kafka原理及说明文档
参考博文:kafka工作原理介绍 - Saint - CSDN博客
Kafka教程(一)Kafka入门教程 - yuan_xw的专栏 - CSDN博客
Kafka介绍 - 一人浅醉- - 博客园
kafka原理和实践(一)原理:10分钟入门 - 只会一点java - 博客园
自己写的springboot整合kafka的demo(有用的话请star哦!):https://github.com/lwj108/message-center-kafka
1.什么是消息队列(Message Queue)
消息队列是消息在传输过程中保存消息的容器(源自百度百科),消息传送依赖于大量支持组件,这些组件负责处理连接服务、消息的路由和传送、持久性、安全性及日志记录。目前使用较多的消息队列有:ActiveMQ,RabbitMQ,Kafka,RocketMQ等等。应用的场景有异步处理,应用解耦,流量削锋和消息通讯。
2.kafka介绍
kafka是分布式发布-订阅消息系统,即分布式流处理平台。Kafka是最初由Linkedin公司开发,使用Scala语言编写,后成为Apache顶级项目。是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展
3.kafka术语介绍
- Producer 消息生产者,是消息的源头,负责生成消息并发送到kafka服务器上。
- Consumer 消息消费者,是消息的使用方,负责消费kafka服务器上的消息。
- Topic 主题,有用户定义并配置在kafka服务器,勇于建立生产者和消费者之间的订阅关系;生产者发送消息到指定的Topic下,消费者从这个Topic下消费消息。
- Partition 消息分区,一个Topic下面会分为很多个分区,是Topic物理上的分组,一个Topic可以分为多个Partition,Partition是一个有序的队列,每个partition又由一个一个消息组成。每个消息都被标识了一个递增序列号(offset)代表其进来的先后顺序,并按顺序存储在partition中。
- Broker kafka的服务器,用户存储消息的地方,kafka集群中的一个或者多个服务器统称为Broker。
- Group 消费者分组,用于归组同类消费者,在Kafka中,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。多个消费者可以
- Message 消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息
- Offset 消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个偏移量就是所谓的Offset。
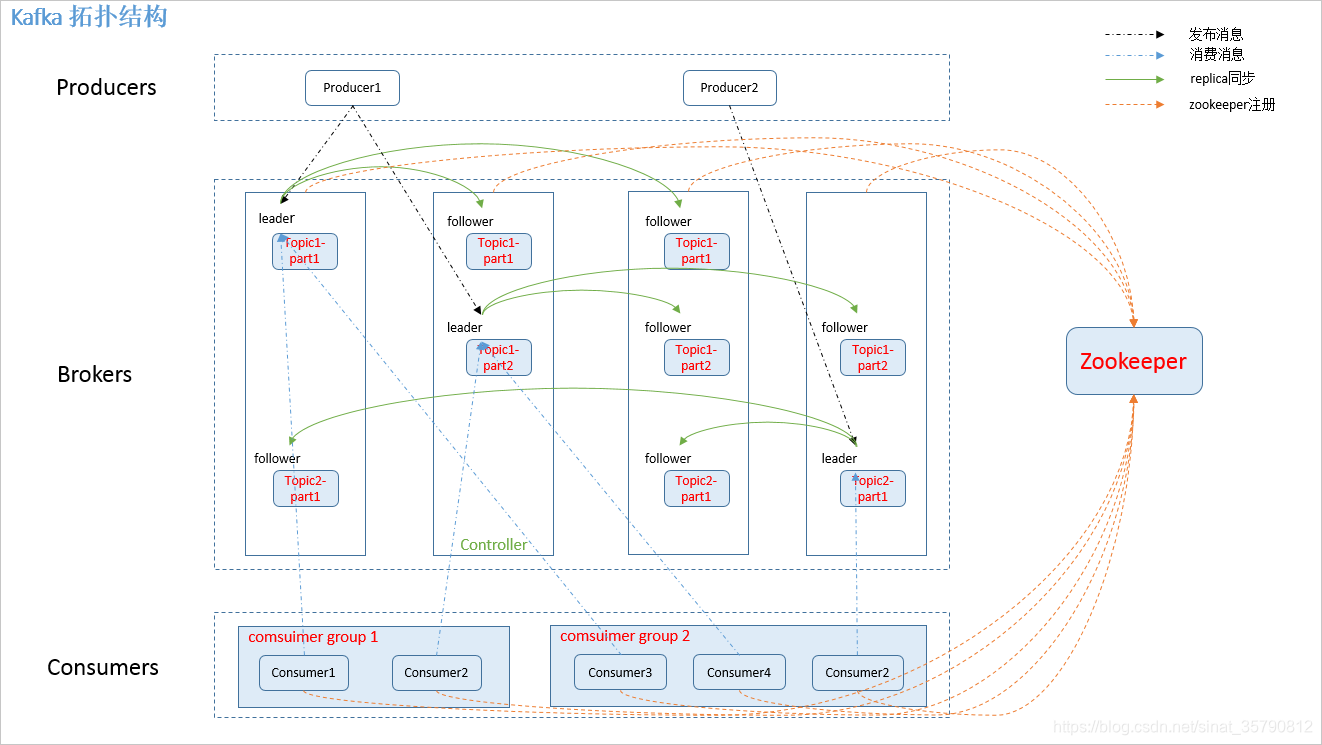
4.kafka工作流程
- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
- Consumer从kafka集群pull数据,并控制获取消息的offset
5.message微服务整合kafka工作原理

① 消息微服务中的数据存库并根据消息的类型通过@Scheduled定时推送到kafka对应的topic。
② 推送即修改sendLog的status状态。
③ 通过@KafkaListener监听各个topic进行消息拉取分发到各个对应的消费者。
④ 根据消费者返回的信息修改消息状态,对于消费者未返回信息的消息返回ResendTopic等待重新发送,消息失败三次后将不再重新发送。
6.消息传送机制
对于JMS实现,消息传输担保非常直接:有且只有一次(exactly once).在kafka中稍有不同:
- at most once: 最多一次,这个和JMS中"非持久化"消息类似.发送一次,无论成败,将不会重发.
- at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功.
- exactly once: 消息只会发送一次.
at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后"未处理"的消息将不能被fetch到,这就是"at most once".
at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态.
exactly once: kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的.
通常情况下"at-least-once"是我们首选.(相比at most once而言,重复接收数据总比丢失数据要好).
7.复制备份
kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower和consumer一样,消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它.即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(不同于其他分布式存储,比如hbase需要"多数派"存活才行)
当leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个"up-to-date"的follower.选择follower时需要兼顾一个问题,就是新leader上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.在选举新leader,需要考虑到"负载均衡".
8.kafka中需要注意的点
kafka和JMS(Java Message Service)实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值.
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响.
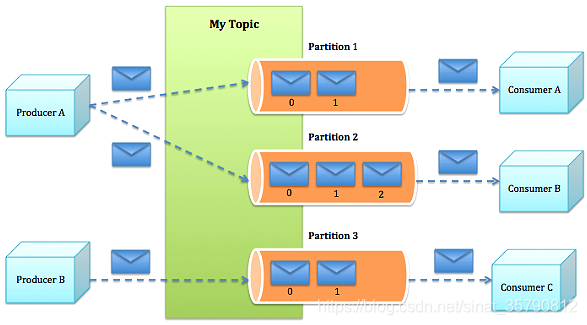
partitions的目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.
一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可…由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
Producers将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等.
Consumers本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号