大数据超全面入门干货知识,看这一篇就够了!
随着科技的飞速发展和互联网的普及,大数据已成为 21 世纪最炙手可热的话题之一。它像一面神秘的面纱,覆盖着现实世界,隐藏着无穷无尽的可能性。今天将带领大家一起揭开大数据这个未知世界的神秘面纱,带你了解大数据的概念、应用以及大数据相关组件。
一、什么是大数据
大数据是指规模巨大、类型复杂且增长迅速的数据集合。这些数据无法通过传统的数据管理和处理工具进行捕捉、存储、管理和分析。
大数据的特点可以概括为“四V”:
Volume(大量):数据容量和复杂性使传统工具和技术已无法处理
Velocity(高速):增长速度快,处理速度快
Variety(多样性):人对人;人对机器;机器对机器
Value(价值):创造价值高,价值密度低
通过大数据分析,我们可以从海量的数据中挖掘出有价值的信息,为决策提供有力支持。
二、大数据的应用领域
商业智能和市场营销:企业可以通过大数据分析深入了解消费者需求和行为模式,从而制定更加精准的市场营销策略,提升产品和服务的竞争力。
健康医疗:利用大数据分析可以对医疗数据进行挖掘,辅助医生进行诊断和治疗,提高医疗效率和患者治愈率。
金融服务:银行和金融机构可以利用大数据分析进行风险评估、欺诈检测以及个性化推荐,提供更加安全和便捷的金融服务。
城市规划:城市可以通过大数据分析优化交通管理、资源配置和环境保护,提升城市的可持续发展和居民生活质量。
三、大数据相关组件介绍
在大数据的世界里,有许多神奇的组,它们像齐心协力的小伙伴,一起为我们揭开数据的奥秘。接下来让我们介绍一下这些组件吧!
3.1 Hadoop
Hadoop 就像一个超级大仓库,可以存放海量的数据,并帮助我们进行高效处理。它是一个开源的分布式计算框架,让数据分散储存在多台计算机上,然后使用 MapReduce 的方法,将数据分成小块一块一块地处理,最后把结果汇总起来。Hadoop 可以高效地处理大量的数据,让我们轻松面对海量信息的挑战。
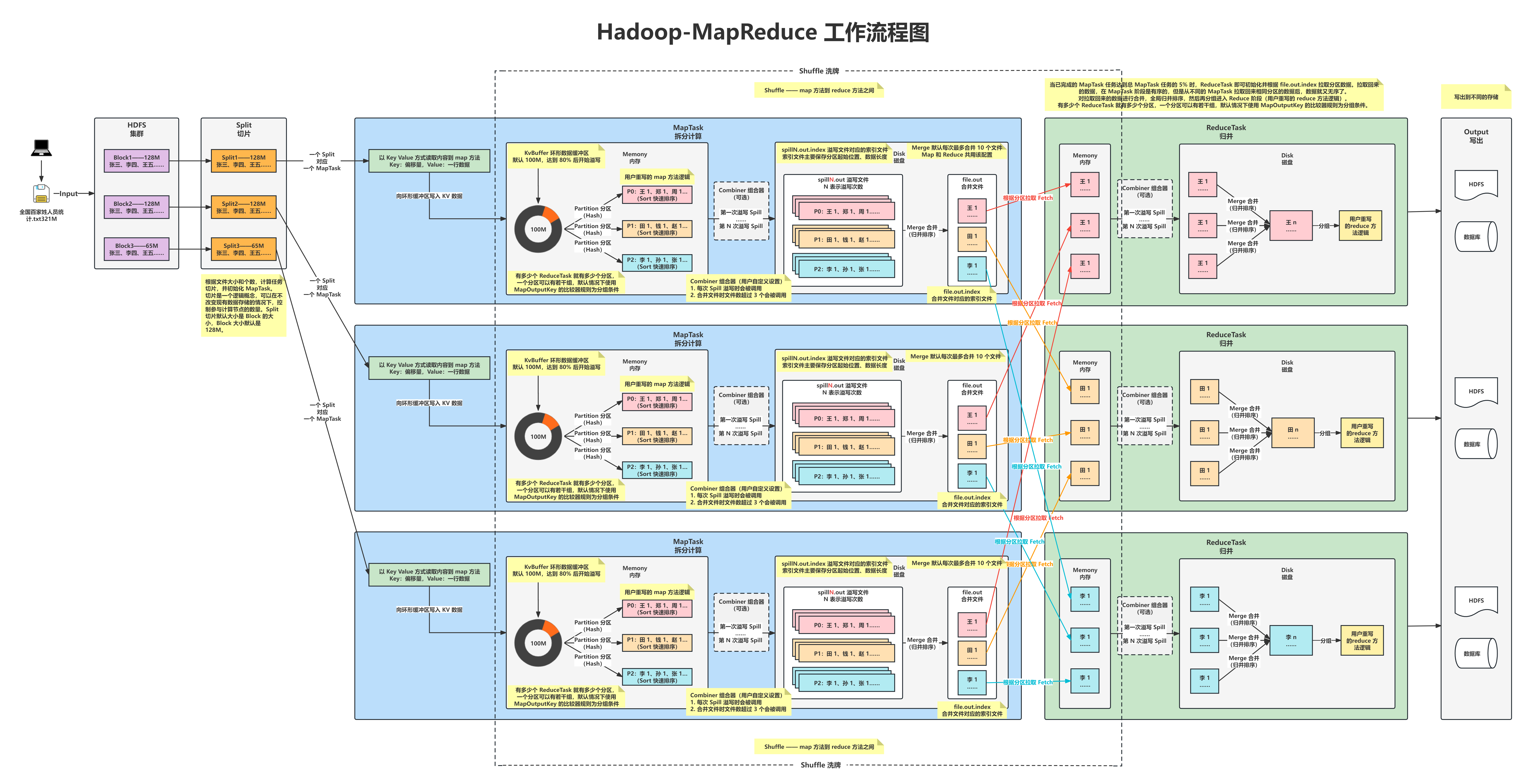
Hadoop-MapReduce 工作流程图 流程图模板_ProcessOn思维导图、流程图
https://www.processon.com/view/62bcf2827d9c08073522dd0e
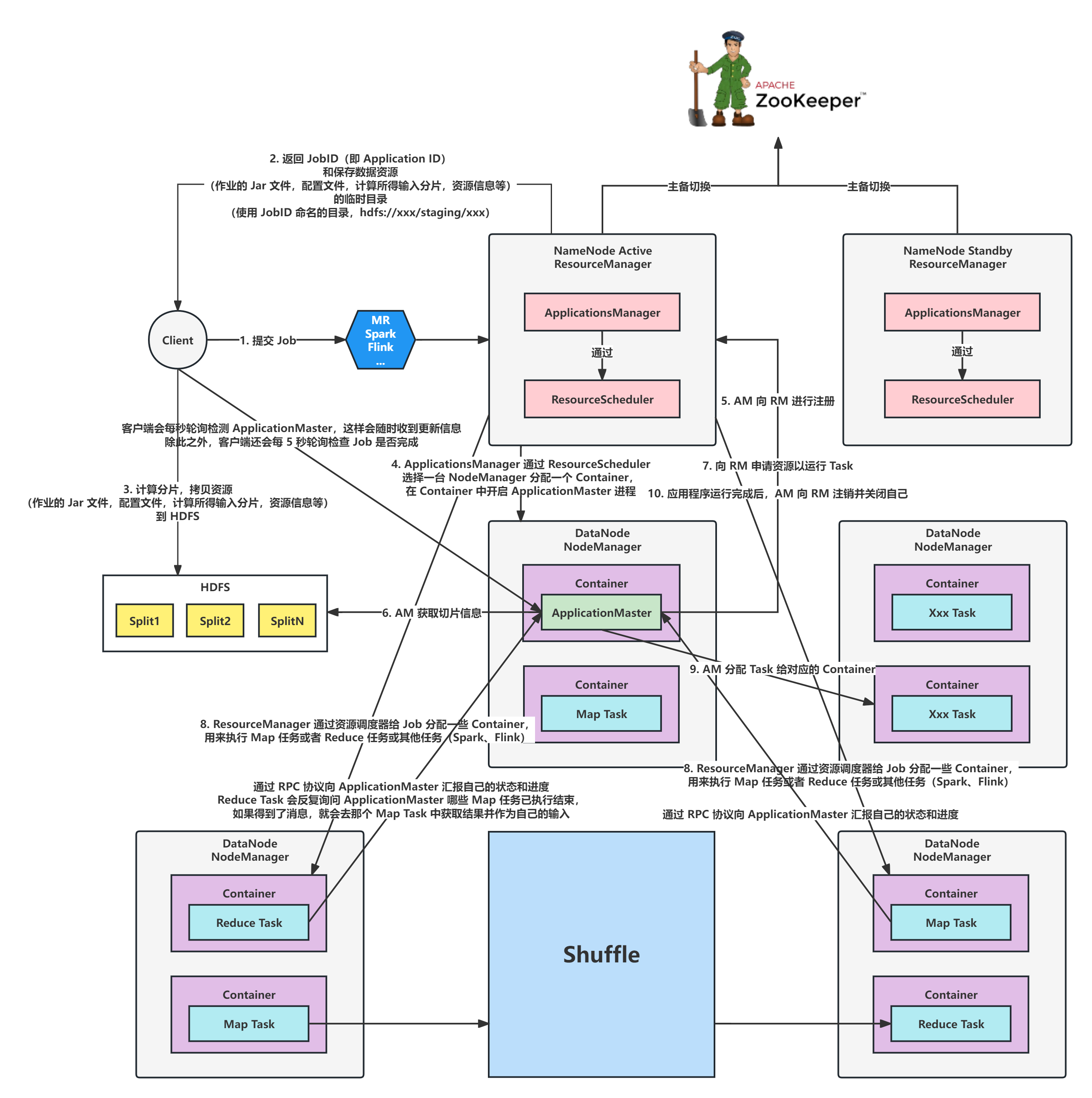
MapReduce2.x YARN 工作流程图 流程图模板_ProcessOn思维导图、流程图
https://www.processon.com/view/62c038edf346fb66f499eb69
3.2 Hive
Hive 就像是一个大数据魔法师,它可以将我们熟悉的 SQL 语言与大数据结合起来。有了 Hive,我们不需要学习新的编程语言,只需使用熟悉的 SQL,就能轻松地查询和分析海量的数据。Hive 会将 SQL 转换成 Hadoop 能够理解的 MapReduce 任务,让我们用得更加得心应手。
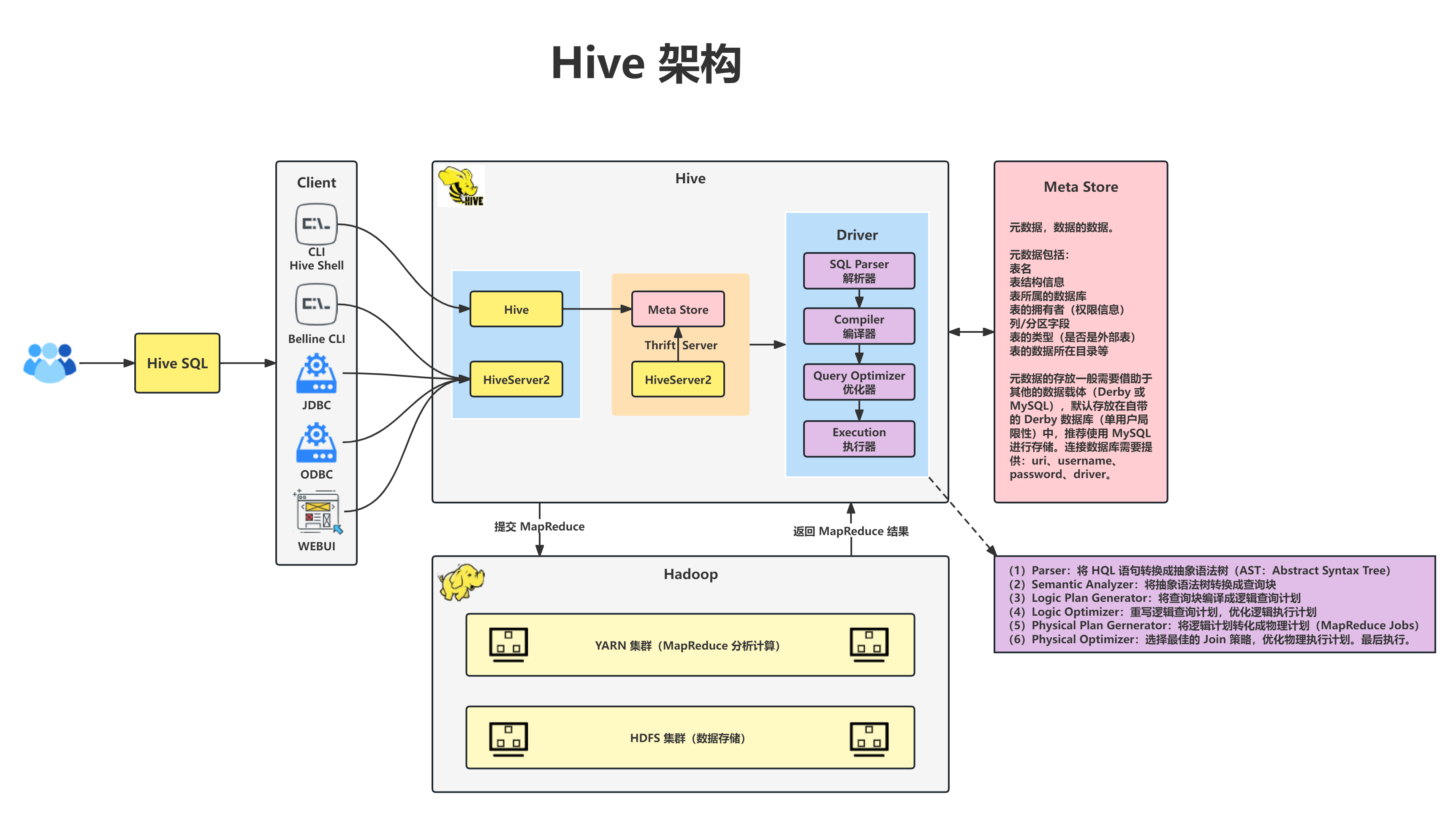
编辑▲Hive架构
https://www.processon.com/view/62e64bd35653bb0716178909
3.3 Spark
Spark 是 Hadoop 的好搭档,它像是个速度飞快的数据处理快车。与 Hadoop 相比,Spark 更擅长内存计算,这意味着它能更快地处理数据。Spark 支持各种复杂任务,如流式处理、机器学习和图形计算等,为我们提供更多可能性。它的快速处理能力让我们在大数据领域行驶如风!
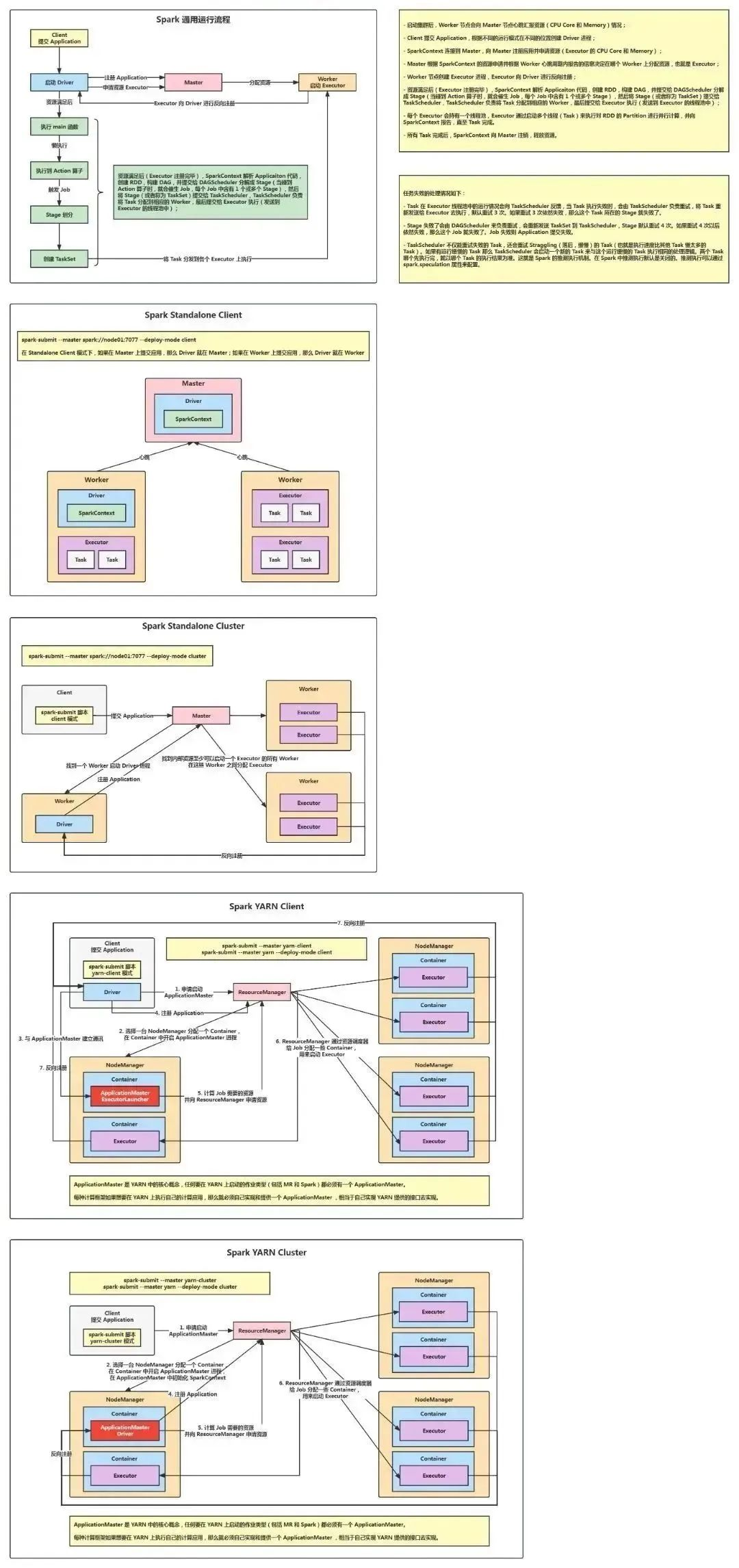
Spark 运行架构 流程图模板_ProcessOn思维导图、流程图
https://www.processon.com/view/63418a6507912921d8042a53
3.4 HBase
HBase 是一个分布式数据库,它像是一个超大号的表格,可以存储非结构化数据,也可以让非结构化数据配合Phoenix实现SQL操作。与传统的数据库不同,HBase 可以轻松应对海量的数据,而且还具备高可扩展性和高容错性。它通常用于存储非结构化数据,比如日志和社交媒体数据,为我们提供了一个强大的数据存储工具。
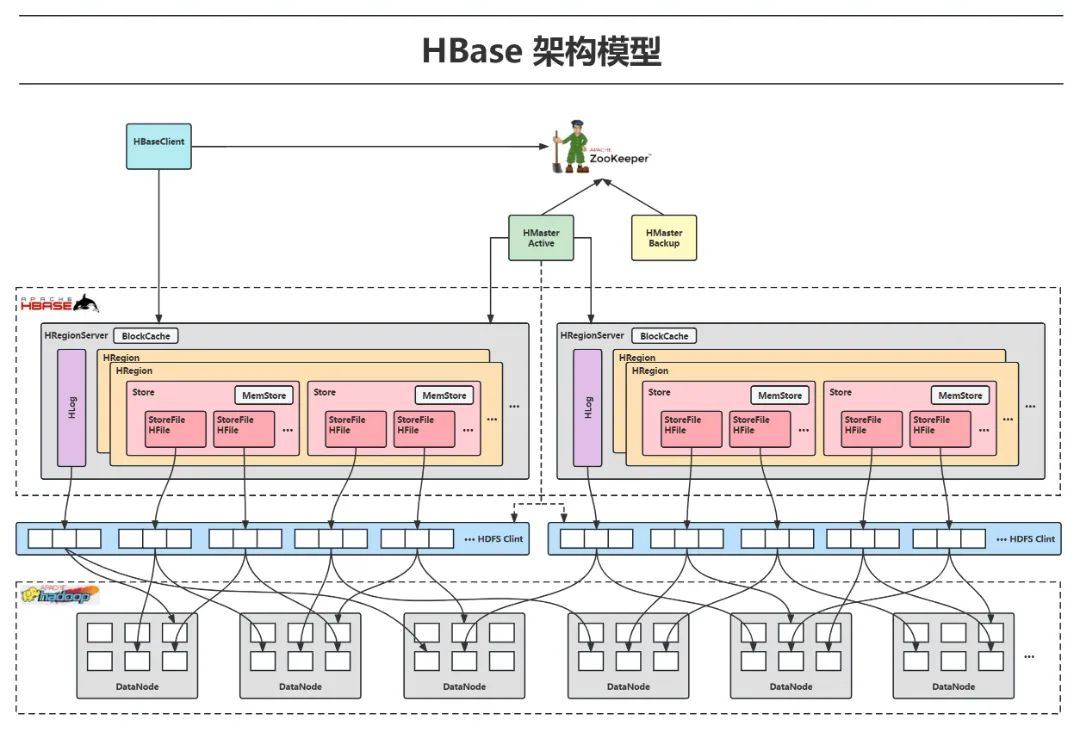
HBase 架构 流程图模板_ProcessOn思维导图、流程图
https://www.processon.com/view/630afe5663768906ff69458f
3.5 Kafka
Kafka 是一个高吞吐量的分布式消息队列系统,用于实时数据流的传输和处理。它能够支持百万级别的消息传输,是构建实时数据处理系统的理想选择。Kafka 是一个高效的消息传递平台,就像是一条快速传送信息的管道。它能够让消息快速、可靠地从发送方传送到接收方。不仅如此,它还能让消息的发送和接收变得灵活,就像是可以随时寄快递,而收件人在方便的时候签收包裹一样。
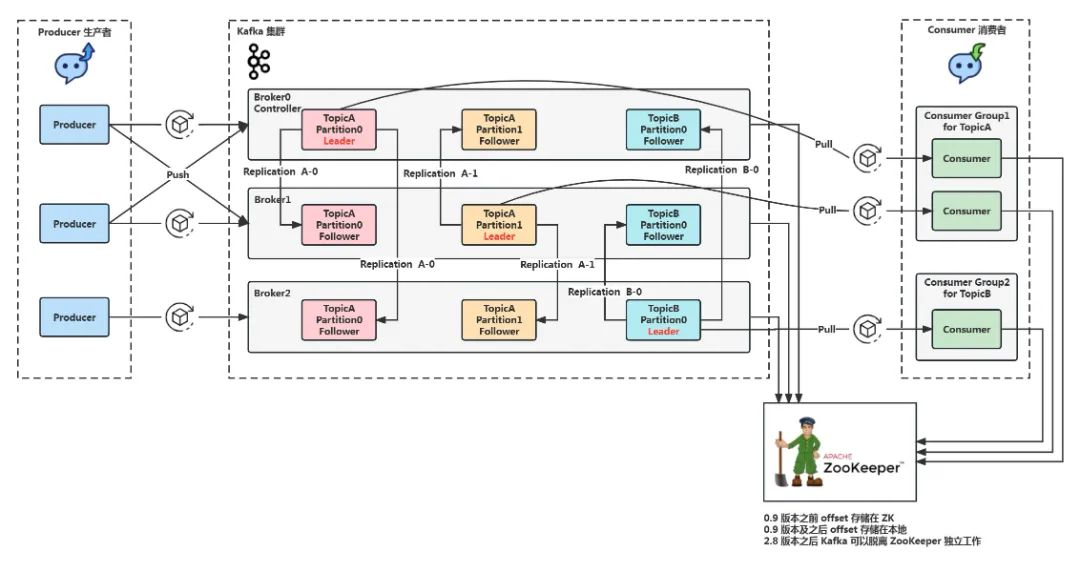
Kafka 架构 流程图模板_ProcessOn思维导图、流程图
https://www.processon.com/view/63c947c265644d659e1d8c1f
3.6 Flink
Flink 就像是一个实时数据处理专家,它可以让我们的数据处理变得更加快速和高效。Flink 支持流式数据处理,这意味着它可以实时地处理数据流,而不需要等待所有数据都到齐。这对于一些需要实时反馈的任务非常有用,比如实时监控和推荐系统。
3.7 ZooKeeper
ZooKeeper 就像是一个动物管理员,它负责管理大数据系统中的各种服务和组件。它可以帮助我们进行分布式协调和配置管理,确保所有组件能够协同工作。ZooKeeper 是大数据生态系统的重要支柱,保证了整个系统的稳定性和可靠性。
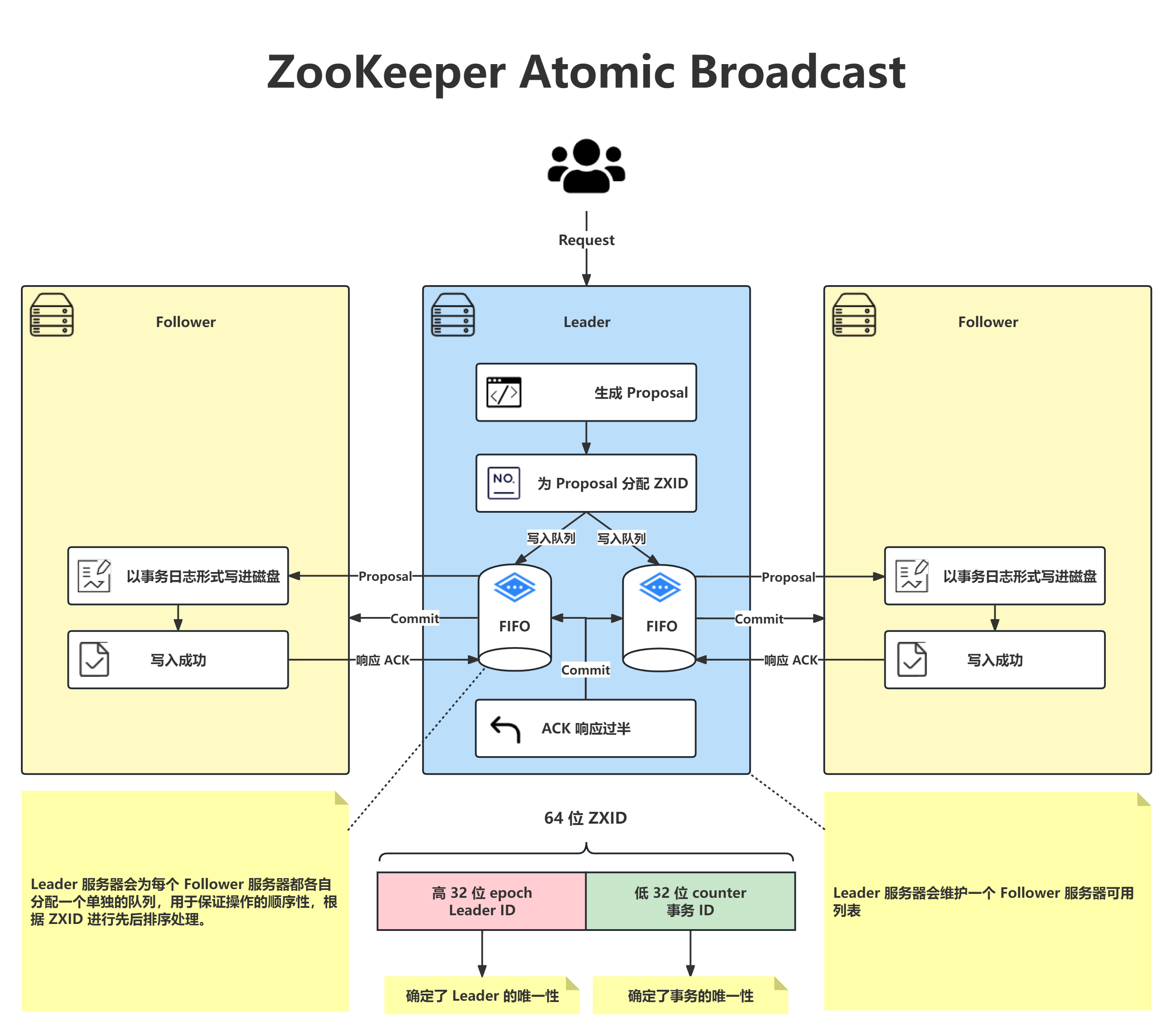
编辑▲ZooKeeper 的核心——ZAB 协议
四、大数据相关组件协作
当谈到大数据组件之间的协作时,你可以把它们比作一个默契的团队,共同合作以完成复杂的数据任务。让我用一个生动的比喻来解释:
想象一下,你们是一个大数据探险队,面对一片未知的数据荒原。这个探险队由不同的成员组成:
像一条高速传送信息的管道,让探险队成员之间能够快速、可靠地传递消息,保持信息的及时交流。
这个探险队的成员之间默契配合,各司其职,共同协作,最终完成了复杂的数据任务。就像一个默契的团队一样,大数据组件们一起工作,使得数据处理变得更加高效、可靠,帮助我们揭开数据的神秘面纱。
五、大数据面临的挑战
尽管大数据为我们带来了前所未有的机遇,但也面临着一些挑战:
隐私和安全:大数据中包含着大量的个人信息,隐私和安全保护成为重要的问题。必须采取措施确保数据的安全性和合法使用。
数据质量:大数据往往来源于不同的渠道和系统,数据质量良莠不齐。不准确或不完整的数据可能导致错误的决策。
处理能力:海量数据的处理需要强大的计算能力和存储资源。构建大数据处理系统需要投入大量资金和技术支持。
法律法规:随着大数据的广泛应用,相关法律法规也在不断完善。企业和组织必须遵守相关规定,否则可能面临法律责任。
大数据是当今社会的瑰宝,它让我们能够洞悉未知世界,做出更明智的决策。通过了解大数据的概念、应用和相关组件,我们可以更好地把握这项技术带来的机遇和挑战。在未来的日子里,大数据必将继续引领科技的发展,为我们带来更多的惊喜和改变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号