


python批量将文件编码格式转换为 UTF8带标签的格式,解决linux环境下中文编码乱码的问题
指定一个文件夹,遍历文件夹内的文件和子文件夹内的文件,然后识别文件后缀为cpp的文件,通过chardet取检测文件的编码格式,如果不是UTF-8-SIG,则转换为UTF-8-SIG
python脚本格式如下

import os import sys import codecs import chardet def convert(filename,out_enc="UTF-8-SIG"): try: content=codecs.open(filename,'rb+').read() source_encoding=chardet.detect(content)["encoding"] print(source_encoding) if source_encoding != "UTF-8-SIG":#"GB2312": content=content.decode(source_encoding).encode(out_enc) codecs.open(filename,'wb+').write(content) print("covert file "+filename) except IOError as err: print("I/O error:{0}".format(err)) def removeBom(file): '''移除UTF-8文件的BOM字节''' data = open(file,'rb+').read() if data[:3] == codecs.BOM_UTF8: data = data[3:] data.decode("utf-8") # print(data.decode("utf-8")) def explore(dir): for root,dirs,files in os.walk(dir): for file in files: if os.path.splitext(file)[1]=='.cpp': print(file) path=os.path.join(root,file) convert(path) # removeBom(path) def main(): explore(sys.argv[1]) if __name__=="__main__": main()
如果出现未找到chardet的错误,在cmd中执行下pip install chardet 命令,就可以安装chardet
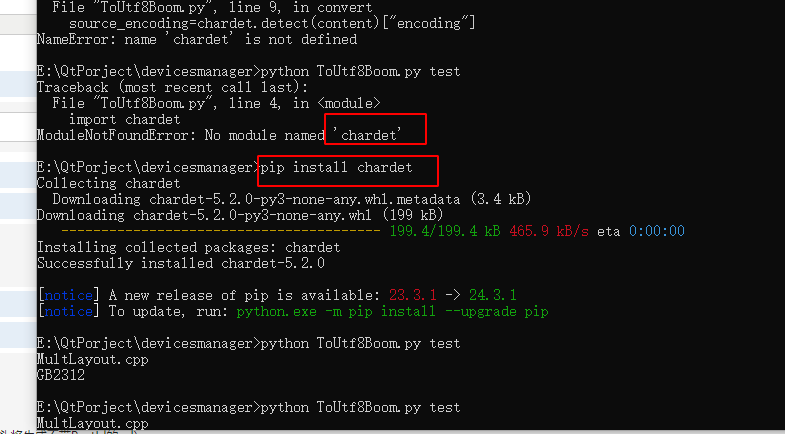
然后用cmd执行 执行命令 python ToUtf8.py test test是文件夹的名称;就可以批量实现文件的编码格式识别和转换了;
自己开发了一个股票智能分析软件,功能很强大,需要的关注微信公众号:QStockView


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix