
Hadoop伪分布式搭建
搭建伪分布式环境,只需要一台Linux服务器,一般开发测试使用
在单机上模拟分布式环境
HDFS:主节点 NameNode
从节点 DataNode SecondaryNameNode
yarn: 主节点 ResourceManager
从节点 NodeManager
tools和training是自定义目录
工具:SecureCRT6.5.0
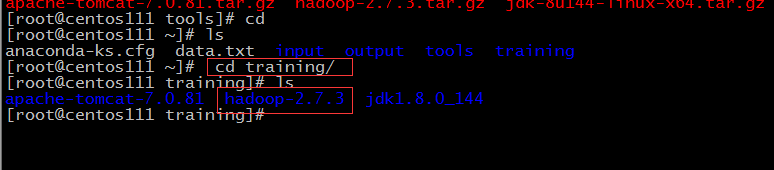
- 将Hadoop包上传到Linux服务器上,如~/tools目录下
![]()
- 解压该压缩包到~/training目录下
![]()
-
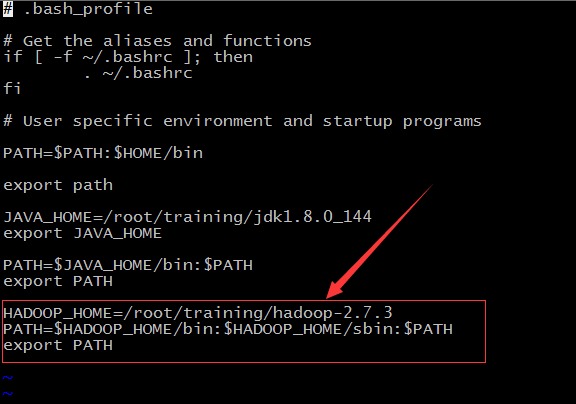
在~/.bash_profile里设置环境变量,增加红色框内容。 vi ~/.bash_profile,按 【i】 进入编辑模式,按【esc】退出编辑模式,输入冒号:wq回车保存
![]()
- 执行source ~/.bash_profile 使环境变量生效
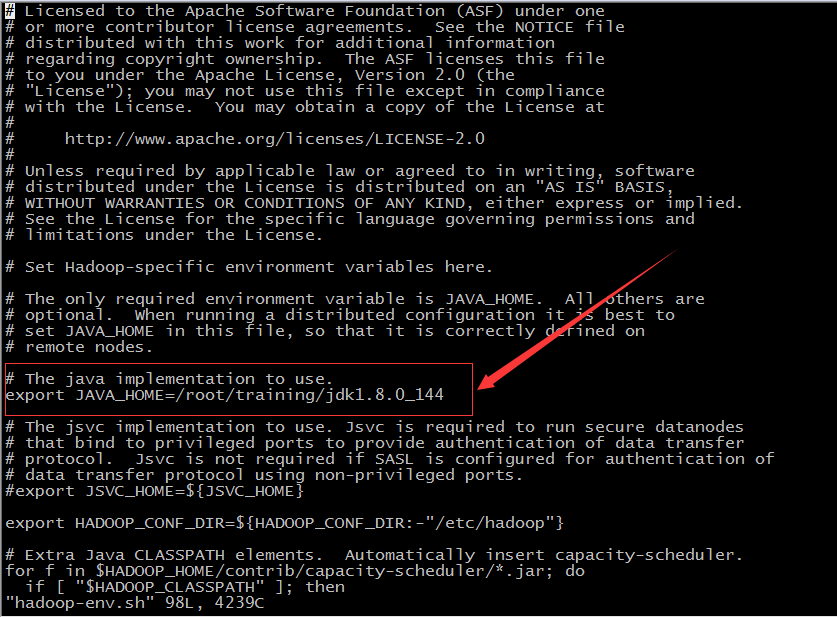
- 配置jdk路径,找到Hadoop的配置文件hadoop-env.sh,vi /root/training/hadoop-2.7.3/etc/hadoop/hadoop-env.sh回车,加入红色部分,JAVA_HOME就是jdk的路径
![]()
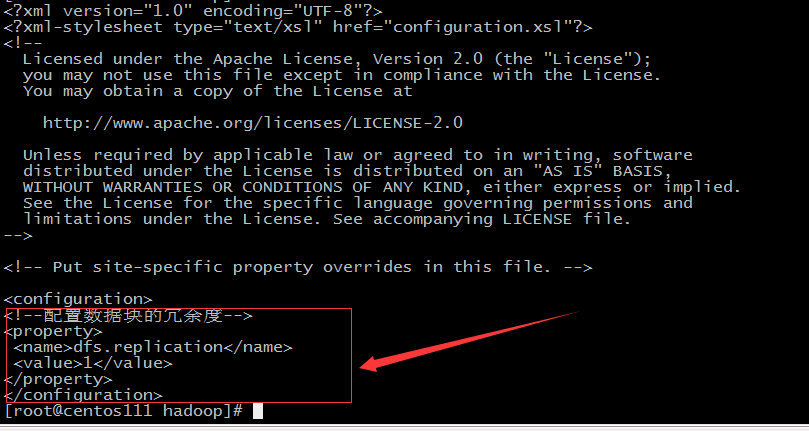
- 接着配置hdfs-site.xml,加入红色框内容
<!--配置数据块的冗余度-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>![]()
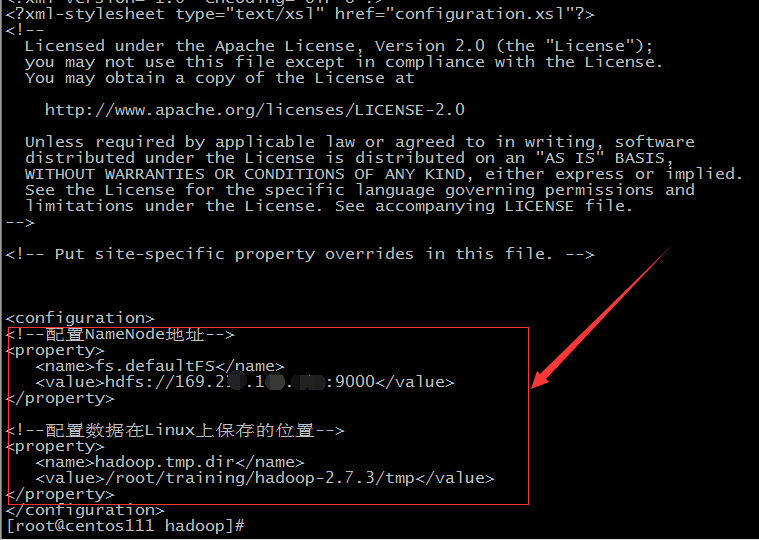
- 配置core-site.xml,加入如下内容
<!--配置NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://本机IP:9000</value>
</property><!--配置数据在Linux上保存的位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>![]()
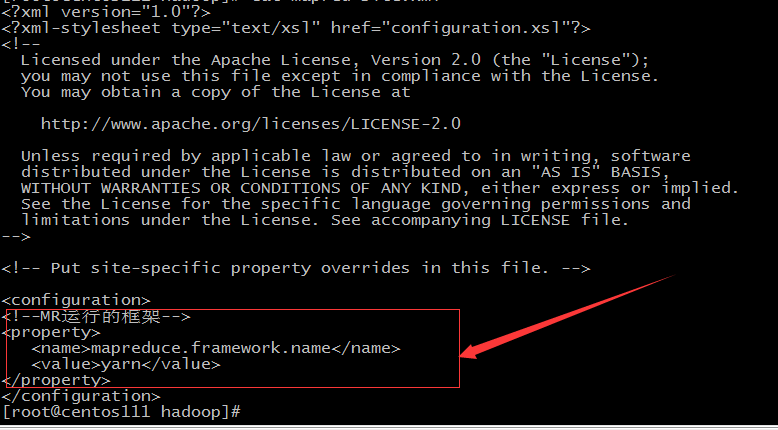
- 配置mapred-site.xml,添加如下
<!--MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>![]()
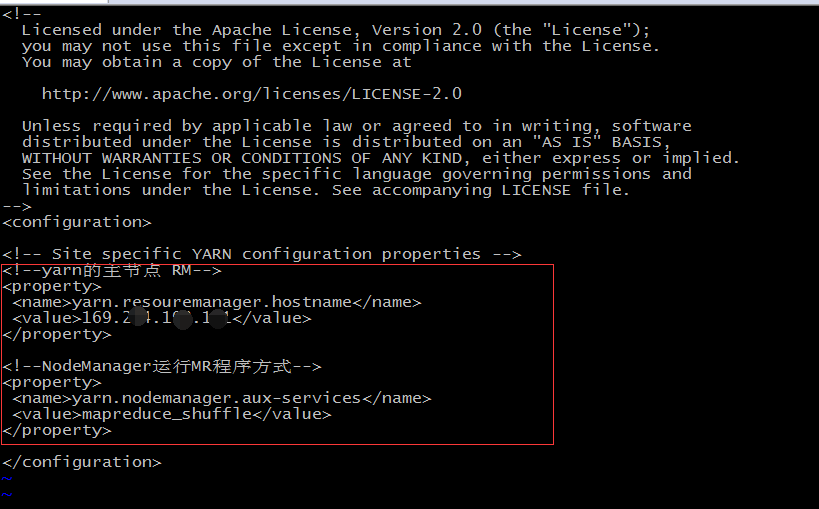
- 配置yarn-site.xml,添加如下
<!--yarn的主节点 RM-->
<property>
<name>yarn.resouremanager.hostname</name>
<value>IP地址</value>
</property><!--NodeManager运行MR程序方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>![]()
- namenode首次需要格式化,犹如软盘一样使用前要格式化
![]()
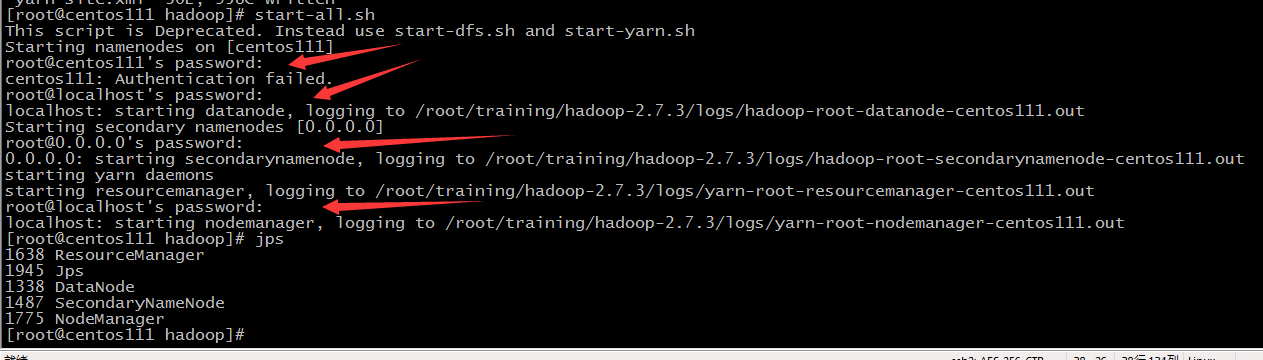
- 启动start-all.sh,表示启动所有服务,但发现要输入四次密码
![]()
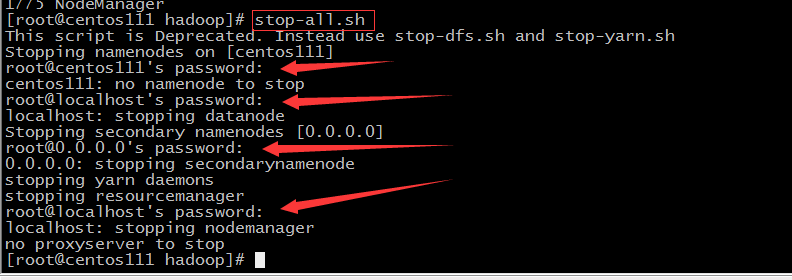
- 停止所有服务,执行stop-all.sh,也要输入四次密码,从启动到停止服务,一共输入8次密码。如果启动多台服务器,那岂不是很多密码
![]()
伪分布式环境到此就搭建配置完成。基于输入多次密码,可以配置免密登录,下一节将会讲解



 浙公网安备 33010602011771号
浙公网安备 33010602011771号