Linux——深入理解NUMA _【DBA 必备技能1】

———————————————————————————————————————————————————
---- bayaim
---- 2025年3月3日10:11:21
———————————————————————————————————————————————————
一、NUMA的由来,SMP架构
NUMA(Non-Uniform Memory Access),即非一致性内存访问,是一种关于多个CPU如何访问内存的架构模型,早期,在计算机系统中,CPU是这样访问内存的:
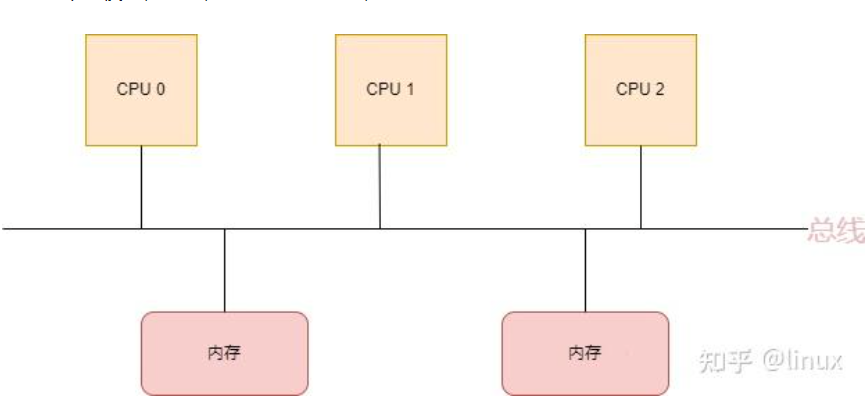
在这种架构中,所有的CPU都是通过一条总线来访问内存,我们把这种架构叫做SMP架构(Symmetric Multi-Processor),也就是对称多处理器结构。可以看出来,SMP架构有下面4个特点:
- CPU和CPU以及CPU和内存都是通过一条总线连接起来
- CPU都是平等的,没有主从关系
- 所有的硬件资源都是共享的,即每个CPU都能访问到任何内存、外设等
- 内存是统一结构和统一寻址的(UMA, Uniform Memory Architecture)
SMP架构在CPU核不多的情况下,问题不明显,有实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU:
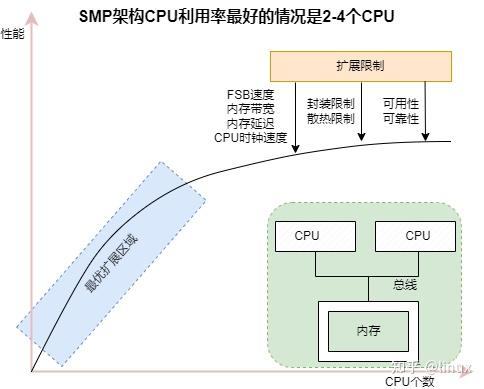
但是随着CPU多核技术的发展,一颗物理CPU中集成了越来越多的core,导致SMP架构的性能瓶颈越来越明显,因为所有的处理器都通过一条总线连接起来,因此随着处理器的增加,系统总线成为了系统瓶颈,另外,处理器和内存之间的通信延迟也较大。
为了解决SMP架构下不断增多的CPU Core导致的性能问题,NUMA架构应运而生,NUMA调整了CPU和内存的布局和访问关系,具体示意如下图:
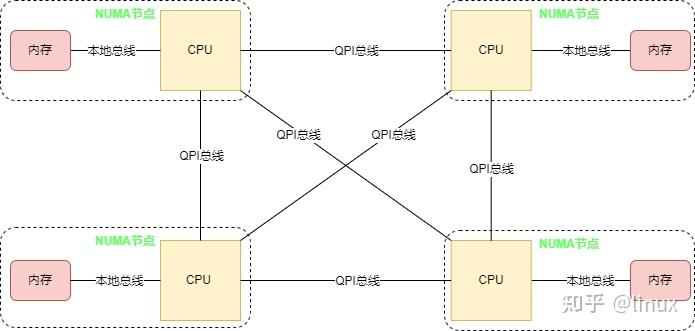
在NUMA架构中,将CPU划分到多个NUMA Node中,每个Node有自己独立的内存空间和PCIE总线系统。各个CPU间通过QPI总线进行互通。
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访,问速度越慢,所以叫做非一致性内存访问,这个访问内存的距离我们称作Node Distance。
虽然NUMA很好的解决了SMP架构下CPU大量扩展带来的性能问题,但是其自身也存在着不足,当Node节点本地内存不足时,需要跨节点访问内存,节点间的访问速度慢,从而也会带来性能的下降。所以我们在编写应用程序时,要充分利用NUMA系统的这个特点,尽量的减少不同CPU模块之间的交互,避免远程访问资源,如果应用程序能有方法固定在一个CPU模块里,那么应用的性能将会有很大的提升。
二、NUMA架构下的CPU和内存分布
在Linux系统上,可以查看到NUMA架构下CPU和内存的分布情况,不过在这之前,我们先得理清几个概念:
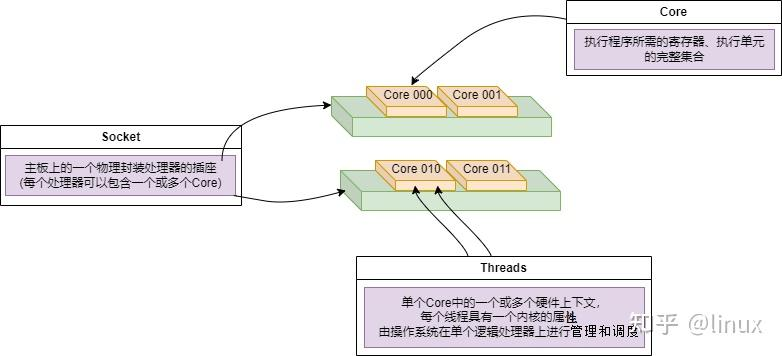
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽,Socket表示可以看得到的真实的CPU核 。
- Core:物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等,Core表示的是在同一个物理核内逻辑层面的核。同一个物理CPU的多个Core,有自己独立的L1和L2 Cache,共享L3 Cache。
- Thread:使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,共享执行单元和一二三级Cache,超线程技术可以带来20%~30%的性能提升。
- Node:即NUMA Node,包含有若干个 CPU Core 的组。
Socket、Core和Threads之间的关系示意如下:
三、Linux 常见运维
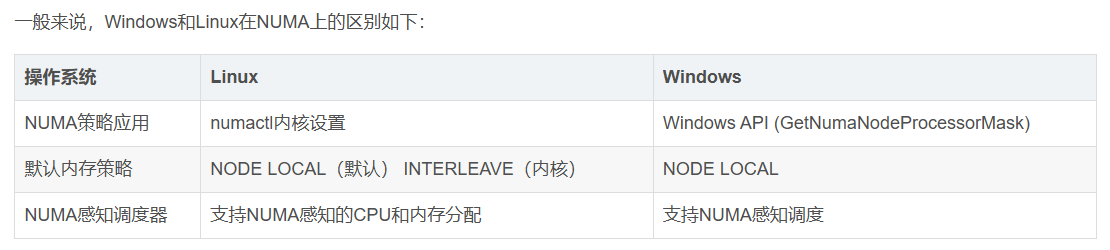
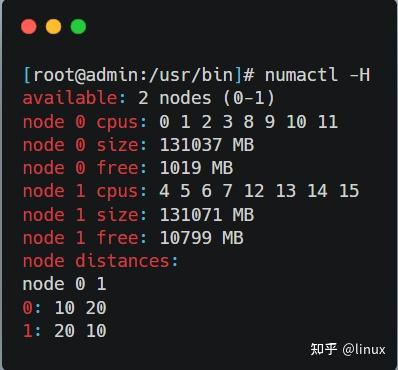
1、使用 numactl -H 命令可以看到NUMA下的内存分布:
2、通过numastat命令查看NUMA系统下内存的访问命中率:
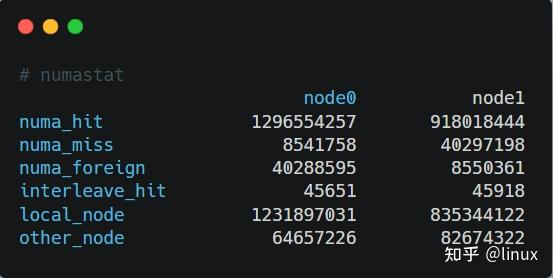
- numa_hit:成功分配给此节点的页面数量。
- numa_miss:由于预期节点上的内存较低,在此节点上分配的页面数量。每个 numa_miss 事件在另一个节点上都有对应的 numa_foreign 事件。
- numa_foreign:最初用于分配给另一节点的页面数量。每个 numa_foreign 事件在另一节点上都有对应的 numa_miss 事件。
- interleave_hit:成功分配给此节点的交集策略页面数量。
- local_node:此节点上的进程在这个节点上成功分配的页面数量。
- other_node:通过另一节点上的进程在这个节点上分配的页面数量。
如果miss值和foreign值越高,就要考虑线程绑定以及内存分配使用的问题。
需要注意的是,NUMA Node和socket并不一定是一对一的关系,在AMD的CPU中,可能更多见于NUMA Node比socket个数多(一般AMD的CPU的NUMA可以在BIOS中进行配置),而Intel的CPU中,NUMA Node可能比socket的个数还少。
3、 NUMA 的内存策略
• localalloc:总是在当前节点上分配内存;如当前节点内存不足,再从其他节点分配。Default即此策略
• preferred :倾向于在特定节点上分配内存,当指定节点的内存不足时,操作系统会在其他节点上分配
• membind:只能在传入的几个节点上分配内存,当指定节点的内存不足时,内存的分配就会失败
• interleave:内存会在传入的节点上依次轮询,当指定节点的内存不足时,操作系统会在其他节点上分配
4、开启和关闭 NUMA
1) BIOS开启NUMA:将使用localalloc模式,总是在当前节点上分配内存;如当前节点内存不足,再从其他节点分配。大多数情况下,它是默认值。
2)BISO关闭NUMA:将使用细粒度交织模式。以几个CacheLine(到底是几个还需要验证)大小为单位交织。
3)如果使用numactl: 以numactl为准。
4)如果程序使用set_mempolicy(),以set_mempolicy()为准。
5、
CPU内部有很多并行的,叫指令级并行,ILP,有时候会影响测试结果,要想办法避免。
6、绑定固定node
之前曾经介绍过NUMA的原理以及基于Cgroup的NUMA设定。
这次我采用的是通过docker封装好的SPECjbb2005,Docker从本质上说底层就是一个cgroup。
首先是机器的NUMA拓扑:
# # numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 0 size: 130502 MB
node 0 free: 123224 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 1 size: 131072 MB
node 1 free: 126082 MB
node distances:
node 0 1
0: 10 21
1: 21 10开启HT之后,系统显示64个core,其中core 0-15,32-47位于NUMA node0,Core16-31,48-63 位于 NUMA node1
通过限制cpuset-cpus,cpuset-mems只允许SPECjbb运行在core 0-15,32-47,并只能访问NUMA node1
docker run --cpuset-cpus=0-15,32-47 --cpuset-mems=0 specjbb然后就是之允许方位node1
docker run --cpuset-cpus=0-15,32-47 --cpuset-mems=1 specjbb最后就是不做任何限定
docker run --cpuset-cpus=0-15,32-47 specjbb一开始我自己觉得这3个场景的性能差异应该不会很大,谁知道拿出数据来之后我傻了。
7、
1. 查看主机Node
下面将结合自己机器来看下NUMA架构下的CPU拓扑关系。
NUMA使用node来管理cpu和内存。
ls /sys/devices/system/node/node
2. 查看主机Socket
Socket的信息可以通过/proc/cpuinfo查看,里面的physical id标示的就是socket号。
cat /proc/cpuinfo | grep "physical id" | sort -ucat /proc/cpuinfo | grep "physical id" | sort -u | wc -l3. 查看每个Node的cpu
ls /sys/devices/system/node/node0/cpu
ls /sys/devices/system/node/node1/cpu
4. 查看主机Core信息
下面看下core的信息,core也是通过/proc/cpuinfo查看,其中和core相关的信息有:
|
core id |
此cpu在所在core中的编号 |
|
cpu cores |
一个socket上面有多少个core |
作者的机器上每个socket上面有10个core
cat /proc/cpuinfo | grep "cpu cores" | sort -u5. 查看主机Thread
下面来看下thread的信息,cat /proc/cpuinfo可以看到每个thread,也就是每个逻辑cpu的详细信息。
cat /proc/cpuinfo上面是cpu0的详细信息,红色框中是相关的几条信息。
physical id为0表示此cpu在socket0也就是node0上面
cpu cores为10表示此node上面有10个core
core id为0表示此cpu在node0的core0上面
siblings为20表示此cpu0在core0里面的兄弟逻辑cpu为cpu20
6、如何查看机器的NUMA拓扑结构
[root@bigdata-batch ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 48 //共有48个逻辑CPU(threads) On-line CPU(s) list: 0-47 Thread(s) per core: 2 //每个core有2个threads Core(s) per socket: 12 //每个socket有12个cores Socket(s): 2 //共有2个sockets NUMA node(s): 2 //共有2个NUMA nodes Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Silver 4116 CPU @ 2.10GHz Stepping: 4 CPU MHz: 2399.926 CPU max MHz: 3000.0000 CPU min MHz: 800.0000 BogoMIPS: 4200.00 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 16896K NUMA node0 CPU(s): 0-11,24-35 NUMA node1 CPU(s): 12-23,36-47
从上面的输出,可以看出当前机器有2个sockets,每个sockets包含1个numa node,每个numa node中有12个cores,每个cores包含2个thread,
所以,总的threads数量=2(sockets)×1(node)×12(cores)×2(threads)=48.
———————————————————————————————————————————————————
---------------------------------------------------------
摘录地址:
https://zhuanlan.zhihu.com/p/643610982
https://zhuanlan.zhihu.com/p/717945729
、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号