
Hbase的基本架构以及对应的读写流程
一、HBase简介
1,定义:
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
2,HBase的架构图:

架构角色:
1)Master
Master是所有Region Server的管理者,其实现为HRegionServer,主要作用有:
a>对于表的DDL操作:create,delete,alter
b>对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
2)Zookeeper:
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
3)WAL:
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写入Write-Ahead logfile的文件中,然后再写入到Memstore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)MemStore:
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
5)StoreFile:
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在StoreFile上是有序的。
3,数据模型:
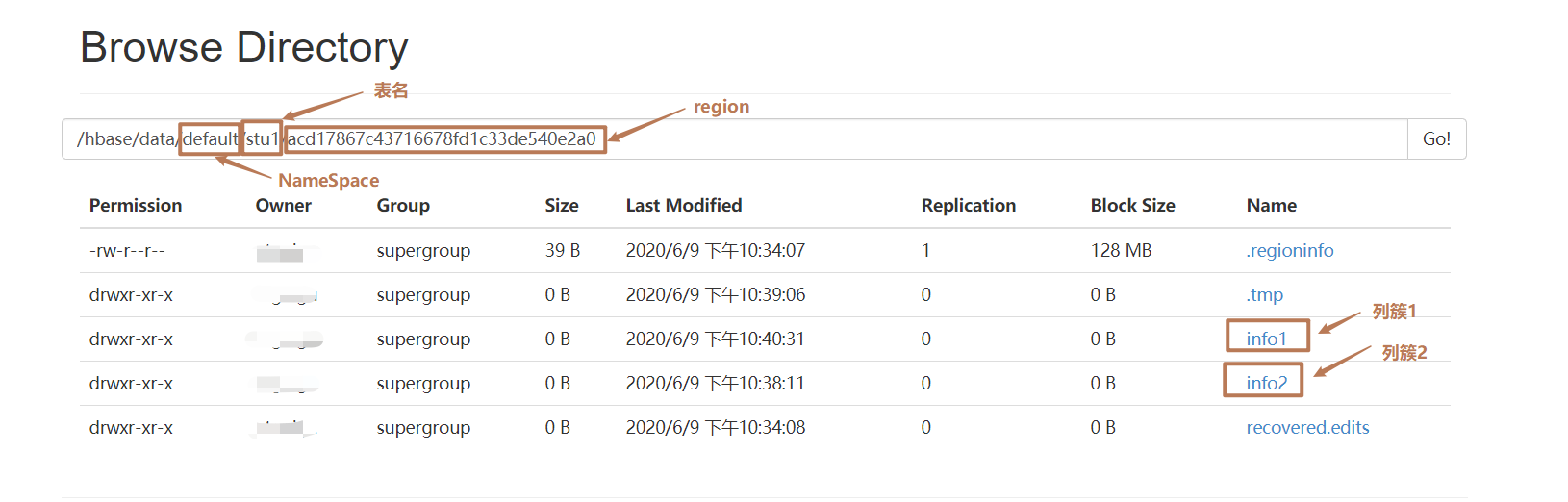
1)Name Space
命名空间,类似于关系型数据库的DataBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase的内置表,default表示用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要生命列簇即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询时智能根据RowKey进行检索,所以RowKey的书籍十分重要。
4)Cloumn
HBase中的每个列都由Cloumn Family(列簇)和Cloumn Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列簇,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
二、HBase写数据流程
1,HBase的写数据流程
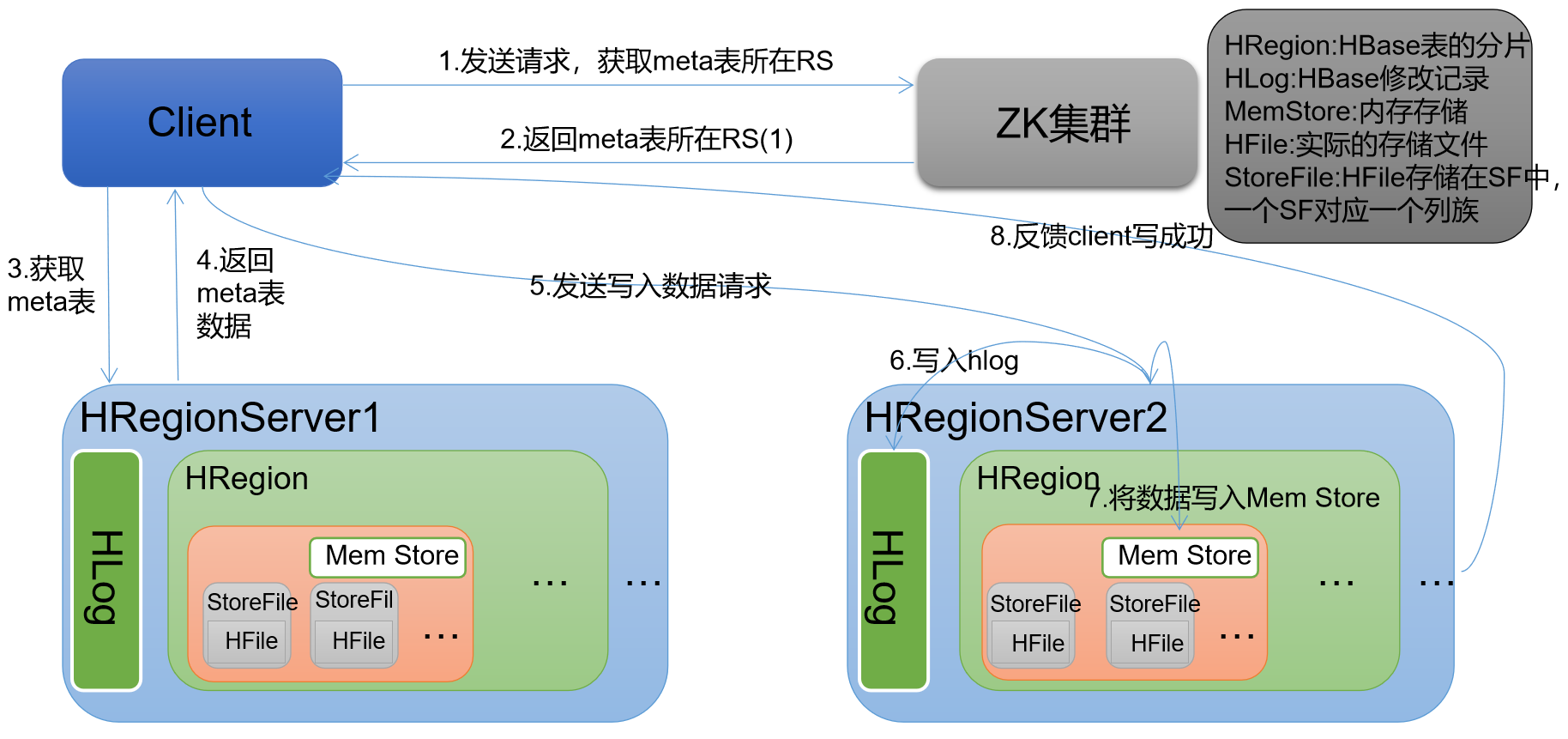
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。 #zk get /hbase/meta-region-server 2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。 并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。 #hbase scan 'hbase:meta' 查询到具体哪张表由哪个Region Server维护 3)与目标 Region Server 进行通讯; 4)将数据顺序写入(追加)到 WAL; 5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序; 6)向客户端发送 ack; 7)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
2,MemStore Flush刷写
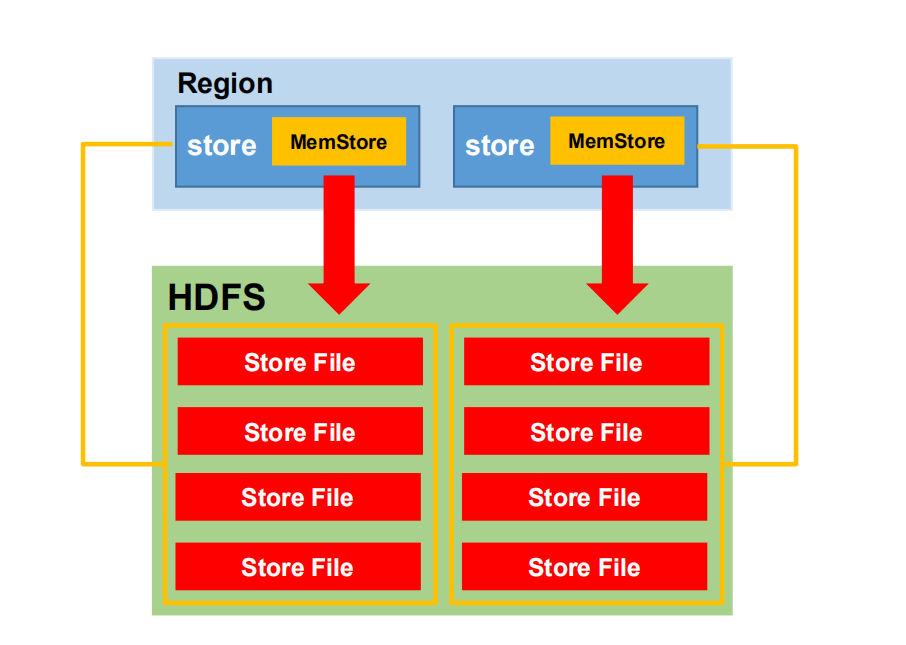
MemStore刷写时机
1.当某个MemStore的大小达到了hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore (对应的列簇)都会刷写。 当达到128M的时候会触发flush memstore,当达到128M * n还没法触发flush时候会抛异常来拒绝写入。两个相关参数的默认值如下: hbase.hregion.memstore.flush.size=128M(默认) hbase.hregion.memstore.block.multiplier=4(默认) 2.当 region server 中 memstore 的总大小达到 java_heapsize(应用的堆内存) *hbase.regionserver.global.memstore.size(默认值 0.4) *hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95), region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server中所有 memstore 的总大小减小到上述值以下。当 region server 中 memstore 的总大小达到java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)时,会阻止继续往所有的 memstore 写数据。 3.到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。 4.当 WAL 文件的数量超过 hbase.regionserver.maxlogs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.maxlogs 以下(该属性名已经废弃,现无需手动设置,最大值为 32)。
三、HBase读数据流程
1,读数据流程
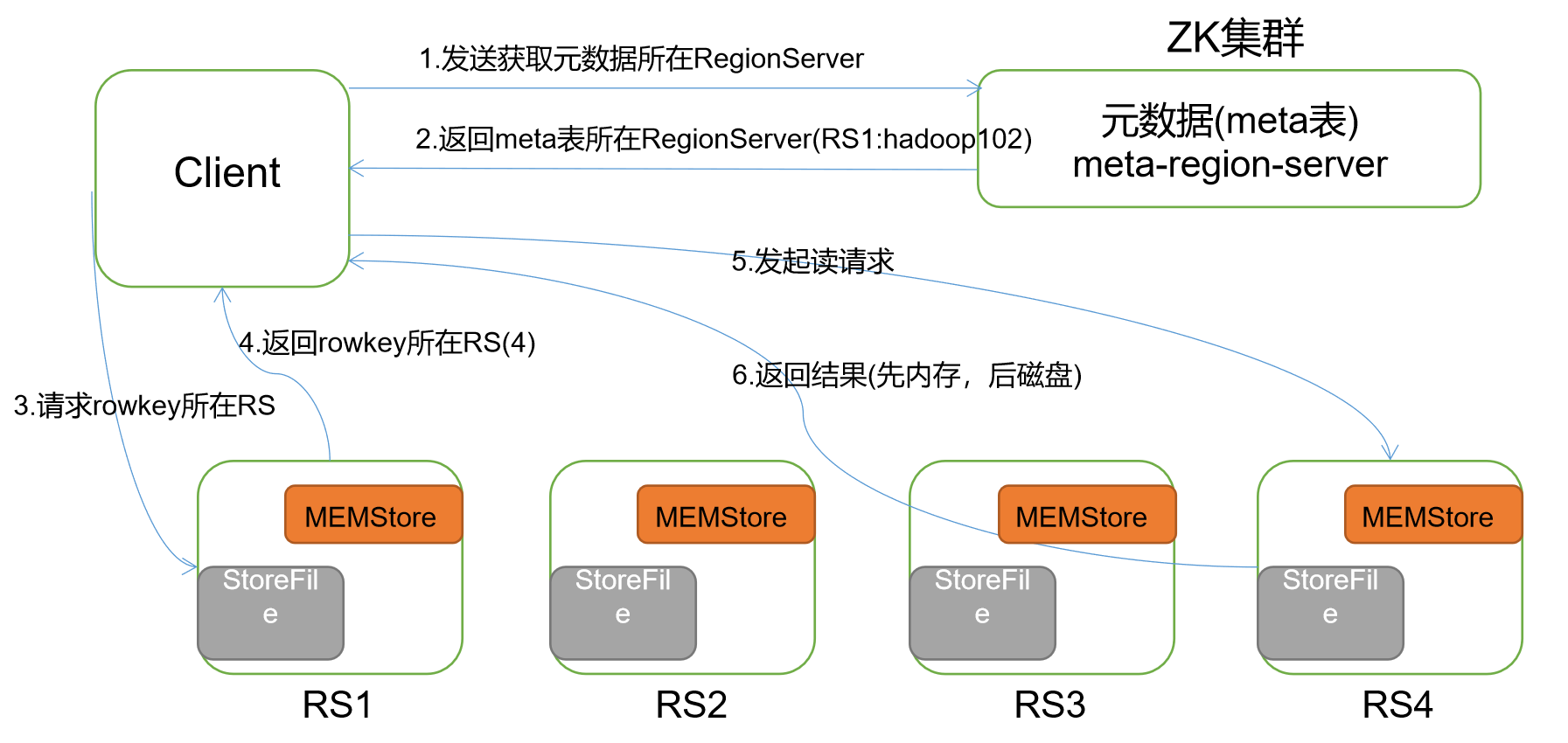
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。 2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。 3)与目标 Region Server 进行通讯; 4)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。 5)将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。 6)将合并后的最终结果返回给客户端。
2,StoreFile Compaction
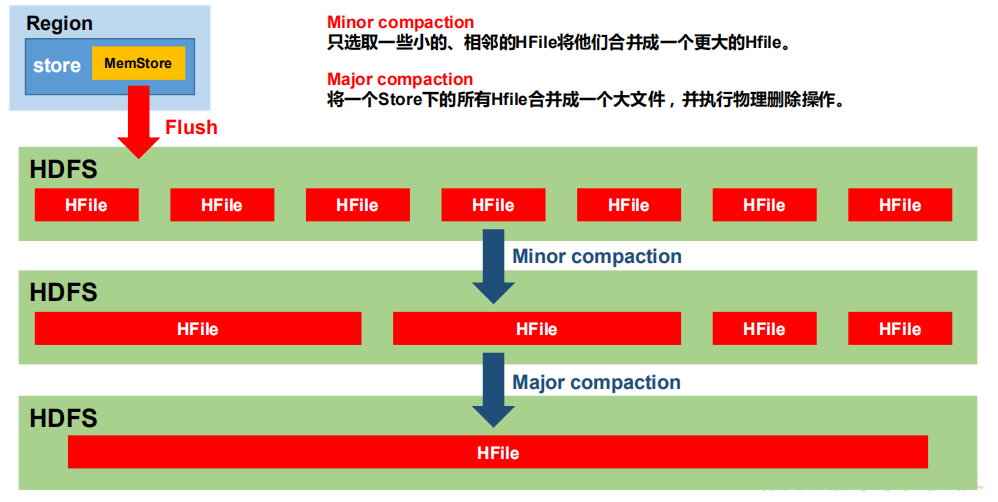
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清除掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别时Minor Compaction和Major Compaction。Minor Compaction会将临时的若干较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。Major Compaction会将一个Store下的所有HFile合并为一个大HFile,并且会清理掉过期和删除的数据。
3,Region Split

默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号