
Oracle Undo表空间使用情况分析 - 11gR2
环境介绍
操作系统: AIX 7.1
数据库:Oracle 11.2.0.4
一般情况下,收到Undo表空间报警基本都是忽略的,因为大部分统计Undo使用率的SQL都是把UNEXPIRED部分算作已使用部分的,实际上其中有较大部分是可以重用的。
这两天持续报Undo表空间剩余可用空间低于1%,所以查看了一下原因。
查询SQL语句:
SQL> select tablespace_name, status, sum(bytes/1024/1024) "MB"
from dba_undo_extents
group by tablespace_name, status
order by 1, 2;

不同状态的含义:
ACTIVE :有活动事务在使用 Undo,这部分空间属于Session正在使用的空间;
UNEXPIRED :事务提交并且没到undo_retention设置时间之前,这些Undo Block还没有过期,但是已经没有活动事务在使用了,在超过undo_retention设置时间之后,这部分空间会变成EXPIRED状态;
EXPIRED :事务提交并且到undo_retention设置时间之后,这些Undo Block已经过期了,这部分空间是可以重用的,属于未使用空间;
可以看到 ACTIVE和UNEXPIRED的大小达到98272 MB(UNDOTBS1表空间大小98296 MB),使用率接近100%。
查找资料发现Oracle 10g中引入了一个新的自动调整undo_retention的特性,在Oracle Database 10g中当自动undo管理被默认启用,每隔10分钟会自动设置当前的undo_retention,Oracle Database尝试至少保留旧的undo信息到该时间。该信息可以在视图v$undostat查到。
SQL> select begin_time,tuned_undoretention from V$UNDOSTAT where rownum < 11;
BEGIN_TIME TUNED_UNDORETENTION
------------------------------ -------------------
2021/09/23 09:53:51 653881
2021/09/23 09:43:51 654763
2021/09/23 09:33:51 654644
2021/09/23 09:23:51 654513
2021/09/23 09:13:51 654883
2021/09/23 09:03:51 654863
2021/09/23 08:53:51 651826
2021/09/23 08:43:51 655097
2021/09/23 08:33:51 655045
2021/09/23 08:23:51 654809
2021/09/23 08:13:51 654226
可以看到Oracle设置的undo_retention时间高达65W多,所以导致出现大量的UNEXPIRED占用。
Metalink里有一篇文章介绍Automatic Tuning of Undo Retention引起空间问题的文章:
Automatic Tuning of Undo_retention Causes Space Problems [ID 420525.1]
文章里给出了3个解决方法:
1)设置Undo数据文件为可扩展并且MAXSIZE为数据文件当前大小;
SQL> alter database datafile ‘<datafile_flename>’ autoextend on maxsize <current_size>;
感觉这个设置就是为了让Automatic Tuning of Undo Retention能更准确的估算v$undostat.tuned_undoretention的大小,但是发现好像不是太管用,至少没有立竿见影。
2)设置隐藏参数_smu_debug_mode
SQL> alter system set "_smu_debug_mode" = 33554432;
设置这个之后v$undostat.tuned_undoretention会取(maxquerylen secs + 300)和参数undo_retention里的最大值。网上有人设置之后出现大量ORA-01555错误,遂放弃这个方法。
3)设置隐藏参数_undo_autotune
SQL> alter system set "_undo_autotune" = false;
这个方法就比较暴力了,直接禁用了Automatic Tuning of Undo Retention特性。
4)非官方解决方法(后来再查发现也是官方建议,参考Note 742035.1)
alter system set "_highthreshold_undoretention"=86400;
在查undo相关参数的时候,发现如下参数,感觉应该有第4种解决方法:
KSPPINM KSPPSTVL KSPPDESC
---------------------------------------- -------------------- ------------------------------------------------------------
_highthreshold_undoretention 4294967294 high threshold undo_retention in seconds
测试之后,发现该参数的值可以限定v$undostat.tuned_undoretention的最大大小。
SQL> select begin_time,maxquerylen,expiredblks,unexpiredblks,activeblks,tuned_undoretention from V$UNDOSTAT where rownum < 11;
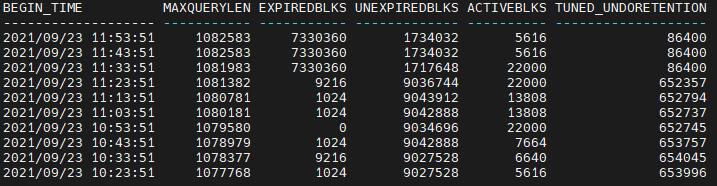
tuned_undoretention最大值限定之后,UNEXPIRED部分就开始释放了,所以方法这个还是有效的。并且将该值限定到86400,也就是一天,应该没有什么事务需要占用一天的Undo了,有也需要提出来优化。
SQL> select tablespace_name, status, sum(bytes/1024/1024) "MB"
from dba_undo_extents
group by tablespace_name, status
order by 1, 2;

至此,该问题解决,既使用了Automatic Tuning of Undo Retention的新特性,也不会导致Undo表空间使用率的问题。完美!
附录
Maclean博客里查询Undo使用率的SQL
查询undo真实的使用率:
prompt
prompt ############## IN USE Undo Data ##############
prompt
select
((select (nvl(sum(bytes),0))
from dba_undo_extents
where tablespace_name in (select tablespace_name from dba_tablespaces
where retention like '%GUARANTEE' )
and status in ('ACTIVE','UNEXPIRED')) *100) /
(select sum(bytes)
from dba_data_files
where tablespace_name in (select tablespace_name from dba_tablespaces
where retention like '%GUARANTEE' )) "PCT_INUSE"
from dual;
此外,从Maclean的博客中找到两条实用的UNDO表空间监控的查询SQL:
--在Oracle 10g版本中可以使用V$UNDOSTAT视图用于监控实例中当前事务使用UNDO表空间的情况。视图中的每行列出了每隔十分钟从实例中收集到的统计信息。
--每行都表示了在过去7*24小时里每隔十分钟UNDO表空间的使用情况,事务量和查询长度等信息的统计快照。
--UNDO表空间的使用情况会因事务量变化而变化,一般我们在计算时同时参考UNDO表空间的平均使用情况和峰值使用情况
--以下SQL语句用于计算过去7*24小时中UNDO表空间的平均使用量
select ur undo_retention,
dbs db_block_size,
((ur * (ups * dbs)) + (dbs * 24)) / 1024 / 1024 as "M_bytes"
from (select value as ur from v$parameter where name = 'undo_retention'),
(select (sum(undoblks) / sum(((end_time - begin_time) * 86400))) ups
from v$undostat),
(select value as dbs from v$parameter where name = 'db_block_size');
--以下SQL语句则按峰值情况计算UNDO表空间所需空间:
select ur undo_retention,
dbs db_block_size,
((ur * (ups * dbs)) + (dbs * 24)) / 1024 / 1024 as "M_bytes"
from (select value as ur from v$parameter where name = 'undo_retention'),
(select (undoblks / ((end_time - begin_time) * 86400)) ups
from v$undostat
where undoblks in (select max(undoblks) from v$undostat)),
(select value as dbs from v$parameter where name = 'db_block_size');
Automatic Tuning of Undo Retention特性介绍
Oracle 10g中引入了一个新的自动调整undo_retention的特性,其目的是为了减少ORA-01555错误出现的概率,Oracle会忽略UNDO_RETENTION参数设置的阀值,而是根据UNDO表空间的大小和使用率来自动调整UNDO信息的保留时间。会造成的影响是UNDO表空间的区(extent)中大部分都是未过期状态(unexpired),这就会导致数据库在给事务分配UNDO块时,会优先使用UNDO表空间的的空闲空间分配,而不是覆盖已经分配的空间,这使得UNDO表空间的使用率保持在一个较高的水平。
Oracle数据库在为事务进行分配UNDO块时,会按照这样的算法和流程:
1. 如果当前区(extent)中还有空闲块,在需要空间时会继续使用本区(extent)中的空闲块。
2. 在当前区(extent)使用完后,如果下一个区(extent)是过期状态(expired),那么就跳转到下一个区(extent)的第一个数据块。
3. 如果下一个区(extent)不是过期状态(expired),就从UNDO表空间申请空间,如果UNDO表空间中存在空闲的空间,就分配新的区(extent)加入到undo segment,然后跳转到新区(extent)的第一个数据块。
4. 如果没有剩余空闲的区(extent),则会从OFFLINE状态的回滚段中窃取(STEAL)过期的区,加入当前的回滚段,并使用第一个数据块。
5. 如果OFFLINE状态的回滚段中没有过期的区,那么会从ONLINE状态的回滚段窃取(STEAL)过期的区加入当前的回滚段,并使用第一个数据块。
6. 如果UNDO表空间能够自动扩展,则会扩展UNDO表空间,并将新区加入到当前回滚段中。
7. 如果undo表空间数据文件不能扩展,调低10%的retention值,然后窃取(STEAL)在短保留时间的过期区,如果还未找到过期区,则继续以10%的速度减少回滚的保留时间。
8. 随机从其他OFFLINE状态的回滚段中窃取(STEAL)未过期的(unexpired)的区。
如果以上的尝试都失败,那么久会报ORA-30036错误。
从上面的步骤可以看出,事务会优先使用UNDO空闲空间、过期状态(expired)的UNDO区,然后会尝试扩展表空间的数据文件,只有在以上步骤都得不到获得UNDO表空间后,才会去使用未过期(unexpired)的UNDO区。
引用链接:https://blog.csdn.net/w892824196/article/details/100123813

 浙公网安备 33010602011771号
浙公网安备 33010602011771号