
Redis分布式锁
一、分布式锁简介
1,什么是分布式锁
- 当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
- 与单机模式下的锁不仅需要保证进程可见,还需要考虑进程与锁之间的网络问题。
- 分布式锁还是可以将标记存在内存,只是该内存不是某个进程分配的内存而是公共内存如 Redis、Memcache。至于利用数据库、文件等做锁与单机的实现是一样的,只要保证标记能互斥就行。
2,分布式锁具备的条件
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
- 高可用的获取锁与释放锁;
- 高性能的获取锁与释放锁;
- 具备可重入特性;
- 具备锁失效机制,防止死锁;
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
二、采用Redis实现分布式锁
1,常规代码实现
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "product_001";
try {
/*Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "aaa"); //jedis.setnx
stringRedisTemplate.expire(lockKey, 30, TimeUnit.SECONDS); //设置超时*/
//为解决原子性问题将设置锁和设置超时时间合并
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "aaa", 10, TimeUnit.SECONDS);
//未设置成功,当前key已经存在了,直接返回错误
if (!result) {
return "error_code";
}
//业务逻辑实现,扣减库存
....
} catch (Exception e) {
e.printStackTrace();
}finally {
stringRedisTemplate.delete(lockKey);
}
return "end";
}
2,超时问题分析
上述代码可以看到,当前锁的失效时间为10s,如果当前扣减库存的业务逻辑执行需要15s时,高并发时会出现问题:
- 线程1,首先执行到10s后,锁(product_001)失效
- 线程2,在第10s后同样进入当前方法,此时加上锁(product_001)
- 当执行到15s时,线程1删除线程2加的锁(product_001)
- 线程3,可以加锁 .... 如此循环,实际锁已经没有意义
a)方案1:当前线程删除当前线程所加的锁
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "product_001";
//定义唯一的客户端ID
String clientId = UUID.randomUUID().toString();
try {
//为解决原子性问题将设置锁和设置超时时间合并,将clientID作为值放入锁中
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 10, TimeUnit.SECONDS);
//未设置成功,当前key已经存在了,直接返回错误
if (!result) {
return "error_code";
}
//业务逻辑实现,扣减库存
....
} catch (Exception e) {
e.printStackTrace();
}finally {
//只有在获取锁的值为当前clientId时才会进行删除锁操作
if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
stringRedisTemplate.delete(lockKey);
}
}
return "end";
}
这样能保证每个线程删除的锁为当前线程添加的锁,但是还是会有超卖的问题:因为线程1在还没有执行完成的时候,此时锁已经到达过期时间,此时线程2则会加锁成功
b)方案2:续命锁
定义一个子线程,定时去查看是否存在主线程的持有当前锁,如果存在则为其延长过期时间。
3,Redisson
a)简单实现
@Autowired Redisson redisson; @RequestMapping("/deduct_stock_redisson") public String deductStockRedisson() { String lockKey = "product_001"; RLock rlock = redisson.getLock(lockKey); try { rlock.lock(); //业务逻辑实现,扣减库存 .... } catch (Exception e) { e.printStackTrace(); } finally { rlock.unlock(); } return "end"; }
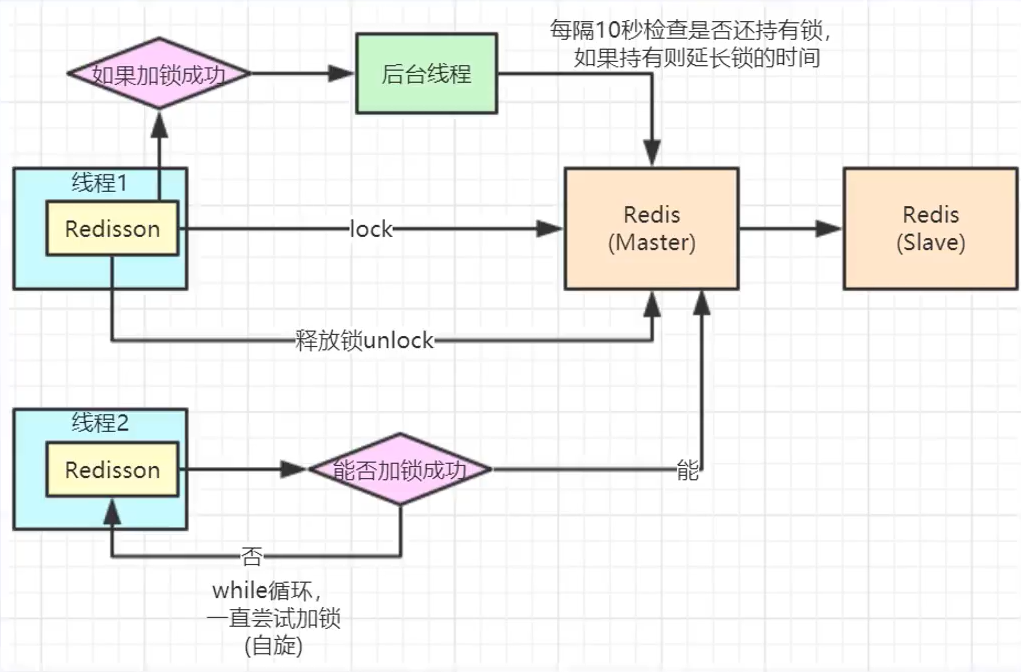
- 多个线程去执行lock操作,仅有一个线程能够加锁成功,其它线程循环阻塞。
- 加锁成功,锁超时时间默认30s,并开启后台线程,加锁的后台会每隔10秒去检测线程持有的锁是否存在,还在的话,就延迟锁超时时间,重新设置为30s,即锁延期。
- 对于原子性,Redis分布式锁底层借助Lua脚本实现锁的原子性。锁延期是通过在底层用Lua进行延时,延时检测时间是对超时时间timeout /3
b)tryLock()与lock()区别
-
lock()会阻塞等待
-
tryLock()尝试获取锁,返回值为是否获取都锁
c)Redisson的可重入锁
- Redis存储锁的数据类型是 Hash类型
- Hash数据类型的key值包含了当前线程信息。

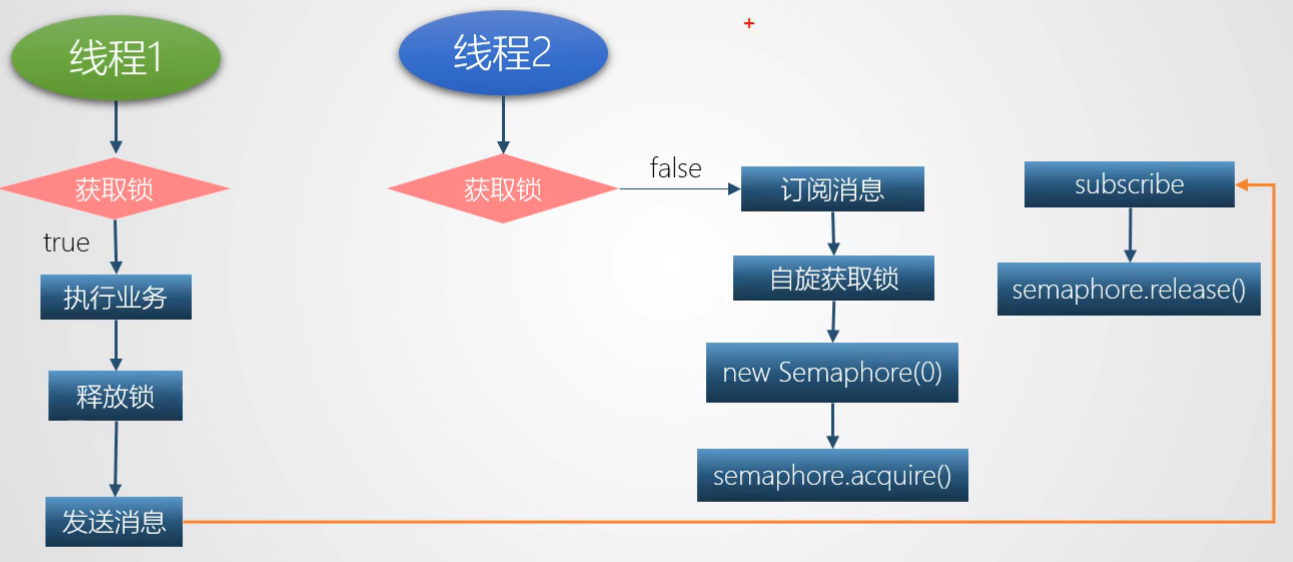
d)采用Mq和Semaphore
信号量主要用于两个目的
- 一个是用于共享资源的互斥使用
- 另一个用于并发线程数的控制
三、采用Redisson分布式锁的问题分析
1,主从同步问题
当主Redis加锁了,开始执行线程,若还未将锁通过异步同步的方式同步到从Redis节点,主节点就挂了,此时会把某一台从节点作为新的主节点,此时别的线程就可以加锁了,这样就出错了,怎么办?
a)采用zookeeper代替Redis
由于zk集群的特点,其支持的是CP。而Redis集群支持的则是AP。
b)采用RedLock
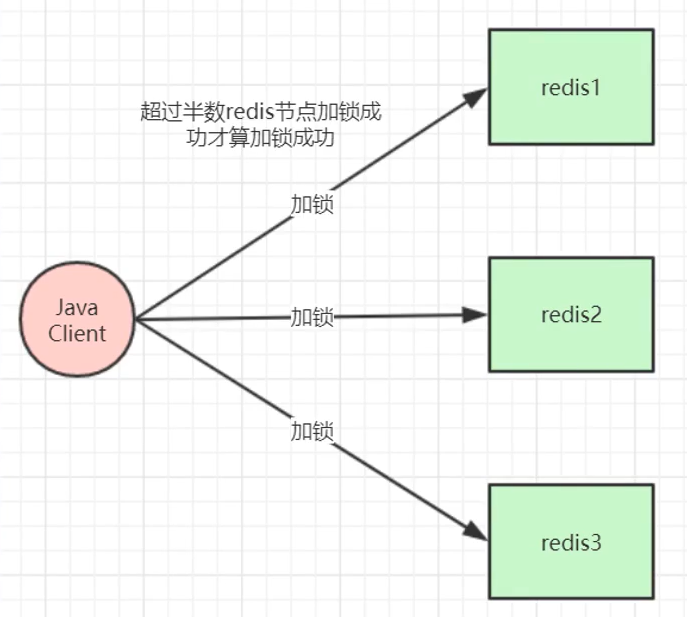
假设有3个redis节点,这些节点之间既没有主从,也没有集群关系。客户端用相同的key和随机值在3个节点上请求锁,请求锁的超时时间应小于锁自动释放时间。当在2个(超过半数)redis上请求到锁的时候,才算是真正获取到了锁。如果没有获取到锁,则把部分已锁的redis释放掉。
@RequestMapping("/deduct_stock_redlock")
public String deductStockRedlock() {
String lockKey = "product_001";
//TODO 这里需要自己实例化不同redis实例的redisson客户端连接,这里只是伪代码用一个redisson客户端简化了
RLock rLock1 = redisson.getLock(lockKey);
RLock rLock2 = redisson.getLock(lockKey);
RLock rLock3 = redisson.getLock(lockKey);
// 向3个redis实例尝试加锁
RedissonRedLock redLock = new RedissonRedLock(rLock1, rLock2, rLock3);
boolean isLock;
try {
// 500ms拿不到锁, 就认为获取锁失败。10000ms即10s是锁失效时间。
isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS);
System.out.println("isLock = " + isLock);
if (isLock) {
//业务逻辑处理
...
}
} catch (Exception e) {
} finally {
// 无论如何, 最后都要解锁
redLock.unlock();
}
}
具体使用存在争议,不太推荐使用。如果考虑高可用并发推荐使用Redisson,考虑一致性推荐使用zookeeper。
2,提高并发:分段锁
由于Redisson实际上就是将并行的请求,转化为串行请求。这样就降低了并发的响应速度,为了解决这一问题,可以将锁进行分段处理:例如秒杀商品001,原本存在1000个商品,可以将其分为20段,为每段分配50个商品...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号