


Scrapy是什么
1.Scrapy是蜘蛛爬虫框架,我们用蜘蛛来获取互联网上的各种信息,然后再对这些信息进行数据分析处理。
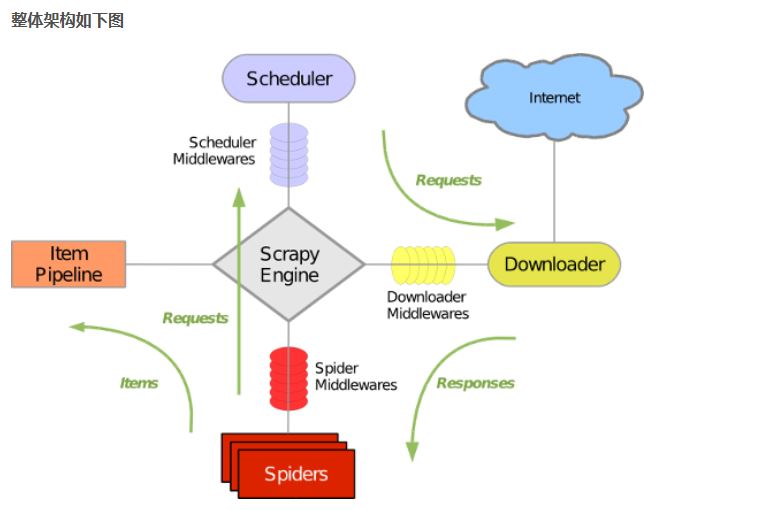
2.Scrapy的组成
- 引擎:处理整个系统的数据流处理,出发事务
- 调度器: 接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回
- 下载器: 下载网页内容,并将网页内容返回给蜘蛛
- 蜘蛛: 蜘蛛是主要干活的,用来制定特定域名或网页的解析规则
- 项目管道: 清洗验证存储数据,页面被蜘蛛解析后,被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件: 位于引擎和下载器之间,处理引擎与下载器之间的请求及响应
- 蜘蛛中间件:位于引擎和蜘蛛之间,处理从引擎发送到调度的请求及响应
3.工作机制
- 爬取流程
首先从URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回给Scheduler;另一种是需要保存的数据,他们被送到Item Pipeline那里,那是对数据进行后期处理(详细分析,过滤,存储)的地方。另外在数据流动的管道里还可以安装各种中间件,进行必要的处理。
- 数据流程
- 引擎打开一个网站,找到处理该网站的Spider,并向Spider请求第一个要爬取的URL。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器中以request进行调度。
- 引擎向调度器请求下一个要爬取的URL
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件转发给下载器
- 下载完毕后,下载器生成一个该页面的response,并将其通过中间件返回给引擎
- 引擎从下载器中接收到response并通过Spider中间件发送给Spider处理
- Spider处理response并返回爬取到的Item及新的Request给引擎。
- 引擎将爬取到的Item给Item Pipeline,将Request给调度器
- 从第二步重复,直到调度器中没有更多的request,引擎关闭该网站。

