hadoop完全分布式安装(ubuntu)
一、安装虚拟机软件VMware
VMware10
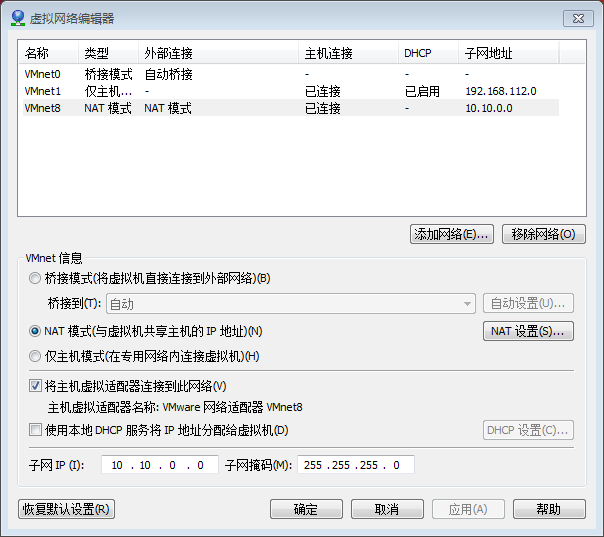
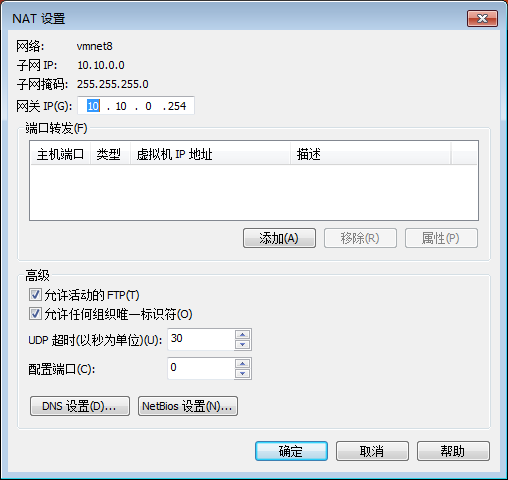
设置NAT模式
不使用DHCP为虚拟机自动分配IP,为虚拟机设置静态IP作准备。
二、安装ubuntu
1、添加虚拟机,安装ubuntu
其中要选择"稍后安装系统",否则vmware默认会采用简易安装ubuntu,后面采用"正常安装"
2、设置网络
(1)虚拟机网络连接选择"NAT"
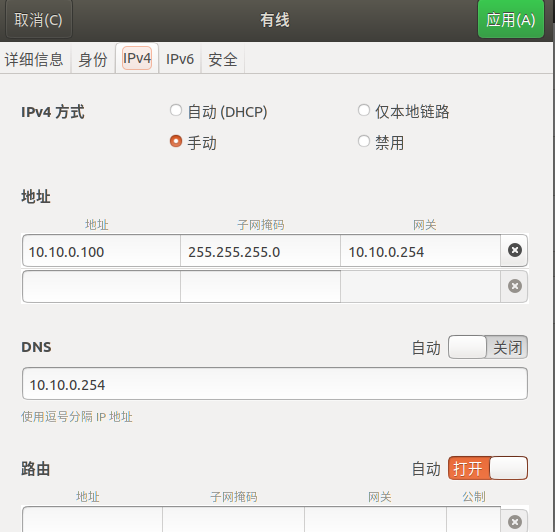
(2)手动设置IP
#注意:网关和NAT设置中的网关保持一致,DNS选择网关地址,这样就可以连接上外网。
问题描述:
最小化安装ubuntu,结果使用ifconfig查看IP,提示没有安装net-tools。使用sudo apt install net-tools安装,又提示没有可用的软件包net- tools,但是它被其他的软件包引用了。
解决方法:
进入下面第3步后,再使用sudo apt-get update更新软件列表。
3、修改ubuntu的软件镜像源
#国外的镜像网速慢,可更改为阿里云的镜像
最简单的方法是:
桌面系统中的“ubuntu软件"更新中,选择中国的镜像-阿里云镜像,亲测速度明显提升。如果采用这种方法,就无视下面(1)、(2)步。
(1)修改sources.list文件
$>sudo vim /etc/apt/sources.list
[/etc/apt/sources.list]
deb http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
(2)更新软件列表
$>sudo apt-get update //更新软件列表,apt-get upgrade是软件列表中的软件
三、安装vmware-tools工具
#目的:实现宿主机和虚拟机之间数据共享,如:共享剪贴板,共享文件夹,文件拖拽复制等功能。
1、安装VMware Tools
(1)在vmware软件中操作
在vmware中,“虚拟机"->"安装VMware Tools"->在ubuntu桌面出现光盘图标(这个光盘就是加载vmware主目录下的linux.iso文件)。
(2)在ubuntu系统中操作
将光盘中的"VMwareTools-9.6.2-1688356.tar.gz"解圧到硬盘,进入其子目录"vmware-tools-distrib",打开终端,执行:sudo ./vmware-install.pl
说明:安装期间一路回车,如果出现"找不到gcc binary"的提示,需要修改vmware-tools-distrib/bin/vmware-config-tool.pl,使用vim打开后,ctrl+F查找"kh_path",将"$kh_path=''"注释掉后,然后重新安装,出现指定gcc路径时选择no。
2、设置共享文件夹
关闭ubuntu系统,在vmware中设置共享文件夹,记住共享名,然后启动ubuntu,打开终端。
$>vmware-hgfsclient #出现共享名
问题描述1:
进入/mnt/hgfs中看不到宿主机的共享内容,手动挂载。
解决方法:手动挂载
$>sudo vmhgfs-fuse .host:/BigData /mnt/hgfs
问题描述2:
Command 'vmhgfs-fuse' not found, but can be installed with:sudo apt install open-vm-tools
解决方法:
$>sudo apt install open-vm-tools
$>sudo vmhgfs-fuse .host:/BigData /mnt/hgfs
问题描述3:
fuse: mountpoint is not empty
fuse: if you are sure this is safe, use the 'nonempty' mount option
解决方法:
$>sudo vmhgfs-fuse .host:/BigData /mnt/hgfs -o nonempty -o allow_other #要加allow_other,否则普通用户不能访问hgfs
四、安装JDK
1、安装
将下载的安装包放入宿主机的共享文件夹中,然后客户机上的/mnt/hgfs目录tar开。
$>cd /mnt/hgfs
$>tar -zxvf jdk-8u181-linux-x64.tar.gz -C ~/app/
$>cd ~/app
$>mv jdk-8u181-linux-x64 jdk #改名
2、配置
$>cd ~
$>nano .bashrc
[~/.bashrc]
#在末尾加以下内容:
export JAVA_HOME=/home/zyz/app/jdk
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
#nano文本编辑器,ctrl+o是保存,ctrl+x是退出。
$>source .bashrc #编译生效
五、安装hadoop
1、安装
$>cd /mnt/hgfs
$>tar -zxvf hadoop-2.7.3.tar.gz -C ~/app/
$>cd ~/app
$>mv hadoop-2.7.3.tar.gz hadoop #改名
2、配置
(1)配置环境变量
[~/.bashrc]
export JAVA_HOME=/home/zyz/app/jdk
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export HADOOP_HOME=/home/zyz/app/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
$>source .bashrc
(2)编辑slaves文件
[$HADOOP_HOME/etc/hadoop/slaves]
slave1
slave2
#指定datanode
(3)编辑core-site.xml
[$HADOOP_HOME/etc/hadoop/core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zyz/app/hadoop/tmp</value>
</property>
<!-- 以下使用hiveserver2访问hive时需要的配置 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
(4)编辑hdfs-site.xml文件
[$HADOOP_HOME/etc/hadoop/hdfs-site.xml]
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 事先在$HADOOP_HOME中创建hdfs文件夹,hdfs里的name和data文件夹,格式化时系统自动创建 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zyz/app/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/zyz/app/hadoop/hdfs/data</value>
</property>
</configuration>
(5)编辑yarn-site.xml
[$HADOOP_HOME/etc/hadoop/hdfs-site.xml]
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>dfs.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>
(6)编辑hadoop-env.sh
[$HADOOP_HOME/etc/hadoop/hadoop-env.sh]
export JAVA_HOME=/home/zyz/app/jdk
(7)编辑yarn-env.sh
[$HADOOP_HOME/etc/hadoop/yarn-env.sh]
export JAVA_HOME=/home/zyz/app/jdk
六、完整克隆master为slave1和slave2
1、修改slave1
(1)修改slave1网络地址
IP:10.10.0.101
子网掩码:255.255.255.0
网关:10.10.0.254
DNS:10.10.0.254
说明:IP采用手动,即静态,在桌面环境下修改即可。
(2)修改slave1的主机名
$>nano /etc/hostname
slave1
2、修改slave2
(1)修改slave2网络地址
IP:10.10.0.102
子网掩码:255.255.255.0
网关:10.10.0.254
DNS:10.10.0.254
(2)修改slave1的主机名
$>nano /etc/hostname
slave2
七、集群ssh免密登录
1、安装ssh-server
$>sudo apt install ssh-server
2、配置免密登录
以master为例:
(1)生成密钥对
$>ssh-keygen -t rsa -p ""
[~/.ssh]
id_rsa #私钥
id_rsa.pub #公钥
authorized_key #认证库
(2)将公钥的内容追加到认证库
$>cat id_rsa.pub >> authorized_key
(3)登录localhost
$>ssh localhost
$>exit #退出
(4)slave1重复(1)~(3)
#将slave1生成的公钥复制到master
$>scp id_rsa.pub zyz@master:/home/zyz/.ssh/id_rsa_slave1.pub #在slave1的~/.ssh下操作
#在master上将复制过来的slave1的公钥id_rsa_slave1.pub的内容追加到认证库authorized_key
$>cat id_rsa_slave1.pub >> authorized_key
(5)slave2重复(1)~(3)
#将slave2生成的公钥复制到master
$>scp id_rsa.pub zyz@master:/home/zyz/.ssh/id_rsa_slave2.pub #在slave2的~/.ssh下操作
#在master上将复制过来的slave2的公钥id_rsa_slave2.pub的内容追加到认证库authorized_key
$>cat id_rsa_slave2.pub >> authorized_key
(6)将master中含有3个机器的公钥内容的认证库authorized_key复制到slave1和slave2的.ssh目录下。
$>scp authorized_key zyz@slave1:/home/zyz/.ssh/
$>scp authorized_key zyz@slave2:/home/zyz/.ssh/
八、启动hadoop
1、格式化
$>hdfs namenode -format #第一次启动需要格式化
2、启动
$>start-all.sh #相当于start-hdfs.sh和start-yarn.sh
3、查看进程
(1)查看master进程
$>jps #正确的进程有:Jps、NameNode、SecondaryNameNode、ResourceManager
(2)slave1、slav2进程
$>ssh slave1 #正确的进程有:Jps、DataNode、NodeManager
$>jps
$>exit #退出slave1
$>ssh slave2 #正确的进程有:Jps、DataNode、NodeManager
$>jps
$>exit #退出slave2
4、webUI查看集群
#提示:可在master桌面系统中,打开firefox浏览器。
(1)查看集群
http://10.10.0.100:50070 #50070是namenode默认的端口号
(2)查看MapReduce运行
http://10.10.0.100:8088 #8088是ResourceManager默认的端口号
5、测试集群,跑wordcount程序
(1)在hdfs上新建目录
$>hdfs dfs -mkdir -p /input/wordcount #输入目录
$>hdfs dfs -mkdir -p /output/wordcount #输出目录
(2)新建2个文本文件txt1、txt2并上传入hdfs,作为运行所需要的数据
$>cd /tmp
$>echo hello world hello hadoop >txt1
$>echo world hive hello hadoop >txt2
$>hdfs dfs -put /tmp/txt* /input/wordcount
(3)运行hadoop自带的wordcount程序
$>hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar /input/wordcount /output/wordcount
(4)观察结果
$>hdfs dfs -ls -R output/wordcount #R表示递归查看
----------------以上为hadoop完全分布式的安装-----------------
安装hive(采用外模式)
1、安装mysql
(1)安装mysql
$>apt install mysql-server
(2)添加用户
a.创建用户
msql>create user zyz@localhost identified by '123';
b.授予zyz用户访问hive数据库的所有权限
mysql>grant all privileges on hive to zyz@localhost identified by '123';
#如果行不通
mysql>grant all on *.* to zyz@localhost identified by '123' #授予zyz用户所有数据库的一切权限
c.刷新权限
mysql>flush privileges;
d.查询是否具有权限
mysql>use mysql;
mysql>select * from user where user='zyz' \G;
(3)本地登录测试
$>mysql -u zyz -p123
(4)创建hive数据库
mysql>create database hive;
2、安装hive
(1)安装
$>tar -zxvf /mnt/hgfs/apache-hive-2.1.0-bin.tar.gz -C ~/app
$>mv apache-hive-2.1.0-bin hive #更名
(2)配置环境变量
$>nano ~/.bashrc
[~/.bashrc]
export JAVA_HOME=/home/zyz/app/jdk
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export HADOOP_HOME=/home/zyz/app/hadoop
export HIVE_HOME=/home/zyz/app/hive
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH
$>source .bashrc
(3)配置hive-env.sh
$>cd ~/app/hive/conf
$>cp hive-env.sh.template hive-env.sh
$>nano hive-env.sh
HADOOP_HOME=/home/zyz/app/hadoop
(4)配置hive-site.xml
$>cd ~/app/hive/conf
$>cp hive-site.xml.template hive-site.xml
$>nano hive-site.xml
<property>
<name>hive.querylog.location</name>
<value>/home/zyz/app/hive/tmp</value> <!--事先建好tmp目录-->
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/zyz/app/hive/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/zyz/app/hive/tmp</value>
</property>
<!-- mysql驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- mysql连接url-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<!-- 用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>zyz</value>
</property>
<!-- 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
(5)初始化mysql数据库
cd ~/app/hive/bin
schematool -initSchema -dbType mysql
(6)运行hive
$HADOOP_HOME/sbin/start-all.sh //先启动hadoop
$HIVE_HOME/bin/hive //启动hive
hive>!clear; #hive提示符状态也可调用linux命令,在linux命令前加"!"
使用hiveserver2连接hive
1、下载并复制jdbc的连接jar包
如:mysql-connector-java-5.1.47.jar,将其复制$HIVE_HOME/lib中
2、修改core-site.xml
hive2新加了权限,需修改hadoop的配置文件
[$HADOOP_HOME/etc/hadoop/core-site.xml]
<property>
<name>hadoop.proxyuser.zyz.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.zyz.groups</name>
<value>*</value>
</property>
#说明:zyz是操作hadoop的用户
主要原因是hadoop引入了一个安全伪装机制,使得hadoop 不允许上层系统直接将实际用户传递到hadoop层,而是将实际用户传递给一个超级代理,由此代理在hadoop上执行操作,避免任意客户端随意操作hadoop
3、启动hiveserver2
(1)启动
$>$HIVE_HOME/bin/hiveserver2 & //在后台运行
$>jobs //查看作业
$>netstat -ano | grep 10000 //hiveserver2的端口为10000
说明:若要停止hiveserver2,可使用命令:hiveserver2 stop。若还不行,则杀死进程:kill -9 <pid>
(2)使用beeline连接hiveserver2
$>beeline -u jdbc:hive2://localhost:10000/mydb -n hadoop -phadoop
说明:$HIVE_HOME/lib下需要hive-jdbc-2.1.0-standalone.jar
(3)使用java连接hive
URL:jdbc:hive2://localhost:10000/mydb
user:zyz
password:123

 浙公网安备 33010602011771号
浙公网安备 33010602011771号