
Redis常用数据类型及其存储结构(源码篇)
正文
一、SDS
1,SDS源码解读
sds (Simple Dynamic String),Simple的意思是简单,Dynamic即动态,意味着其具有动态增加空间的能力,扩容不需要使用者关心。String是字符串的意思。说白了就是用C语言自己封装了一个字符串类型,这个项目由Redis作者antirez创建,作为Redis中基本的数据结构之一,现在也被独立出来成为了一个单独的项目,项目地址位于这里。
sds 有两个版本,在Redis 3.2之前使用的是第一个版本,其数据结构如下所示:
typedef char *sds; //注意,sds其实不是一个结构体类型,而是被typedef的char* struct sdshdr { unsigned int len; //buf中已经使用的长度 unsigned int free; //buf中未使用的长度 char buf[]; //柔性数组buf };
但是在Redis 3.2 版本中,对数据结构做出了修改,针对不同的长度范围定义了不同的结构,如下,这是目前的结构:

typedef char *sds; struct __attribute__ ((__packed__)) sdshdr5 { // 对应的字符串长度小于 1<<5 unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { // 对应的字符串长度小于 1<<8 uint8_t len; /* used */ // 目前字符创的长度,使用1个byte uint8_t alloc; // 已经分配的总长度,使用1个byte unsigned char flags; // flag用3bit来标明类型,类型后续解释,其余5bit目前没有使用。使用1byte。 char buf[]; // 柔性数组,以'\0'结尾 }; struct __attribute__ ((__packed__)) sdshdr16 { // 对应的字符串长度小于 1<<16 uint16_t len; /* used,使用2byte */ uint16_t alloc; /* excluding the header and null terminator,使用2byte */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { // 对应的字符串长度小于 1<<32 uint32_t len; /* used,使用4byte */ uint32_t alloc; /* excluding the header and null terminator,使用4byte */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { // 对应的字符串长度小于 1<<64 uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };
2,SDS的特点
- 二进制安全的数据结构,不会产生数据的丢失
- 内存预分配机制,避免了频繁的内存分配。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。(字符串最大长度为 512M)
- 兼容c语言函数库
二、Redis中几种数据结构
redisDb 默认情况下有16个,每个 redisDb 内部包含一个 dict 的数据结构,dict 内部包含 dictht 数组,数组个数为2,主要用于 hash 扩容使用。dictht 内部包含 dictEntry 的数组,dictEntry 其实就是 hash 表的一个 key-value 节点,如果冲突通过 链地址法 解决
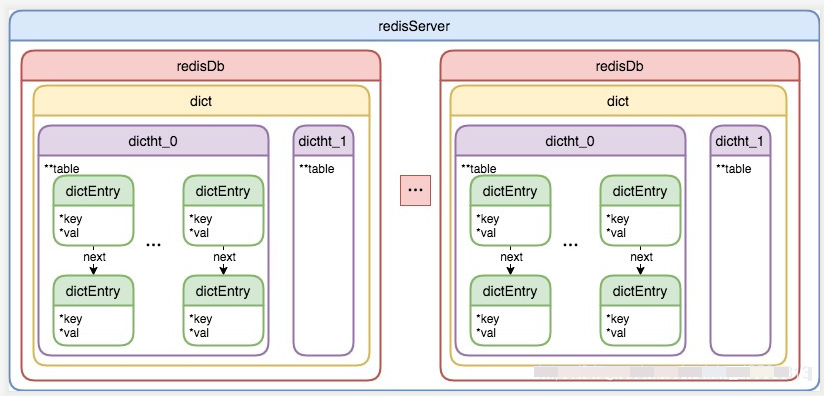
1,redisServer
数据结构 redisServer 是一个 redis 服务端的抽象,定义在server.h中。 redisServer中的属性非常多,以下为节选的一部分,简单介绍下
struct redisServer { /* General */ pid_t pid; /* Main process pid. */ ...... int hz; /* serverCron() calls frequency in hertz */ redisDb *db; dict *commands; /* Command table */ dict *orig_commands; /* Command table before command renaming. */ aeEventLoop *el; ...... char runid[CONFIG_RUN_ID_SIZE+1]; /* ID always different at every exec. */ ...... list *clients; /* List of active clients */ list *clients_to_close; /* Clients to close asynchronously */ list *clients_pending_write; /* There is to write or install handler. */ list *clients_pending_read; /* Client has pending read socket buffers. */ list *slaves, *monitors; /* List of slaves and MONITORs */ client *current_client; /* Current client executing the command. */ ...... };
hz: redis 定时任务触发的频率*db: redisDb 数组,默认 16 个 redisDb*commands: redis 支持的命令的字典*el: redis 事件循环实例runid[CONFIG_RUN_ID_SIZE+1]: 当前 redis 实例的 runid
2,redisDb
redisDb 是 redis 数据库的抽象,定义在 server.h 中,比较关键的属性如下
typedef struct redisDb { dict *dict; /* 键值对字典,保存数据库中所有的键值对 */ dict *expires; /* 过期字典,保存着设置过期的键和键的过期时间*/ dict *blocking_keys; /*保存着 所有造成客户端阻塞的键和被阻塞的客户端 (BLPOP) */ dict *ready_keys; /* 保存着 处于阻塞状态的键,value为NULL*/ dict *watched_keys; /* 事物模块,用于保存被WATCH命令所监控的键 */ // 当内存不足时,Redis会根据LRU算法回收一部分键所占的空间,而该eviction_pool是一个长为16数组,保存可能被回收的键 // eviction_pool中所有键按照idle空转时间,从小到大排序,每次回收空转时间最长的键 struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */ int id; /* 数据库ID */ long long avg_ttl; /* 键的平均过期时间 */ } redisDb;
3,dict
dict 是 redis 中的字典,定义在 dict.h 文件中,其主要的属性如下
typedef struct dict { dictType *type; void *privdata; dictht ht[2]; //方便渐进的rehash扩容,dict的hashtable long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict;
ht[2]: 哈希表数组,为了扩容方便有 2 个元素,其中一个哈希表正常存储数据,另一个哈希表为空,空哈希表在 rehash 时使用rehashidx:rehash 索引,当不在进行 rehash 时,值为 -1
4,dictht
dictht 是哈希表结构,定义在 dict.h 文件中,其重要的属性如下
typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht;
**table: key-value 键值对节点数组,类似 Java 中的 HashMap 底层数组size: 哈希表容量大小sizemask: 总是等于 size - 1,用于计算索引值used: 哈希表实际存储的 dictEntry 数量
5,dictEntry
dictEntry 是 redis 中的 key-value 键值对节点,是实际存储数据的节点,定义在 dict.h 文件中,其重要的属性如下
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry;
*key: 键对象,总是一个字符串类型的对象 SDS*val: 值对象,可能是任意类型的对象。对应常见的5种数据类型:string,hash,list,set,zset*next: 尾指针,指向下一个节点
三、数据类型
1,Redis数据对象结构
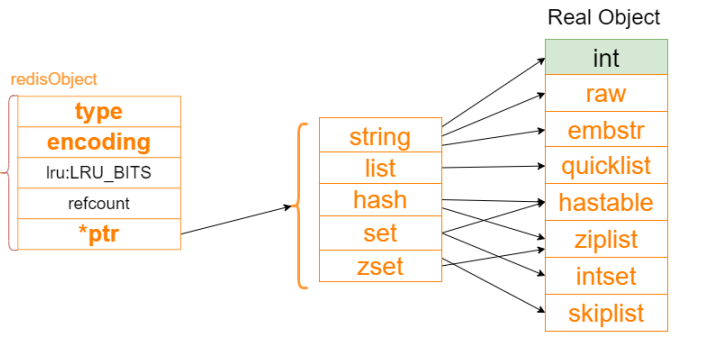
Redis 数据库中所有数据都以 key-value 节点 dictEntry 存储,其中 key 和 value 都是一个 redisObject 结构体对象,只不过 key 总是一个字符串类型的对象(SDS),value 则可能是任意一种数据类型的对象。 redisObject 结构体定义在 server.h 中如下所示
typedef struct redisObject { unsigned type:4; //占用4bit unsigned encoding:4; //占用4bit unsigned lru:LRU_BITS; /*占用24bit LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; //占用4byte void *ptr; //占用8byte 总空间:4bit+4bit+24bit+4byte+8byte = 16byte } robj;
可以看到该结构体中重要的属性如下,不同的对象具有不同的类型 type,同一个类型的 type 会有不同的存储形式 encoding
type: 该属性标明了数据对象的类型,比如 String,List 等encoding: 这个属性指明了对象底层的存储结构,比如 ZSet 类型对象可能的存储结构有 ZIPLIST 和 SKIPLIST*ptr: 指向底层存储结构的指针
2,Redis数据类型及存储结构
Redis 中数据类型及其存储结构定义在 server.h 文件中
/* The actual Redis Object */ #define OBJ_STRING 0 /* String object. */ #define OBJ_LIST 1 /* List object. */ #define OBJ_SET 2 /* Set object. */ #define OBJ_ZSET 3 /* Sorted set object. */ #define OBJ_HASH 4 /* Hash object. */ #define OBJ_MODULE 5 /* Module object. */ #define OBJ_STREAM 6 /* Stream object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
四、Redis中常用数据类型和结构
1,字符串对象String
OBJ_STRING 字符串对象底层数据结构一般为简单动态字符串(SDS),但其存储方式可以是 OBJ_ENCODING_INT、OBJ_ENCODING_EMBSTR 和 OBJ_ENCODING_RAW,不同的存储方式代表着对象内存结构的不同。
a)OBJ_ENCODING_INT
如果保存的字符串长度小于 20 并且可以解析为整数(值范围为:-2^63 ~ 2^63-1),那么这个整数就会直接保存在 redisObject 的 ptr 属性里
b)OBJ_ENCODING_EMBSTR
长度小于 44 (OBJ_ENCODING_EMBSTR_SIZE_LIMIT)的字符串将以简单动态字符串(SDS) 的形式存储,但是会使用 malloc 方法一次分配内存,将 redisObject 对象头和 SDS 对象连续存在一起。因为默认分配空间为64byte,而其中value为string类型采用sdshdr8中len、alloc、flags各占用1byte,buf以'\0'占用1byte,redisObject占用16字节,剩余buff可使用为64-4-16=44byte。
c)OBJ_ENCODING_RAW
字符串将以简单动态字符串(SDS)的形式存储,需要两次 malloc 分配内存,redisObject 对象头和 SDS 对象在内存地址上一般是不连续的
d)检测
#string类型查看redis的存储 SET key value //存入字符串键值对 STRLEN key //查看key的长度(占用的byte字节) OBJECT ENCODING key //查看key在redis中的存储类型 SETRANGE key offset value //修改key从offset(字符偏移量)字符修改为value,如果原本为embstr修改后也会变成raw。 GETRANGE key start end //获取key的部分值
2,列表对象list
OBJ_LIST 列表对象的底层存储结构有过 3 种实现,分别是 OBJ_ENCODING_LINKEDLIST、 OBJ_ENCODING_ZIPLIST 和 OBJ_ENCODING_QUICKLIST,其中 OBJ_ENCODING_LINKEDLIST 在 3.2 版本以后就废弃了。使用命令:OBJECT ENCODING key 查看存储类型。
a)OBJ_ENCODING_LINKEDLIST
底层采用双端链表实现,每个链表节点都保存了一个字符串对象,在每个字符串对象内保存了一个元素。
b)OBJ_ENCODING_ZIPLIST
底层实现类似数组,使用特点属性保存整个列表的元信息,如整个列表占用的内存大小,列表保存的数据开始的位置,列表保存的数据的个数等,其保存的数据被封装在 zlentry。
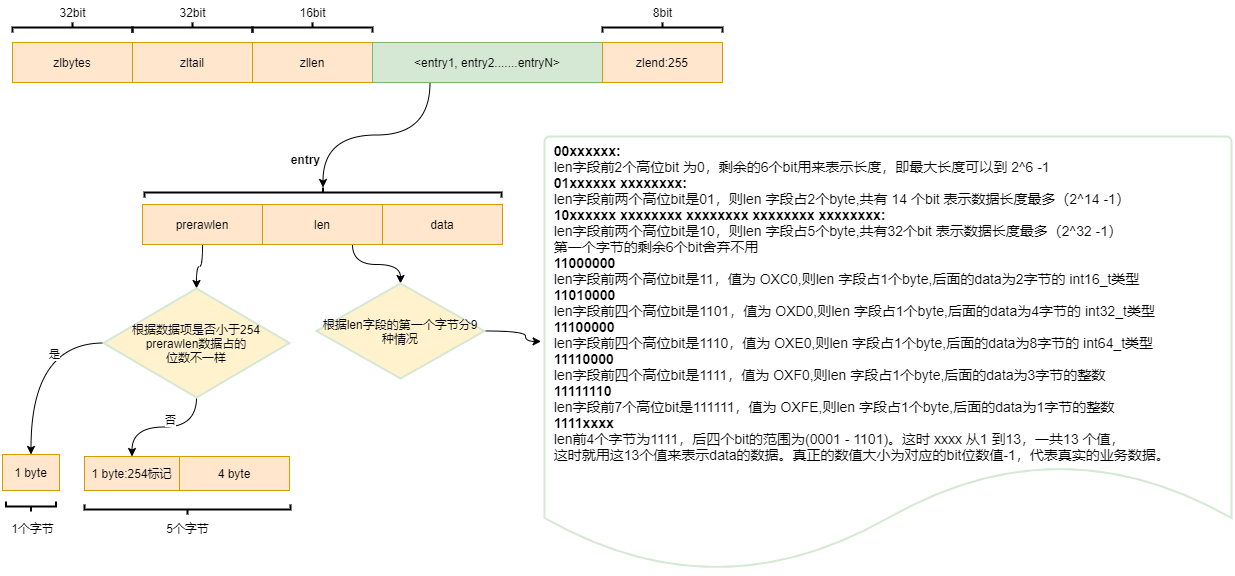
- zlbytes:记录整个压缩列表占用的内存字节数。uint_32_t,4byte。
- zltail:记录压缩列表表尾节点距离起始地址有多少字节,通过这个偏移量,程序无需遍历整个压缩列表就能确定表尾节点地址。uint_32_t,4byte。
- zlen:记录压缩列表包含的节点数量。uint_16_t,2byte。
- entryX:压缩列表的各个节点,节点长度由保存的内容决定。
- zlend:特殊值(
0xFFF),用于标记压缩列表末端。uint_8_t,1byte。- prerawlen:表示当前节点的前一个节点长度
- len:当前节点的长度
- data:当前节点的数据
c)OBJ_ENCODING_QUICKLIST
底层采用双端链表结构,不过每个链表节点都保存一个 ziplist,数据存储在 ziplist 中
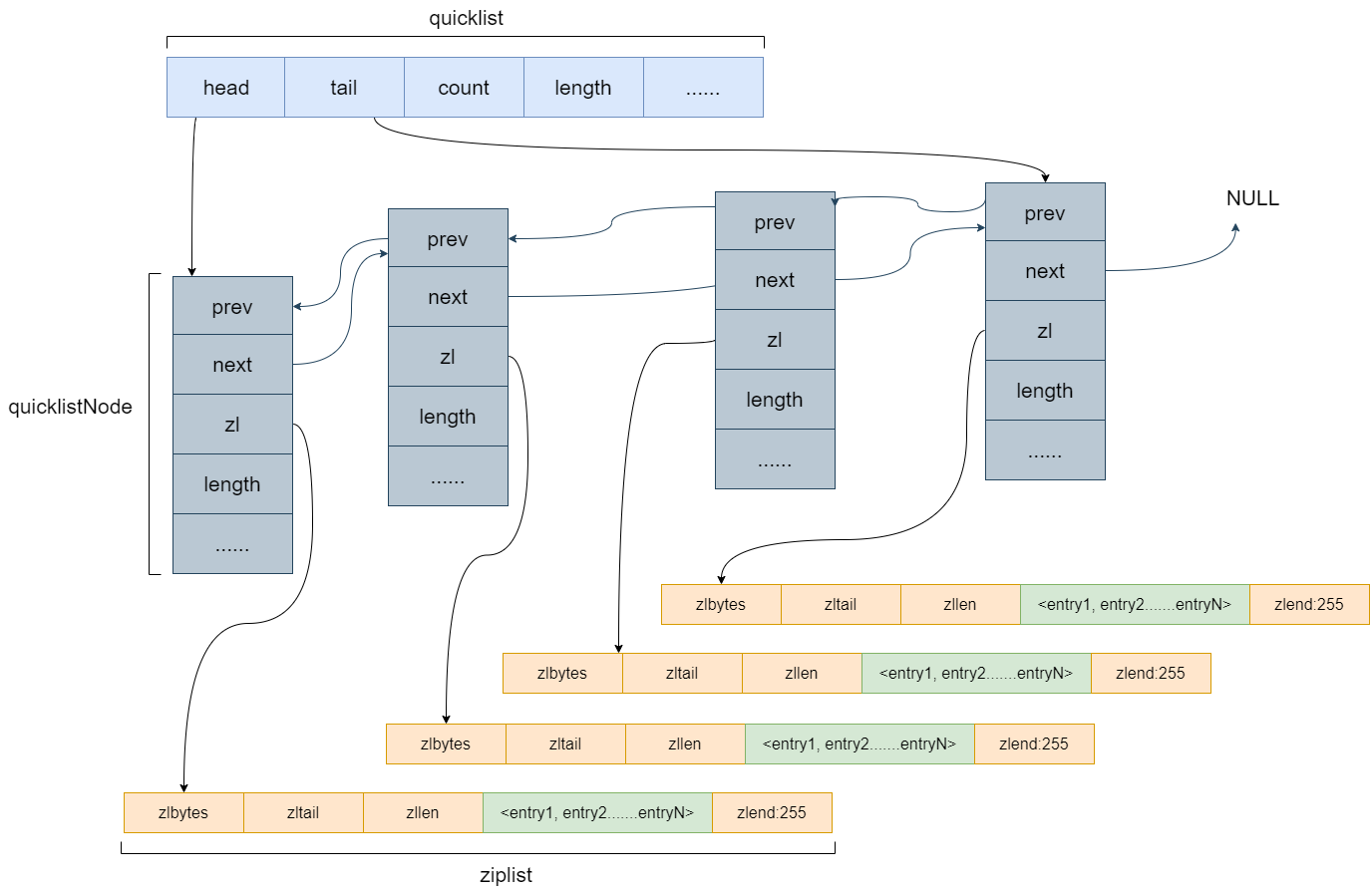
d)redis.conf配置
通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率。
list-max-ziplist-size -2 //单个ziplist节点最大能存储8kb,超过则进行分裂,将数据存储在新的ziplist节点中 list-compress-depth 0 //0代表所有节点,都不进行压缩。1,代表从头节点往后走一个,尾部节点往前走一个不用压缩,其他的全部压缩。
3,集合对象Set
OBJ_SET集合对象的底层存储结构有两种,OBJ_ENCODING_HT和OBJ_ENCODING_INTSET
a)OBJ_ENCODING_INTSET
typedef struct intset { uint32_t encoding; //编码类型 uint32_t length; //元素个数 int8_t contents[]; //元素数据 } intset; //redis中保存整型的编码类型有int16_t,int32_t,int64_t #define INTSET_ENC_INT16(sizeof(int16_t)) #define INTSET_ENC_INT32(sizeof(int32_t)) #define INTSET_ENC_INT64(sizeof(int64_t))
集合保存的所有元素都是整数值将会采用这种存储结构,但①当集合对象保存的元素数量超过512 (由server.set_max_intset_entries 配置)或者②元素无法用整型表示后会转化为 OBJ_ENCODING_HT
b)OBJ_ENCODING_HT
底层为dict字典,数据作为字典的键保存,键对应的值都是NULL,与 Java 中的 HashSet 类似
4,有序集合ZSet
OBJ_ZSET 有序集合对象的存储结构分为 OBJ_ENCODING_SKIPLIST 和 OBJ_ENCODING_ZIPLIST
a)OBJ_ENCODING_ZIPLIST
当 ziplist 作为 zset 的底层存储结构时,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素值,第二个元素保存元素的分值,而且分值小的靠近表头,大的靠近表尾
有序集合对象使用 ziplist 存储需要同时满足以下两个条件,不满足任意一条件将使用 skiplist
- 所有元素长度小于64 (server.zset_max_ziplist_value 配置)字节
- 元素个数小于128 (server.zset-max-ziplist-entries 配置)
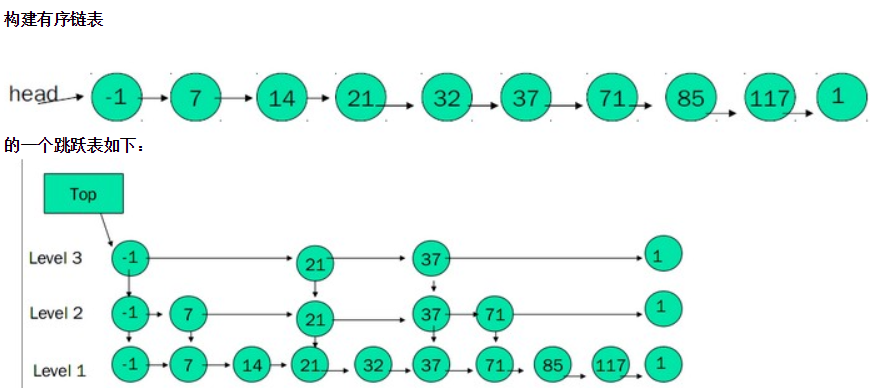
b)OBJ_ENCODING_SKIPLIST
底层实现是跳跃表结合字典。每个跳跃表节点都保存一个集合元素,并按分值从小到大排列,节点的 object 属性保存了元素的值,score属性保存分值;字典的每个键值对保存一个集合元素,元素值包装为字典的键,元素分值保存为字典的值。
skiplist 同时使用跳跃表和字典实现的原因:
- 跳跃表优点是有序,但是查询分值时复杂度为O(logn);字典查询分值(zscore命令)复杂度为O(1) ,但是无序,结合两者可以实现优势互补
- 集合的元素成员和分值是共享的,跳跃表和字典通过指针指向同一地址,不会浪费内存

5,哈希对象Hash
OBJ_HASH 的存储结构分为 OBJ_ENCODING_ZIPLIST 和 OBJ_ENCODING_HT(使用命令:OBJECT ENCODING key 查看存储类型),其实现如下:
a)OBJ_ENCODING_ZIPLIST
在以 ziplist 结构存储数据的哈希对象中,key-value 键值对以紧密相连的方式存入压缩链表,先把key放入表尾,再放入value;键值对总是向表尾添加。
- 哈希对象使用 ziplist 存储数据需要同时满足以下两个条件,不满足任意一个都使用 dict 结构
- 所有键值对的键和值的字符串长度都小于64 (server.hash_max_ziplist_value 配置)字节
- 键值对数量小于512(server.hash-max-ziplist-entries)个

b)OBJ_ENCODING_HT
底层为 dict 字典,哈希对象中的每个 key-value 对都使用一个字典键值对dictEntry来保存,字典的键和值都是字符串对象。
c)检测
HMSET key f1 v1 f2 v2 f3 v3 //在一个哈希表key中存储多个键值对 OBJECT ENCODING key //查看key在redis中的存储类型为ziplist HGETALL key //查看key对应的所有field和value发现为有序的 HSET key f4 x...x //在一个哈希表key中存储一个长度超过64的value HSTRLEN key f4 //查看key中field为f4的长度 OBJECT ENCODING key //查看key在redis中的存储类型为hashtable HGETALL key //查看key对应的所有field和value发现为无序


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话