使用Beautiful Soup扒取指定标题
# coding:utf-8 import requests from bs4 import BeautifulSoup BASE_LIB='html5lib' UA='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' HEADERS={'user-agent':UA} url='http://www.runoob.com/' resp = requests.get(url, headers=HEADERS) #向指定的url发出请求得到响应对象resp text = resp.text.encode('iso-8859-1').decode('utf-8') #通过resp对象的text可以得到响应文本,但需要字符编码的转换 bs = BeautifulSoup(text, BASE_LIB) # 如果不使用html5lib,系统默认会使用lxml,beautiful soup就是html解析器 divs=bs.select('div.col.middle-column-home > div') #获取符合css选择器内容,得到一个list for div in divs[:10]: #只取前10个(pc端)分类,后面是移动端 h4s=div.select('h4') #从每个分类中找出h4标题 for h4 in h4s: print h4.text
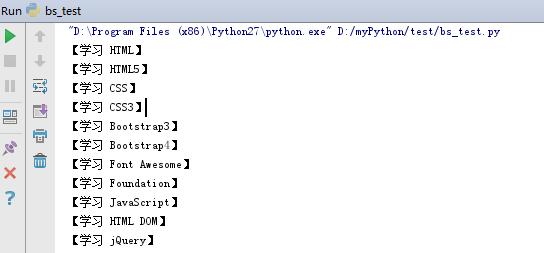
从菜鸟教程中扒取的标题截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号