社招前端一面必会vue面试题
DIFF算法的原理
在新老虚拟DOM对比时:
- 首先,对比节点本身,判断是否为同一节点,如果不为相同节点,则删除该节点重新创建节点进行替换
- 如果为相同节点,进行patchVnode,判断如何对该节点的子节点进行处理,先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
- 比较如果都有子节点,则进行updateChildren,判断如何对这些新老节点的子节点进行操作(diff核心)。
- 匹配时,找到相同的子节点,递归比较子节点
在diff中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从O(n3)降低值O(n),也就是说,只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
vuex是什么?怎么使用?哪种功能场景使用它?
Vuex是一个专为Vue.js应用程序开发的状态管理模式。vuex就是一个仓库,仓库里放了很多对象。其中state就是数据源存放地,对应于一般 vue 对象里面的data里面存放的数据是响应式的,vue组件从store读取数据,若是store中的数据发生改变,依赖这相数据的组件也会发生更新它通过mapState把全局的state和getters映射到当前组件的computed计算属性
vuex一般用于中大型web单页应用中对应用的状态进行管理,对于一些组件间关系较为简单的小型应用,使用vuex的必要性不是很大,因为完全可以用组件prop属性或者事件来完成父子组件之间的通信,vuex更多地用于解决跨组件通信以及作为数据中心集中式存储数据。- 使用
Vuex解决非父子组件之间通信问题vuex是通过将state作为数据中心、各个组件共享state实现跨组件通信的,此时的数据完全独立于组件,因此将组件间共享的数据置于State中能有效解决多层级组件嵌套的跨组件通信问题
vuex的State在单页应用的开发中本身具有一个“数据库”的作用,可以将组件中用到的数据存储在State中,并在Action中封装数据读写的逻辑。这时候存在一个问题,一般什么样的数据会放在State中呢? 目前主要有两种数据会使用vuex进行管理:
- 组件之间全局共享的数据
- 通过后端异步请求的数据
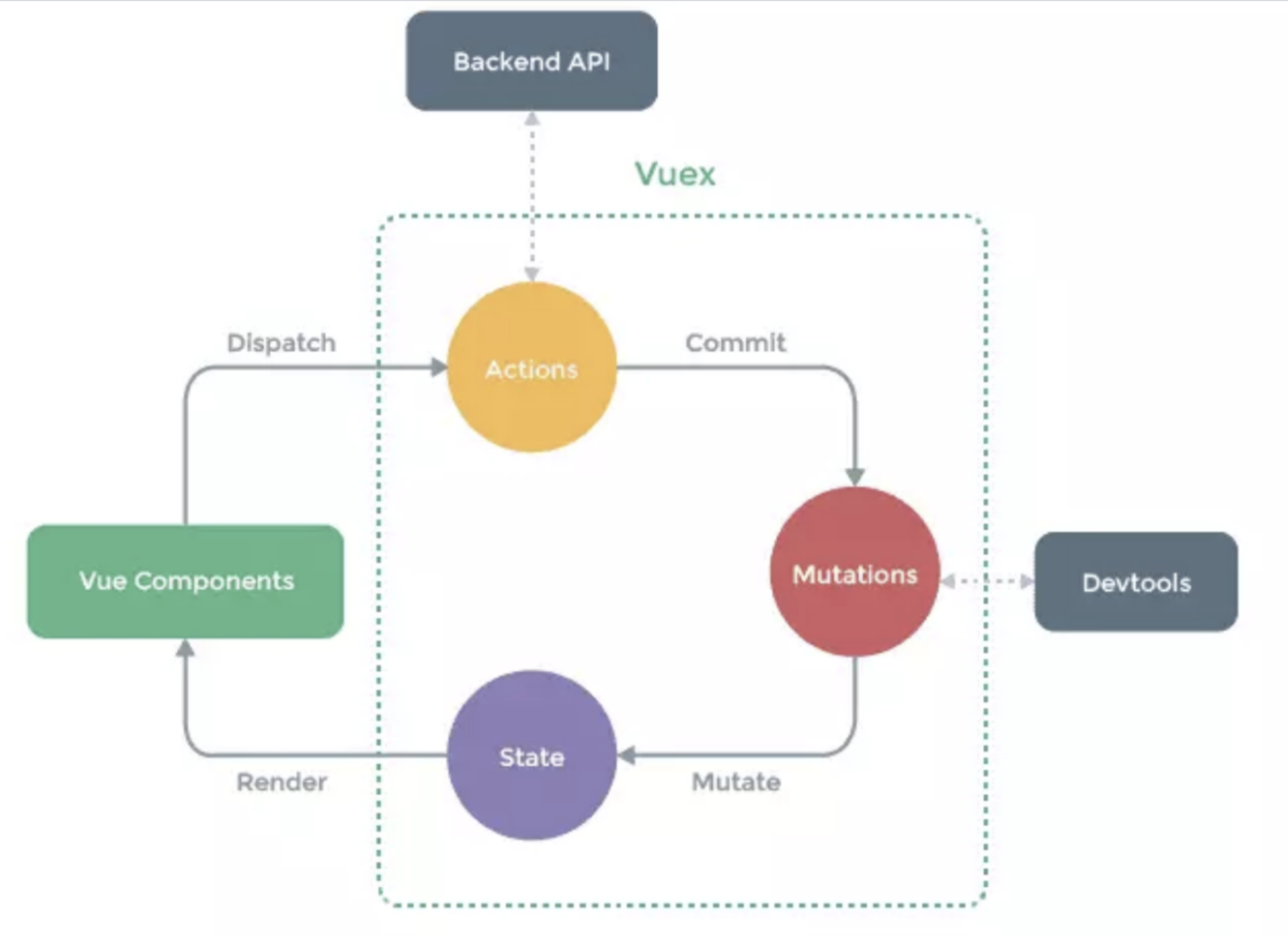
包括以下几个模块
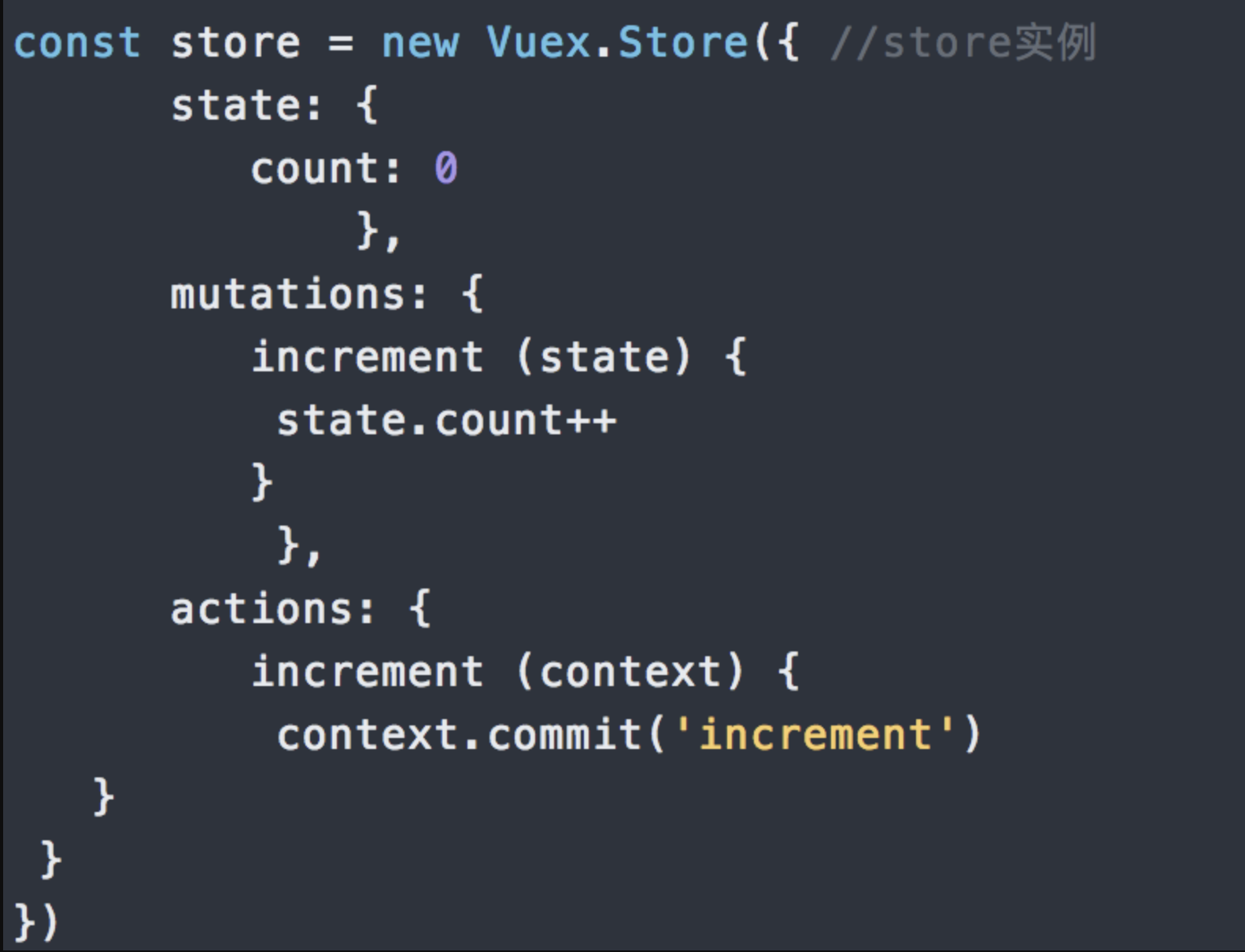
state:Vuex使用单一状态树,即每个应用将仅仅包含一个store实例。里面存放的数据是响应式的,vue组件从store读取数据,若是store中的数据发生改变,依赖这相数据的组件也会发生更新。它通过mapState把全局的state和getters映射到当前组件的computed计算属性mutations:更改Vuex的store中的状态的唯一方法是提交mutationgetters:getter可以对state进行计算操作,它就是store的计算属性虽然在组件内也可以做计算属性,但是getters可以在多给件之间复用如果一个状态只在一个组件内使用,是可以不用gettersaction:action类似于muation, 不同在于:action提交的是mutation,而不是直接变更状态action可以包含任意异步操作modules:面对复杂的应用程序,当管理的状态比较多时;我们需要将vuex的store对象分割成模块(modules)
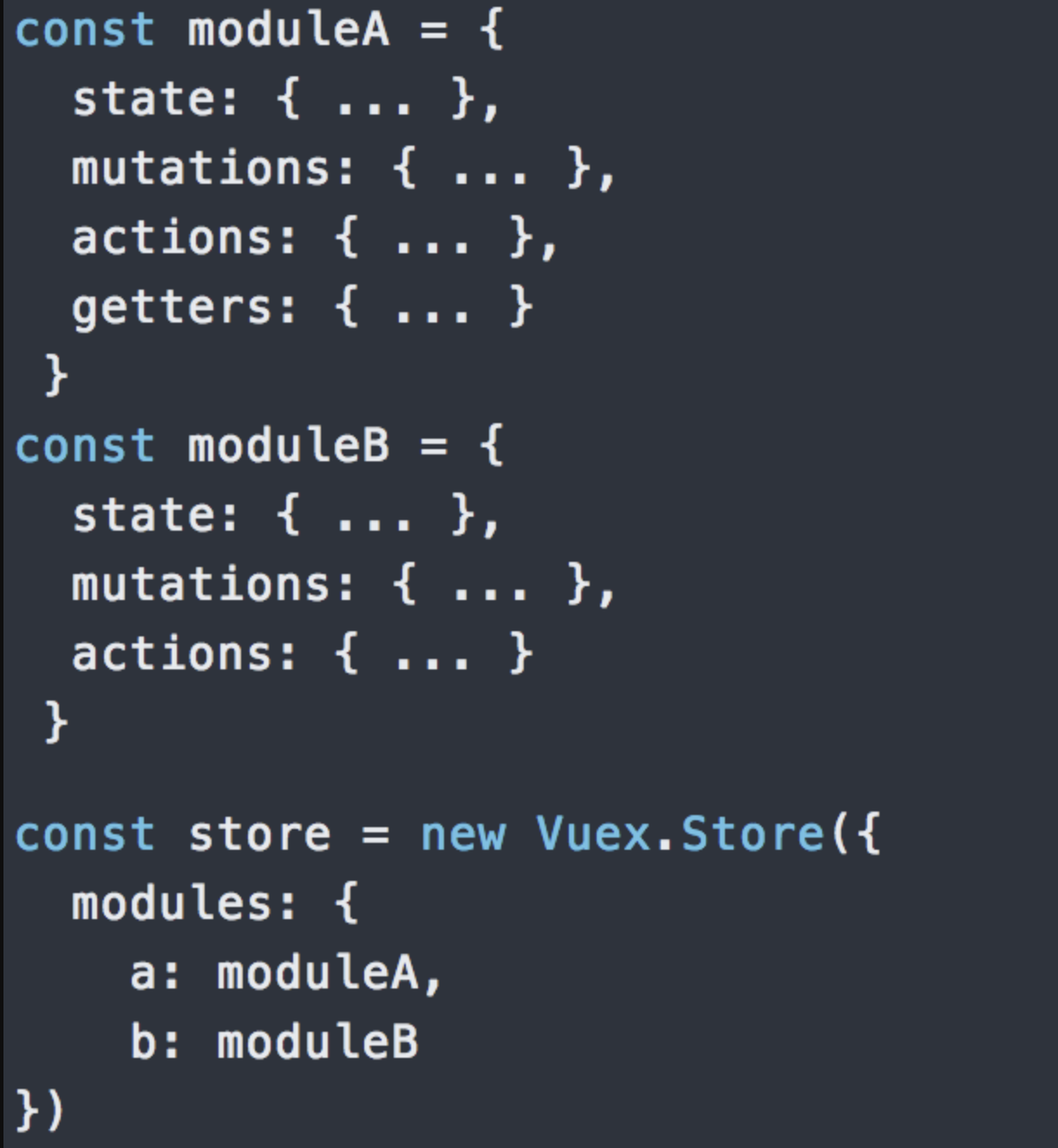
modules:项目特别复杂的时候,可以让每一个模块拥有自己的state、mutation、action、getters,使得结构非常清晰,方便管理
回答范例
思路
- 给定义
- 必要性阐述
- 何时使用
- 拓展:一些个人思考、实践经验等
回答范例
Vuex是一个专为Vue.js应用开发的 状态管理模式 + 库 。它采用集中式存储,管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。- 我们期待以一种简单的“单向数据流”的方式管理应用,即状态 -> 视图 -> 操作单向循环的方式。但当我们的应用遇到多个组件共享状态时,比如:多个视图依赖于同一状态或者来自不同视图的行为需要变更同一状态。此时单向数据流的简洁性很容易被破坏。因此,我们有必要把组件的共享状态抽取出来,以一个全局单例模式管理。通过定义和隔离状态管理中的各种概念并通过强制规则维持视图和状态间的独立性,我们的代码将会变得更结构化且易维护。这是
vuex存在的必要性,它和react生态中的redux之类是一个概念 Vuex解决状态管理的同时引入了不少概念:例如state、mutation、action等,是否需要引入还需要根据应用的实际情况衡量一下:如果不打算开发大型单页应用,使用Vuex反而是繁琐冗余的,一个简单的store模式就足够了。但是,如果要构建一个中大型单页应用,Vuex基本是标配。- 我在使用
vuex过程中感受到一些等
可能的追问
vuex有什么缺点吗?你在开发过程中有遇到什么问题吗?
- 刷新浏览器,
vuex中的state会重新变为初始状态。解决方案-插件vuex-persistedstate
action和mutation的区别是什么?为什么要区分它们?
action中处理异步,mutation不可以mutation做原子操作action可以整合多个mutation的集合mutation是同步更新数据(内部会进行是否为异步方式更新数据的检测)$watch严格模式下会报错action异步操作,可以获取数据后调佣mutation提交最终数据
- 流程顺序:“相应视图—>修改State”拆分成两部分,视图触发
Action,Action再触发Mutation`。 - 基于流程顺序,二者扮演不同的角色:
Mutation:专注于修改State,理论上是修改State的唯一途径。Action:业务代码、异步请求 - 角色不同,二者有不同的限制:
Mutation:必须同步执行。Action:可以异步,但不能直接操作State
组件中写name属性的好处
可以标识组件的具体名称方便调试和查找对应属性
// 源码位置 src/core/global-api/extend.js
// enable recursive self-lookup
if (name) {
Sub.options.components[name] = Sub // 记录自己 在组件中递归自己 -> jsx
}
实现双向绑定
我们还是以Vue为例,先来看看Vue中的双向绑定流程是什么的
new Vue()首先执行初始化,对data执行响应化处理,这个过程发生Observe中- 同时对模板执行编译,找到其中动态绑定的数据,从
data中获取并初始化视图,这个过程发生在Compile中 - 同时定义⼀个更新函数和
Watcher,将来对应数据变化时Watcher会调用更新函数 - 由于
data的某个key在⼀个视图中可能出现多次,所以每个key都需要⼀个管家Dep来管理多个Watcher - 将来data中数据⼀旦发生变化,会首先找到对应的
Dep,通知所有Watcher执行更新函数
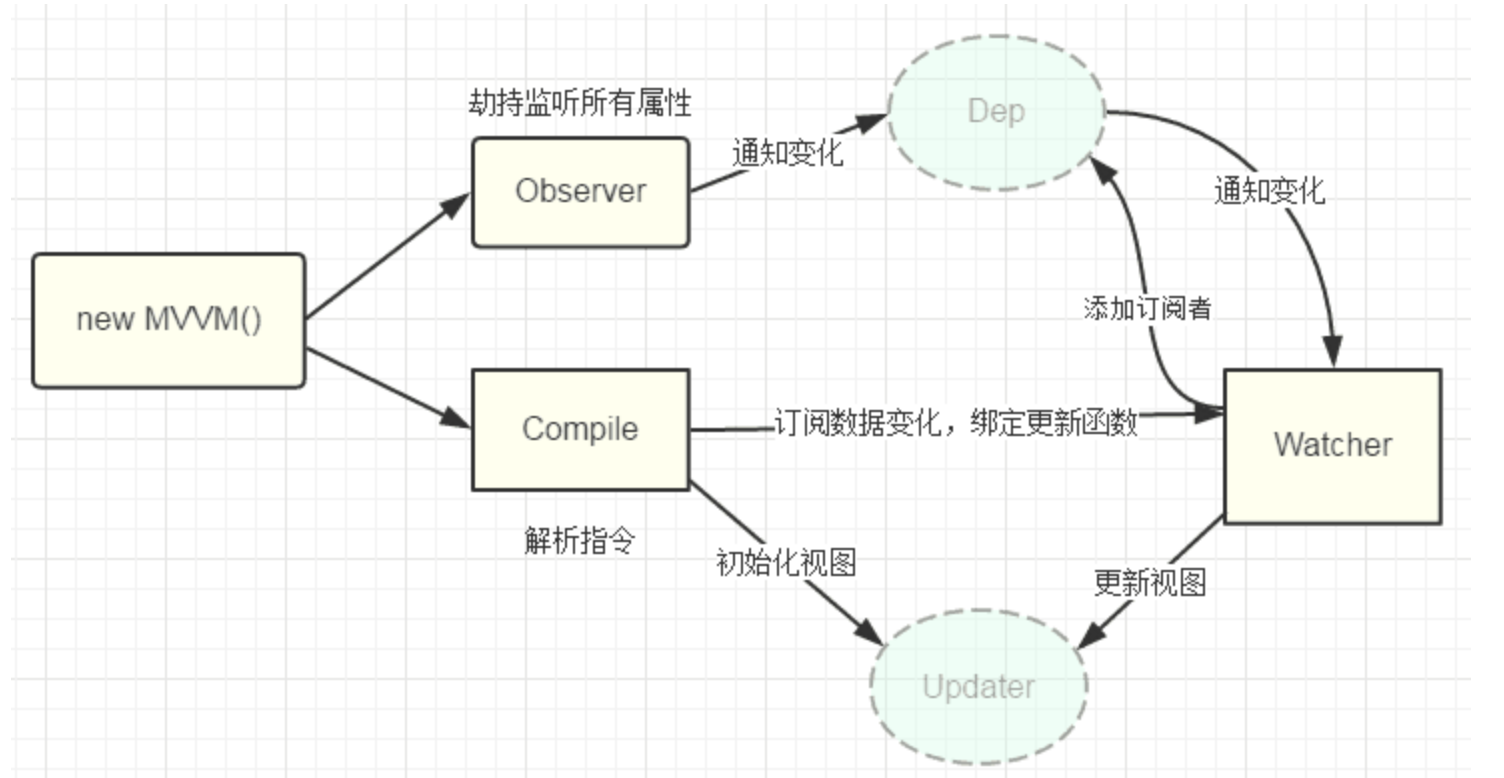
流程图如下:
先来一个构造函数:执行初始化,对data执行响应化处理
class Vue {
constructor(options) {
this.$options = options;
this.$data = options.data;
// 对data选项做响应式处理
observe(this.$data);
// 代理data到vm上
proxy(this);
// 执行编译
new Compile(options.el, this);
}
}
对data选项执行响应化具体操作
function observe(obj) {
if (typeof obj !== "object" || obj == null) {
return;
}
new Observer(obj);
}
class Observer {
constructor(value) {
this.value = value;
this.walk(value);
}
walk(obj) {
Object.keys(obj).forEach((key) => {
defineReactive(obj, key, obj[key]);
});
}
}
编译Compile
对每个元素节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数
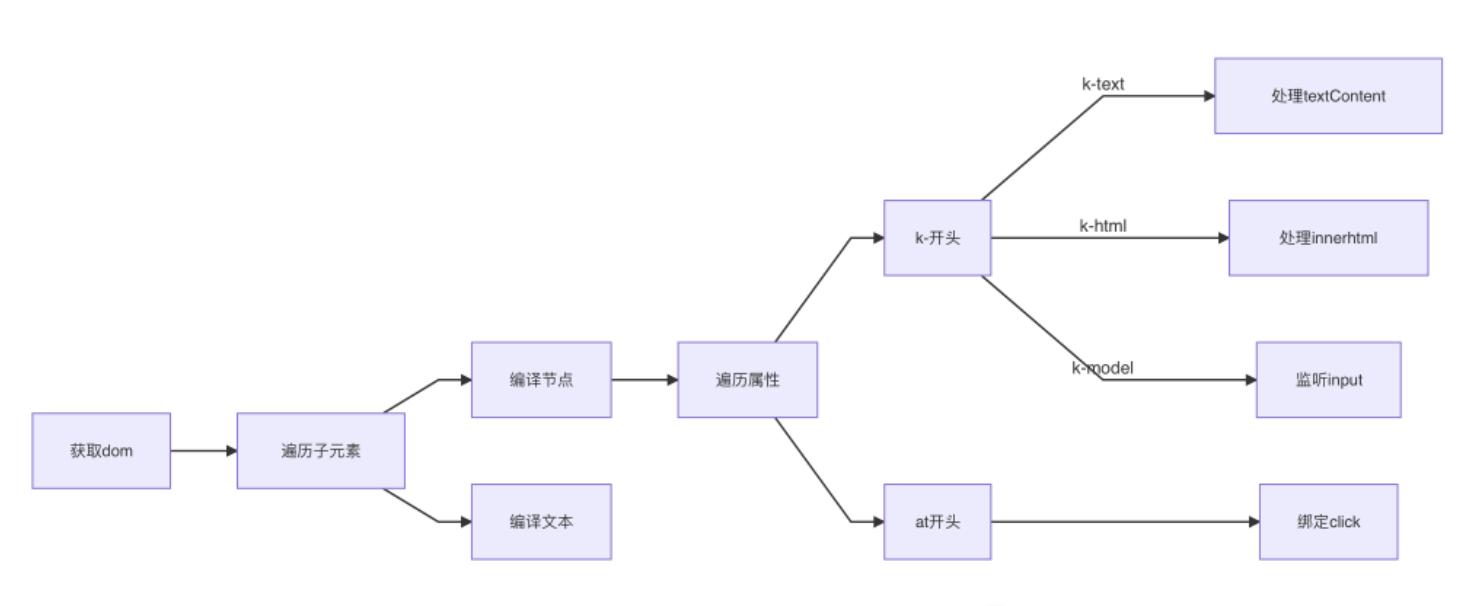
class Compile {
constructor(el, vm) {
this.$vm = vm;
this.$el = document.querySelector(el); // 获取dom
if (this.$el) {
this.compile(this.$el);
}
}
compile(el) {
const childNodes = el.childNodes;
Array.from(childNodes).forEach((node) => { // 遍历子元素
if (this.isElement(node)) { // 判断是否为节点
console.log("编译元素" + node.nodeName);
} else if (this.isInterpolation(node)) {
console.log("编译插值⽂本" + node.textContent); // 判断是否为插值文本 {{}}
}
if (node.childNodes && node.childNodes.length > 0) { // 判断是否有子元素
this.compile(node); // 对子元素进行递归遍历
}
});
}
isElement(node) {
return node.nodeType == 1;
}
isInterpolation(node) {
return node.nodeType == 3 && /\{\{(.*)\}\}/.test(node.textContent);
}
}
依赖收集
视图中会用到data中某key,这称为依赖。同⼀个key可能出现多次,每次都需要收集出来用⼀个Watcher来维护它们,此过程称为依赖收集多个Watcher需要⼀个Dep来管理,需要更新时由Dep统⼀通知
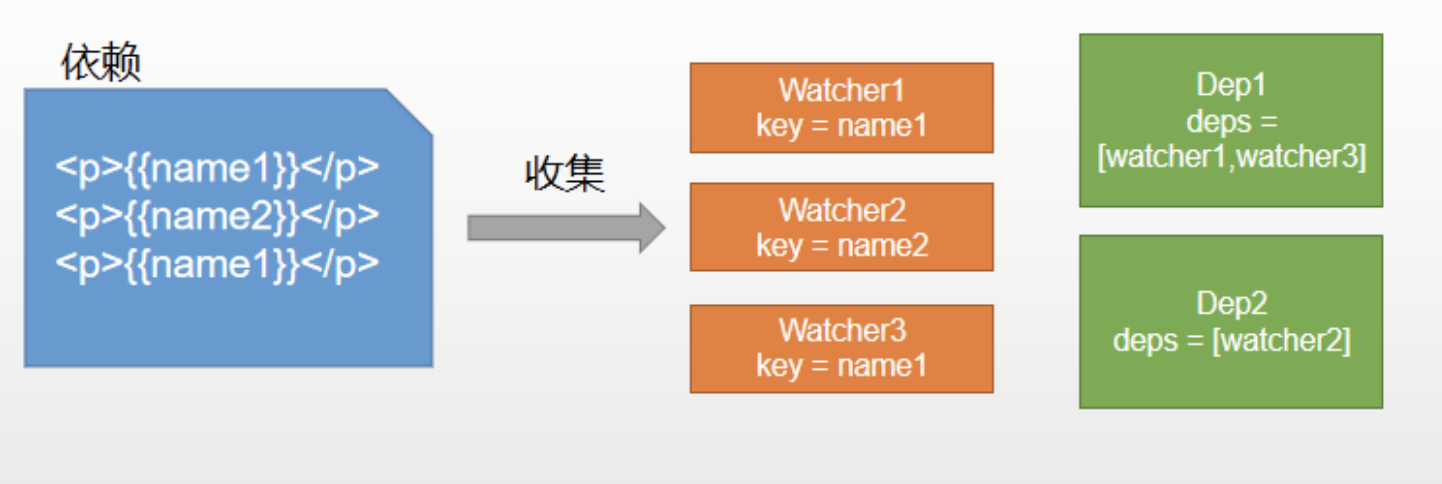
实现思路
defineReactive时为每⼀个key创建⼀个Dep实例- 初始化视图时读取某个
key,例如name1,创建⼀个watcher1 - 由于触发
name1的getter方法,便将watcher1添加到name1对应的Dep中 - 当
name1更新,setter触发时,便可通过对应Dep通知其管理所有Watcher更新
// 负责更新视图
class Watcher {
constructor(vm, key, updater) {
this.vm = vm
this.key = key
this.updaterFn = updater
// 创建实例时,把当前实例指定到Dep.target静态属性上
Dep.target = this
// 读一下key,触发get
vm[key]
// 置空
Dep.target = null
}
// 未来执行dom更新函数,由dep调用的
update() {
this.updaterFn.call(this.vm, this.vm[this.key])
}
}
声明Dep
class Dep {
constructor() {
this.deps = []; // 依赖管理
}
addDep(dep) {
this.deps.push(dep);
}
notify() {
this.deps.forEach((dep) => dep.update());
}
}
创建watcher时触发getter
class Watcher {
constructor(vm, key, updateFn) {
Dep.target = this;
this.vm[this.key];
Dep.target = null;
}
}
依赖收集,创建Dep实例
function defineReactive(obj, key, val) {
this.observe(val);
const dep = new Dep();
Object.defineProperty(obj, key, {
get() {
Dep.target && dep.addDep(Dep.target);// Dep.target也就是Watcher实例
return val;
},
set(newVal) {
if (newVal === val) return;
dep.notify(); // 通知dep执行更新方法
},
});
}
watch 原理
watch 本质上是为每个监听属性 setter 创建了一个 watcher,当被监听的属性更新时,调用传入的回调函数。常见的配置选项有 deep 和 immediate,对应原理如下
deep:深度监听对象,为对象的每一个属性创建一个watcher,从而确保对象的每一个属性更新时都会触发传入的回调函数。主要原因在于对象属于引用类型,单个属性的更新并不会触发对象setter,因此引入deep能够很好地解决监听对象的问题。同时也会引入判断机制,确保在多个属性更新时回调函数仅触发一次,避免性能浪费。immediate:在初始化时直接调用回调函数,可以通过在created阶段手动调用回调函数实现相同的效果
Vue computed 实现
- 建立与其他属性(如:
data、Store)的联系; - 属性改变后,通知计算属性重新计算
实现时,主要如下
- 初始化
data, 使用Object.defineProperty把这些属性全部转为getter/setter。 - 初始化
computed, 遍历computed里的每个属性,每个computed属性都是一个watch实例。每个属性提供的函数作为属性的getter,使用Object.defineProperty转化。 Object.defineProperty getter依赖收集。用于依赖发生变化时,触发属性重新计算。- 若出现当前
computed计算属性嵌套其他computed计算属性时,先进行其他的依赖收集
参考 前端进阶面试题详细解答
keep-alive 使用场景和原理
keep-alive是Vue内置的一个组件, 可以实现组件缓存 ,当组件切换时不会对当前组件进行卸载。 一般结合路由和动态组件一起使用 ,用于缓存组件- 提供
include和exclude属性, 允许组件有条件的进行缓存 。两者都支持字符串或正则表达式,include表示只有名称匹配的组件会被缓存,exclude表示任何名称匹配的组件都不会被缓存 ,其中exclude的优先级比include高 - 对应两个钩子函数
activated和deactivated,当组件被激活时,触发钩子函数activated,当组件被移除时,触发钩子函数deactivated keep-alive的中还运用了LRU(最近最少使用) 算法,选择最近最久未使用的组件予以淘汰
<keep-alive></keep-alive>包裹动态组件时,会缓存不活动的组件实例,主要用于保留组件状态或避免重新渲染- 比如有一个列表和一个详情,那么用户就会经常执行打开详情=>返回列表=>打开详情…这样的话列表和详情都是一个频率很高的页面,那么就可以对列表组件使用
<keep-alive></keep-alive>进行缓存,这样用户每次返回列表的时候,都能从缓存中快速渲染,而不是重新渲染
关于keep-alive的基本用法
<keep-alive>
<component :is="view"></component>
</keep-alive>
使用includes和exclude:
<keep-alive include="a,b">
<component :is="view"></component>
</keep-alive>
<!-- 正则表达式 (使用 `v-bind`) -->
<keep-alive :include="/a|b/">
<component :is="view"></component>
</keep-alive>
<!-- 数组 (使用 `v-bind`) -->
<keep-alive :include="['a', 'b']">
<component :is="view"></component>
</keep-alive>
匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称 (父组件 components 选项的键值),匿名组件不能被匹配
设置了 keep-alive 缓存的组件,会多出两个生命周期钩子(activated与deactivated):
- 首次进入组件时:
beforeRouteEnter>beforeCreate>created>mounted>activated> ... ... >beforeRouteLeave>deactivated - 再次进入组件时:
beforeRouteEnter>activated> ... ... >beforeRouteLeave>deactivated
使用场景
使用原则:当我们在某些场景下不需要让页面重新加载时我们可以使用keepalive
举个栗子:
当我们从首页–>列表页–>商详页–>再返回,这时候列表页应该是需要keep-alive
从首页–>列表页–>商详页–>返回到列表页(需要缓存)–>返回到首页(需要缓存)–>再次进入列表页(不需要缓存),这时候可以按需来控制页面的keep-alive
在路由中设置keepAlive属性判断是否需要缓存
{
path: 'list',
name: 'itemList', // 列表页
component (resolve) {
require(['@/pages/item/list'], resolve)
},
meta: {
keepAlive: true,
title: '列表页'
}
}
使用<keep-alive>
<div id="app" class='wrapper'>
<keep-alive>
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive"></router-view>
</div>
思考题:缓存后如何获取数据
解决方案可以有以下两种:
beforeRouteEnter:每次组件渲染的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
actived:在keep-alive缓存的组件被激活的时候,都会执行actived钩子
// 注意:服务器端渲染期间avtived不被调用
activated(){
this.getData() // 获取数据
},
扩展补充:LRU 算法是什么?
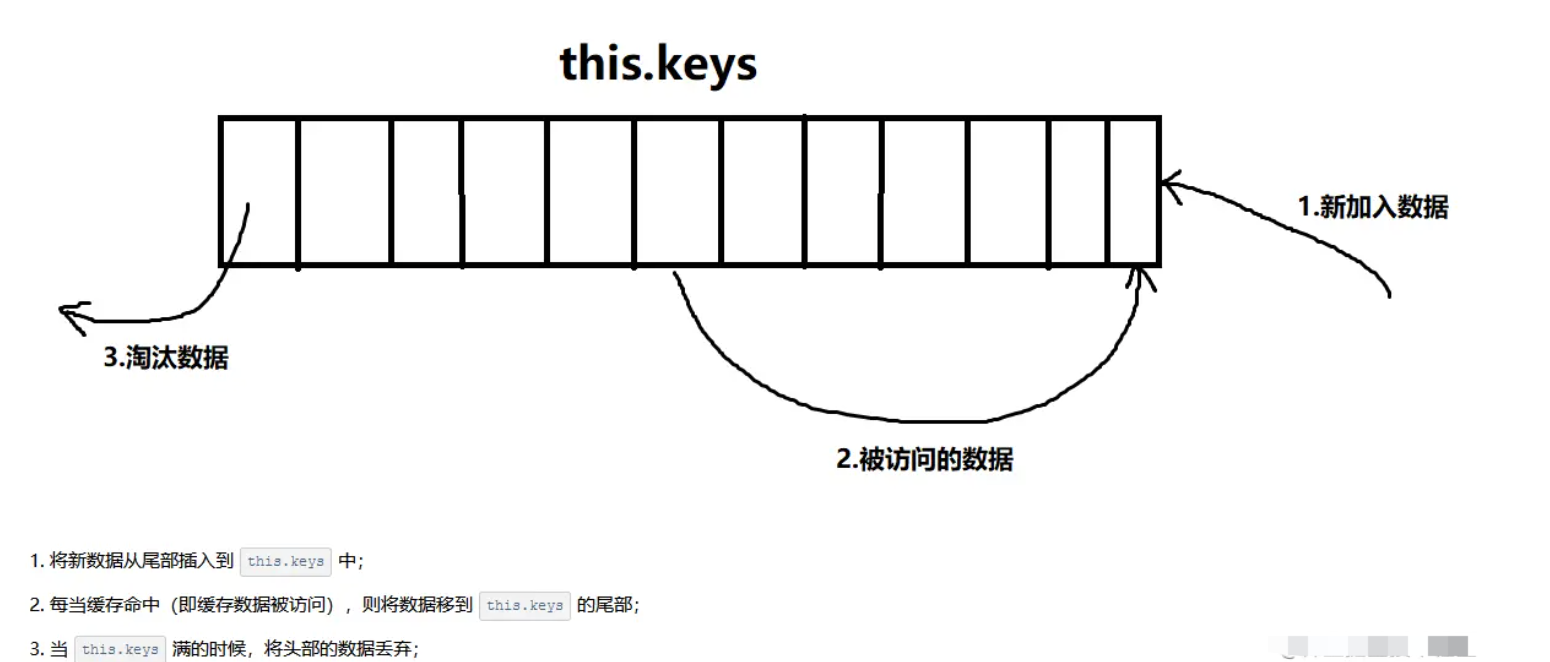
LRU的核心思想是如果数据最近被访问过,那么将来被访问的几率也更高,所以我们将命中缓存的组件key重新插入到this.keys的尾部,这样一来,this.keys中越往头部的数据即将来被访问几率越低,所以当缓存数量达到最大值时,我们就删除将来被访问几率最低的数据,即this.keys中第一个缓存的组件
相关代码
keep-alive是vue中内置的一个组件
源码位置:src/core/components/keep-alive.js
export default {
name: "keep-alive",
abstract: true, //抽象组件
props: {
include: patternTypes, //要缓存的组件
exclude: patternTypes, //要排除的组件
max: [String, Number], //最大缓存数
},
created() {
this.cache = Object.create(null); //缓存对象 {a:vNode,b:vNode}
this.keys = []; //缓存组件的key集合 [a,b]
},
destroyed() {
for (const key in this.cache) {
pruneCacheEntry(this.cache, key, this.keys);
}
},
mounted() {
//动态监听include exclude
this.$watch("include", (val) => {
pruneCache(this, (name) => matches(val, name));
});
this.$watch("exclude", (val) => {
pruneCache(this, (name) => !matches(val, name));
});
},
render() {
const slot = this.$slots.default; //获取包裹的插槽默认值 获取默认插槽中的第一个组件节点
const vnode: VNode = getFirstComponentChild(slot); //获取第一个子组件
// 获取该组件节点的componentOptions
const componentOptions: ?VNodeComponentOptions =
vnode && vnode.componentOptions;
if (componentOptions) {
// 获取该组件节点的名称,优先获取组件的name字段,如果name不存在则获取组件的tag
const name: ?string = getComponentName(componentOptions);
const { include, exclude } = this;
// 不走缓存 如果name不在inlcude中或者存在于exlude中则表示不缓存,直接返回vnode
if (
// not included 不包含
(include && (!name || !matches(include, name))) ||
// excluded 排除里面
(exclude && name && matches(exclude, name))
) {
//返回虚拟节点
return vnode;
}
const { cache, keys } = this;
// 获取组件的key值
const key: ?string =
vnode.key == null
? // same constructor may get registered as different local components
// so cid alone is not enough (#3269)
componentOptions.Ctor.cid +
(componentOptions.tag ? `::${componentOptions.tag}` : "")
: vnode.key;
// 拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存
if (cache[key]) {
//通过key 找到缓存 获取实例
vnode.componentInstance = cache[key].componentInstance;
// make current key freshest
remove(keys, key); //通过LRU算法把数组里面的key删掉
keys.push(key); //把它放在数组末尾
} else {
cache[key] = vnode; //没找到就换存下来
keys.push(key); //把它放在数组末尾
// prune oldest entry //如果超过最大值就把数组第0项删掉
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode);
}
}
vnode.data.keepAlive = true; //标记虚拟节点已经被缓存
}
// 返回虚拟节点
return vnode || (slot && slot[0]);
},
};
可以看到该组件没有template,而是用了render,在组件渲染的时候会自动执行render函数
this.cache是一个对象,用来存储需要缓存的组件,它将以如下形式存储:
this.cache = {
'key1':'组件1',
'key2':'组件2',
// ...
}
在组件销毁的时候执行pruneCacheEntry函数
function pruneCacheEntry (
cache: VNodeCache,
key: string,
keys: Array<string>,
current?: VNode
) {
const cached = cache[key]
/* 判断当前没有处于被渲染状态的组件,将其销毁*/
if (cached && (!current || cached.tag !== current.tag)) {
cached.componentInstance.$destroy()
}
cache[key] = null
remove(keys, key)
}
在mounted钩子函数中观测 include 和 exclude 的变化,如下:
mounted () {
this.$watch('include', val => {
pruneCache(this, name => matches(val, name))
})
this.$watch('exclude', val => {
pruneCache(this, name => !matches(val, name))
})
}
如果include 或exclude 发生了变化,即表示定义需要缓存的组件的规则或者不需要缓存的组件的规则发生了变化,那么就执行pruneCache函数,函数如下
function pruneCache (keepAliveInstance, filter) {
const { cache, keys, _vnode } = keepAliveInstance
for (const key in cache) {
const cachedNode = cache[key]
if (cachedNode) {
const name = getComponentName(cachedNode.componentOptions)
if (name && !filter(name)) {
pruneCacheEntry(cache, key, keys, _vnode)
}
}
}
}
在该函数内对this.cache对象进行遍历,取出每一项的name值,用其与新的缓存规则进行匹配,如果匹配不上,则表示在新的缓存规则下该组件已经不需要被缓存,则调用pruneCacheEntry函数将其从this.cache对象剔除即可
关于keep-alive的最强大缓存功能是在render函数中实现
首先获取组件的key值:
const key = vnode.key == null?
componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '')
: vnode.key
拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存,如下:
/* 如果命中缓存,则直接从缓存中拿 vnode 的组件实例 */
if (cache[key]) {
vnode.componentInstance = cache[key].componentInstance
/* 调整该组件key的顺序,将其从原来的地方删掉并重新放在最后一个 */
remove(keys, key)
keys.push(key)
}
直接从缓存中拿 vnode 的组件实例,此时重新调整该组件key的顺序,将其从原来的地方删掉并重新放在this.keys中最后一个
this.cache对象中没有该key值的情况,如下:
/* 如果没有命中缓存,则将其设置进缓存 */
else {
cache[key] = vnode
keys.push(key)
/* 如果配置了max并且缓存的长度超过了this.max,则从缓存中删除第一个 */
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode)
}
}
表明该组件还没有被缓存过,则以该组件的key为键,组件vnode为值,将其存入this.cache中,并且把key存入this.keys中
此时再判断this.keys中缓存组件的数量是否超过了设置的最大缓存数量值this.max,如果超过了,则把第一个缓存组件删掉
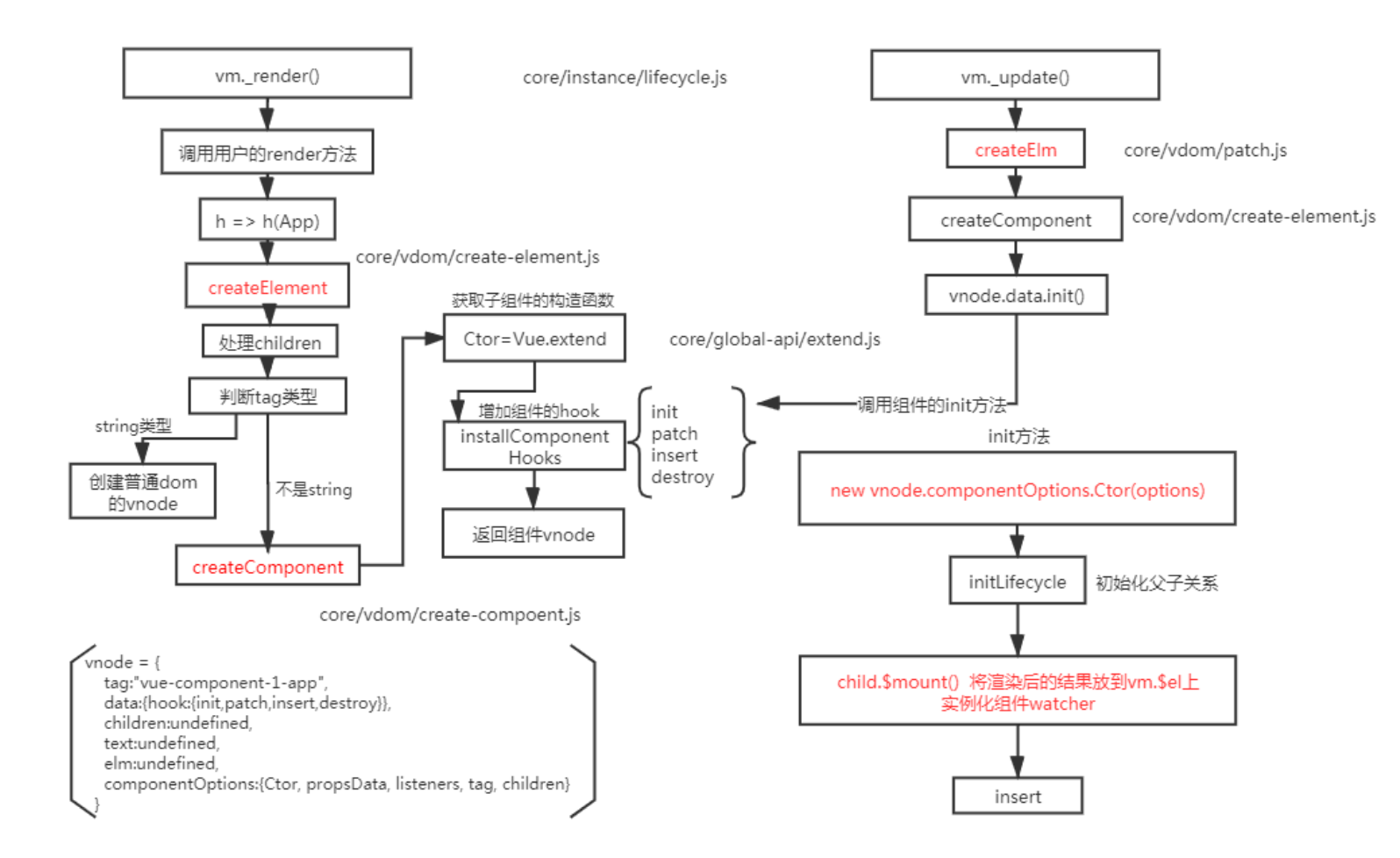
Vue组件渲染和更新过程
渲染组件时,会通过
Vue.extend方法构建子组件的构造函数,并进行实例化。最终手动调用$mount()进行挂载。更新组件时会进行patchVnode流程,核心就是diff算法
Vue中如何扩展一个组件
此题属于实践题,考察大家对vue常用api使用熟练度,答题时不仅要列出这些解决方案,同时最好说出他们异同
答题思路:
- 按照逻辑扩展和内容扩展来列举
- 逻辑扩展有:
mixins、extends、composition api - 内容扩展有
slots;
- 逻辑扩展有:
- 分别说出他们使用方法、场景差异和问题。
- 作为扩展,还可以说说
vue3中新引入的composition api带来的变化
回答范例:
- 常见的组件扩展方法有:
mixins,slots,extends等 - 混入
mixins是分发Vue组件中可复用功能的非常灵活的方式。混入对象可以包含任意组件选项。当组件使用混入对象时,所有混入对象的选项将被混入该组件本身的选项
// 复用代码:它是一个配置对象,选项和组件里面一样
const mymixin = {
methods: {
dosomething(){}
}
}
// 全局混入:将混入对象传入
Vue.mixin(mymixin)
// 局部混入:做数组项设置到mixins选项,仅作用于当前组件
const Comp = {
mixins: [mymixin]
}
- 插槽主要用于
vue组件中的内容分发,也可以用于组件扩展
子组件Child
<div>
<slot>这个内容会被父组件传递的内容替换</slot>
</div>
父组件Parent
<div>
<Child>来自父组件内容</Child>
</div>
如果要精确分发到不同位置可以使用具名插槽,如果要使用子组件中的数据可以使用作用域插槽
- 组件选项中还有一个不太常用的选项
extends,也可以起到扩展组件的目的
// 扩展对象
const myextends = {
methods: {
dosomething(){}
}
}
// 组件扩展:做数组项设置到extends选项,仅作用于当前组件
// 跟混入的不同是它只能扩展单个对象
// 另外如果和混入发生冲突,该选项优先级较高,优先起作用
const Comp = {
extends: myextends
}
- 混入的数据和方法不能明确判断来源且可能和当前组件内变量产生命名冲突,
vue3中引入的composition api,可以很好解决这些问题,利用独立出来的响应式模块可以很方便的编写独立逻辑并提供响应式的数据,然后在setup选项中组合使用,增强代码的可读性和维护性。例如
// 复用逻辑1
function useXX() {}
// 复用逻辑2
function useYY() {}
// 逻辑组合
const Comp = {
setup() {
const {xx} = useXX()
const {yy} = useYY()
return {xx, yy}
}
}
异步组件是什么?使用场景有哪些?
分析
因为异步路由的存在,我们使用异步组件的次数比较少,因此还是有必要两者的不同。
体验
大型应用中,我们需要分割应用为更小的块,并且在需要组件时再加载它们
import { defineAsyncComponent } from 'vue'
// defineAsyncComponent定义异步组件,返回一个包装组件。包装组件根据加载器的状态决定渲染什么内容
const AsyncComp = defineAsyncComponent(() => {
// 加载函数返回Promise
return new Promise((resolve, reject) => {
// ...可以从服务器加载组件
resolve(/* loaded component */)
})
})
// 借助打包工具实现ES模块动态导入
const AsyncComp = defineAsyncComponent(() =>
import('./components/MyComponent.vue')
)
回答范例
- 在大型应用中,我们需要分割应用为更小的块,并且在需要组件时再加载它们。
- 我们不仅可以在路由切换时懒加载组件,还可以在页面组件中继续使用异步组件,从而实现更细的分割粒度。
- 使用异步组件最简单的方式是直接给
defineAsyncComponent指定一个loader函数,结合ES模块动态导入函数import可以快速实现。我们甚至可以指定loadingComponent和errorComponent选项从而给用户一个很好的加载反馈。另外Vue3中还可以结合Suspense组件使用异步组件。 - 异步组件容易和路由懒加载混淆,实际上不是一个东西。异步组件不能被用于定义懒加载路由上,处理它的是
vue框架,处理路由组件加载的是vue-router。但是可以在懒加载的路由组件中使用异步组件
Vue中修饰符.sync与v-model的区别
sync的作用
.sync修饰符可以实现父子组件之间的双向绑定,并且可以实现子组件同步修改父组件的值,相比较与v-model来说,sync修饰符就简单很多了- 一个组件上可以有多个
.sync修饰符
<!-- 正常父传子 -->
<Son :a="num" :b="num2" />
<!-- 加上sync之后的父传子 -->
<Son :a.sync="num" :b.sync="num2" />
<!-- 它等价于 -->
<Son
:a="num"
:b="num2"
@update:a="val=>num=val"
@update:b="val=>num2=val"
/>
<!-- 相当于多了一个事件监听,事件名是update:a, -->
<!-- 回调函数中,会把接收到的值赋值给属性绑定的数据项中。 -->
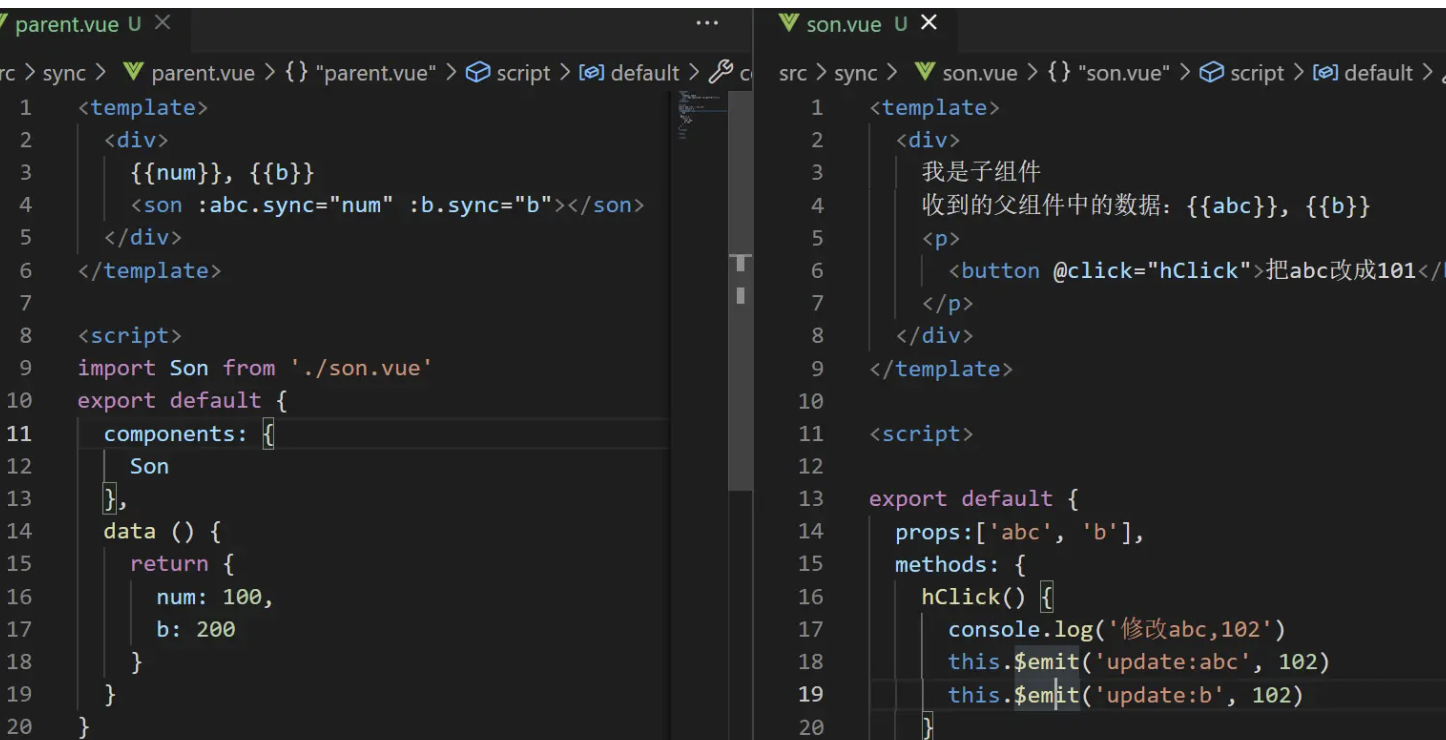
v-model的工作原理
<com1 v-model="num"></com1>
<!-- 等价于 -->
<com1 :value="num" @input="(val)=>num=val"></com1>
- 相同点
- 都是语法糖,都可以实现父子组件中的数据的双向通信
- 区别点
- 格式不同:
v-model="num",:num.sync="num" v-model:@input + value:num.sync:@update:numv-model只能用一次;.sync可以有多个
- 格式不同:
函数式组件优势和原理
函数组件的特点
- 函数式组件需要在声明组件是指定
functional:true - 不需要实例化,所以没有
this,this通过render函数的第二个参数context来代替 - 没有生命周期钩子函数,不能使用计算属性,
watch - 不能通过
$emit对外暴露事件,调用事件只能通过context.listeners.click的方式调用外部传入的事件 - 因为函数式组件是没有实例化的,所以在外部通过
ref去引用组件时,实际引用的是HTMLElement - 函数式组件的
props可以不用显示声明,所以没有在props里面声明的属性都会被自动隐式解析为prop,而普通组件所有未声明的属性都解析到$attrs里面,并自动挂载到组件根元素上面(可以通过inheritAttrs属性禁止)
优点
- 由于函数式组件不需要实例化,无状态,没有生命周期,所以渲染性能要好于普通组件
- 函数式组件结构比较简单,代码结构更清晰
使用场景:
- 一个简单的展示组件,作为容器组件使用 比如
router-view就是一个函数式组件 - “高阶组件”——用于接收一个组件作为参数,返回一个被包装过的组件
例子
Vue.component('functional',{ // 构造函数产生虚拟节点的
functional:true, // 函数式组件 // data={attrs:{}}
render(h){
return h('div','test')
}
})
const vm = new Vue({
el: '#app'
})
源码相关
// functional component
if (isTrue(Ctor.options.functional)) { // 带有functional的属性的就是函数式组件
return createFunctionalComponent(Ctor, propsData, data, context, children)
}
// extract listeners, since these needs to be treated as
// child component listeners instead of DOM listeners
const listeners = data.on // 处理事件
// replace with listeners with .native modifier
// so it gets processed during parent component patch.
data.on = data.nativeOn // 处理原生事件
// install component management hooks onto the placeholder node
installComponentHooks(data) // 安装组件相关钩子 (函数式组件没有调用此方法,从而性能高于普通组件)
Vue中v-html会导致哪些问题
- 可能会导致
xss攻击 v-html会替换掉标签内部的子元素
let template = require('vue-template-compiler');
let r = template.compile(`<div v-html="'<span>hello</span>'"></div>`)
// with(this){return _c('div',{domProps: {"innerHTML":_s('<span>hello</span>')}})}
console.log(r.render);
// _c 定义在core/instance/render.js
// _s 定义在core/instance/render-helpers/index,js
if (key === 'textContent' || key === 'innerHTML') {
if (vnode.children) vnode.children.length = 0
if (cur === oldProps[key]) continue // #6601 work around Chrome version <= 55 bug where single textNode // replaced by innerHTML/textContent retains its parentNode property
if (elm.childNodes.length === 1) {
elm.removeChild(elm.childNodes[0])
}
}
双向绑定的原理是什么
我们都知道 Vue 是数据双向绑定的框架,双向绑定由三个重要部分构成
- 数据层(Model):应用的数据及业务逻辑
- 视图层(View):应用的展示效果,各类UI组件
- 业务逻辑层(ViewModel):框架封装的核心,它负责将数据与视图关联起来
而上面的这个分层的架构方案,可以用一个专业术语进行称呼:MVVM这里的控制层的核心功能便是 “数据双向绑定” 。自然,我们只需弄懂它是什么,便可以进一步了解数据绑定的原理
理解ViewModel
它的主要职责就是:
- 数据变化后更新视图
- 视图变化后更新数据
当然,它还有两个主要部分组成
- 监听器(
Observer):对所有数据的属性进行监听 - 解析器(
Compiler):对每个元素节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数
Vue为什么需要虚拟DOM?优缺点有哪些
由于在浏览器中操作
DOM是很昂贵的。频繁的操作DOM,会产生一定的性能问题。这就是虚拟Dom的产生原因。Vue2的Virtual DOM借鉴了开源库snabbdom的实现。Virtual DOM本质就是用一个原生的JS对象去描述一个DOM节点,是对真实DOM的一层抽象
优点:
- 保证性能下限 : 框架的虚拟
DOM需要适配任何上层API可能产生的操作,它的一些DOM操作的实现必须是普适的,所以它的性能并不是最优的;但是比起粗暴的DOM操作性能要好很多,因此框架的虚拟DOM至少可以保证在你不需要手动优化的情况下,依然可以提供还不错的性能,即保证性能的下限; - 无需手动操作 DOM : 我们不再需要手动去操作
DOM,只需要写好View-Model的代码逻辑,框架会根据虚拟DOM和 数据双向绑定,帮我们以可预期的方式更新视图,极大提高我们的开发效率; - 跨平台 : 虚拟
DOM本质上是JavaScript对象,而DOM与平台强相关,相比之下虚拟DOM可以进行更方便地跨平台操作,例如服务器渲染、weex开发等等。
缺点:
- 无法进行极致优化:虽然虚拟
DOM+ 合理的优化,足以应对绝大部分应用的性能需求,但在一些性能要求极高的应用中虚拟DOM无法进行针对性的极致优化。 - 首次渲染大量
DOM时,由于多了一层虚拟DOM的计算,会比innerHTML插入慢。
虚拟 DOM 实现原理?
虚拟 DOM 的实现原理主要包括以下 3 部分:
- 用
JavaScript对象模拟真实DOM树,对真实DOM进行抽象; diff算法 — 比较两棵虚拟DOM树的差异;pach算法 — 将两个虚拟DOM对象的差异应用到真正的DOM树。
说说你对虚拟 DOM 的理解?回答范例
思路
vdom是什么- 引入
vdom的好处 vdom如何生成,又如何成为dom- 在后续的
diff中的作用
回答范例
-
虚拟
dom顾名思义就是虚拟的dom对象,它本身就是一个JavaScript对象,只不过它是通过不同的属性去描述一个视图结构 -
通过引入
vdom我们可以获得如下好处:
-
将真实元素节点抽象成
VNode,有效减少直接操作dom次数,从而提高程序性能- 直接操作
dom是有限制的,比如:diff、clone等操作,一个真实元素上有许多的内容,如果直接对其进行diff操作,会去额外diff一些没有必要的内容;同样的,如果需要进行clone那么需要将其全部内容进行复制,这也是没必要的。但是,如果将这些操作转移到JavaScript对象上,那么就会变得简单了 - 操作
dom是比较昂贵的操作,频繁的dom操作容易引起页面的重绘和回流,但是通过抽象VNode进行中间处理,可以有效减少直接操作dom的次数,从而减少页面重绘和回流
- 直接操作
-
方便实现跨平台
- 同一
VNode节点可以渲染成不同平台上的对应的内容,比如:渲染在浏览器是dom元素节点,渲染在Native( iOS、Android)变为对应的控件、可以实现SSR、渲染到WebGL中等等 Vue3中允许开发者基于VNode实现自定义渲染器(renderer),以便于针对不同平台进行渲染
- 同一
vdom如何生成?在vue中我们常常会为组件编写模板 -template, 这个模板会被编译器 -compiler编译为渲染函数,在接下来的挂载(mount)过程中会调用render函数,返回的对象就是虚拟dom。但它们还不是真正的dom,所以会在后续的patch过程中进一步转化为dom。
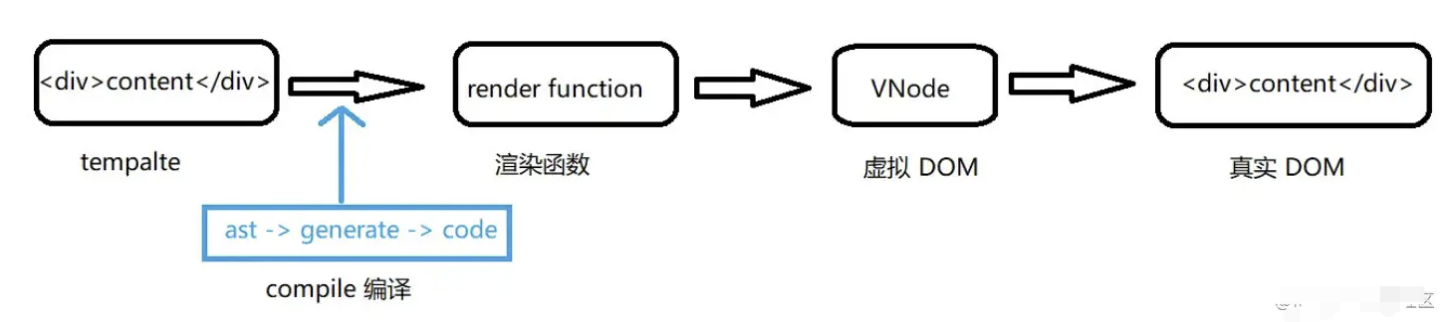
- 挂载过程结束后,
vue程序进入更新流程。如果某些响应式数据发生变化,将会引起组件重新render,此时就会生成新的vdom,和上一次的渲染结果diff就能得到变化的地方,从而转换为最小量的dom操作,高效更新视图
为什么要用vdom?案例解析
现在有一个场景,实现以下需求:
[
{ name: "张三", age: "20", address: "北京"},
{ name: "李四", age: "21", address: "武汉"},
{ name: "王五", age: "22", address: "杭州"},
]
将该数据展示成一个表格,并且随便修改一个信息,表格也跟着修改。 用jQuery实现如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<button id="btn-change">改变</button>
<script src="https://cdn.bootcss.com/jquery/3.2.0/jquery.js"></script>
<script>
const data = [{
name: "张三",
age: "20",
address: "北京"
},
{
name: "李四",
age: "21",
address: "武汉"
},
{
name: "王五",
age: "22",
address: "杭州"
},
];
//渲染函数
function render(data) {
const $container = $('#container');
$container.html('');
const $table = $('<table>');
// 重绘一次
$table.append($('<tr><td>name</td><td>age</td><td>address</td></tr>'));
data.forEach(item => {
//每次进入都重绘
$table.append($(`<tr><td>${item.name}</td><td>${item.age}</td><td>${item.address}</td></tr>`))
})
$container.append($table);
}
$('#btn-change').click(function () {
data[1].age = 30;
data[2].address = '深圳';
render(data);
});
</script>
</body>
</html>
- 这样点击按钮,会有相应的视图变化,但是你审查以下元素,每次改动之后,
table标签都得重新创建,也就是说table下面的每一个栏目,不管是数据是否和原来一样,都得重新渲染,这并不是理想中的情况,当其中的一栏数据和原来一样,我们希望这一栏不要重新渲染,因为DOM重绘相当消耗浏览器性能。 - 因此我们采用JS对象模拟的方法,将
DOM的比对操作放在JS层,减少浏览器不必要的重绘,提高效率。 - 当然有人说虚拟DOM并不比真实的
DOM快,其实也是有道理的。当上述table中的每一条数据都改变时,显然真实的DOM操作更快,因为虚拟DOM还存在js中diff算法的比对过程。所以,上述性能优势仅仅适用于大量数据的渲染并且改变的数据只是一小部分的情况。
如下DOM结构:
<ul id="list">
<li class="item">Item1</li>
<li class="item">Item2</li>
</ul>
映射成虚拟DOM就是这样:
{
tag: "ul",
attrs: {
id: "list"
},
children: [
{
tag: "li",
attrs: { className: "item" },
children: ["Item1"]
}, {
tag: "li",
attrs: { className: "item" },
children: ["Item2"]
}
]
}
使用snabbdom实现vdom
这是一个简易的实现
vdom功能的库,相比vue、react,对于vdom这块更加简易,适合我们学习vdom。vdom里面有两个核心的api,一个是h函数,一个是patch函数,前者用来生成vdom对象,后者的功能在于做虚拟dom的比对和将vdom挂载到真实DOM上
简单介绍一下这两个函数的用法:
h('标签名', {属性}, [子元素])
h('标签名', {属性}, [文本])
patch(container, vnode) // container为容器DOM元素
patch(vnode, newVnode)
现在我们就来用snabbdom重写一下刚才的例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<button id="btn-change">改变</button>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom.js"></script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-class.js"></script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-props.js"></script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-style.js"></script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-eventlisteners.min.js"></script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/h.js"></script>
<script>
let snabbdom = window.snabbdom;
// 定义patch
let patch = snabbdom.init([
snabbdom_class,
snabbdom_props,
snabbdom_style,
snabbdom_eventlisteners
]);
//定义h
let h = snabbdom.h;
const data = [{
name: "张三",
age: "20",
address: "北京"
},
{
name: "李四",
age: "21",
address: "武汉"
},
{
name: "王五",
age: "22",
address: "杭州"
},
];
data.unshift({name: "姓名", age: "年龄", address: "地址"});
let container = document.getElementById('container');
let vnode;
const render = (data) => {
let newVnode = h('table', {}, data.map(item => {
let tds = [];
for(let i in item) {
if(item.hasOwnProperty(i)) {
tds.push(h('td', {}, item[i] + ''));
}
}
return h('tr', {}, tds);
}));
if(vnode) {
patch(vnode, newVnode);
} else {
patch(container, newVnode);
}
vnode = newVnode;
}
render(data);
let btnChnage = document.getElementById('btn-change');
btnChnage.addEventListener('click', function() {
data[1].age = 30;
data[2].address = "深圳";
//re-render
render(data);
})
</script>
</body>
</html>
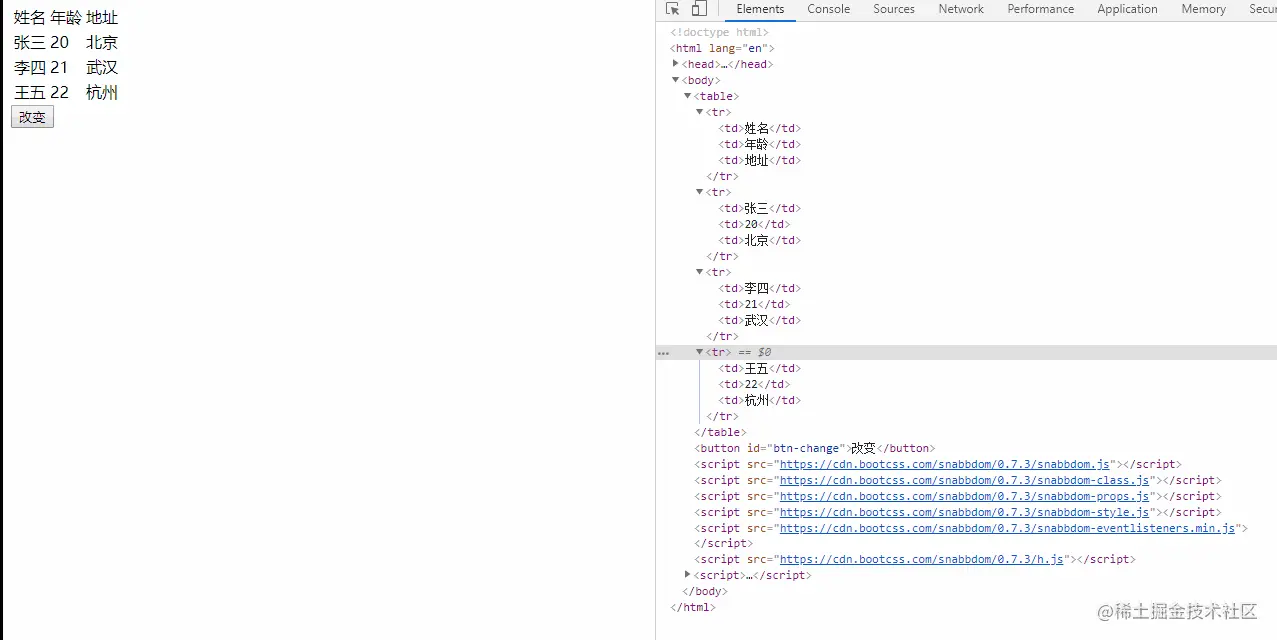
你会发现, 只有改变的栏目才闪烁,也就是进行重绘 ,数据没有改变的栏目还是保持原样,这样就大大节省了浏览器重新渲染的开销
vue中使用
h函数生成虚拟DOM返回
const vm = new Vue({
el: '#app',
data: {
user: {name:'poetry'}
},
render(h){
// h()
// h(App)
// h('div',[])
let vnode = h('div',{},'hello world');
return vnode
}
});
使用vue渲染大量数据时应该怎么优化?说下你的思路!
分析
企业级项目中渲染大量数据的情况比较常见,因此这是一道非常好的综合实践题目。
回答
-
在大型企业级项目中经常需要渲染大量数据,此时很容易出现卡顿的情况。比如大数据量的表格、树
-
处理时要根据情况做不同处理:
-
可以采取分页的方式获取,避免渲染大量数据
-
vue-virtual-scroller (opens new window)等虚拟滚动方案,只渲染视口范围内的数据
-
如果不需要更新,可以使用v-once方式只渲染一次
-
通过v-memo (opens new window)可以缓存结果,结合
v-for使用,避免数据变化时不必要的VNode创建 -
可以采用懒加载方式,在用户需要的时候再加载数据,比如
tree组件子树的懒加载
- 还是要看具体需求,首先从设计上避免大数据获取和渲染;实在需要这样做可以采用虚表的方式优化渲染;最后优化更新,如果不需要更新可以
v-once处理,需要更新可以v-memo进一步优化大数据更新性能。其他可以采用的是交互方式优化,无线滚动、懒加载等方案
理解Vue运行机制全局概览
全局概览
首先我们来看一下笔者画的内部流程图。
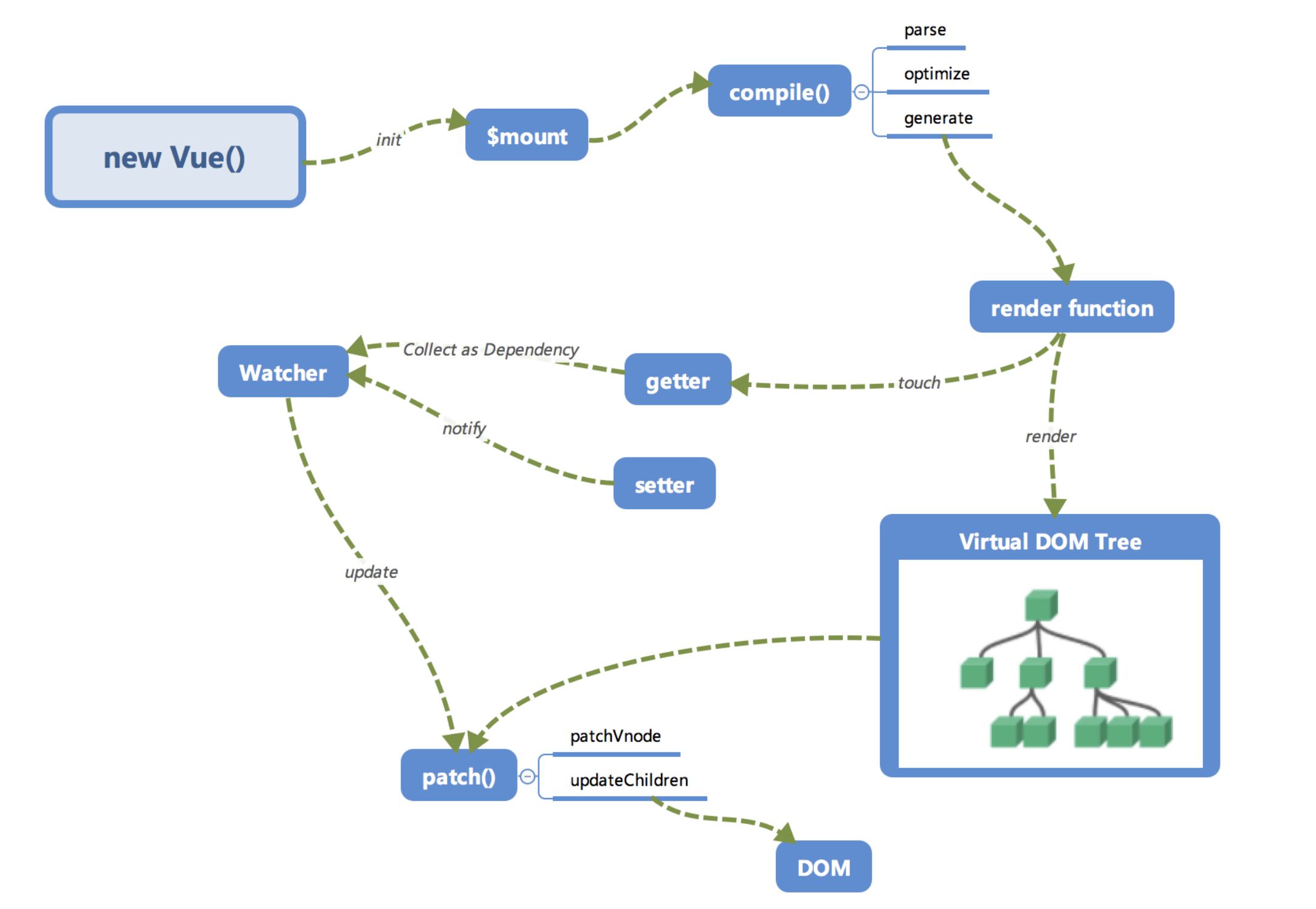
大家第一次看到这个图一定是一头雾水的,没有关系,我们来逐个讲一下这些模块的作用以及调用关系。相信讲完之后大家对Vue.js内部运行机制会有一个大概的认识。
初始化及挂载
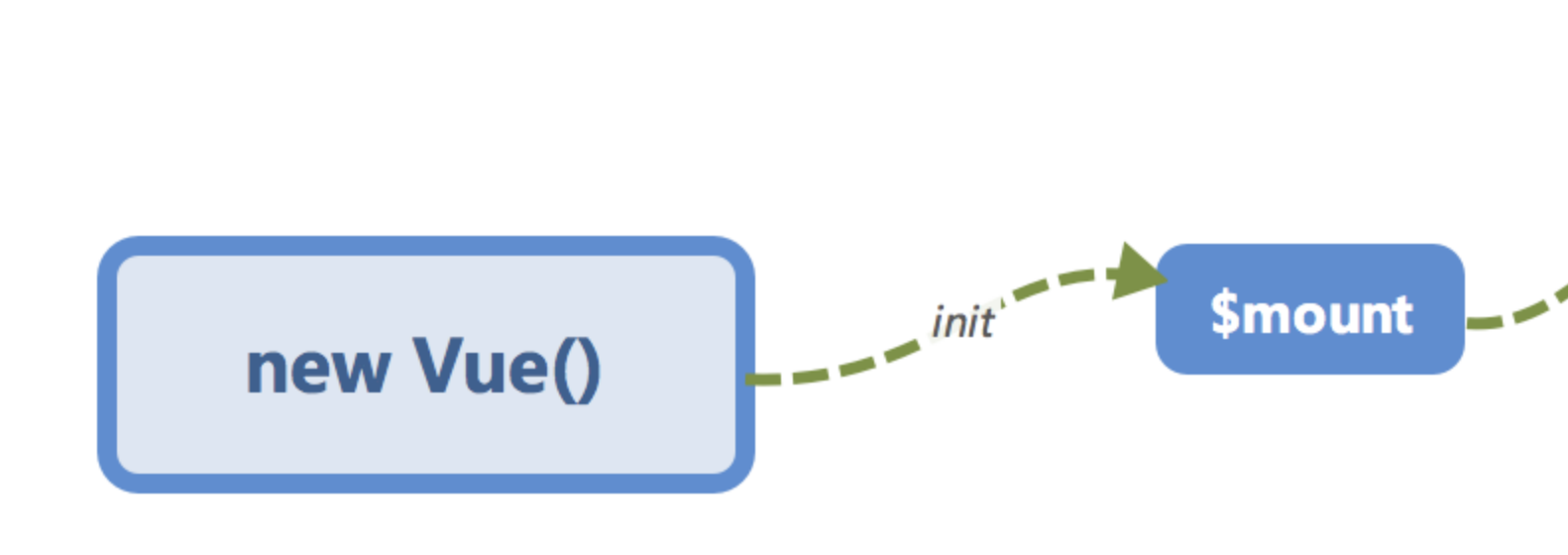
在
new Vue()之后。 Vue 会调用_init函数进行初始化,也就是这里的init过程,它会初始化生命周期、事件、 props、 methods、 data、 computed 与 watch 等。其中最重要的是通过Object.defineProperty设置setter与getter函数,用来实现「 响应式 」以及「 依赖收集 」,后面会详细讲到,这里只要有一个印象即可。
初始化之后调用
$mount会挂载组件,如果是运行时编译,即不存在 render function 但是存在 template 的情况,需要进行「 编译 」步骤。
编译
compile编译可以分成 parse、optimize 与 generate 三个阶段,最终需要得到 render function。
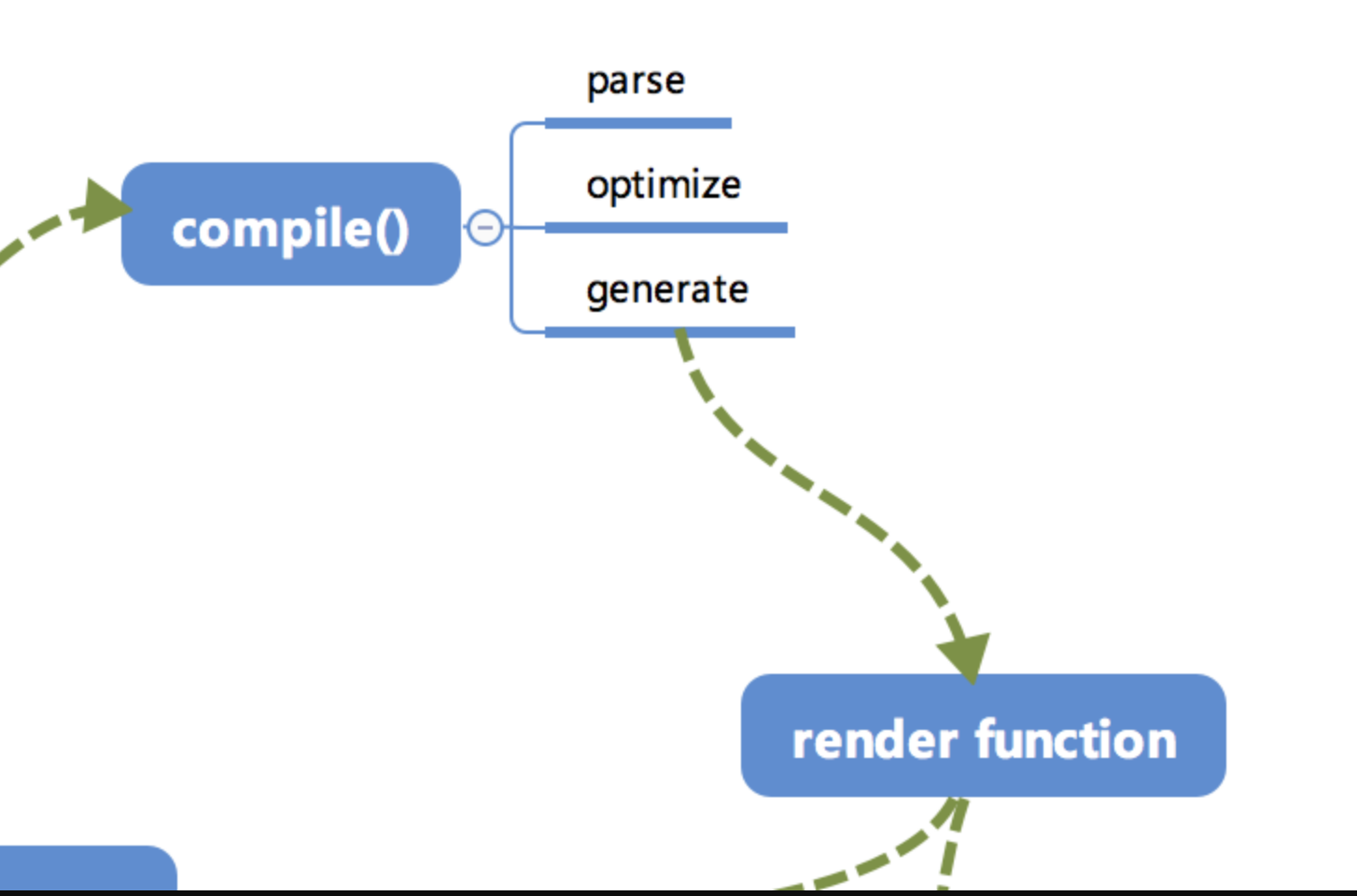
1. parse
parse 会用正则等方式解析 template 模板中的指令、class、style等数据,形成AST。
2. optimize
optimize的主要作用是标记 static 静态节点,这是 Vue 在编译过程中的一处优化,后面当update更新界面时,会有一个patch的过程, diff 算法会直接跳过静态节点,从而减少了比较的过程,优化了patch的性能。
3. generate
generate是将 AST 转化成render function字符串的过程,得到结果是render的字符串以及 staticRenderFns 字符串。
- 在经历过
parse、optimize与generate这三个阶段以后,组件中就会存在渲染VNode所需的render function了。
响应式
接下来也就是 Vue.js 响应式核心部分。
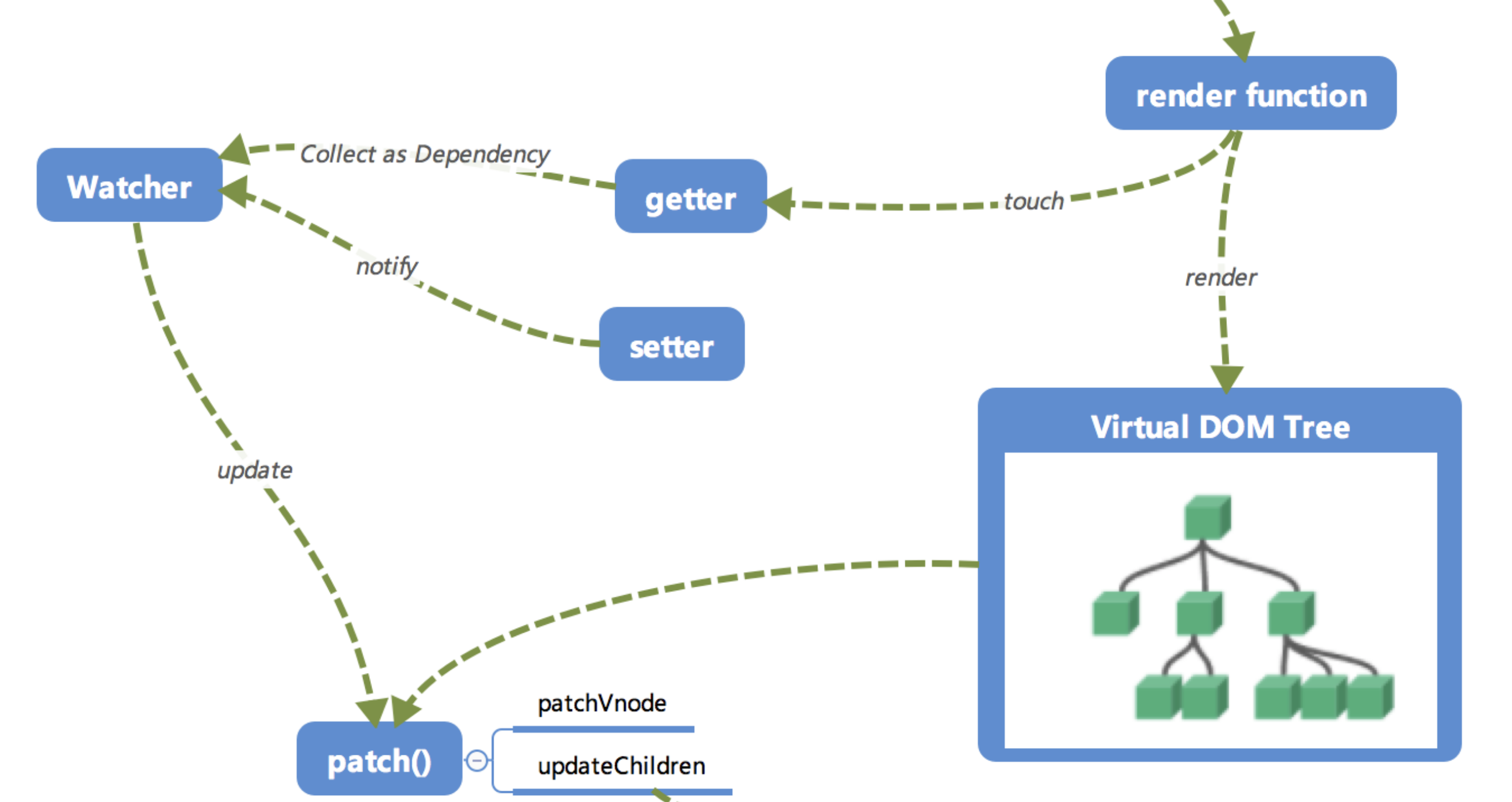
这里的
getter跟setter已经在之前介绍过了,在init的时候通过Object.defineProperty进行了绑定,它使得当被设置的对象被读取的时候会执行getter函数,而在当被赋值的时候会执行setter函数。
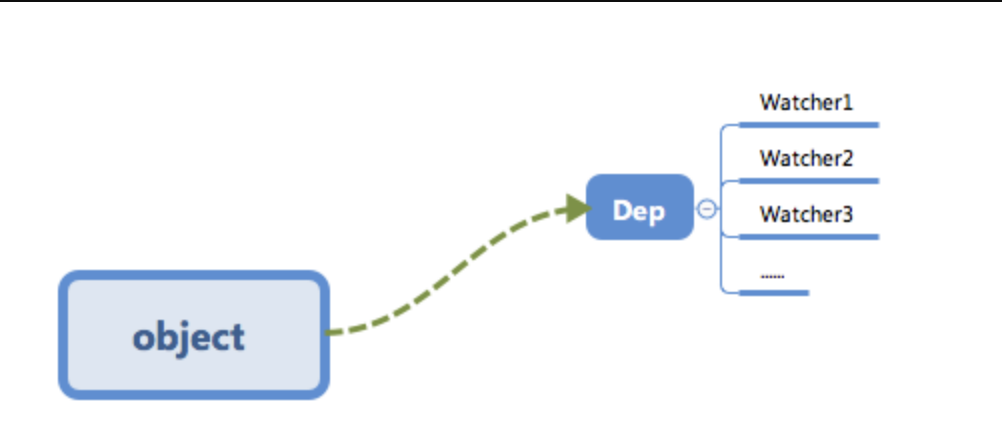
- 当
render function被渲染的时候,因为会读取所需对象的值,所以会触发getter函数进行「 依赖收集 」,「 依赖收集 」的目的是将观察者Watcher对象存放到当前闭包中的订阅者Dep的subs中。形成如下所示的这样一个关系。
在修改对象的值的时候,会触发对应的
setter,setter通知之前「 依赖收集 」得到的 Dep 中的每一个 Watcher,告诉它们自己的值改变了,需要重新渲染视图。这时候这些 Watcher 就会开始调用update来更新视图,当然这中间还有一个patch的过程以及使用队列来异步更新的策略,这个我们后面再讲。
Virtual DOM
我们知道,
render function会被转化成VNode节点。Virtual DOM其实就是一棵以 JavaScript 对象( VNode 节点)作为基础的树,用对象属性来描述节点,实际上它只是一层对真实 DOM 的抽象。最终可以通过一系列操作使这棵树映射到真实环境上。由于 Virtual DOM 是以 JavaScript 对象为基础而不依赖真实平台环境,所以使它具有了跨平台的能力,比如说浏览器平台、Weex、Node 等。
比如说下面这样一个例子:
{
tag: 'div', /*说明这是一个div标签*/
children: [ /*存放该标签的子节点*/
{
tag: 'a', /*说明这是一个a标签*/
text: 'click me' /*标签的内容*/
}
]
}
渲染后可以得到
<div>
<a>click me</a>
</div>
这只是一个简单的例子,实际上的节点有更多的属性来标志节点,比如 isStatic (代表是否为静态节点)、 isComment (代表是否为注释节点)等。
更新视图
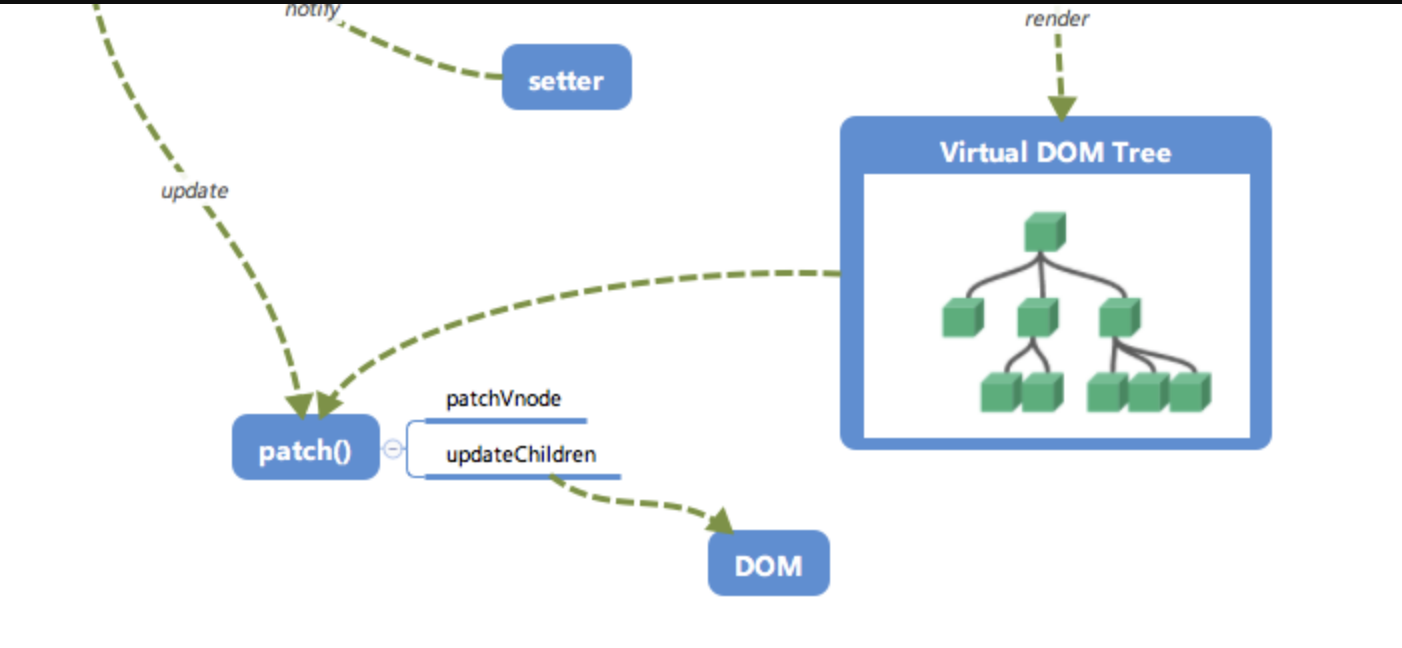
- 前面我们说到,在修改一个对象值的时候,会通过
setter -> Watcher -> update的流程来修改对应的视图,那么最终是如何更新视图的呢? - 当数据变化后,执行 render function 就可以得到一个新的 VNode 节点,我们如果想要得到新的视图,最简单粗暴的方法就是直接解析这个新的
VNode节点,然后用innerHTML直接全部渲染到真实DOM中。但是其实我们只对其中的一小块内容进行了修改,这样做似乎有些「 浪费 」。 - 那么我们为什么不能只修改那些「改变了的地方」呢?这个时候就要介绍我们的「
patch」了。我们会将新的VNode与旧的VNode一起传入patch进行比较,经过 diff 算法得出它们的「 差异 」。最后我们只需要将这些「 差异 」的对应 DOM 进行修改即可。
再看全局
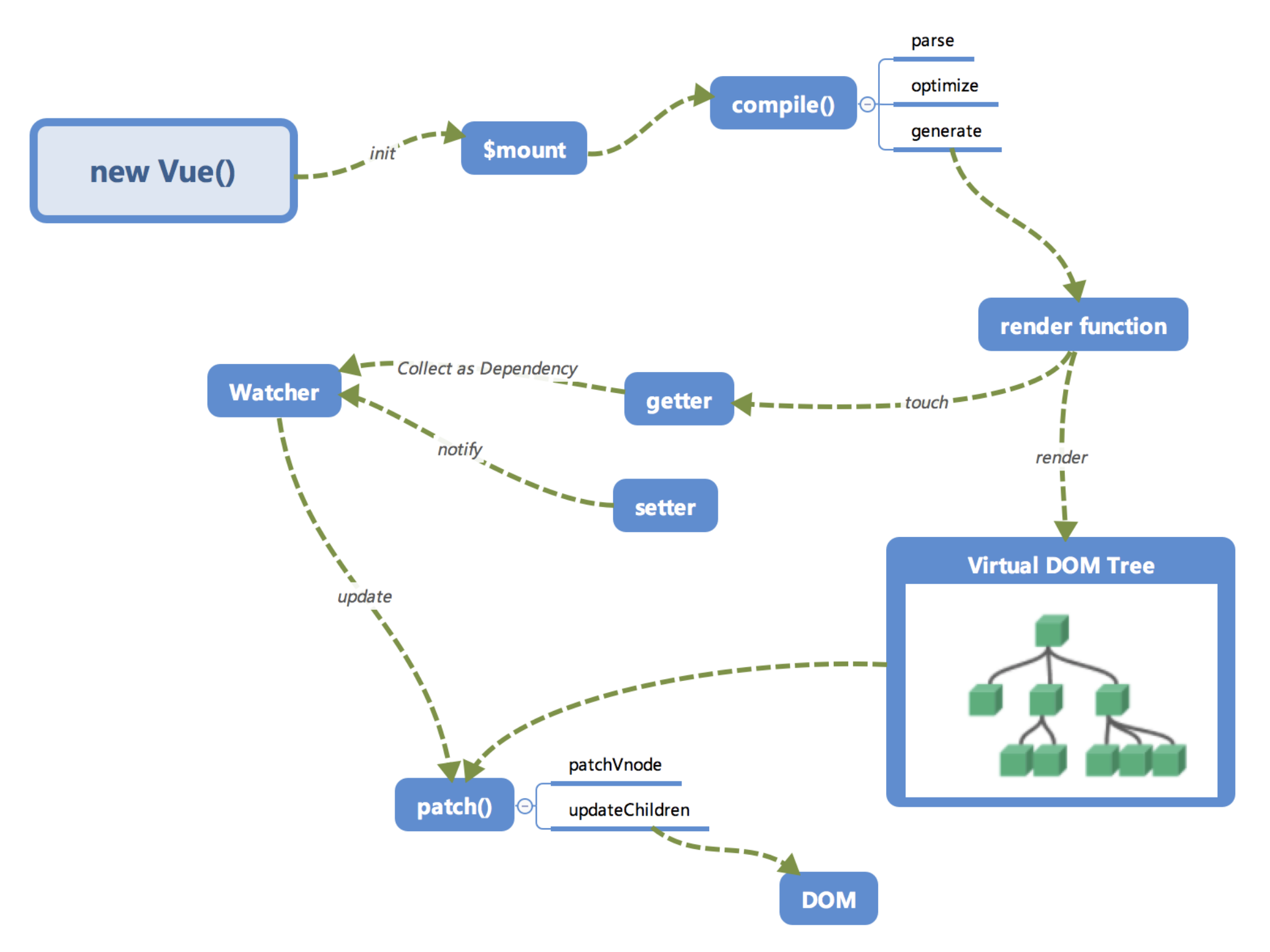
回过头再来看看这张图,是不是大脑中已经有一个大概的脉络了呢?
怎么缓存当前的组件?缓存后怎么更新
缓存组件使用keep-alive组件,这是一个非常常见且有用的优化手段,vue3中keep-alive有比较大的更新,能说的点比较多
思路
- 缓存用
keep-alive,它的作用与用法 - 使用细节,例如缓存指定/排除、结合
router和transition - 组件缓存后更新可以利用
activated或者beforeRouteEnter - 原理阐述
回答范例
- 开发中缓存组件使用
keep-alive组件,keep-alive是vue内置组件,keep-alive包裹动态组件component时,会缓存不活动的组件实例,而不是销毁它们,这样在组件切换过程中将状态保留在内存中,防止重复渲染DOM
<keep-alive>
<component :is="view"></component>
</keep-alive>
- 结合属性
include和exclude可以明确指定缓存哪些组件或排除缓存指定组件。vue3中结合vue-router时变化较大,之前是keep-alive包裹router-view,现在需要反过来用router-view包裹keep-alive
<router-view v-slot="{ Component }">
<keep-alive>
<component :is="Component"></component>
</keep-alive>
</router-view>
- 缓存后如果要获取数据,解决方案可以有以下两种
beforeRouteEnter:在有vue-router的项目,每次进入路由的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
actived:在keep-alive缓存的组件被激活的时候,都会执行actived钩子
activated(){
this.getData() // 获取数据
},
keep-alive是一个通用组件,它内部定义了一个map,缓存创建过的组件实例,它返回的渲染函数内部会查找内嵌的component组件对应组件的vnode,如果该组件在map中存在就直接返回它。由于component的is属性是个响应式数据,因此只要它变化,keep-alive的render函数就会重新执行
Vue.extend 作用和原理
官方解释:
Vue.extend使用基础Vue构造器,创建一个“子类”。参数是一个包含组件选项的对象。
其实就是一个子类构造器 是 Vue 组件的核心 api 实现思路就是使用原型继承的方法返回了 Vue 的子类 并且利用 mergeOptions 把传入组件的 options 和父类的 options 进行了合并
extend是构造一个组件的语法器。然后这个组件你可以作用到Vue.component这个全局注册方法里还可以在任意vue模板里使用组件。 也可以作用到vue实例或者某个组件中的components属性中并在内部使用apple组件。Vue.component你可以创建 ,也可以取组件。
相关代码如下
export default function initExtend(Vue) {
let cid = 0; //组件的唯一标识
// 创建子类继承Vue父类 便于属性扩展
Vue.extend = function (extendOptions) {
// 创建子类的构造函数 并且调用初始化方法
const Sub = function VueComponent(options) {
this._init(options); //调用Vue初始化方法
};
Sub.cid = cid++;
Sub.prototype = Object.create(this.prototype); // 子类原型指向父类
Sub.prototype.constructor = Sub; //constructor指向自己
Sub.options = mergeOptions(this.options, extendOptions); //合并自己的options和父类的options
return Sub;
};
}
Vue中的过滤器了解吗?过滤器的应用场景有哪些?
过滤器实质不改变原始数据,只是对数据进行加工处理后返回过滤后的数据再进行调用处理,我们也可以理解其为一个纯函数
Vue 允许你自定义过滤器,可被用于一些常见的文本格式化
ps: Vue3中已废弃filter
如何用
vue中的过滤器可以用在两个地方:双花括号插值和 v-bind 表达式,过滤器应该被添加在 JavaScript表达式的尾部,由“管道”符号指示:
<!-- 在双花括号中 -->
{ message | capitalize }
<!-- 在 `v-bind` 中 -->
<div v-bind:id="rawId | formatId"></div>
定义filter
在组件的选项中定义本地的过滤器
filters: {
capitalize: function (value) {
if (!value) return ''
value = value.toString()
return value.charAt(0).toUpperCase() + value.slice(1)
}
}
定义全局过滤器:
Vue.filter('capitalize', function (value) {
if (!value) return ''
value = value.toString()
return value.charAt(0).toUpperCase() + value.slice(1)
})
new Vue({
// ...
})
注意:当全局过滤器和局部过滤器重名时,会采用局部过滤器
过滤器函数总接收表达式的值 (之前的操作链的结果) 作为第一个参数。在上述例子中,capitalize 过滤器函数将会收到 message 的值作为第一个参数
过滤器可以串联:
{ message | filterA | filterB }
在这个例子中,filterA 被定义为接收单个参数的过滤器函数,表达式 message 的值将作为参数传入到函数中。然后继续调用同样被定义为接收单个参数的过滤器函数 filterB,将 filterA 的结果传递到 filterB 中。
过滤器是 JavaScript函数,因此可以接收参数:
{{ message | filterA('arg1', arg2) }}
这里,filterA 被定义为接收三个参数的过滤器函数。
其中 message 的值作为第一个参数,普通字符串 'arg1' 作为第二个参数,表达式 arg2 的值作为第三个参数
举个例子:
<div id="app">
<p>{{ msg | msgFormat('疯狂','--')}}</p>
</div>
<script>
// 定义一个 Vue 全局的过滤器,名字叫做 msgFormat
Vue.filter('msgFormat', function(msg, arg, arg2) {
// 字符串的 replace 方法,第一个参数,除了可写一个 字符串之外,还可以定义一个正则
return msg.replace(/单纯/g, arg+arg2)
})
</script>
小结:
- 部过滤器优先于全局过滤器被调用
- 一个表达式可以使用多个过滤器。过滤器之间需要用管道符“|”隔开。其执行顺序从左往右
应用场景
平时开发中,需要用到过滤器的地方有很多,比如单位转换、数字打点、文本格式化、时间格式化之类的等
比如我们要实现将30000 => 30,000,这时候我们就需要使用过滤器
Vue.filter('toThousandFilter', function (value) {
if (!value) return ''
value = value.toString()
return .replace(str.indexOf('.') > -1 ? /(\d)(?=(\d{3})+\.)/g : /(\d)(?=(?:\d{3})+$)/g, '$1,')
})
原理分析
使用过滤器
{{ message | capitalize }}
在模板编译阶段过滤器表达式将会被编译为过滤器函数,主要是用过parseFilters,我们放到最后讲
_s(_f('filterFormat')(message))
首先分析一下_f:
_f 函数全名是:resolveFilter,这个函数的作用是从this.$options.filters中找出注册的过滤器并返回
// 变为
this.$options.filters['filterFormat'](message) // message为参数
关于resolveFilter
import { indentity,resolveAsset } from 'core/util/index'
export function resolveFilter(id){
return resolveAsset(this.$options,'filters',id,true) || identity
}
内部直接调用resolveAsset,将option对象,类型,过滤器id,以及一个触发警告的标志作为参数传递,如果找到,则返回过滤器;
resolveAsset的代码如下:
export function resolveAsset(options,type,id,warnMissing){ // 因为我们找的是过滤器,所以在 resolveFilter函数中调用时 type 的值直接给的 'filters',实际这个函数还可以拿到其他很多东西
if(typeof id !== 'string'){ // 判断传递的过滤器id 是不是字符串,不是则直接返回
return
}
const assets = options[type] // 将我们注册的所有过滤器保存在变量中
// 接下来的逻辑便是判断id是否在assets中存在,即进行匹配
if(hasOwn(assets,id)) return assets[id] // 如找到,直接返回过滤器
// 没有找到,代码继续执行
const camelizedId = camelize(id) // 万一你是驼峰的呢
if(hasOwn(assets,camelizedId)) return assets[camelizedId]
// 没找到,继续执行
const PascalCaseId = capitalize(camelizedId) // 万一你是首字母大写的驼峰呢
if(hasOwn(assets,PascalCaseId)) return assets[PascalCaseId]
// 如果还是没找到,则检查原型链(即访问属性)
const result = assets[id] || assets[camelizedId] || assets[PascalCaseId]
// 如果依然没找到,则在非生产环境的控制台打印警告
if(process.env.NODE_ENV !== 'production' && warnMissing && !result){
warn('Failed to resolve ' + type.slice(0,-1) + ': ' + id, options)
}
// 无论是否找到,都返回查找结果
return result
}
下面再来分析一下_s:
_s 函数的全称是 toString,过滤器处理后的结果会当作参数传递给 toString函数,最终 toString函数执行后的结果会保存到Vnode中的text属性中,渲染到视图中
function toString(value){
return value == null
? ''
: typeof value === 'object'
? JSON.stringify(value,null,2)// JSON.stringify()第三个参数可用来控制字符串里面的间距
: String(value)
}
最后,在分析下parseFilters,在模板编译阶段使用该函数阶段将模板过滤器解析为过滤器函数调用表达式
function parseFilters (filter) {
let filters = filter.split('|')
let expression = filters.shift().trim() // shift()删除数组第一个元素并将其返回,该方法会更改原数组
let i
if (filters) {
for(i = 0;i < filters.length;i++){
experssion = warpFilter(expression,filters[i].trim()) // 这里传进去的expression实际上是管道符号前面的字符串,即过滤器的第一个参数
}
}
return expression
}
// warpFilter函数实现
function warpFilter(exp,filter){
// 首先判断过滤器是否有其他参数
const i = filter.indexof('(')
if(i<0){ // 不含其他参数,直接进行过滤器表达式字符串的拼接
return `_f("${filter}")(${exp})`
}else{
const name = filter.slice(0,i) // 过滤器名称
const args = filter.slice(i+1) // 参数,但还多了 ‘)’
return `_f('${name}')(${exp},${args}` // 注意这一步少给了一个 ')'
}
}
小结:
- 在编译阶段通过
parseFilters将过滤器编译成函数调用(串联过滤器则是一个嵌套的函数调用,前一个过滤器执行的结果是后一个过滤器函数的参数) - 编译后通过调用
resolveFilter函数找到对应过滤器并返回结果 - 执行结果作为参数传递给
toString函数,而toString执行后,其结果会保存在Vnode的text属性中,渲染到视图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号