
第一次个人编程作业
论文查重系统
| 这个作业属于哪个课程 | <计科22级34班> |
|---|---|
| 这个作业要求在哪里 | [<作业要求>](个人项目 - 作业 - 计科22级34班 - 班级博客 - 博客园 (cnblogs.com)) |
| 这个作业的目标 | 通过实际编程任务,全面提升学生在编程、算法、项目管理、性能优化、代码测试和版本控制等方面的能力,为学生未来处理复杂开发项目打下扎实的基础。 |
项目 GitHub 链接:https://github.com/Tracywu1/PaperCheck
🧩一、PSP表格
| PSP各个阶段 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 50 |
| · Estimate | · 明确需求和其他因素,估计以下的各个任务需要多少时间 | 50 | 50 |
| Development | 开发 | 390 | 435 |
| · Analysis | · 需求分析 (包括学习新技术、新工具的时间) | 60 | 50 |
| · Design Spec | · 生成设计文档(整体框架的设计,各模块的接口,用时序图,快速原型等方法) | 60 | 60 |
| · Design Review | · 设计复审 | 10 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 30 | 20 |
| · Coding | · 具体编码 | 120 | 200 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 160 | 180 |
| · Test Report | · 测试报告(发现了多少bug,修复了多少) | 30 | 50 |
| · Size Measurement | · 计算工作量(多少行代码,多少次签入,多少测试用例,其他工作量) | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划(包括写文档、博客的时间) | 120 | 120 |
| · 合计 | 570 | 665 |
🧩二、计算模块接口的设计与实现过程
1.类
- Main:程序的入口点,处理命令行参数并协调整个查重过程
- PlagiarismChecker:核心类,负责检查抄袭
- SimHashCalculator:计算文本的SimHash值
- FileUtil:处理文件读写
- HashUtil:计算字符串哈希值
- Constants:存储系统常量和配置
2.函数
- Main.main():程序入口,处理命令行参数并执行查重流程
- PlagiarismChecker.checkPlagiarism():检查两段文本的抄袭程度
- SimHashCalculator.getSimHash():计算文本的SimHash值
- FileUtil.readFile():读取文件内容
- FileUtil.writeResult():写入检测结果
- HashUtil.hash():计算字符串哈希值
3.类之间的关系
- Main 类是整个程序的入口,它使用 FileUtil 读取输入文件,调用 PlagiarismChecker 进行抄袭检测,然后再次使用 FileUtil 写入结果。
- PlagiarismChecker 依赖于 SimHashCalculator 来计算SimHash值。
- SimHashCalculator 又依赖于 HashUtil 来计算单词的哈希值,并使用 Constants 中定义的常量和停用词列表。
4.关键函数流程图
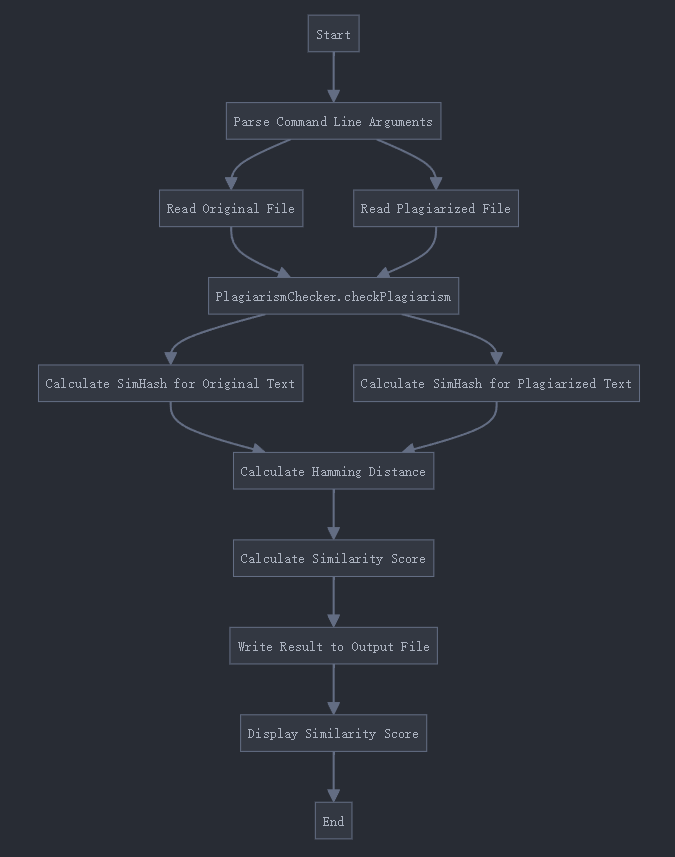
5.算法关键点和独到之处
(1)关键点:
- 命令行接口:
- 程序通过命令行参数接收输入和输出文件路径,提高了灵活性和可集成性。
- SimHash算法:
- 使用SimHash算法来快速估计文本相似度,特别适用于大规模文本比较。
- SimHash将长文本转换为固定长度的指纹(在这里是64位),通过比较指纹来判断相似度。
- 分词和停用词过滤:
- 使用结巴分词(JiebaSegmenter)进行中文分词,这对于处理中文文本很重要。
- 使用预定义的停用词列表(在Constants类中定义)进行过滤,提高了相似度计算的准确性。
- 词频加权:
- 在计算SimHash时考虑了词频,这使得重要词语对最终的指纹产生更大影响。
- 汉明距离:
- 使用汉明距离来衡量两个SimHash的差异,这是一种简单但有效的相似度度量方法。
- 可配置性:
- 通过Constants类集中管理配置参数(如哈希位数和停用词列表),便于未来调整和优化。
- 错误处理:
- Main类中包含了基本的错误处理机制,可以捕获并报告在文件读写或相似度计算过程中可能发生的异常。
(2)独到之处:
- 使用Java 8 Stream API进行词频统计和SimHash计算,代码简洁高效。
- 采用BigInteger来处理哈希值,提供了更大的数值范围和更精确的计算。
- 将相似度结果规范化到0-1范围,便于理解和比较。
- 系统设计考虑了中文文本的特点,包括使用专门的中文分词工具和中文停用词列表。
🧩三、计算模块接口部分的性能改进

由 IDEA 自带的 profiler 功能生成了以上图表,它展示了程序运行时的方法调用树和每个方法所的执行时间。
对图表的分析:
- 性能瓶颈:
- SimHashCalculator.getSimHash 和 JiebaSegmenter.sentenceProcess 是查重过程中的主要耗时点。
改进思路:
- 使用延迟初始化和双重检查锁定模式来初始化 JiebaSegmenter,这样可以避免在不需要时进行昂贵的初始化操作。
- 在 SimHashCalculator 中使用传统的 for 循环替代流操作,并使用 long[] 数组代替 int[],可能会略微提高性能。
SimHashCalculator 类原代码:
public class SimHashCalculator {
private static final JiebaSegmenter SEGMENTER = new JiebaSegmenter();
public static String getSimHash(String text) throws NoSuchAlgorithmException {
if (text == null || text.trim().isEmpty()) {
return String.join("", Collections.nCopies(Constants.HASH_BITS, "0"));
}
// 使用jieba分词对文本进行分词处理
List<String> words = SEGMENTER.sentenceProcess(text);
// 过滤掉停止词,并统计剩余词汇的词频
Map<String, Long> wordFrequency = words.stream()
.filter(word -> !Constants.STOP_WORDS.contains(word))
.collect(Collectors.groupingBy(w -> w, Collectors.counting()));
// 如果过滤后没有剩余的词,返回全0的SimHash
if (wordFrequency.isEmpty()) {
return String.join("", Collections.nCopies(Constants.HASH_BITS, "0"));
}
// 初始化用于存储每个哈希位的权重和的数组
int[] v = new int[Constants.HASH_BITS];
// 遍历词频映射,根据每个词的哈希值更新数组v
for (Map.Entry<String, Long> entry : wordFrequency.entrySet()) {
BigInteger hash = HashUtil.hash(entry.getKey());
long weight = entry.getValue();
// 遍历哈希值的每一位
for (int i = 0; i < Constants.HASH_BITS; i++) {
if (hash.testBit(Constants.HASH_BITS - 1 - i)) {
v[i] += weight;
} else {
v[i] -= weight;
}
}
}
// 将数组v中的每个元素转换为二进制字符串,并拼接成最终的SimHash值
StringBuilder simHashBuilder = new StringBuilder(Constants.HASH_BITS);
for (int i = 0; i < Constants.HASH_BITS; i++) {
if (v[i] >= 0) {
simHashBuilder.append("1");
} else {
simHashBuilder.append("0");
}
}
return simHashBuilder.toString();
}
}
改进后代码:
public class SimHashCalculator {
private static volatile JiebaSegmenter SEGMENTER;
private static JiebaSegmenter getSegmenter() {
if (SEGMENTER == null) {
synchronized (SimHashCalculator.class) {
if (SEGMENTER == null) {
SEGMENTER = new JiebaSegmenter();
}
}
}
return SEGMENTER;
}
/**
* 计算给定文本的 SimHash 值。
* @param text 输入的文本字符串
* @return 文本的 SimHash 值,以二进制字符串形式表示
*/
public static String getSimHash(String text){
// 同之前
// 使用数组来存储词频,避免使用流操作,并使用 long[] 数组代替 int[]
long[] v = new long[Constants.HASH_BITS];
for (String word : words) {
if (!Constants.STOP_WORDS.contains(word)) {
BigInteger hash = HashUtil.hash(word);
for (int i = 0; i < Constants.HASH_BITS; i++) {
if (hash.testBit(Constants.HASH_BITS - 1 - i)) {
v[i]++;
} else {
v[i]--;
}
}
}
}
// 使用StringBuilder构建最终的SimHash
StringBuilder simHashBuilder = new StringBuilder(Constants.HASH_BITS);
for (long bit : v) {
simHashBuilder.append(bit >= 0 ? "1" : "0");
}
return simHashBuilder.toString();
}
}
使用延迟初始化和双重检查锁定模式来初始化 JiebaSegmenter:
private static volatile JiebaSegmenter SEGMENTER;
private static final int SHORT_TEXT_THRESHOLD = 50; // 定义短文本的阈值
// 使用延迟初始化和双重检查锁定模式来初始化JiebaSegmenter,这样可以避免在不需要时进行昂贵的初始化操作。
private static JiebaSegmenter getSegmenter() {
if (SEGMENTER == null) {
synchronized (PlagiarismChecker.class) {
if (SEGMENTER == null) {
SEGMENTER = new JiebaSegmenter();
}
}
}
return SEGMENTER;
}
改进后的程序运行时的方法调用树:
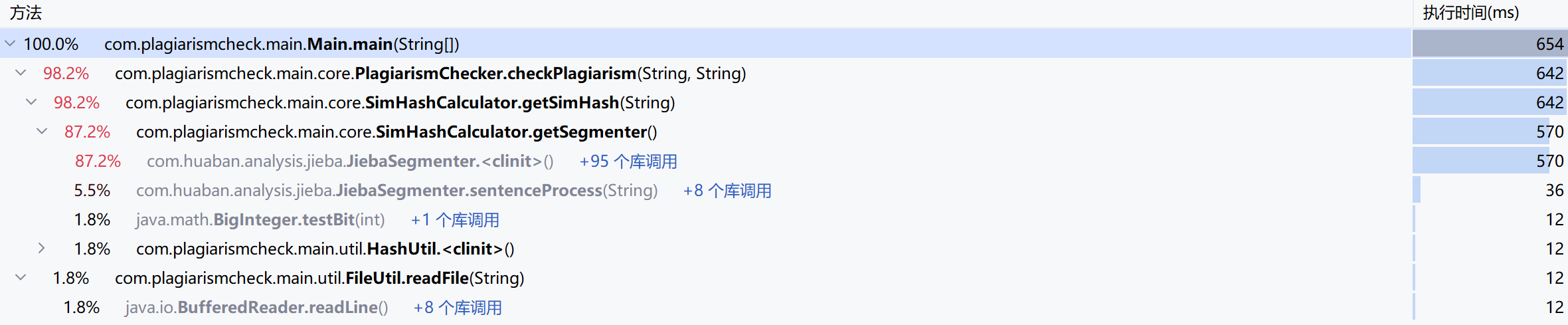
🧩四、计算模块部分单元测试展示
PlagiarismCheckerTest:
-
testCheckPlagiarismWithSimilarTexts: 测试相似但不完全相同的文本,验证相似度在合理范围内。
public void testCheckPlagiarismWithSimilarTexts() throws PlagiarismException.EmptyTextException { // 定义原始文本和涉嫌抄袭的文本 String originalText = "今天是星期天,天气晴,今天晚上我要去看电影。"; String plagiarizedText = "今天是周天,天气晴朗,我晚上要去看电影。"; // 调用PlagiarismChecker类的checkPlagiarism方法检查两段文本的相似度 double similarity = PlagiarismChecker.checkPlagiarism(originalText, plagiarizedText); System.out.println(similarity); // 验证返回的相似度是否在0到1之间 assertTrue(similarity >= 0 && similarity <= 1); // 预期这两段文本的相似度应该很高,因此相似度应大于0.5 assertTrue(similarity >= 0.5); } -
testCheckPlagiarismWithIdenticalTexts: 测试完全相同的文本,验证相似度为1。
-
testCheckPlagiarismWithDifferentTexts: 测试完全不同的文本,验证相似度接近0。
-
testCheckPlagiarismWithLongTexts: 测试长文本,验证系统能处理大量数据。
-
testTextWithManyStopWords: 测试包含大量停用词的文本,验证相似度在合理范围内。
SimHashCalculatorTest:
-
testGetSimHashWithNormalText: 测试普通文本的SimHash计算。
public void testGetSimHashWithNormalText() { // 测试普通文本的SimHash计算 String text = "This is a test text for SimHash calculation."; String simHash = SimHashCalculator.getSimHash(text); assertNotNull("SimHash不应为空", simHash); assertEquals("SimHash长度应为64位", 64, simHash.length()); assertTrue("SimHash应只包含0和1", simHash.matches("[01]+")); } -
testGetSimHashWithChineseText: 测试中文文本的SimHash计算,验证多语言支持。
-
testGetSimHashConsistency: 测试SimHash计算的一致性,确保相同输入产生相同结果。
-
testGetSimHashWithSpecialCharacters: 测试包含特殊字符的文本,验证系统的鲁棒性。
FileUtilTest:
-
testReadFileWithNormalContent: 测试读取普通内容的文件。
public void testReadFileWithNormalContent() throws Exception { // 测试读取普通内容的文件 File file = tempFolder.newFile("normal.txt"); String content = "This is a test file content."; try (BufferedWriter writer = new BufferedWriter(new FileWriter(file))) { writer.write(content); } String readContent = FileUtil.readFile(file.getPath()); assertEquals("读取的内容应与写入的内容相同", content, readContent); } -
testReadFileWithEmptyContent: 测试读取空文件,验证边界情况处理。
-
testReadNonexistentFile: 测试读取不存在的文件,验证异常处理。
-
testWriteResultWithNormalValue: 测试写入正常的相似度值。
-
testWriteResultWithZeroValue: 测试写入零相似度值,验证边界情况处理。
HashUtilTest:
-
testHashWithNormalString: 测试普通字符串的哈希计算。
public void testHashWithNormalString() { // 测试普通字符串的哈希计算 String input = "test string"; BigInteger hash = HashUtil.hash(input); assertNotNull("哈希值不应为空", hash); assertTrue("哈希值应大于0", hash.compareTo(BigInteger.ZERO) > 0); } -
testHashConsistency: 测试哈希计算的一致性,确保相同输入产生相同哈希值。
-
testHashWithEmptyString: 测试空字符串的哈希计算,验证边界情况处理。
-
testHashWithLongString: 测试长字符串的哈希计算,验证系统对大量数据的处理能力。
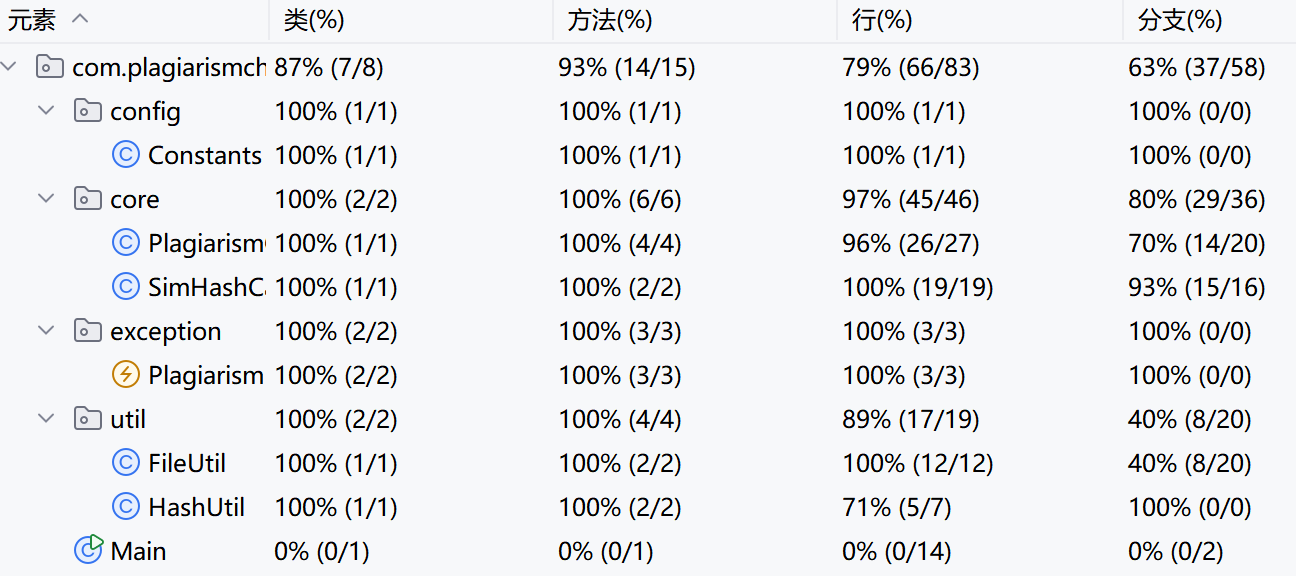
🧩五、计算模块部分异常处理说明
空输入异常 (NullInputException)
设计目标: 防止空输入导致的潜在空指针异常,提高系统的稳定性。
// NullInputException.java
public class NullInputException extends RuntimeException {
public NullInputException(String message) {
super(message);
}
}
// PlagiarismCheckerTest.java
import org.junit.Test;
import static org.junit.Assert.*;
public class PlagiarismCheckerTest {
@Test(expected = NullInputException.class)
public void testNullInput() {
PlagiarismChecker.checkPlagiarism(null, "Some text");
}
}
错误场景: 当用户提供空文本作为输入时,例如忘记上传文件或文件内容为空。
🧩附录:代码签入记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号