OceanBase-OCP-【告警】-OCP频繁出现主机不可用告警
一、先说,处理过程
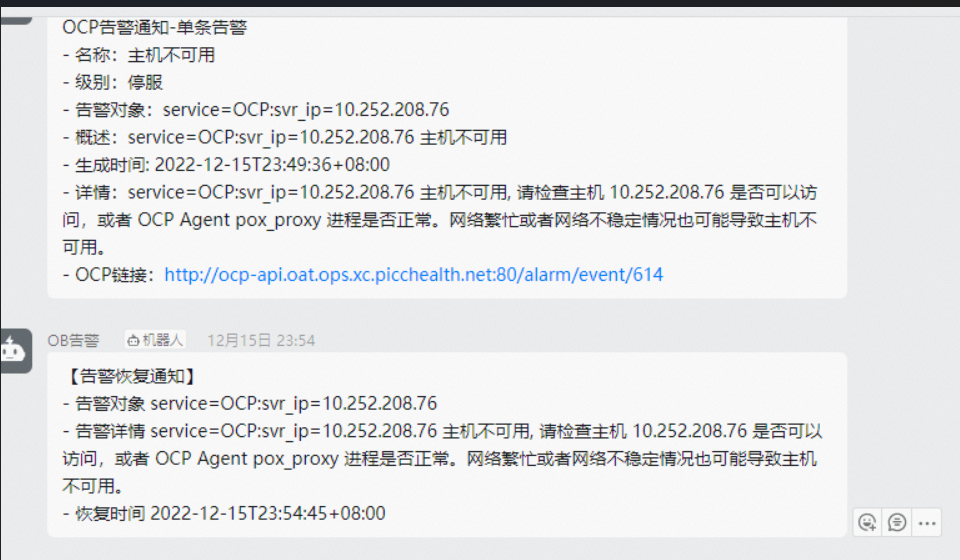
OCP频繁出现主机不可用告警 -------------------------------------------------- 一、环境 生产环境,监控9个节点,fgc、内存、OCP各个节点网络、NTP都是正常。 云平台底座 3.14-3.16.2,客户ocp是3.1.2-20211025说是升级完ocp会到3.2.4,客户OCP 1-1-1 集群,经常性OCP不可用告警,麻烦查下原因。 3.14-3.16.2 是云平台底座 ocp是3.1.2-20211025 说是升级完ocp会到3.2.4 但我看升完了也没变 ---------------------------------------------------- 二、工单 工单标题 : OCP频繁出现主机不可用告警 OceanBean产品 : OCP 产品版本 : 3.14-3.16.2 问题类型 : 服务故障 问题描述 : 专有云信创环境,底座3.16.2版本 近期频繁出现主机不可用告警,告警期间排查告警主机正常未宕机,ocp与告警主机可以互通,agent进程正常未重启,请协助排查告警原因。 告警规则是否为opc_host表中心跳超时>30s后进行主机判断 ------------------------------------------------- 三、处理 总则: 这个比较难定位问题,但是不影响使用话,可以接受先不管 查询OB主机不可用原因: 三个节点的集群: 1- 1- 1 ocp跟主机可以相互ping通是吧 可以的,而且昨天告警的是个ocp机器 最近这个环境做过云平台升级 10.252.208.76 是其中一个 OCP 10.252.208.76 现在都是没问题的,这就是生产,观察好久了网络或者进程情况,这是第五次还是第六次的告警了。客户要结果 ================================ 2022-12-15 23:49:45.740 INFO 82 --- [alarm-task-2,,6ef057187550] c.a.o.s.a.c.d.GroupMessageDistributor : distribute done, channelId=100001, recipientCount=0, recipients=, message=[OCP告警通知] - 名称: 主机不可用 - 级别:停服 - 告警对象:service=OCP:svr_ip=10.252.208.76 - 概述:service=OCP:svr_ip=10.252.208.76 主机不可用 - 生成时间: 2022-12-15T23:49:36+08:00 - 详情:service=OCP:svr_ip=10.252.208.76 主机不可用, 请检查主机 10.252.208.76 是否可以访问,或者 OCP Agent pox_proxy 进程是否正常。网络繁忙或者网络不稳定情况也可能导致主机不可用。 - 链接:http://ocp-api.oat.ops.xc.picchealth.net:80/alarm/event/614 2022-12-15 23:49:45.740 INFO 82 --- [alarm-task-2,,6ef057187550] c.a.o.s.a.core.process.AlarmProcessor : aggregate result distribute, channelId=100001, groupKey=host_unavailable, distributedNotificationsCount=1 ------------------------------------------- 处理过程: 这个应该是没有重启,看 pid 是一样的,没有日志应该就是请求卡住了,或者请求没有发送到 agent 端 之前版本的限制了并发数量,之前遇到过离线的是线程被占满了,可以看下这个时间段的日志里面有没有其他的慢请求 12.16 19:46:36 告警的这次,pos_proxy在一分钟内没日志,看下面的日志是不是重启了? 2分钟没日志 这个应该是没有重启,看 pid 是一样的,没有日志应该就是请求卡住了,或者请求没有发送到 agent 端 按照以往我们处理的经验会有:看下经常不可用的机器上有没有积攒du进程,触发造成的,该工单诊断以来您的环境的现象属于进程请求卡住了,有时候进程异常了出现短暂不可用现象。 处理总结: 有没有这个指令,或者 ps -ef | grep du, 看下经常不可用的机器上有没有积攒du进程 OCP 3.1.2版本主机频繁告警不可用,日志里有 rpc read timeout,这个是已知问题吗? 这个是依赖 rpc 请求来判断的,每分钟一次,遇到网络波动的话可能偶尔会出现 如果有网络波动,tsar应该可以佐证,但是tasr都是正常的 这个波动不一定体现在网络负载上,可以看下 ocp-agent 端 pos_proxy 的日志在这个时间段是否有请求 问题原因: 1、各个OCP到主机之间网络正常 2、 ps -ef | grep du 机器上有没有积攒du进程 3、OCP 3.1.2版本主机频繁告警不可用,日志里有 rpc read timeou 处理建议: 1、当前告警不影响生产使用,如果出现可以忽略,或增加告警产生频率时间间隔。下次再出现时候我们在具体分析原因 看了下 ocp-agent 端没有收到请求,server 端显示执行命令 10s 超时了,这个校验请求是通过 RPC 请求来发送的,受影响的因素比较多,之前提供过一个参数来增加主机状态监测的容错,可以先修改下这个参数增加下容错,想彻底解决的话可以考虑升级 ocp 版本 可以在系统参数里面查询下 ocp.host.check.unavailable-time-threshold 这个配置项,默认应该是 60000 可以改成 180000 试下,这个作用就是连续 3 次监测失败才会发送主机离线的告警 如果云底座没有调整网络策略的话应该没太关系才对,升级到 3.2.4 版本的话这个 主机状态监测协议就变成 http 了,应该就没这个问题了 是的,把这个改成 180000,这个参数不用重启
二、再说,问题截图







【欢迎关注公众号】:database运维

 浙公网安备 33010602011771号
浙公网安备 33010602011771号