
MySQL
一、 ACID
1.1 原子性(Atomicity)
原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做,如果事务中一个sql语句执行失败,则已执行的语句也必须回滚,数据库退回到事务前的状态。
InnoDB是靠undo log实现回滚,当事务对数据库进行修改时,InnoDB会生成对应的undo log;如果事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。undo log数据逻辑日志,它记录的是sql执行相关的信息。当回滚时,InnoDB会根据undo log做与之相反的操作,对于insert会执行delete,对于update会执行与之相反的update(当事务执行update时,其生成的undo log会包含被修改行的主键、修改了哪些列、修改前的值等以便于回滚)。
1.2 一致性(Consistency)
一致性指的是事务不能破坏数据的完整性(实体完整性、列完整性、外键约束等)和业务的一致性(事务的一致性操作)。从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。
1.3 隔离性(Isolation)
隔离性是指事务内部的操作与事务是隔离的,并发执行的各个事务之间不能互相干扰。(一个事务)写操作对(另一个事务)写操作的影响:锁机制保证隔离性;(一个事务)写操作对(另一个事务)读操作的影响:MVCC保证隔离性。
a>锁机制
锁机制的基本原理可以概况为:事务在修改数据之前,需要先获得相应的锁;获得锁之后,事务便可以修改数据;该事务操作期间,这部分数据是锁定的,其他事务如果想要修改该数据需要等当前事务提交或回滚后释放锁。
b>隔离级别
读未提交(脏读)、读已提交(不可重复读)Oracle默认、可重复读(幻读)MySQL默认、串行化
c>MVCC(MySQL InnoDB RR)
Read View:
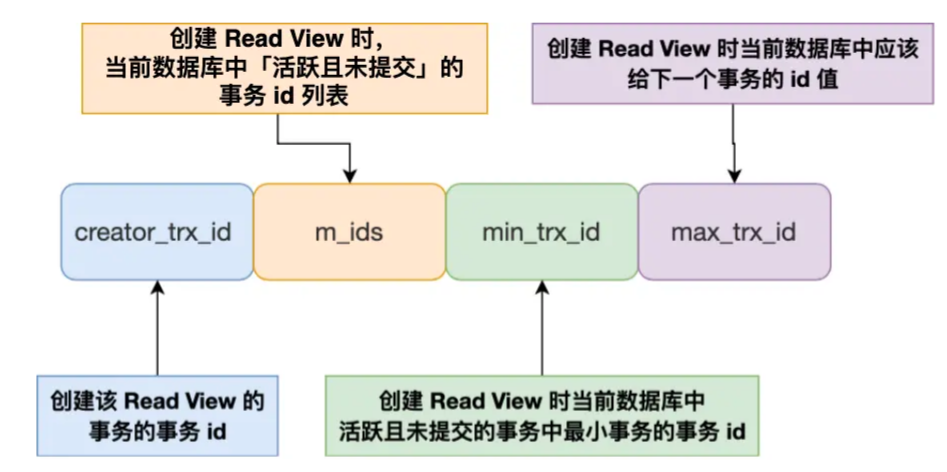
- creator_trx_id:创建该Read View的事务id
- m_ids:在创建Read View时,当前数据库中活跃事务的事务id列表。其中“活跃事务”指启动了但还没有提交的事务
- min_trx_id:在创建Read View时,当前数据中活跃事务中事务id最小的事务,也就是m_ids中的最小值
- max_trx_id:在创建Read View时当前数据库中应该给下一个事务的id值,也就是全局事务中最大的事务id值+1
版本链:MySQL的每行记录逻辑上其实是一个链表。MySQL行记录中除了业务数据外,还有隐藏的trx_id和roll_ptr
- trx_id:表示最近修改的事务id,每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。新增一个事务时,trx_id会递增,因此trx_id能够表示事务开始的先后顺序。
- roll_pointer:指向该行上一个版本的地址,每次对某条聚簇索引记录进行改动时,都会把旧的版本写入undo日志中,然后这个隐藏列相当于一个指针,可以通过它来找到该记录修改前的信息。
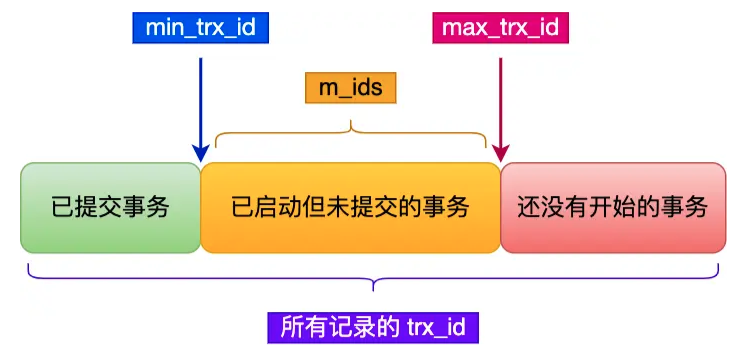
- 如果记录的trx_id值小于Read View中的min_trx_id值,表示这个版本的记录在创建Read View前已经提交的事务生成,所以该版本的记录对当前事务可见
- 如果记录的trx_id值大于等于Read View中的max_trx_id值,表示这个版本的记录在创建Read View后才启动的事务生成,所以该版本的记录对当前事务不可见
- 如果记录的trx_id在min_trx_id和max_trx_id之间,需要判断trx_id是否在m_ids列表中:
- 如果trx_id在m_ids中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见
- 如果trx_id不在m_ids中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select ... for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select ... for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
1.4 持久性(Durability)
持久性是指事务一旦提交,它对数据库的改变就应该是永久的,接下来的其他操作或故障不应该对其产生影响。InnoDB是靠redo log实现持久性的。
a>Buffer Pool
InnoDB作为MySQL的存储引擎,数据是存放在磁盘中的,但如果每次读写数据都需要磁盘IO,效率会很低。为此,InnoDB提供了缓存(Buffer Pool),Buffer Pool中包含了磁盘中部分数据页(默认16 KB)的映射, 作为访问数据库的缓冲。当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool中。当想数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)。
Buffer Pool的使用大大提高了读写数据的效率,但是也带来了新的问题。如果MySQL宕机,而此时Buffer Pool 中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
b>redo log
redo log的出现就是为了解决InnoDB的持久性问题。当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;当事务提交时,会调用fsync接口对redo log进行刷盘。如果MySQL宕机,重启时可以读取redo log中的数据,对数据进行恢复。redo log采用的是WAL(write ahead logging)预写日志,指的是 MySQL 的写操作并不是立刻更新到磁盘上,而是先记录在日志上,然后在合适的时间再更新到磁盘上。
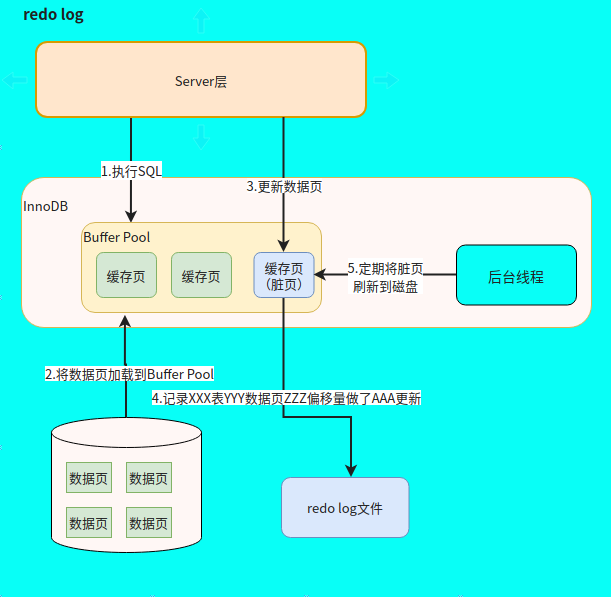
既然redo log(环形写入)也需要在事务提交时将日志写入磁盘,为什么它比直接将Buffer Pool中修改的数据写入磁盘(即刷脏)要快呢?主要有以下两方面的原因:
(1)刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO。
(2)刷脏是以数据页(Page)为单位的,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。
二、 binlog
2.1 binlog的原理和流程
二进制日志(binlog):1.用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步;2.用于数据库的基于时间点的还原。
binlog刷盘流程:
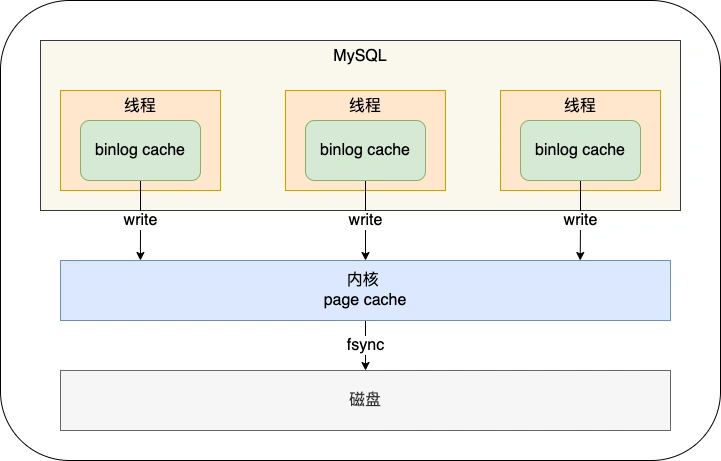
MySQL 给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
MySQL提供一个 sync_binlog 参数来控制数据库的 binlog 刷到磁盘上的频率:
- sync_binlog = 0 的时候,表示每次提交事务都只 write,不 fsync,后续交由操作系统决定何时将数据持久化到磁盘;
- sync_binlog = 1 的时候,表示每次提交事务都会 write,然后马上执行 fsync;
- sync_binlog =N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
2.2 redo log 与 binlog的区别
- redo log是属于InnoDB层面,binlog属于MySQL Server层面的,这样在数据库用别的存储引擎时可以达到一致性的要求。
- redo log是物理日志,记录该数据页更新的内容;binlog是逻辑日志,记录的是这个更新语句的原始逻辑
- redo log是循环写,日志空间大小固定;binlog是追加写,是指一份写到一定大小的时候会更换下一个文件,不会覆盖。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
三、主从复制
3.1 主从复制的实现原理
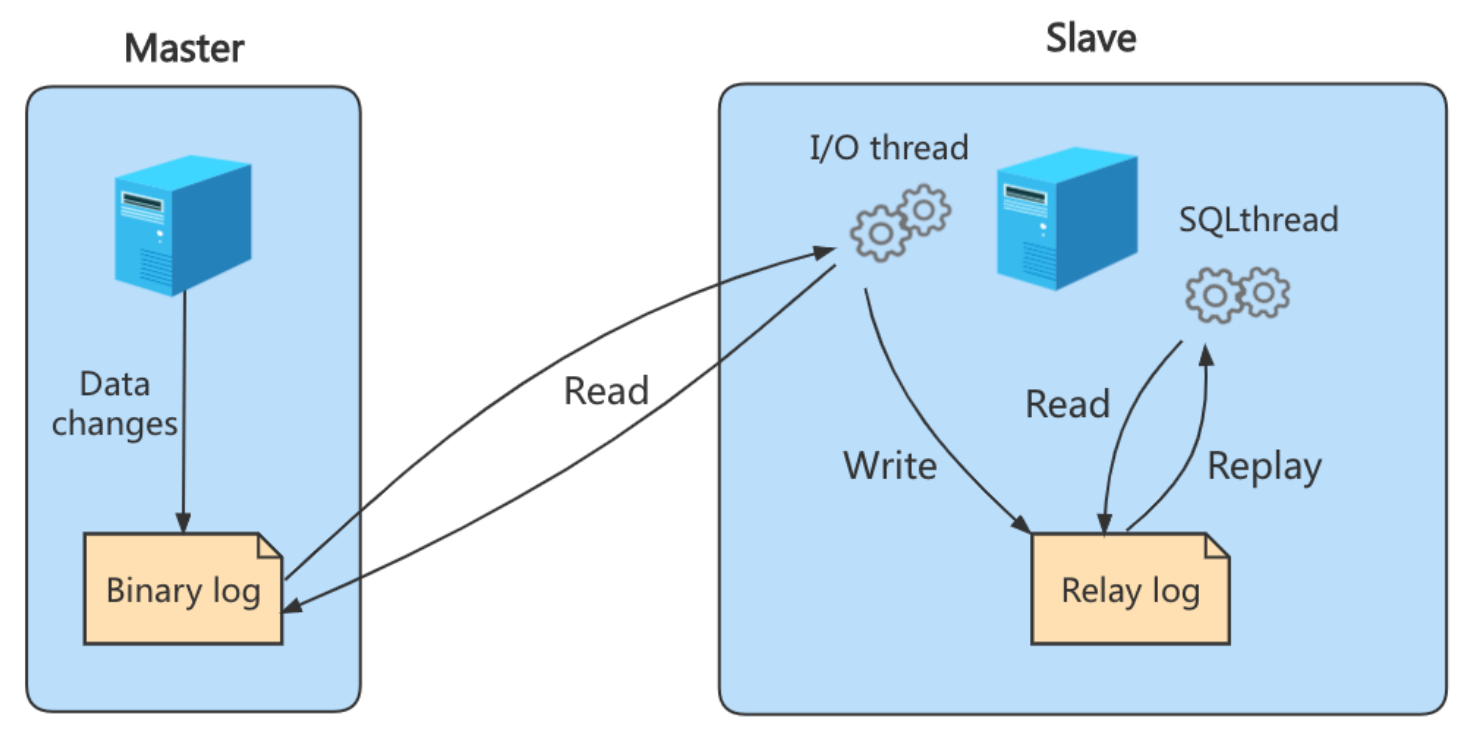
- MySQL主库在收到客户端提交事务的请求后,会先写入binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应
- 从库会创建一个专门的I/O线程,连接主库的log dump线程,来接收主库的binlog日志,再把binlog信息写入relay log的中继日志里,再返回给主库“复制成功”的响应
- 从库会创建一个用于回放日志的线程,去读relay log中继日志,然后回放更新存储引擎中的数据,最终实现主从的数据一致性。
3.2 主从复制从库是不是越多越好?
不是的。因为从库数量增加,从库连接上来的I/O线程也比较多,主库也要创建同样多的log dump线程来处理复制的请求,对主库资源消耗比较高,同时还受限于主库的网络带宽。
3.3 主从复制的模型
- 同步复制:MySQL主库提交事务的线程要等待所有从库的复制成功响应,才返回客户端结果。问题:性能差,因为要复制到所有节点才返回响应;可用性差,主库和所有从库任何一个数据库除问题,都会影响业务
- 异步复制(默认模型):MySQL主库提交事务的线程并不会等待binlog同步到各从库,直接返回客户端。问题:主库宕机,数据会发生丢失
- 半同步复制:MySQL 5.7版本后增加的一种复制方式,介于二者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应即可。兼顾异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库为最新数据,不存在数据丢失的风险。
3.4 主从复制的延迟问题
- 主库DML请求频繁(TPS较大)
- 原因:主库并发写入数据,而从库SQL Thread为单线程应用日志,很容易造成relaylog堆积产生延迟。
- 思路:做sharding,打散写请求。考虑升级MySQL 5.7+,开启基于逻辑时钟的并行复制
- 主库执行大事务
- 原因:在主从库配置相近的情况下,主库花费很长时间更新一张大表,从库也需要花费几乎相同的时间更新,导致从库延迟堆积
- 思路:拆分大事务,及时提交
- 主库对大表执行DDL语句
- 原因:DDL未开始执行,被阻塞,SHOW SLAVE STATUS检查到Slave_SQL_Running_State为waiting for table metadata lock,且Exec_Master_Log_Pos不变;DDL正在执行,单线程应用导致延迟增减,Slave_SQL_Running_State为altering table,Exec_Master_Log_Pos不变。
- 思路:通过processlist或information_schema.innodb_trx来找到阻塞DDL语句的查询,干掉该查询,让DDL正常在从库执行。建议考虑:① 业务低峰期执行;②set sql_log_bin=0后,分别在主从库上手动执行DDL(此操作对于某些DDL操作会造成数据不一致,请务必严格测试)
- 主从实例配置不一致
- 原因:主库实例服务器使用SSD,而从库实例服务器使用普通SAS盘、cpu主频不一致等;如RAID卡写策略不一致,OS内核参数设置不一致,MySQL落盘策略不一致等
- 思路:尽量统一DB机器的配置(包括硬件及选项参数);甚至对于某些OLAP业务,从库实例硬件配置高于主库等
- 从库自身压力过大
- 原因:从库执行大量的select请求,或者从库正在备份等,此时可能造成cpu负载过高,io利用率过高等,导致SQL Thread应用过慢
- 思路:建立更多从库,打散读请求,降低现有从库实例的压力
- 网络延迟
- 网络通信状况也会影响主从复制(影响从库的IO线程获取主库binlog),只能升级带宽,优化网络。
四、两阶段提交
4.1 MySQL中两阶段提交的应用
redo log和binlog 都要持久化到磁盘,但是这两个独立的逻辑,可能出现半成功的状态,这样会造成两份日志之间的逻辑不一致。如果将redo log刷入磁盘后,MySQL宕机了,而binlog还没有来得及写入。MySQL重启,主库会更新而从库不会更新。如果将binlog刷入到磁盘后,MySQL宕机了,而redo log还没有来得及写入。MySQL重启,主库不会更新而从库会更新。
MySQL为了避免出现两份日志之间的逻辑不一致问题,使用了【两阶段提交】来解决。两阶段提交把单个事务的提交拆分成2个阶段,分别是【准备(Prepare)阶段】和【提交(commit)阶段】。MySQL的内部开启一个XA事务,分两阶段爱完成XA事务的提交。
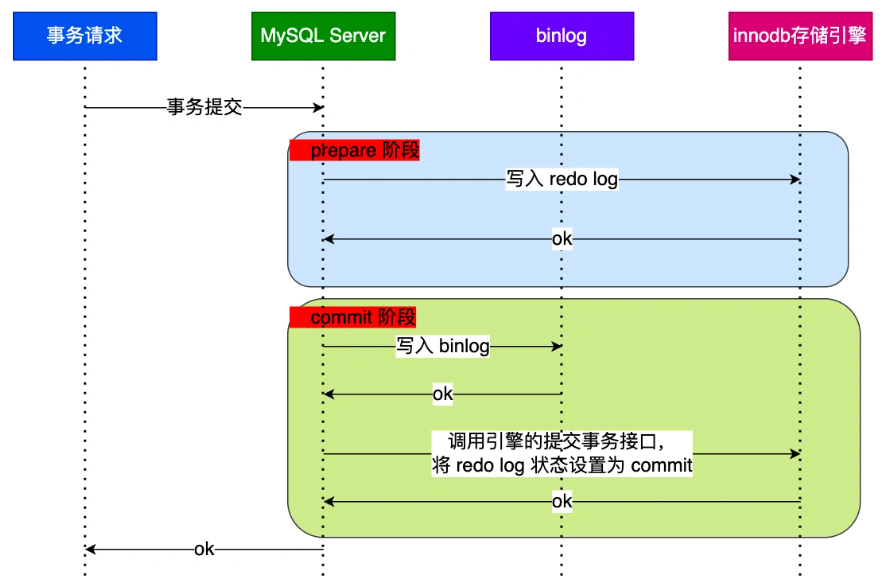
- prepare阶段:将XID(内部XA事务的ID)写入到redo log,同时将redo log对应的事务状态设置为prepare,然后将redo log刷新到硬盘
- commit阶段:把XID写入到binlog,然后将binlog刷新到磁盘,接着调用InnoDB的提交事务接口,将redo log状态设置为commit(将事务设置为commit状态后,刷入到磁盘redo log文件,所以commit状态也是会刷盘的)
4.2 异常重启会出现什么现象?
- 如果 binlog 中没有当前内部 XA 事务的 XID,说明 redolog 完成刷盘,但是 binlog 还没有刷盘,则回滚事务。
- 如果 binlog 中有当前内部 XA 事务的 XID,说明 redolog 和 binlog 都已经完成了刷盘,则提交事务。
对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。
4.3 两阶段提交的问题
- 磁盘I/O次数高:对于“双1”配置( sync_binlog = 1、innodb_flush_log_at_trx_commit = 1),每个事务提交都会进行两次fsync(刷盘),一次是redo log刷盘,另一次是binlog刷盘
- 锁竞争激烈:两阶段提交虽然保证单事务两个日志的内容一致,但是在多事务的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证在多事务的情况下两个日志的提交顺序一致。
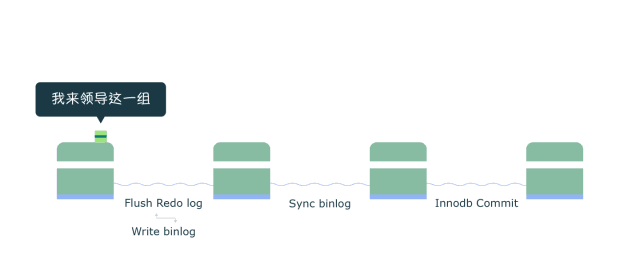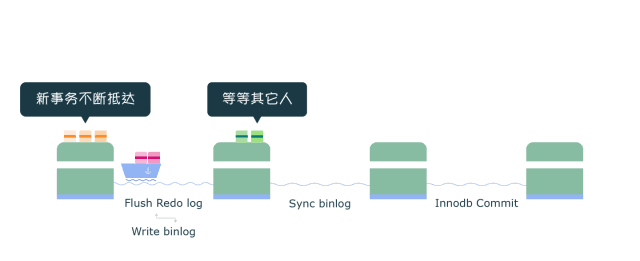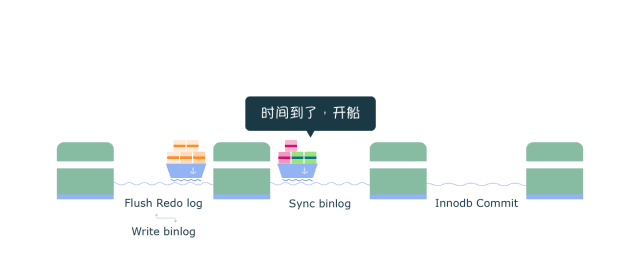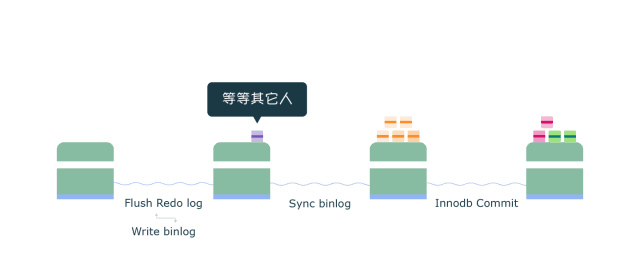
4.4 组提交
Binlog 组提交
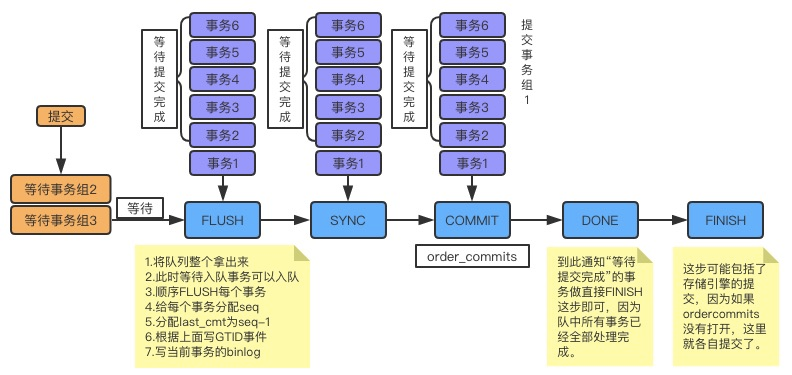
在MySQL中每个阶段都有一个队列,每个队列都有一把锁保护,第一个进入队列的事务会成为leader,leader领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
五、索引
5.1 索引的定义、数据结构和类型
5.2 索引的选择策略
#建表 CREATE TABLE `t` ( `id` INT ( 11 ) NOT NULL AUTO_INCREMENT, `a` INT ( 11 ) NOT NULL, `b` INT ( 11 ) NOT NULL, PRIMARY KEY ( `id` ), KEY `a` ( `a` ) USING BTREE, KEY `b` ( `b` ) USING BTREE ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4; #定义测试数据存储过程 delimiter; CREATE DEFINER = `root` @`10.%` PROCEDURE `idata` ( ) BEGIN DECLARE i INT DEFAULT 1; WHILE i <= 100000 DO INSERT INTO t ( id, a, b ) VALUES ( i, i, i ); SET i = i + 1; END WHILE; END delimiter; #执行存储过程,插入测试数据 call idata();
a>优化器目的
优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。优化器选择索引的依据有(或者说下面的条件都可能对选择产生影响):
- 扫描的行数(基于采样)
- 是否回表操作
- 是否使用临时表
- 是否使用排序或者文件排序
b>干预优化器
如果执行计划(explain)不是按照我们的预期执行,那么可以采用一些引导或强制措施:
- 使用 force index 强行选择一个索引。select * from t force index(索引名称) where ...
- 可以考虑修改语句,引导需要期望的结果。比如:order by b limit 1 -> order by b,a limit 1
- 在某些场景下可以新建一个更适合的索引,提供给优化器选择,或者删除可能误导的索引【与业务耦合度很高】
-- 查看执行计划,使用了字段a上的索引 mysql> explain select * from t where a between 10000 and 20000; +----+-------------+-------+-------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | t | range | a | a | 4 | NULL | 10000 | Using where | +----+-------------+-------+-------+---------------+------+---------+------+-------+-------------+ --由于需要进行字段b排序,虽然索引b需要扫描更多的行数,但本身是有序的,综合扫描行数和排序,优化器选择了索引b,认为代价更小 mysql> explain select * from t where (a between 10000 and 20000) and (b between 50000 and 100000) order by b limit 1; +----+-------------+-------+-------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE index强制走索引a,纠正优化器错误的选择,不建议使用(不通用,且索引名称更变语句也需要变) mysql> explain select * from t force index (a) where (a between 10000 and 20000) and (b between 50000 and 100000) order by b limit 1; +----+-------------+-------+-------+---------------+------+---------+------+-------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+-------+-----------------------------+ | 1 | SIMPLE | t | range | a | a | 4 | NULL | 10000 | Using where; Using filesort | +----+-------------+-------+-------+---------------+------+---------+------+-------+-----------------------------+ -- 方案2:引导 MySQL 使用我们期望的索引,按b,a排序,优化器需要考虑a排序的代价 mysql> explain select * from t where (a between 10000 and 20000) and (b between 50000 and 100000) order by b,a limit 1; +----+-------------+-------+-------+---------------+------+---------+------+-------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+-------+-----------------------------+ | 1 | SIMPLE | t | range | a,b | a | 4 | NULL | 10000 | Using where; Using filesort | +----+-------------+-------+-------+---------------+------+---------+------+-------+-----------------------------+ -- 方案3:有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引 ALTER TABLE `t` DROP INDEX `a`, DROP INDEX `b`, ADD INDEX `ab` (`a`,`b`) ;
c>采样原理
一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,称之为“基数”(cardinality)
mysql> show index from t; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | t | 0 | PRIMARY | 1 | id | A | 100302 | NULL | NULL | | BTREE | | | | t | 1 | a | 1 | a | A | 100302 | NULL | NULL | | BTREE | | | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
从性能的角度考虑,InnoDB 使用采样统计,默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。因此,上述两个索引显示的基数只是一个近似值。而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1/M 的时候(innodb_stats_persistent=on时M=20,N=10;off时M=8,N=16),会自动触发重新做一次索引统计。
附录:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号