

python面向对象(九、内置的包和模块)
12.模块和包
12.3 python内置的包和模块
12.3.1 collections
12.3.1.1 Iterable和Iterator
Iterable和Iterator都是collections包中的工具
1)Iterable判断是否可迭代;
2)Iterator 判断是不是迭代器
参考:判定迭代器和可迭代对象Iterator、Iterable
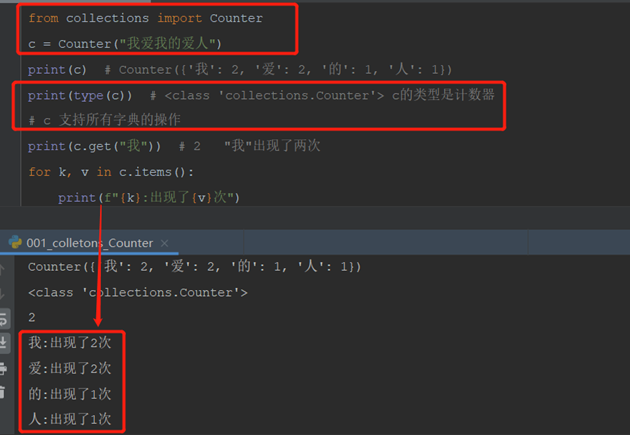
12.3.1.2 Counter 计数器:
统计数据重复出现次数,被统计对象必须是可迭代的
1)统计字符串中字符重复出现次数
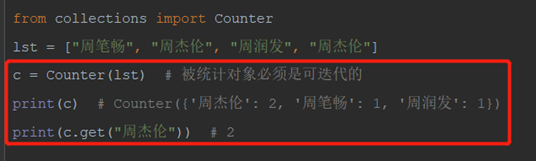
2)统计列表中数据重复出现次数
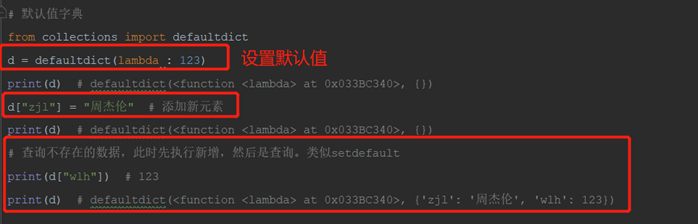
12.3.1.3 defaultdict默认值字典
12.3.1.4 deque 双向队列
1)stack 栈
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈、退栈或弹栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
栈的特点:先进后出(FILO:first in last out)
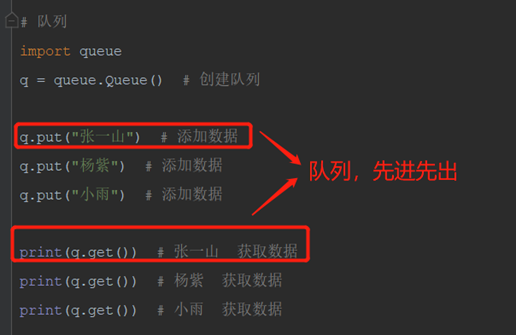
2)queue 队列(先进先出:FIFO)
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头
队列的特点:先进先出
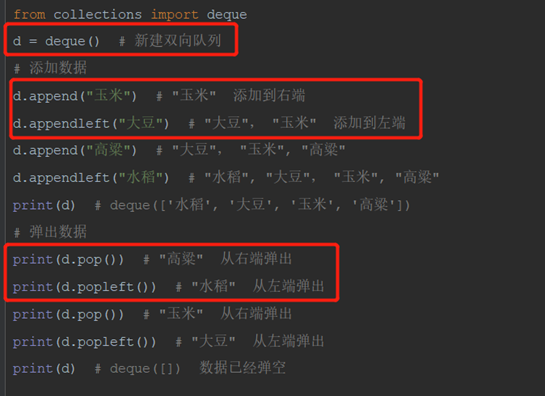
3)deque 双向队列
双向队列(deque,全名double-ended queue),双向队列中的元素可以从两端弹出,其限定插入和删除操作在队列的两端进行。双端队列可以在队列任意一端入队和出队。
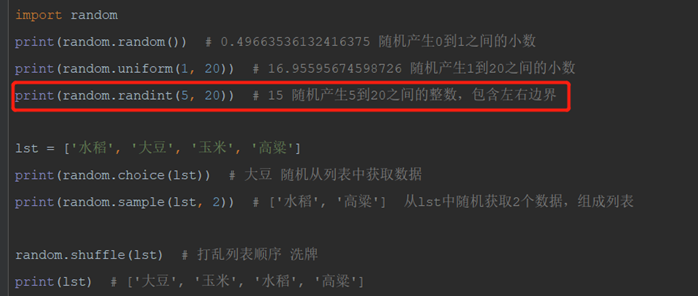
12.3.2 random 随机数
12.3.3 time模块
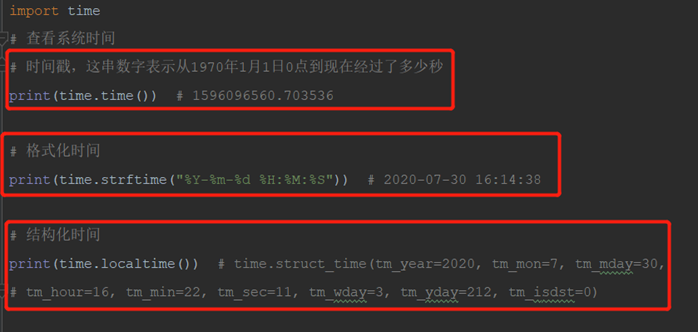
1)time模块中时间表现的格式主要有三种:
(1)timestamp时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。北京时间的时间戳是从1970年1月1日08:00:00开始。
(2)struct_time时间元组,共有九个元素组。
(3)format time 格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
2)python中时间日期格式化符号:
最常用的格式:%Y-%m-%d %H:%M:%S
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
3)时间格式转换图
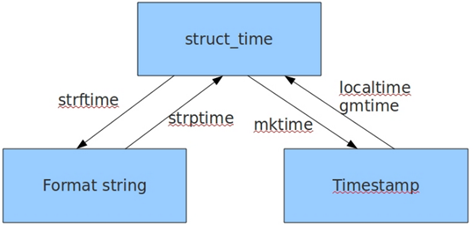
(1)时间戳转化为格式化时间(格式化时间方便阅读)
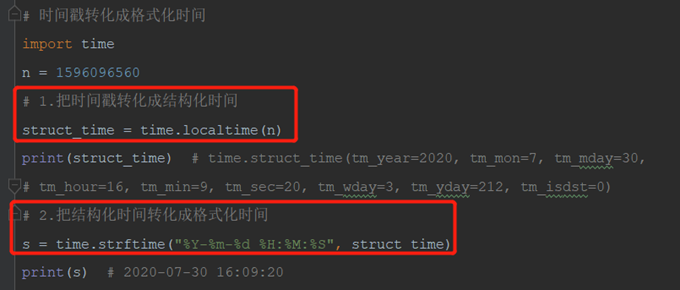
(2)格式化时间转化为时间戳(时间戳便于存储)
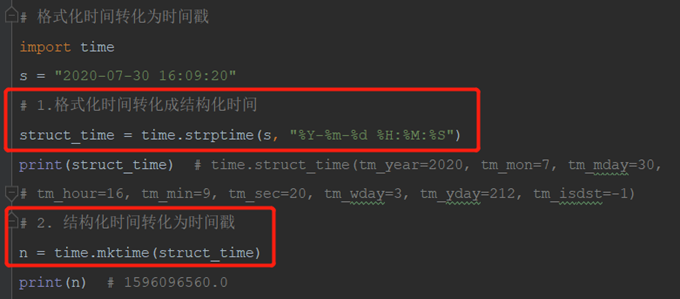
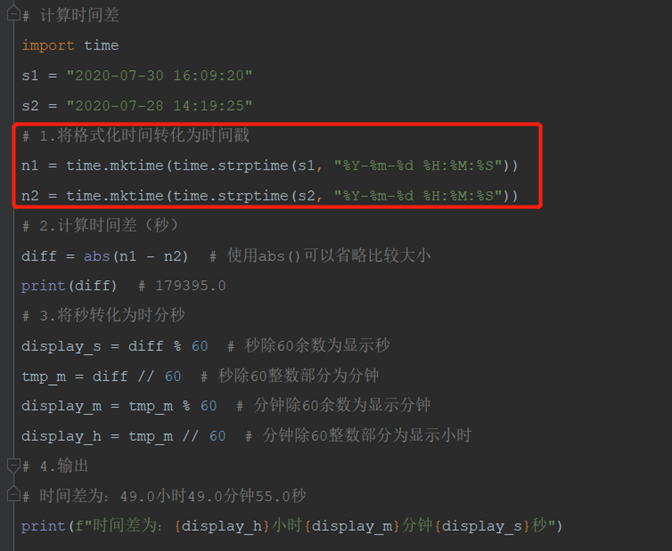
(3)计算时间差
12.3.4 pickle 序列化模块
把一个对象转化成bytes的过程被称为序列化
把bytes转化回对象的过程称为反序列化
1)数据转化
pickle可以将python中几乎所有的数据类型(列表,字典,集合,类等)序列化

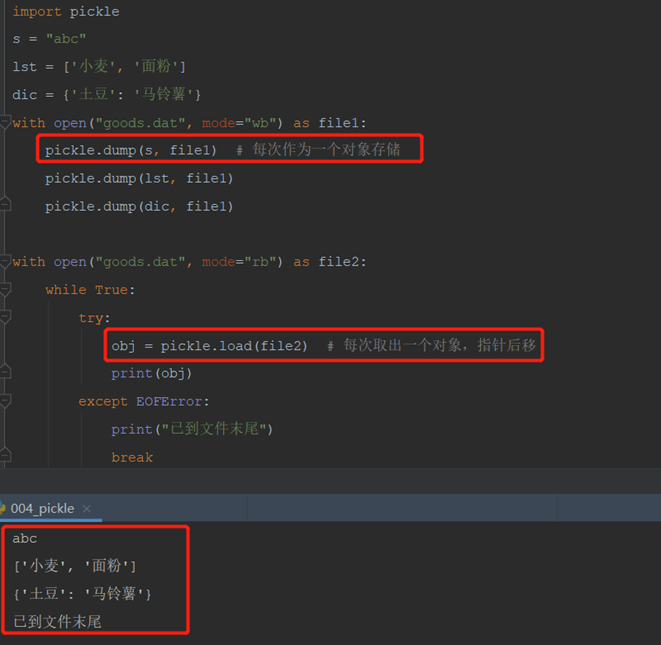
2)将二进制数据写入文件:
方法1:

方法2:
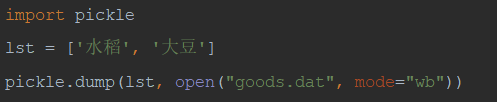
3)从二进制文件读取数据:

4)dump和load每次作为一个对象存储或取出,可以使用while取出所有数据
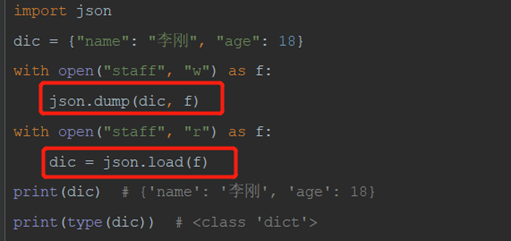
12.3.5 json模块(重点)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
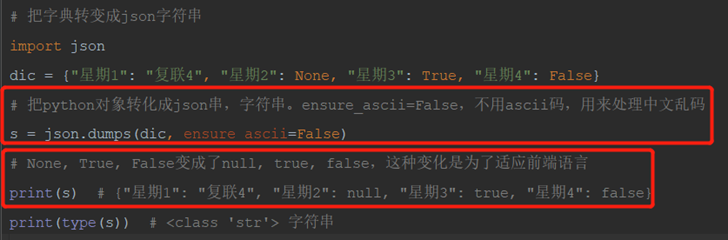
1)json.dumps把字典变成json字符串
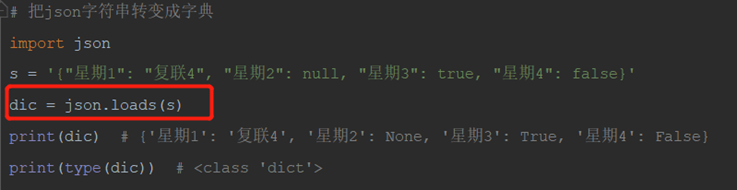
2)json.loads把json字符串,变成字典
3)dump和load
dump:将转化完成的json串写入文件
load:从文件中读取json串转化成字典
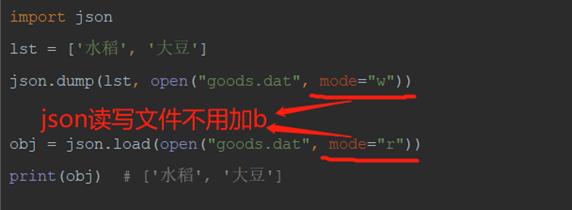
json经常用于存储字典数据
12.3.6 os模块 操作系统相关
1)os.makedirs('dirname/dirname') #可生成多层递规目录, 建议使用

2)os.mkdir('dirname') #生成目录

3)os.removedirs('dirname') #删除目录,若目录为空则删除,并递归到上一级目录,若也为空则删除,以此类推。

4)os.rmdir('dirname') #删除单级目录,建议使用

5)os.listdir('dirname') #返回指定目录下的所有文件和目录名

6)os.remove('filename') #删除一个文件
7)os.rename("oldname", "newname") #重命名文件
8)os.stat() #获取文件或者目录信息,很少使用


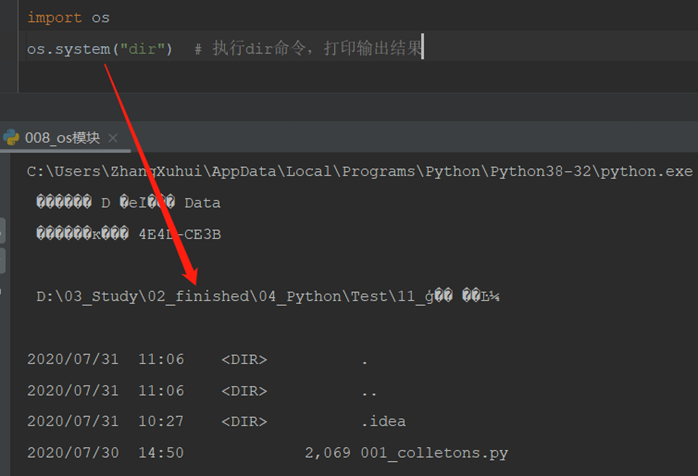
9)os.system()#运行shell命令,注意:这里是打开一个新的shell,运行命令,当命令结束后,关闭shell。中文操作系统使用GBK码,pycharm使用utf-8码,所以中文显示乱码
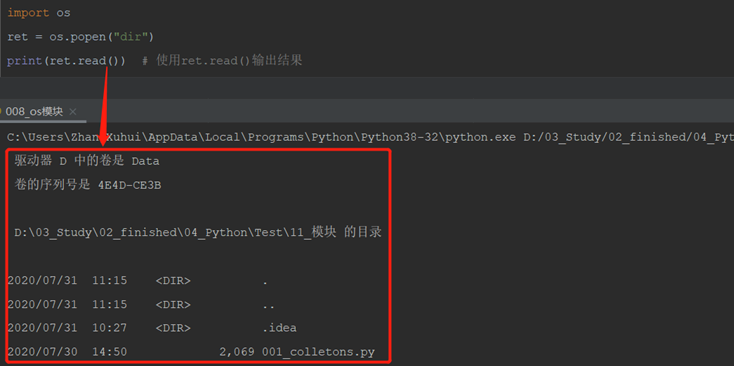
10)os.popen() # 运行shell命令,返回输出结果。支持中文显示
使用ret.read()输出结果
11)os.getcwd() #获取当前python脚本工作路径

12)os.chdir() #改变当前脚本工作路径,相当于shell下的cd
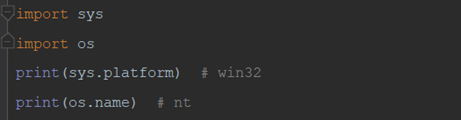
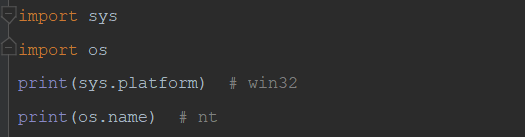
13)os.name #显示当前使用的平台,
'nt'表示Windows,'posix'表示Linux
14)os.sep #显示当前平台下路径分隔符
15)os.linesep #给出当前平台使用的行终止符
16)os.environ #获取系统环境变量
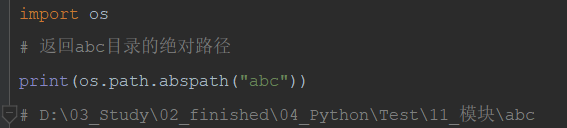
17)os.path.abspath(path) #相对路径转化绝对路径
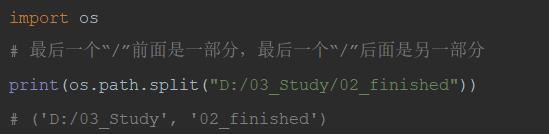
18)os.path.split(path) #将path分割成路径名和文件名。(事实上,如果你完全使用目录,它也会将最后一个目录作为文件名而分离,同时它不会判断文件或目录是否存在)。最后一个“/”前面是一部分,最后一个“/”后面是另一部分

19)os.path.dirname(path) #返回该路径的父目录,其实就是返回os.path.split(path)的第一个元素
20)os.path.basename(path) #返回该路径的最后一个目录或者文件,如果
path以/或\结尾,那么就会返回空值。其实就是返回os.path.split(path)的第二个元素
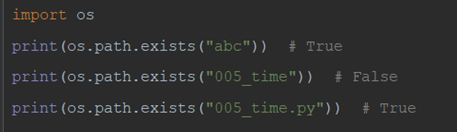
21)os.path.exists(path) #判断文件或文件夹是否,存在返回True,不存在返回False
22)os.path.isabs(path) #如果绝对路径,则返回True
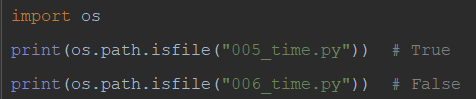
23)os.path.isfile(path) #如果path是一个存在的文件,则返回True
24)os.path.isdir(path) #如果path是一个存在的目录,则返回True
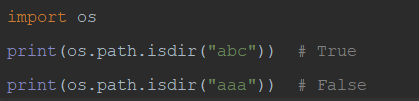
25)os.path.join(path,name) #连接目录与文件名或目录,结果为path/name。path可以输入一个或多个,linux的路径分隔符是“/”,windows的路径分隔符是“\”,两者不同,需要注意
26)os.path.getatime(path) # 返回path所指文件或目录的最后访问时间
27)os.path.getmtime(path) # 返回path所指文件或目录的最后修改时间
28)os.path.getsize(path) # 返回path所指文件或目录的大小

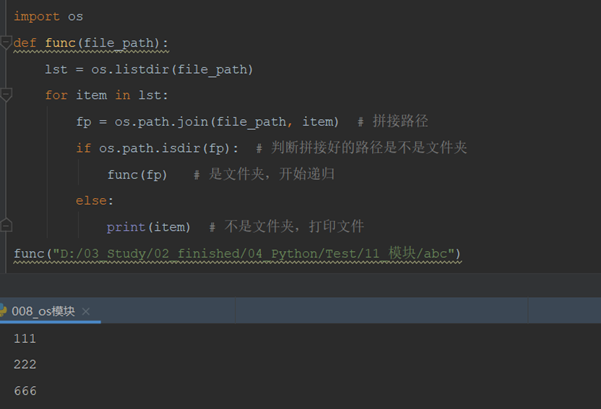
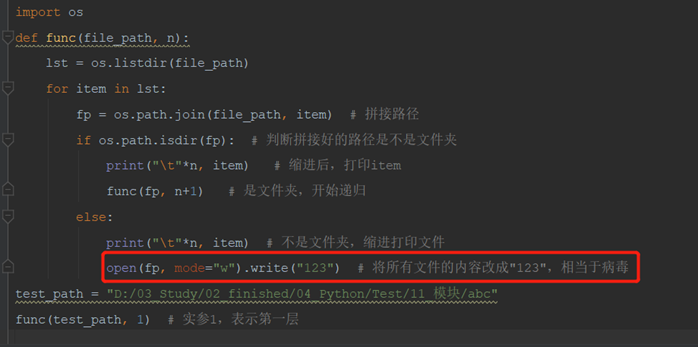
12.3.7 练习:递归打印文件名(树形结构的遍历)
需求:请列出某个文件夹内所有的文件名(包括子文件夹中的文件名)
改进版:深层文件缩进了
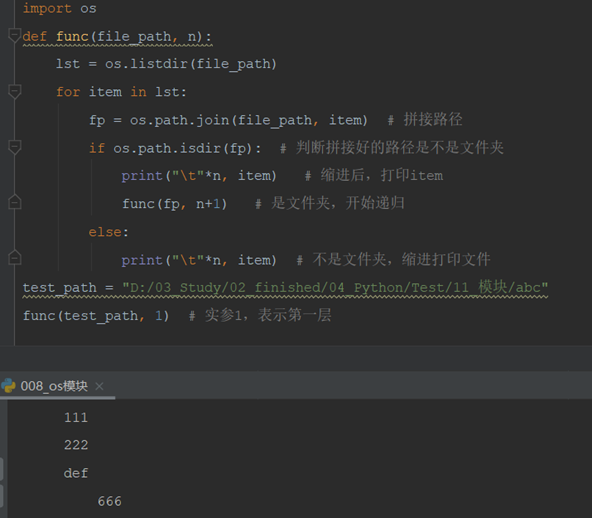
病毒版:
12.3.8 sys模块 解释器相关的操作
1)sys.argv 接收命令行参数
获取当前正在执行的命令行参数,返回参数列表(list)。
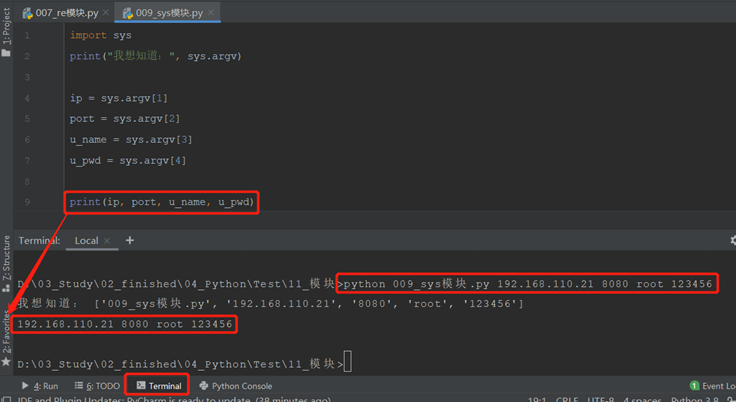
实际应用中可以根据获取到的命令行参数,执行相关操作
2)sys.exit(n) 退出程序,正常退出exit(0),错误退出sys.exit(1)
3)sys.version 获取Python解释程序的版本信息
4)sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
后期还要着重讲解:sys.path 模块搜索路径
5)sys.platform 返回操作系统平台名称
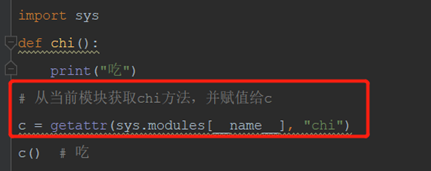
6)sys.modules
sys.modules是一个全局字典,字典sys.modules具有字典所拥有的一切方法,可以通过这些方法了解当前的环境加载了哪些模块。
sys.modules[name]返回当前模块名称
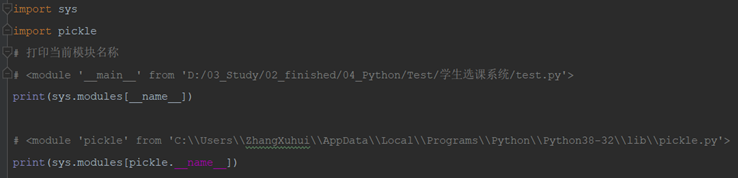
sys.modules[name]可以配合getattr使用获取当前模块或其他模块的方法和属性
12.3.9 re模块
re模块是python提供的一套关于处理正则表达式的模块。核心功能有四个:
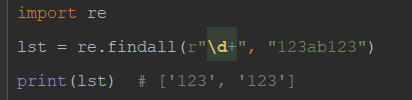
1)re.findall:返回列表,列表中包含所有匹配的结果
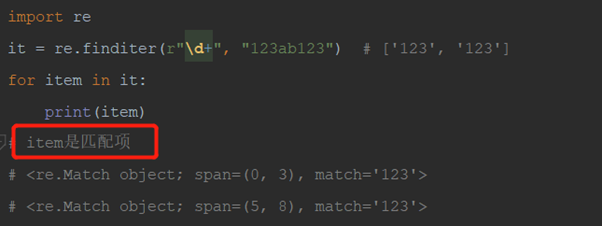
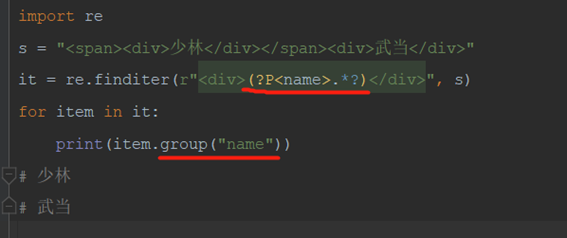
2)re.finditer: 返回匹配项迭代器,需要遍历获取
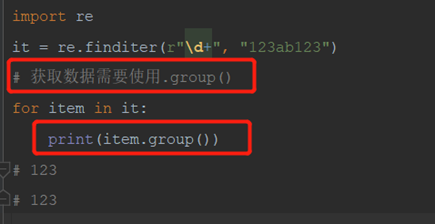
获取数据需要使用.group()
3)re.search返回满则正则表达式的第一个匹配项

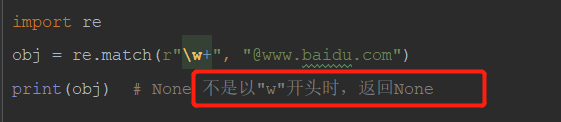
4)re.match() 从头匹配返回满则正则表达式的匹配项
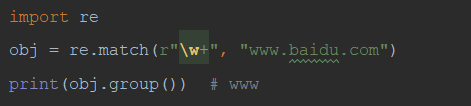
从头匹配,不满足时返回None
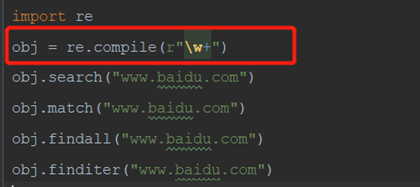
5)re.compile() 把正则加载到内存,可以重复使用
6)获取分组数据(重点)
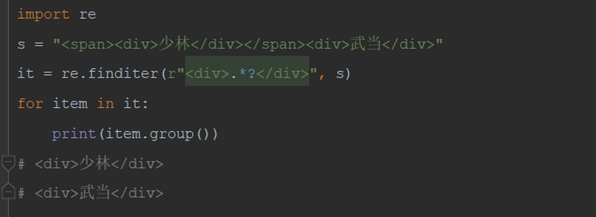
上面获取的数据有多余的
12.3.10 练习:爬虫网页
1)需求:
目标网站:https://www.piaohua.com/html/kongbu/2020/0803/43612.html
获取内容:片名、主演、下载地址
2)打开影片页面,右击页面,查看网页源代码?
源码中可以查看网页的编码方式

3)编写代码
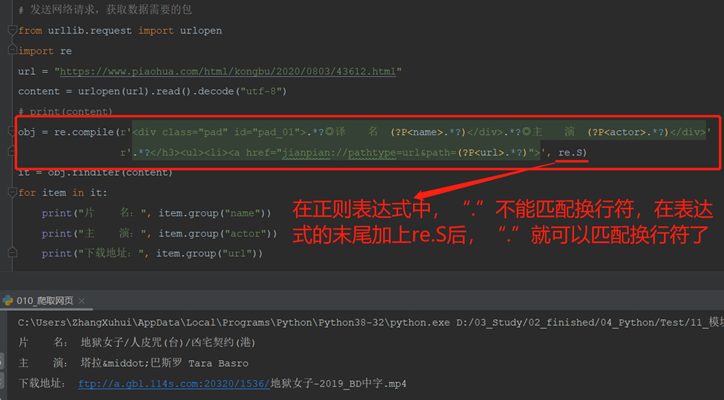
编写正则表达式:
(1)先找到离片名较近的id
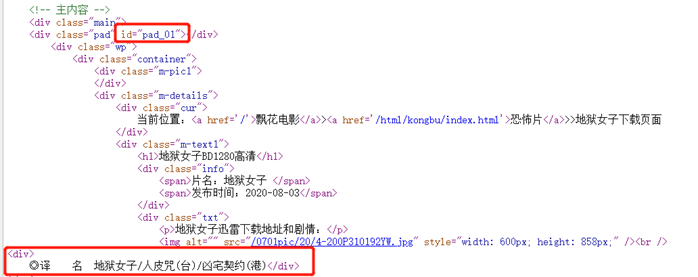
(2)用.?过滤掉中间的信息
(3)◎译 名:从前面最靠近需要的信息
(4)(?P
(5)
这样片名信息表达式就写好了:
