个人第一次编程作业
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 论文查重算法设计+学习PSP表格+单元测试+JProfiler性能分析+Git管理 |
1 代码链接(Java)
1.1 Github链接
1.2 可运行的jar包已经发布至仓库的release包内
2 计算模块接口的设计与实现过程
2.1 主要的类
-
IoProcess类:进行文本输入输出的操作,文本和字符串的相互转换
-
MyApplication类:主程序
-
MyApplicationTest类:对程序进行单元测试
-
MySimHash类(关键类):对字符串进行分词、获取哈希值、加权、合并、降维操作,并计算两字符串的海明距离,计算相似度
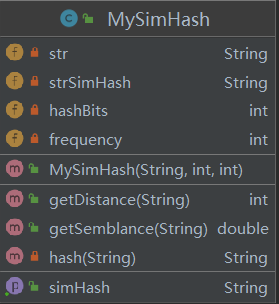
2.2 关键类的关键函数
2.2.1 getSimHash()
-
分词:调用HanLp包,对全部字符串进行分词
-
获取哈希值:调用hash(),获取每个词的哈希值,256bits
-
加权和合并:根据词语的索引进行加权,例如 0~9 的权重为10/-10, 10~19的权重为9/-9,依次递减,并将相同索引的hash值通过相加进行合并
-
降维:对每个索引的哈希值大于0的置为1,小于0的置为0
2.2.2 例子
-
分词,我们假设权重分为5个级别(1~5)。比如:“今天是星期天,天气晴,今天晚上我要去看电影 ” ==> 分词后为 “ 今天/ 是/星期/天/天气/晴/晚上/我/要去/看电影“,分词。
-
hash,通过hash算法把每个词变成hash值,比如“今天”通过hash算法计算为 110101(算法中是设置了196bit的值),“是”通过gethash算法计算为 101011。这样我们的字符串就变成了一串串数字。
-
加权,通过 2步骤的hash生成结果,需要按照单词的权重(单词权重按照先后顺序划分,上面有说过)形成加权数字串,比如“今天”的hash值为“110101”,通过加权计算为“10 10 -10 10 -10 10”;“是”的hash值为“101011”,通过加权计算为 “ 9 -9 9 -9 9 9”。
-
合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。“10+9 10-9 -10+9 10-9 -10+9 10+9”,这里为了方便,没有将所有的都写出来,实际上是将所有的进行相加。
-
降维,把4步算出来的 “19 1 -1 1 -1 19” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 1 0 1 0 1”。
2.2.3 getSembalance()
对比两个哈希值相同索引,如果不同,海明距离加1,最后计算相似度,保留两位小数
2.3 算法的关键以及独到之处
2.3.1 介绍
运用simHash,而不是直接运用Hash,simhash一种局部敏感的hash值,本文主要目的是为比较两文本的相似度,如果使用传统的hash,无法实现目的。
2.3.2 例子
“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
-
1000010010101101111111100000101011010001001111100001001011001011
-
1000010010101101011111100000101011010001001111100001101010001011
通过传统hash计算为:
-
0001000001100110100111011011110
-
1010010001111111110010110011101
可见,simhash变化的只有很小一部分,而hash值发生了很大改变,因此不能用传统的hash
2.4 分包截图
2.5 实际命令行运行效果

3 计算模块接口部分的性能改进
执行单元测试,对各种情况使用JProfiler对性能进行监控
3.1 类的占用情况
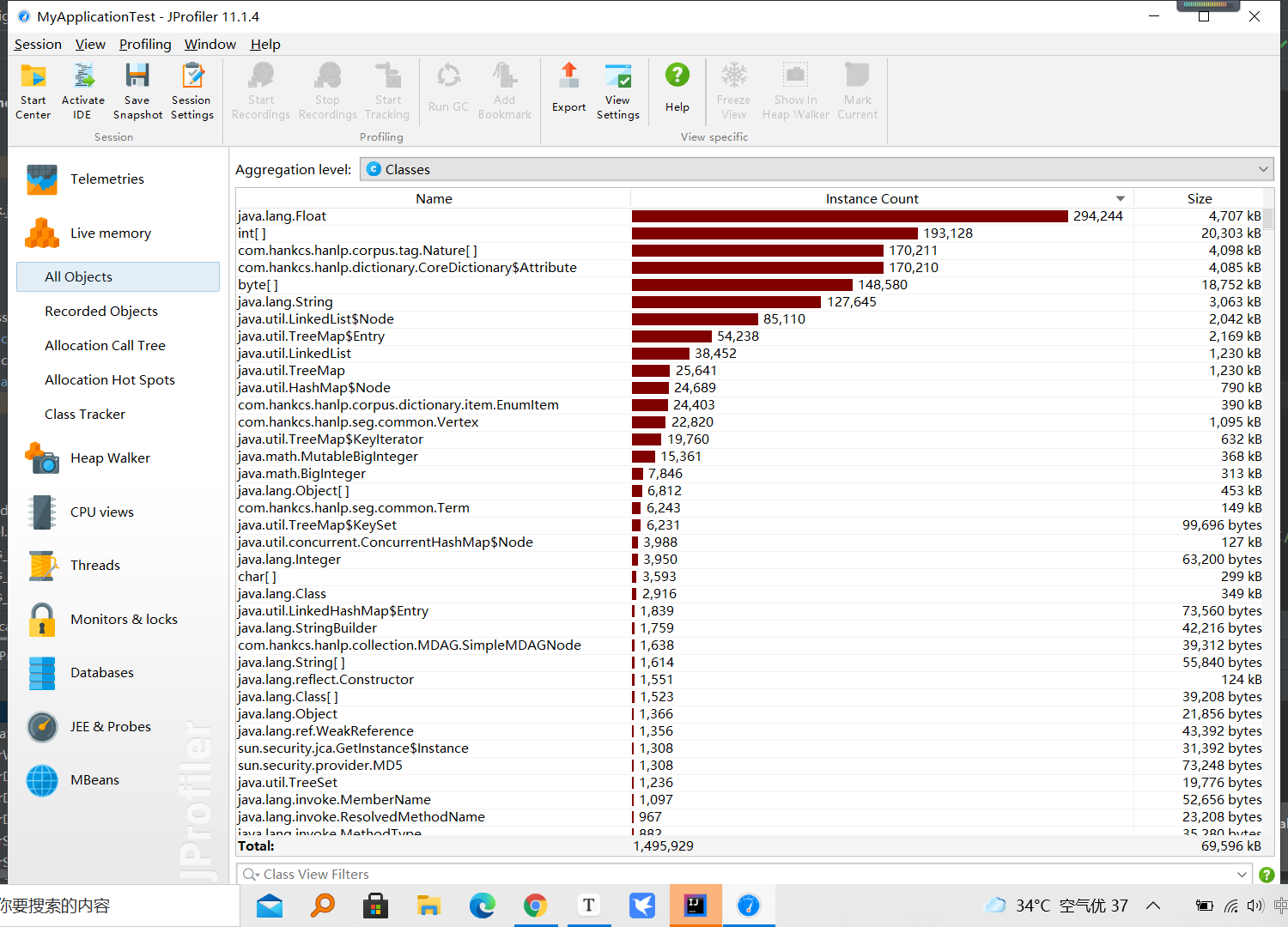
3.2 CPU Load

3.3堆内存情况
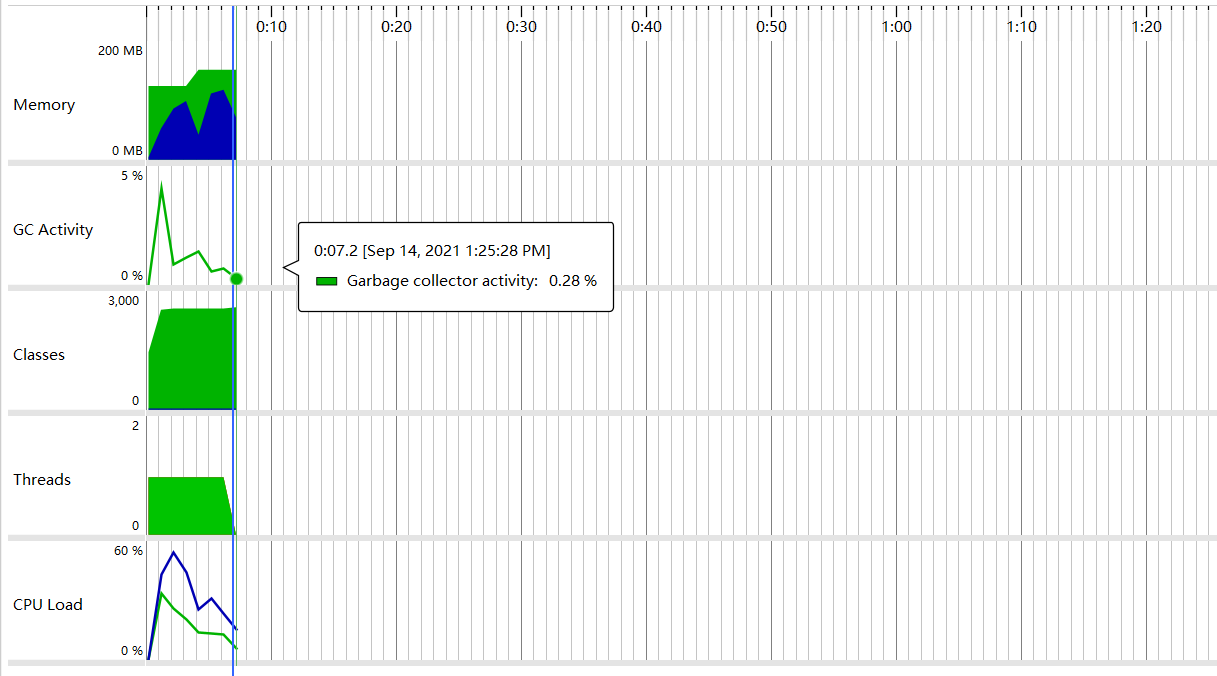
3.4 耗时操作
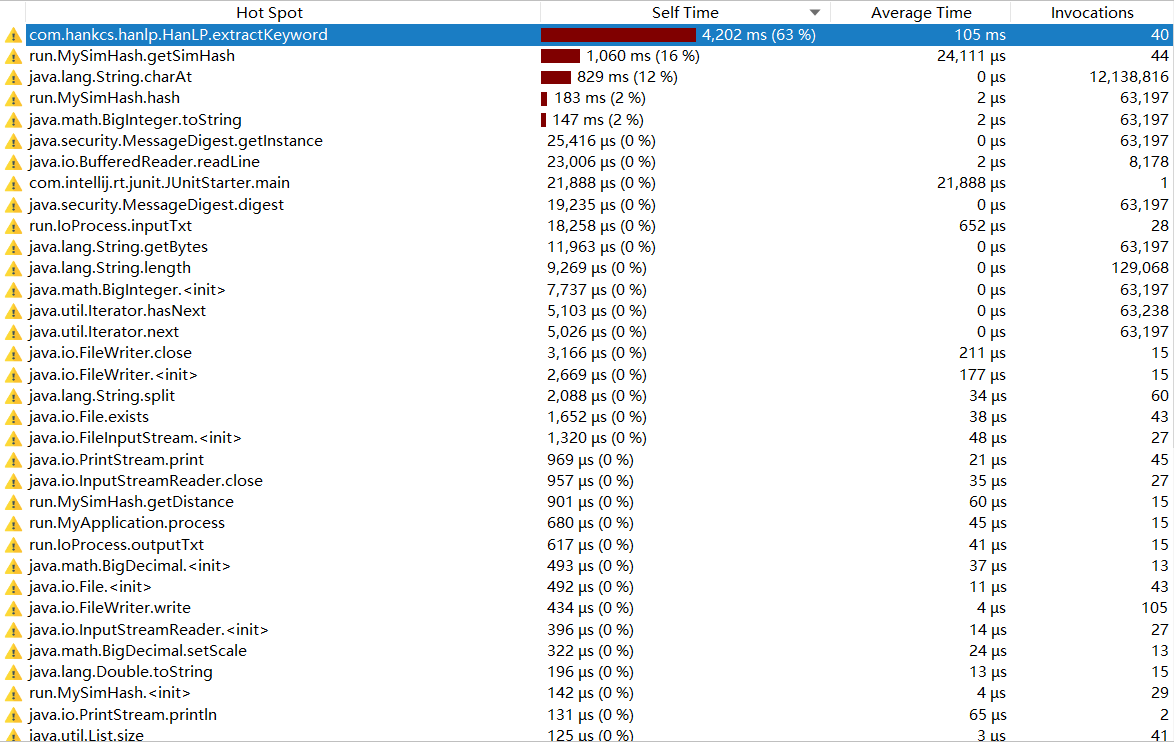
可见,耗时最多的是hanlp分词操作,因此性能瓶颈在于Hanlp分词操作函数,所以我并没有对其他地方进行改动来提升程序的性能
4 计算模块部分单元测试展示
4.1 采用白盒测试,对原文件改进,空文件、添加、删除、错别字,打乱等测试
单元测试代码如下
/**
*Test 1:test the empty txtFile
*/
@Test
public void testForEmpty(){
try {
MyApplication.process("test/orig.txt", "test/empty.txt", "test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
Assert.fail();
}
}
/**
* Test 3:Test 20% text addition: orig_0.8_add.txt
*/
@Test
public void testForAdd(){
try { MyApplication.process("test/orig.txt","test/orig_0.8_add.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
Assert.fail();
}
}
/**
* Test 4:Test 20% text deletion: orig_0.8_del.txt
*/
@Test
public void testForDel(){
try {
MyApplication.process("test/orig.txt","test/orig_0.8_del.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
/**
* Test 5:Test 20% out-of-order text: orig_0.8_dis_1.txt
*/
@Test
public void testForDis1(){
try {
MyApplication.process("test/orig.txt","test/orig_0.8_dis_1.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
/**
* Test 6:Test 20% out-of-order text: orig_0.8_dis_10.txt
*/
@Test
public void testForDis10(){
try { MyApplication.process("test/orig.txt","test/orig_0.8_dis_10.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
/**
* Test 7:Test 20% out-of-order text: orig_0.8_dis_15.txt
*/
@Test
public void testForDis15(){
try {
MyApplication.process("test/orig.txt","test/orig_0.8_dis_15.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
/**
* Test 8:Test the same text: orig.txt
*/
@Test
public void testForSame(){
try {
MyApplication.process("test/orig.txt","test/orig.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
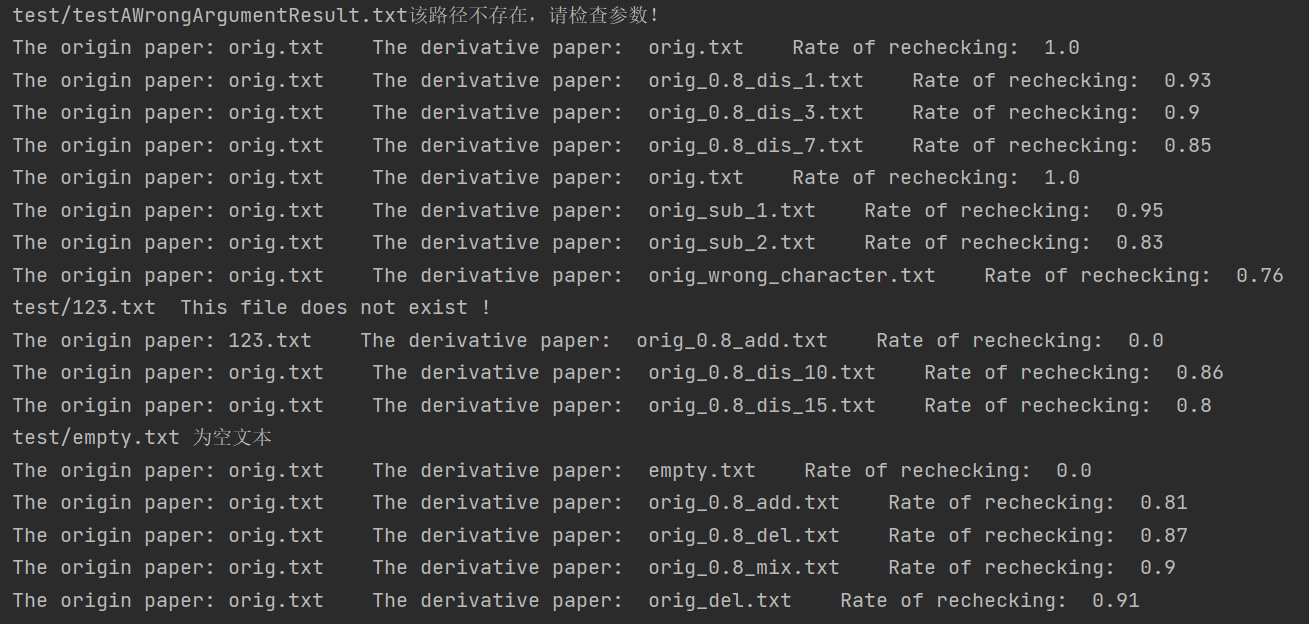
4.2 测试结果
4.3 代码覆盖率

5 计算模块部分异常处理说明
5.1 测试文件输入参数出错的情况
代码如下(只展示部分代码):
/**
*Test 2:The case where the entered comparison text path parameter is an incorrect parameter
*/
public void testForWrongOriginArgument(){
try {
MyApplication.process("test/123.txt","test/orig_0.8_add.txt","test/ansAll.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
测试结果:

5.2 测试文件输出参数出错的情况
代码如下(只展示部分代码):
/**
*Test14: Test if the output file path parameter is an error parameter
*/
@Test
public void testForWrongOutputArgument(){
try {
MyApplication.process("test/orig.txt","test/orig.txt","test/testAWrongArgumentResult.txt");
}
catch (Exception e) {
e.printStackTrace();
}
}
测试结果:

5.3 测试文件为空的情况
代码如下(只展示部分代码):
/**
* Test 1:test the empty txtFile
*/
@Test
public void testForEmpty(){
try {
MyApplication.process("test/orig.txt", "test/empty.txt", "test/ansAll.txt");
} catch (Exception e) {
e.printStackTrace();
Assert.fail();
}
}
测试结果:

6 PSP表格
| PSP2.1 | Personal Software Process Stage | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| Estimate | 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 600 | 600 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 300 |
| Design Spec | 生成设计文档 | 70 | 60 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 60 | 70 |
| Coding | 具体编码 | 200 | 240 |
| Code Review | 代码复审 | 40 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 160 | 180 |
| Test Repor | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 40 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1910 | 2110 | |
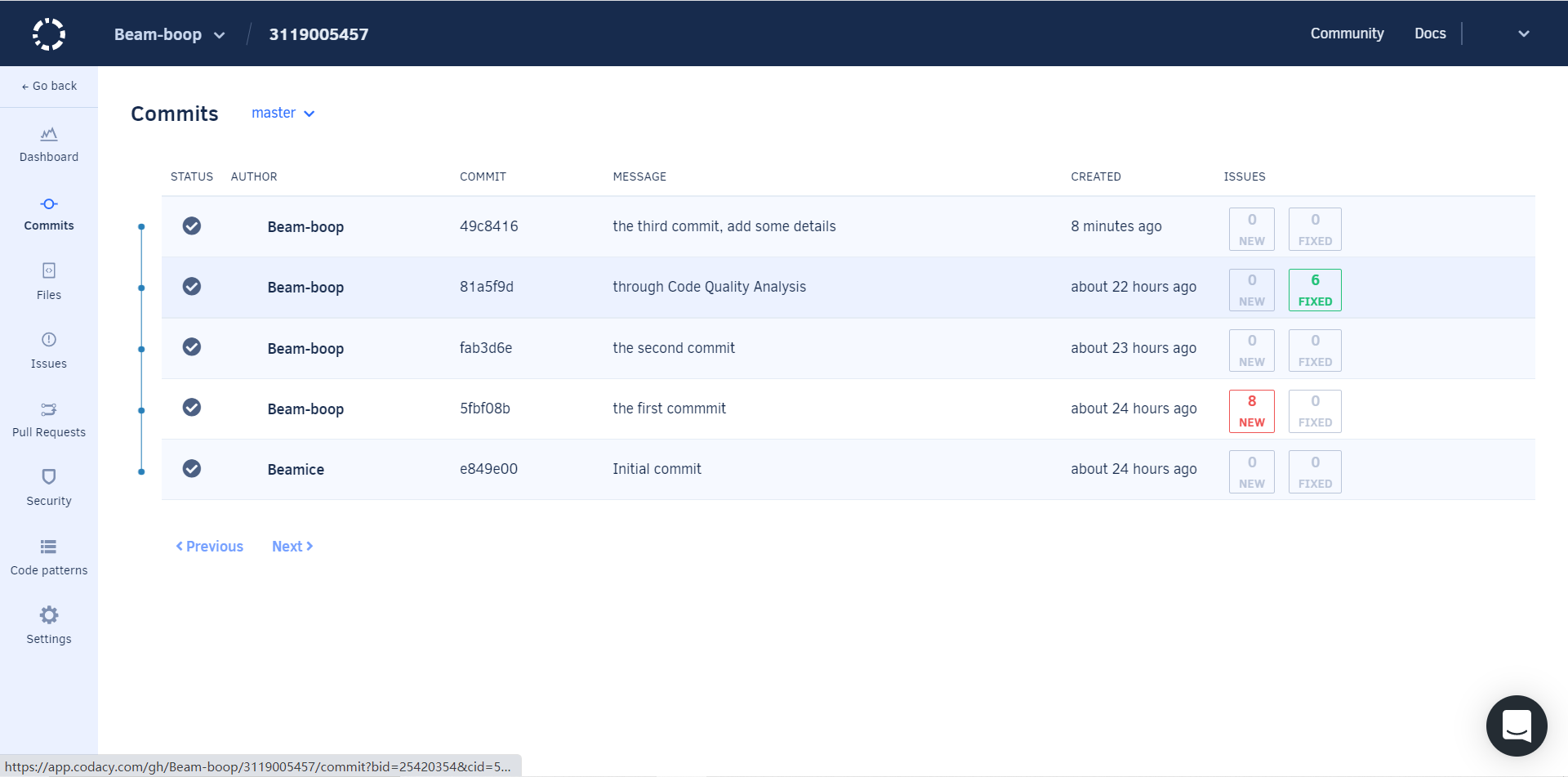
7 代码质量检查Code Quantity Analysis
代码质量检查,用的是codacy,主要问题出现在类名和方法名的命名上,复习了正确的命名方式
对于类名,大驼峰式,符合正则表达式:[A-Z]a-zA-Z0-9
对于方法名,小驼峰式,符合正则表达式:[a-z]a-zA-Z0-9
8 总结
- 因为本人没有完全写过一个类似于这种的开发程序,所以耗时比较久,主要耗时在于Git和Github的学习上,如何将本地文件上传到仓库上;
- 耗时比较多的地方还有对于jar包的打包上,因为没有将Maven等依赖包一起打包进去,所以导致出现错误,最后询问了朋友才解决了问题;
- 以及之前没有接触过的codacy、Jprofiler和单元测试,所以学习新的工具也需要一定的时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号