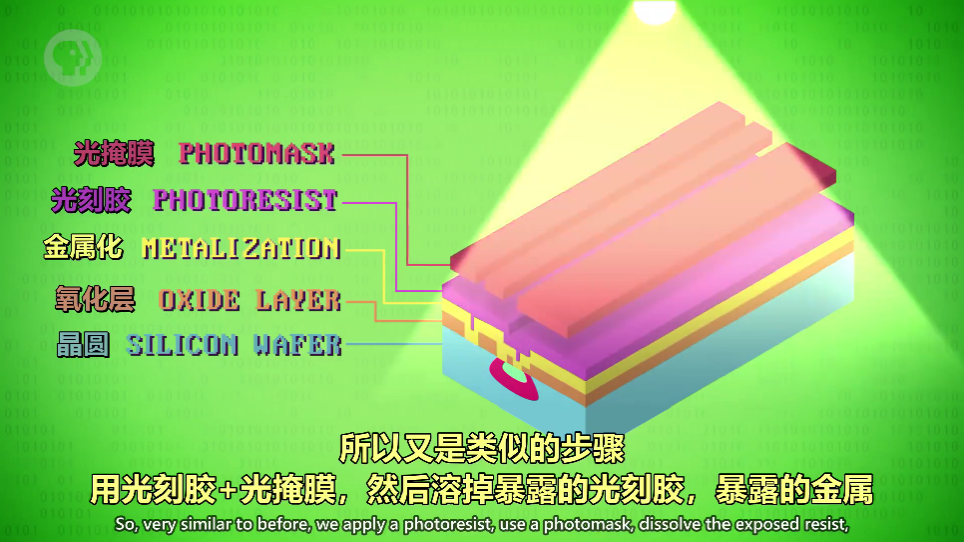
双极型晶体管,这个 1962 年的真实专利改变了世界

-
摩尔定律(Moore's Law)
一种趋势,1965 年由戈登·摩尔发现。每两年左右,得益于材料和制造技术的发展,同样大小的空间,能塞进两倍数量的晶体管
-
英特尔(Intel)
1968 年,Noyce 和 Moore 联手成立了 Intel,Intel 结合 Intergrated(集成)和 Electronics(电子)两个词
集成电路用来做微处理器,CPU 在一个小芯片里,开启了计算机第三次飞跃(其他电子产品也是迅猛发展)
-
晶体管数量大幅增长,1980 年三万个,1990 年一百万个,2000 年三千万个,2010 年十亿个
苹果7的A10处理器,面积仅有1平方厘米,有33亿个晶体管
-
进一步小型化的问题(摩尔定律可能要终结)
- 光的波长不足以制作更精细的设计
- 量子隧穿效应:当晶体管非常小,电极之间可能只距离几个原子,电子会跳过间隙,晶体管漏电

 浙公网安备 33010602011771号
浙公网安备 33010602011771号