你的sql查询为什么这么慢?
做后台开发的程序猿通常需要写各种各样的sql,可很多时候写出来的sql虽然能满足功能性需求,性能上却不尽人意。如果业务复杂,表结构和索引设计又不合理的话,写出来的sql执行时间可能会达到几十甚至上百秒,对于生产环境来说,这是相当恐怖的一件事。因此,了解一些常见的mysql优化技巧很有必要。本文将从表结构和索引设计,sql执行原理,sql编写优化3方面进行分析和讲解,希望能对大家有所帮助。
1、表结构,字段设计是否合理?
这是最基础也是最容易忽视的一个环节。良好的表结构设计是sql优化的基础,在这个存储廉价,空间足够的时代,设计表的过程中,不一定要完全满足范式理论,我们可以通过适当的冗余设计,避免连表查询,达到以空间来换取时间的目的。设计表的时候,我们会根据业务需求来决定建几个表,表之间通过哪些外键来关联。而且通常需要考虑到数据规模(单表记录数最好不要超过千万,如果超过可能需要分表分区,包括垂直分表和水平分表)、查询更新频率(哪些字段经常用于查询,哪些经常用于更新),各字段的类型和长度取值,在哪些字段上建哪种类型的索引等等。
比方说,如果你是innodb存储引擎,那么你的主键最好设计成自增的,这样效率最高。因为innodb存储引擎的索引是基于B+树实现,如果采用自增设计,就能快速找到插入节点的位置进行插入或删除,对其他节点影响较小,避免频繁分裂树结构。有的公司设计表的时候喜欢采用UUID的方式来作为主键,这样的好处是数据迁移的时候,主键不会变,能找到对应关系,但是会有2个问题:1、UUID的长度是36位,占用字节较长,尤其对于innoDB来说,建立辅助索引的时候,辅助索引里存储的都是主键的值,这会导致辅助索引占据空间变大。2、UUID是无序的,每次插入或者删除一条记录的时候,为了维持索引的特性,可能会导致节点频繁分裂,这样非常影响效率。
在设计字段的时候,尽量采用整形的,比如用tinyint 代替char(1),这样便于存储和计算。在满足业务的前提下,长度越短越好,如果有大对象,比如text或blob类型的字段,并且这些字段查询频率较低时,可以考虑拆表来单独存储(也就是垂直分表),避免对主表造成影响。此外,设计表的时候,最好设计为not null,因为允许为null时,mysql还需要有个字节来标识是否是null,而且mysql索引无法存储null,如果在一列允许null 的索引中使用where colum is null,那么mysql是不会走索引的。那如果有的字段就是没值怎么办?可以用空字符串或者0这些代替。
2、sql执行原理
写好了sql后,sql是怎么执行的呢?当我们运行sql的时候,会经历客户端发送请求,服务端接受请求并解析sql,生成sql执行计划,执行并将结果返回给客户端这些过程。要优化sql,首先要知道sql到底在哪些环节花了多长时间。这里不去分析网络因素对sql造成的影响,我们只需关注sql生成的执行计划,这个执行计划能很大程度上帮助我们找到优化sql的方向。那怎么看sql的执行计划呢?explain 你的sql。比如在mysql 5.6自带的sakila数据库上执行如下sql:

可以看到有id,select_type,partitions,type,possible_keys等等内容。首先说一下,比较重要的有id,select_type,type(相当重要),key(相当重要),key_len(可能重要),extra(相当重要)这几列。其他的列就不介绍了。这些内容都代表什么意义呢?
id通常表示执行顺序,比如有3行,id分别为1,1,2,那么执行顺序就是1,1,2,通常id的个数对应select的个数。
select_type表示查询类型,主要有以下几种:
SIMPLE:简单SELECT(不使用UNION或子查询等)
PRIMARY:最外面的SELECT
UNION:UNION中的第二个或后面的SELECT语句
DEPENDENT UNION:UNION中的第二个或后面的SELECT语句,取决于外面的查询
UNION RESULT:UNION的结果。
SUBQUERY:子查询中的第一个SELECT
DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询
DERIVED:导出表的SELECT(FROM子句的子查询)
type:表示使用了哪种类别的连接,有无使用索引,是使用Explain命令分析性能瓶颈的关键项之一,性能由好到坏依次为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
key:表示使用的索引,如果没有选择索引,则为NULL。
key_len:表示索引长度,对于单列索引,该值意义不大,对于联合索引,则有重要作用,key_len的大小显示了联合索引中真正用到的哪几列,如果是联合索引,则该值越大表示走的索引列越多,查询效率越高,这里涉及到索引前缀的知识,该部分后面有空再讲。对于该列的值,也有计算公式:如果是单列索引,则key_len=索引列的长度*字符编码占用的字节数(UTF8编码为3字节,GBK为2字节,latin为1字节)+标识是否允许null的字节数(1字节)+内容长度(针对可变长列,1字节),举个例子:
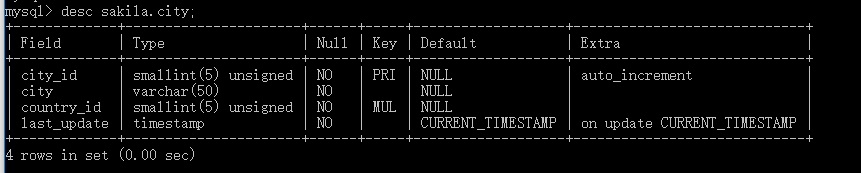
该表中,city_id是主键,city字段是varchar类型,长度为50,默认为null,执行explain select city from sakila.city,如下:

可以发现,这里走了覆盖索引,顺便提下,覆盖索引就是sql的查询内容通过走sql索引就能查到,这种情况就是覆盖索引,所以这里我们看到,即使我们不加where条件也能走索引。索引列是city_name,key_len为152,怎么来的呢?对照上面的公式:50长度*3(UTF8编码一个字符3个字节)+1(标识是否为null)+1(标识内容的长度),这样是不是很清晰了?
最后这列Extra:包含MySQL解决查询的详细信息,也是关键参考项之一。当这列出现了Using filesort(出现这种情况九死一生,很有必要优化)和Using temporary(这里就是十死0生了,必须优化!)就需要格外注意了。
3、优化你的sql
当完成了上面2步以后,如果发现你的sql很慢,这时候就必须对我们的sql进行优化了。2个大的思路是先问问自己:是否建了索引?索引建的是否合适?当我们分析一条sql慢的时候,我们需要考虑,这条sql查询的内容是否建了索引呢?如果没有,那要在哪列建哪种索引呢?比如我们要从用户表(>100W条记录)中根据姓名查某个用户,如果没有建索引,显然会很慢,那么怎么建索引呢?你可能会说很简单嘛,就在姓名上建个索引不就完了嘛。那假如(只是假如)姓名这列里,100W个用户中,有50W个叫张三的,20W个叫李四的,30W个王五的,你在这里建合适吗?显然不合适,或者说,仅仅对这列建单列索引不合适,因为选择性太差。而且这会导致个问题,当sql存储引擎发现走全表扫描比走索引更快的时候,它会放弃走索引,直接扫表。这里有个最重要的关键词:选择性,选择性可以理解为:该表中该列的不重复数/总记录数,该比值在0-1之间,越接近1说明选择性越好,唯一索引的选择性就是1,因此唯一索引是性能最好的索引。像上面用户表中,该表的选择性我们可以这么查:select count(distinct name)/count(*) from customer;因此我们要做的,就是想办法提高索引的选择性,可以采用建联合索引,或者部分索引(就是取该列的N个字符来建索引,但是这种索引不能用于group by中)等等,遵循这个思路,我们就明白,有的开发员在性别列建索引,其实并不是一个好选择,因为选择性太差。要建高效的索引,就一定是选择性好的索引。
端午假期第一天,上午看了会世界杯,下午闲的无聊写了这篇博客,欢迎拍砖交流,转载请务必注明出处,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号