B树、B+树
文章参考:
终于把B树搞明白了(三)_B树的查找,B+树的引入_哔哩哔哩_bilibili
一. B树
1. 概述
1.1 为什么使用B树
对数据进行IO的耗时:影响IO的耗时有很多,这里主要将两点:
- 数据块的大小:磁盘IO的单位为磁盘块,将IO的磁盘块中的数据以页的形式存放在内存中。一般磁盘块和页的大小由操作系统决定,因此如果数据块过大,需要进行多次IO。
- IO的次数:这个涉及到数据的寻址次数,如二叉排序树,不同节点随机存放在不同的磁盘地址,在进行查找时,二分查找保证IO的最多次数为\(log(n)\)。
以往数据结构的缺点:
- 二叉排序树:遇到顺序插入会退化为链表。IO次数过多。
- 平衡二叉树:写的代价过高,需要进行多次旋转。
- 红黑树:数据量较大时,树的深度将会难以控制。会导致IO次数增多。
B树的核心思想:
因此我们需要改进,如果我们将节点的最大子节点树修改为M个而不2个,那么树的深度将会得到有效控制,此时纵向的IO次数大大减少。
此外,我们将每个节点的所有字节点顺序存储,放在一块内存中,这样一次IO就可以读到某个节点的所有子节点,随后在内存中对这些子节点进行对比。避免了横向的多次IO。
1.2 B树的定义
B树是一种多路搜索树,一棵m阶(每个节点最多有m个子节点)的B树满足如下条件:
- 树中每个节点至多有m个孩子。
- 根节点的儿子数为\([2, m]\)。
- 除根节点以外的非叶子节点的儿子数量为\([m/2, m]\)。
- 每个节点存放的关键字(就是索引,用于排序的):
- 至少为\([m/2 - 1]\)(向上取整,且不能少于2个)
- 最多为\(m-1\)个。因为关键字之间是指向子节点的指针,而每个节点的字节最多为m个,那么每个节点的指针最多也是m个,所以关键字最多为m-1个。
- 非叶子节点的关键字:\(k[1],k[2],...,k[m-1]\),有\(k[i]<k[i+1]\)。
- 非叶子节点的指针:\(p[1],p[2],...,p[m]\),其中:
- \(p[1]\)指向的子树的所有关键字小于\(k[1]\)
- \(p[m]\)指向的子树所有关键字大于\(k[m-1]\)
- \(p[i]\)指向的子树的所有关键字大于\(k[i-1]\),小于\(k[i]\)
- 所有叶子节点位于同一层。
1.3 一个3阶b树
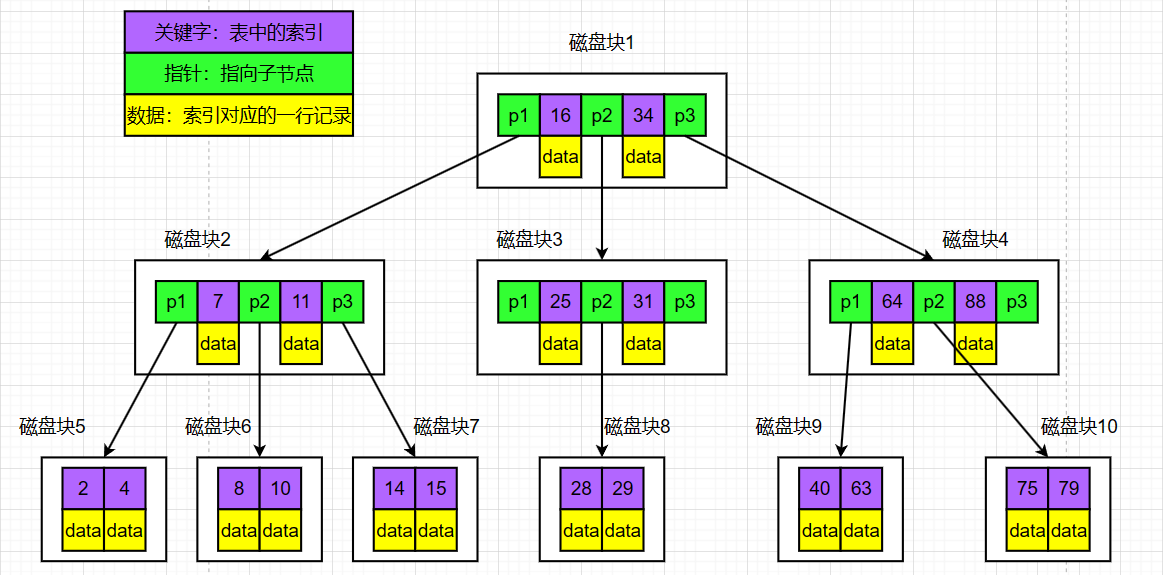
从中可以得出以下结论:
- 指针存在为空的情况。
- B树中索引和该索引对应的记录(数据)存储在一起。
- 有时不需要读到叶子节点即可命中。
- 每个节点存在一块内存中,一次IO可以读取一块节点。
2. B树的搜索
逻辑:具体逻辑如下:
- 从根节点开始。
- 对当前节点,采用二分查找,如果命中,那么找到数据;否则进入3。
- 查找该关键字所在范围的指针指向的儿子节点,重复2、3操作。
- 如果3中对应范围的儿子节点为空,或者该节点已经是叶子节点,说明不存在该关键字,查找结束。
3. 插入
4. 删除
二. B+树
1. 概述
1.1 为什么要使用B+树
B树的缺陷:
B树将关键字和该关键字对应的记录绑定,一同记录在节点中。因为数据的大小是浮动的,且有很多时候数据会很大,而B树中节点的大小一般是固定的(一页或页的整数倍),这会导致每个节点中关键字数量较少。又因为\(指针数量=关键字数量+1\),所以指针数量也会较少,那么该节点的字节点数量就会较少。树的宽度降低,那么深度自然增加。结果就是IO次数又变多了。
B树子节点数量限制:假设操作系统为64位,关键字为int,一行数据大小为1kB,节点的大小为一页(16kB),那么每个节点最多有几个子节点。
-
64位操作系统,指针大小为8B,关键字大小为4B。
-
假设指针m个,关键字m-1个,那么:
\[8m+(m-1)*(1k+4)=16k\\\\ k\approx 17 \]
而当每条记录数据量较大时,例如每条数据大小为8kB,那么一个节点就只有两个关键字了,显然,这会导致树的深度再次加深。
B+树的核心思想:
非叶子节点中不再记录数据,只存储指针和关键字,而数据只存储在叶子节点中。有以下优势:
- 一个节点可以存储众多指针和关键字,树的宽度大大增加。
- 只在叶子节点才会读到数据,十分稳定。
1.2 B+树的定义
B+树是一种B树的变体,也是一种多路搜索树。对于一棵m阶B+树,有:
-
和B树一样的:
-
树中每个节点至多有m个孩子。
-
根节点的儿子数为\([2, m]\)。
-
除根节点以外的非叶子节点的儿子数量为\([m/2, m]\)。
-
每个节点存放的关键字(就是索引,用于排序的):
- 至少为\([m/2 - 1]\)(向上取整,且不能少于2个)
- 最多为\(m-1\)个。因为关键字之间是指向子节点的指针,而每个节点的字节最多为m个,那么每个节点的指针最多也是m个,所以关键字最多为m-1个。
-
非叶子节点的关键字:\(k[1],k[2],...,k[m-1]\),有\(k[i]<k[i+1]\)。
-
-
和B树不一样的:
- 非叶子节点的子树指针和关键字数量一致。
- 非叶子节点的子树指针\(p[i]\),指向的子树关键字范围是:\([ k[i], k[i+1] )\)(注意是左闭右开)
- 为所有的叶子节点增加一个链指针。
- 所有的关键字在叶子节点中均出现。
1.3 一个3阶B+树
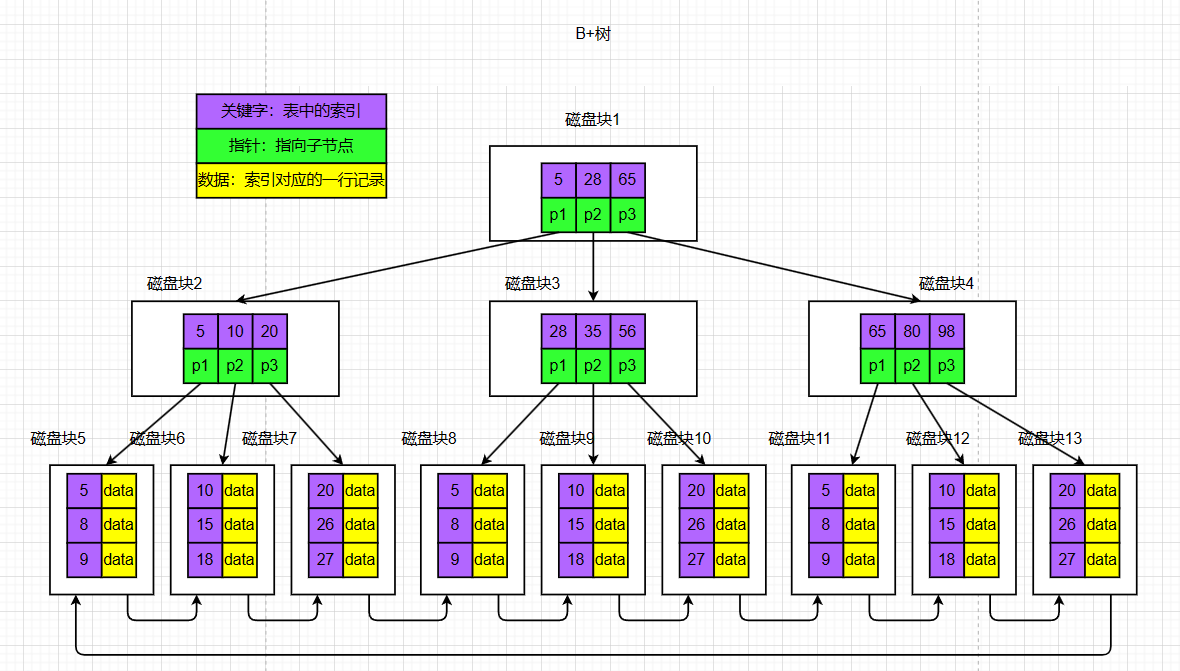
其中:
- 所有的关键字都在叶子节点出现,以链表的形式顺序存储。
- 因为只有叶子节点存有数据,因此只有在叶子节点才能命中。
- 非叶子节点相当于叶子节点的索引。
- 每一个叶子节点都包含一个指向下一个叶子节点的指针。这方便了叶子节点的
范围遍历。 - 更加适合文件索引系统。
2. B+树的搜索
和B树类似,区别主要有两点:
- B+树必须到叶子节点才能命中,因为只有叶子节点存储了数据。
- B+树叶子节点之间通过指针相连,遍历十分方便。而B树的遍历则只能通过中序遍历才能得到递增的序列。
3. 为什么MySQL使用B+树而非B树作为索引结构
-
B+树的IO次数更少。
- B+树非叶子节点只用来存储关键字和指针,不存储数据。因此非叶子节点可以有更多的子节点。树的深度得以降低,平均IO次数更少。
- B树中所有节点中的关键字和数据均成对出现,即便是在非叶子节点中。因此单个非叶子节点容纳的关键字数量较少,树的宽度被限制,深度增加,平均IO次数增加。
-
B+树的查询效率更稳定。
- B+树将所有数据存储在叶子节点,因此每次查询都要到叶子节点。
- 而B树则可能在非叶子节点命中。
-
B+树更加擅长范围查找:
- B+树的叶子节点通过指针双向指针相连,可以直接遍历。
- B树的范围查找只能通过中序遍历进行,效率较低。
-
B+树更加适合遍历。
- B+树将所有数据和对应关键字存在叶子节点中,不同叶子节点之间通过指针相连,因此遍历只需要扫描一遍叶子节点即可。
- B树非叶子节点也有数据,因此遍历要走所有节点,也需要遍历那些没有数据的节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号