python3爬虫应用--爬取网易云音乐(两种办法)
一、需求
好久没有碰爬虫了,竟不知道从何入手。偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫芦画瓢般尝试做一做。本文主要是通过网页的歌名搜索,然后获取到页面上的搜索结果,最后自行选择下载搜索结果中的哪条歌曲。
二、应用
在这个过程中,有很多坑,但还好撑过去了。过程中主要用到的东西有 fiddler抓包查看日志、浏览器JS的分析、python ASE的加密、request包 的简单应用、jsonpath包的运用、python基础的列表、字典、格式化的简单运用。
三、说明
1、本文主要参考引用了以下博文,感谢大神们的思路和过程:
https://www.zhihu.com/question/36081767
https://www.cnblogs.com/nienie/p/8511999.html
https://www.zhihu.com/question/20799742/answer/99491808
https://www.cnblogs.com/mxk123/p/11832247.html(CSS选择器学习)
https://www.cnblogs.com/songzhenhua/p/10260992.html (也是CSS选择器学习)
https://www.cnblogs.com/yuluoxingkong/p/10019246.html (可以借鉴无界面话的浏览器模式)
2、本文仅供娱乐和学习,切勿用于商业用途,如有发现,概不负责!
四、正文
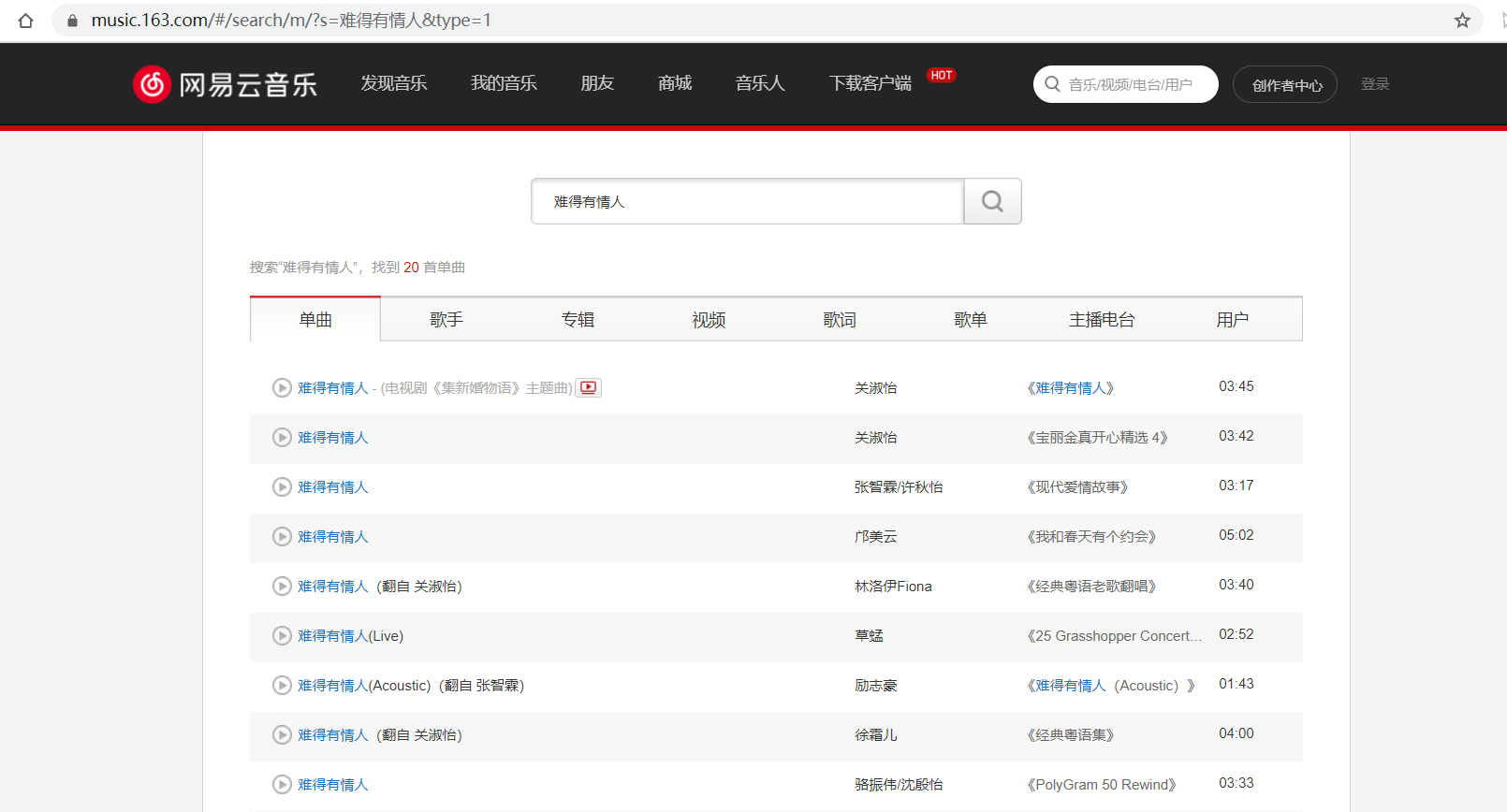
上图就是我们的目标页面,很简单的实现搜索和下载音乐的功能。
根据搜索地址(https://music.163.com/#/search/m/?s=难得有情人&type=1),本文主要的思路有:
思路一
1、使用beautifulsoup 把整个网页load下来,看HTML中是否有歌曲的ID,我们主要是用ID来进行下载,有个歌曲外链的下载地址(http://music.163.com/song/media/outer/url?id=id.mp3
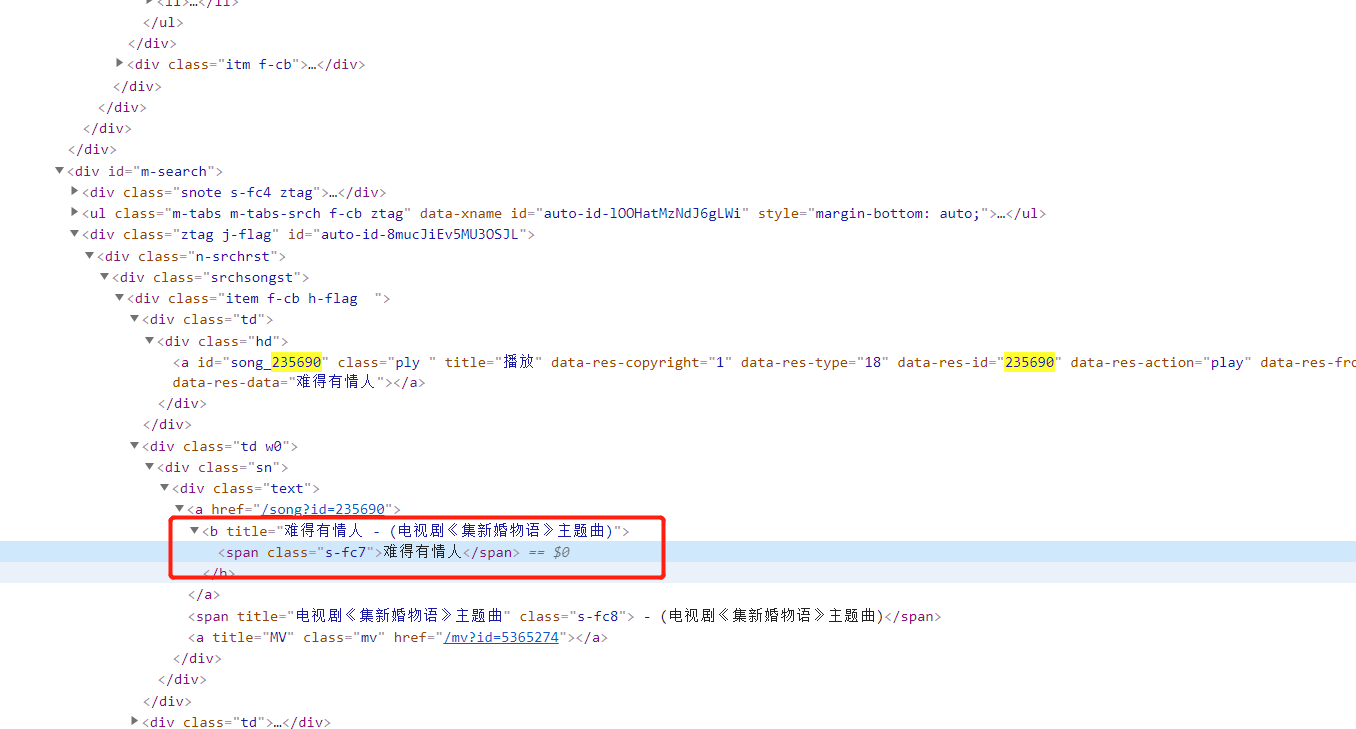
),我也不知道从哪里来的,可以根据ID来下载歌曲。现在看下网页的HTML源码,对着歌名右键——检查,可以看到歌名、歌曲的id、歌手等信息,然后使用beautifulsoup 进行获取就可以了。但是现在关键信息都放在了iframe里面,暂时不知道怎么抓取。本文就先不深入阐述,有时间再研究一下。(补:网上搜了一下可以使用webdriver来实现跨iframe抓取数据,因此也就使用该种方法了,不多说直接放代码,代码比第二种少了一些,不过速度较慢)
------------------------------------补上思路一的代码,效果和思路二是一样的----------------------------------------
import requests # 用于获取网页内容的模块 from bs4 import BeautifulSoup # 用于解析网页源代码的模块 from selenium import webdriver from selenium.webdriver.chrome.options import Options def handle_hmtl(search_name): chrome_options = Options() chrome_options.add_argument('--headless') driver = webdriver.Chrome('chromedriver', chrome_options=chrome_options) link = "https://music.163.com/#/search/m/?s=" + search_name + "&type=1" # 要搜索的链接 driver.get(link) iframe_elemnt = driver.find_element_by_id("g_iframe") # 因为直接获取不到iframe的内容,因此使用web_driver driver.switch_to.frame(iframe_elemnt) # 关键步骤,跳转到iframe里面,就可以获取HTML内容 soup = BeautifulSoup(driver.page_source, "html.parser") # 通过 BeautifulSoup 模块解析网页,具体请参考官方文档。 L = [] # 存储结果的列表 nu = 0 for value in soup.select( "div[class='srchsongst'] div[class^='item f-cb h-flag']"): # 获取到关键class:srchsongst下面的所有元素,结果是一个列表,使用的是CSS的方式 D = {'num': 'null', 'name': 'null', 'id': 'null', 'singer': 'null', 'song_sheet': 'null'} # 初始化字典 D['num'] = nu # 用来计算num D['name'] = value.b.attrs['title'] # 歌名 D['id'] = value.a.attrs['data-res-id'] # 歌曲ID D['singer'] = '/'.join([i.string for i in value.select('a[href^="/artist?i"]')]) # 歌唱者 D['song_sheet'] = value.select('a[class^="s-fc3"]')[0].attrs['title'] # 专辑 L.append(D) nu += 1 return L def load_song(num, result): """ result 是一个列表 num 是一个str """ if isinstance(int(num), int): num = int(num) if num >= 0 and num <= len(result): song_id = result[num]['id'] song_down_link = "http://music.163.com/song/media/outer/url?id=" + result[num]['id'] + ".mp3" # 根据歌曲的 ID 号拼接出下载的链接。歌曲直链获取的方法参考文前的注释部分。 print("歌曲正在下载...") response = requests.get(song_down_link, headers=headers).content # 亲测必须要加 headers 信息,不然获取不了。 f = open(result[num]['name'] + ".mp3", 'wb') # 以二进制的形式写入文件中 f.write(response) f.close() print("下载完成.\n\r") else: print("你输入的数字不在歌曲列表范围,请重新输入") else: print("请输入正确的歌曲序号") if __name__ == '__main__': headers={ # 伪造浏览器头部,不然获取不到网易云音乐的页面源代码。 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36', 'Referer':'http://93.174.95.27', } search_name = input("请输入你想要在网易云音乐中搜索的单曲:") result = handle_hmtl(search_name) print("%3s %-35s %-20s %-20s " % ("序号", " 歌名", "歌手", "专辑")) for i in range(len(result)): print("%3s %-35s %-20s %-20s " % ( result[i]["num"], result[i]["name"], result[i]["singer"], result[i]["song_sheet"])) num = input("请输入你想要下载歌曲的序号/please input the num you want to download:") load_song(num, result) # 下载歌曲
思路二
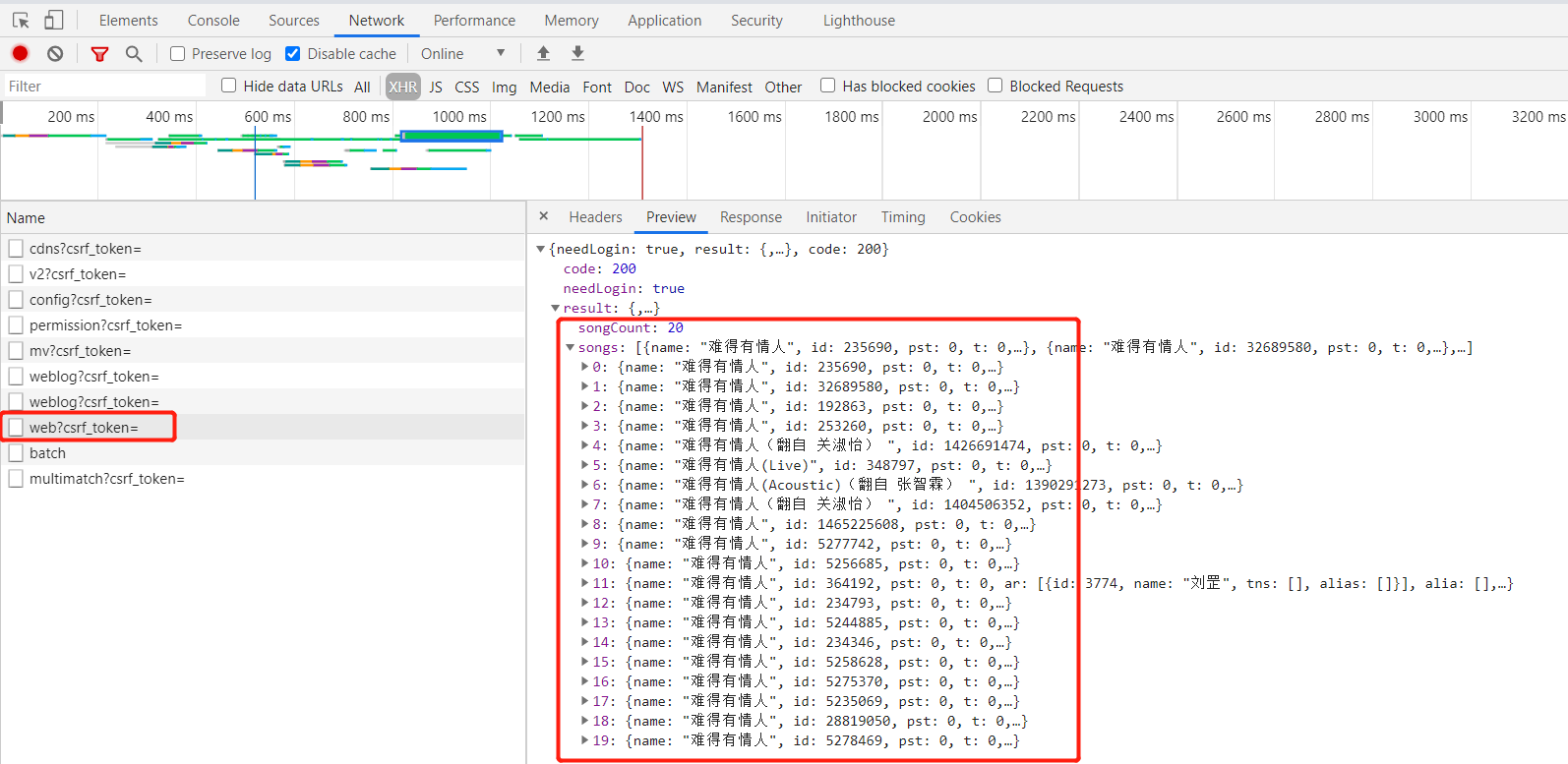
2、第二种思路就是参考博文中,直接获取接口返回的内容,查看接口是否返回歌曲的关键信息,同样右键检查一下,歌词的关键信息是这个接口(https://music.163.com/weapi/cloudsearch/get/web?csrf_token=)返回的,而请求参数是:params和encSecKey,看那么长的一串,肯定是经过加密的了。
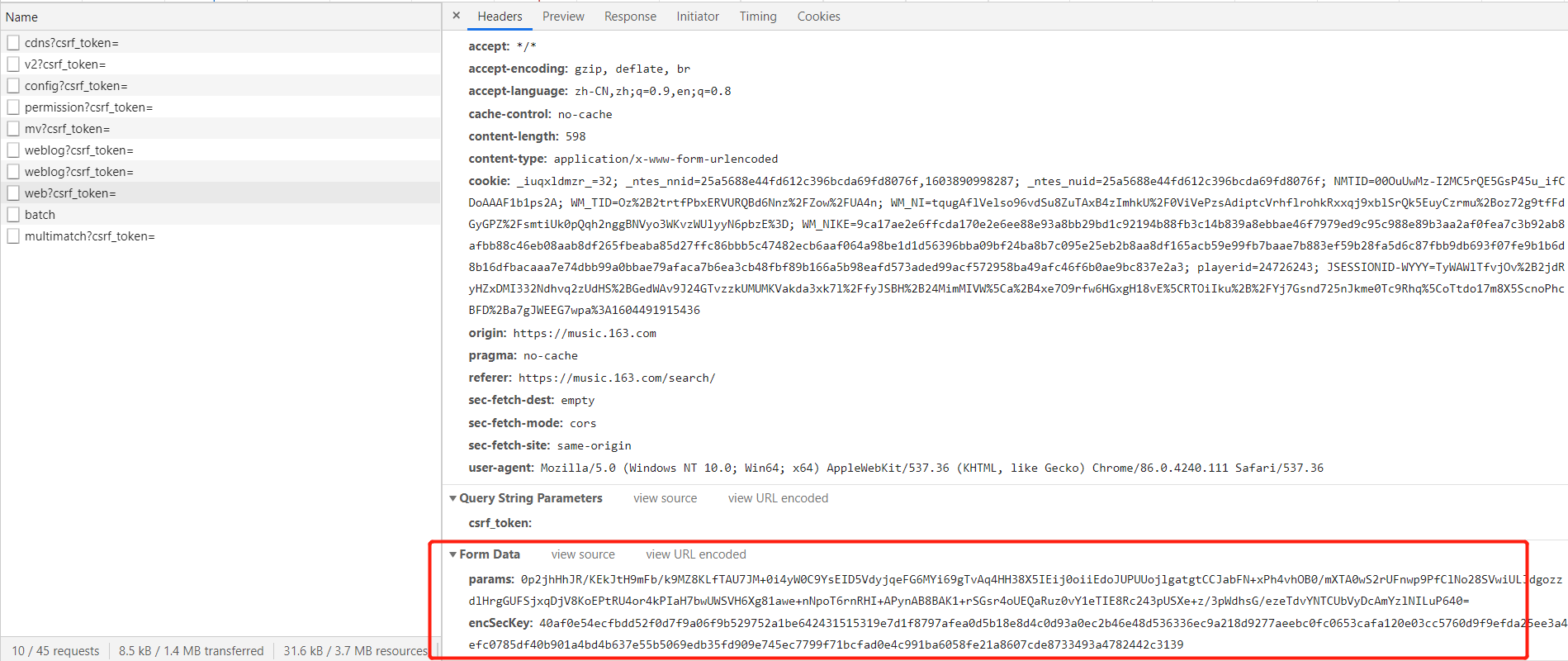
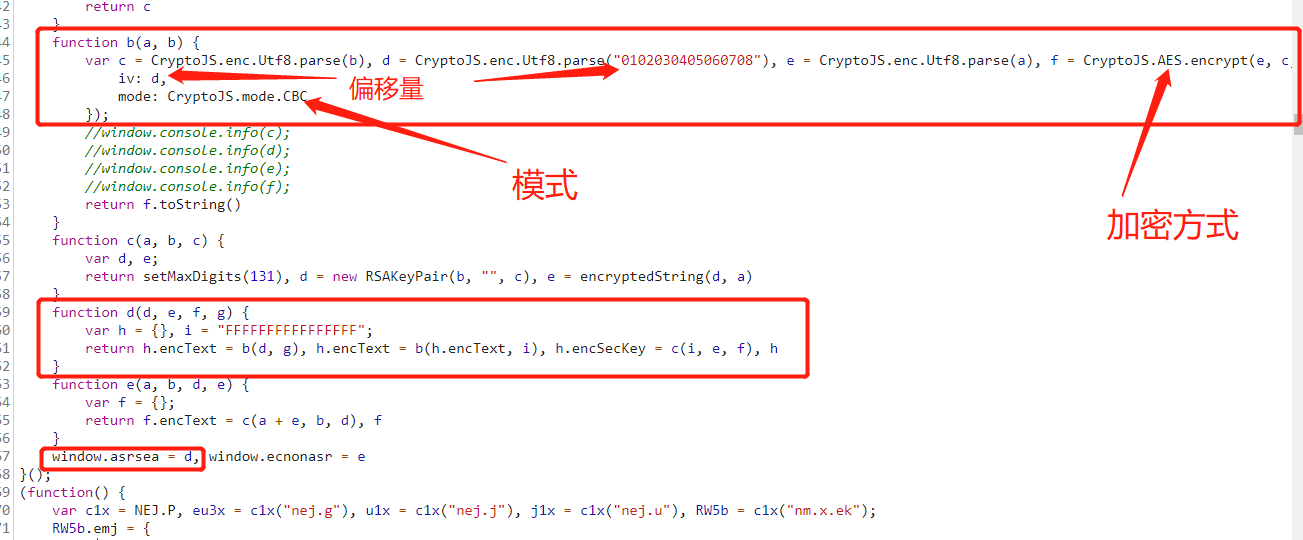
从参考博文中可以得知,该参数是经过JS加密得到的,至于如何知道是经过JS加密得到的,我也不太清楚。从浏览器的initiator项可以这个地址使用了叫core_xxx的JS文件,因此,我们点击JS项,查看该JS文件,果然有该文件。如果没有加载出来该JS文件,那需要在F12的开发者工具的“Disable cashe”勾选上(因为本地缓存了之后浏览器就不加载了)。通过preview来查看JS的代码,我们可以搜索一下我们想要的那两个关键字段encSecKey, 搜索后发现有一个关键的函数 window.asrsea,而这个函数又是一个d 的函数。


因此我们需要知道window.asrsea 的4个参数,JSON.stringify(i1x)、bxX3x(["流泪", "强"])、bxX3x(RW5b.md)、bxX3x(["爱心", "女孩", "惊恐", "大笑"])。这里我们也使用fiddler抓包,然后分别打印出这几个参数的值。【注:这里有个踩坑点,就是参照的博文中,打印的是i1x 而不是JSON.stringify(i1x) 这个。但是打印出i1x之后会有个风险就是使用转义字符的时候容易出错,因此建议打印出全部】,可以看出,JSON.stringify(i1x) 这个参数打印出了好多个值,这里只能一一试错,我暂时没有好的办法定位到哪个是目标接口调用的。同样的办法可以找出那4个参数:


first_param = r'{"hlpretag":"<span class=\"s-fc7\">","hlposttag":"</span>","s":"' + search_name + r'","type":"1","offset":"0","total":"true","limit":"30","csrf_token":""}' second_param = "010001" third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7" forth_param = "0CoJUm6Qyw8W8jud"
fiddler抓包再说一下,如果出现使用fiddler抓包但是原网页显示不全的话,那就需要安装好fiddler的证书之后再试。

知道了这4个参数之后,可以通过JS文件中的内容获取到加密的方式,就是ASE加密,模式是CBC模式,偏移量为vi ;知道了这些参数,就可以使用python的ASE加密进行加密,代码如下:【注:这里有个坑:参考的博文中可能使用的ASE的版本不一致导致了加密算法报错,不加.encoding('utf-8') 的话会出现二进制的报错,另外需要先转成转码变成二进制之后再进行16位补齐】,这样就可以得到params 值,为什么说encSecKey 是常量呢,可以观察到encSecKey 的值是d 函数中的h.encSecKey,这里我们给定一个i 之后,就可以得到固定的encSecKey值。知道了这两个参数之后,就可以获取到完整的返回值了。

def AES_encrypt(text, key, iv): text = text.encode('utf-8') pad = 16 - len(text) % 16 text = text + ( pad * chr(pad)).encode('utf-8') # 需要转成二进制,且可以被16整除 key = key.encode('utf-8') iv = iv.encode('utf-8') encryptor = AES.new(key, AES.MODE_CBC, iv) encrypt_text = encryptor.encrypt(text) # .encode('utf-8') encrypt_text = base64.b64encode(encrypt_text) return encrypt_text.decode('utf-8')
def get_params(): # 获取params 参数的函数 iv = "0102030405060708" first_key = forth_param second_key = 16 * 'F' h_encText = AES_encrypt(first_param, first_key, iv) h_encText = AES_encrypt(h_encText, second_key, iv) return h_encText
得到的json报文之后,可以使用jsonpath 包来进行处理,提取我们需要的值,详细的Jsonpath的规则可参考(https://www.cnblogs.com/aoyihuashao/p/8665873.html):
def handle_json(ressult_str): """通过request返回的json结果,对结果进行处理""" ressult_str = ressult_b.decode('utf-8') # 结果转码为str类型 json_text = json.loads(ressult_str) # 加载为json格式 i = 0 L = [] for i in range(len(jsonpath(json_text, '$..songs[*].id'))): # 根据id获取列表条数 D = {'num': 'null', 'name': 'null', 'id': 'null', 'singer':'null', 'song_sheet':'null'} # 初始化字典 D['num'] = i D['name'] = '/'.join(jsonpath(json_text, "$..songs["+str(i)+"].name")) # 获取名称 D['id'] = str(jsonpath(json_text, "$..songs["+str(i)+"].id")[0]) # 获取ID且获取第一个ID值并转化为str类型 D['singer'] = '/'.join(jsonpath(json_text, "$..songs["+str(i)+"].ar[*].name")) # 获取歌手列表 al_list = jsonpath(json_text, "$..songs["+str(i)+"].al.name") # 获取专辑列表 al = '/'.join(al_list) # 将获取的专辑列表合并 D['song_sheet'] = "《" + al + "》" L.append(D) return L
下面附上全部代码(只为实现功能,还有些bug需要优化):
# coding = utf-8 #from bs4 import BeautifulSoup # 用于解析网页源代码的模块 from binascii import b2a_hex, a2b_hex from jsonpath import jsonpath from Crypto.Cipher import AES import requests # 用于获取网页内容的模块 import base64 import json def get_params(): # 获取params 参数的函数 iv = "0102030405060708" first_key = forth_param second_key = 16 * 'F' h_encText = AES_encrypt(first_param, first_key, iv) h_encText = AES_encrypt(h_encText, second_key, iv) return h_encText def get_encSecKey(): encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c" return encSecKey def AES_encrypt(text, key, iv): text = text.encode('utf-8') pad = 16 - len(text) % 16 text = text + ( pad * chr(pad)).encode('utf-8') # 需要转成二进制,且可以被16整除 key = key.encode('utf-8') iv = iv.encode('utf-8') encryptor = AES.new(key, AES.MODE_CBC, iv) encrypt_text = encryptor.encrypt(text) # .encode('utf-8') encrypt_text = base64.b64encode(encrypt_text) return encrypt_text.decode('utf-8') def get_json(url, params, encSecKey): data = { "params": params, "encSecKey": encSecKey } response = requests.post(url, headers=headers, data=data) return response.content def handle_json(ressult_str): """通过request返回的json结果,对结果进行处理""" ressult_str = ressult_b.decode('utf-8') # 结果转码为str类型 json_text = json.loads(ressult_str) # 加载为json格式 i = 0 L = [] for i in range(len(jsonpath(json_text, '$..songs[*].id'))): # 根据id获取列表条数 D = {'num': 'null', 'name': 'null', 'id': 'null', 'singer':'null', 'song_sheet':'null'} # 初始化字典 D['num'] = i D['name'] = '/'.join(jsonpath(json_text, "$..songs["+str(i)+"].name")) # 获取名称 D['id'] = str(jsonpath(json_text, "$..songs["+str(i)+"].id")[0]) # 获取ID且获取第一个ID值并转化为str类型 D['singer'] = '/'.join(jsonpath(json_text, "$..songs["+str(i)+"].ar[*].name")) # 获取歌手列表 al_list = jsonpath(json_text, "$..songs["+str(i)+"].al.name") # 获取专辑列表 al = '/'.join(al_list) # 将获取的专辑列表合并 D['song_sheet'] = "《" + al + "》" L.append(D) return L def load_song(num, result): if isinstance(int(num), int):
num = int(num) if num >= 0 and num <= len(result): song_id = ressult[num]['id'] song_down_link = "http://music.163.com/song/media/outer/url?id=" + ressult[num]['id'] + ".mp3" # 根据歌曲的 ID 号拼接出下载的链接。歌曲直链获取的方法参考文前的注释部分。 print("歌曲正在下载...") response = requests.get(song_down_link, headers=headers).content # 亲测必须要加 headers 信息,不然获取不了。 f = open(ressult[num]['name'] + ".mp3", 'wb') # 以二进制的形式写入文件中 f.write(response) f.close() print("下载完成.\n\r") else: print("你输入的数字不在歌曲列表范围,请重新输入") else: print("请输入正确的歌曲序号") if __name__ == "__main__": search_name = input("请输入你想要在网易云音乐中搜索的单曲:") headers = { 'Cookie': 'appver=1.5.0.75771;', 'Referer': 'http://music.163.com/' } first_param = r'{"hlpretag":"<span class=\"s-fc7\">","hlposttag":"</span>","s":"' + search_name + r'","type":"1","offset":"0","total":"true","limit":"30","csrf_token":""}' second_param = "010001" third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7" forth_param = "0CoJUm6Qyw8W8jud" url = "https://music.163.com/weapi/cloudsearch/get/web?csrf_token=" params = get_params() encSeckey = get_encSecKey() ressult_b = get_json(url, params, encSeckey) ressult = handle_json(ressult_b) # 过滤出需要的数据,存入到result中 print("%3s %-35s %-20s %-20s " %("序号", " 歌名", "歌手", "专辑") ) for i in range(len(ressult)): print("%3s %-35s %-20s %-20s " %(ressult[i]["num"], ressult[i]["name"], ressult[i]["singer"], ressult[i]["song_sheet"])) num = input("请输入你想要下载歌曲的序号/please input the num you want to download:") load_song(num, ressult) # 下载歌曲

 浙公网安备 33010602011771号
浙公网安备 33010602011771号