


python 正则表达式
1. 检测工具
https://regex101.com/ 这个不要钱
https://www.regexbuddy.com/download.html 需要钱钱买license
是真的好用
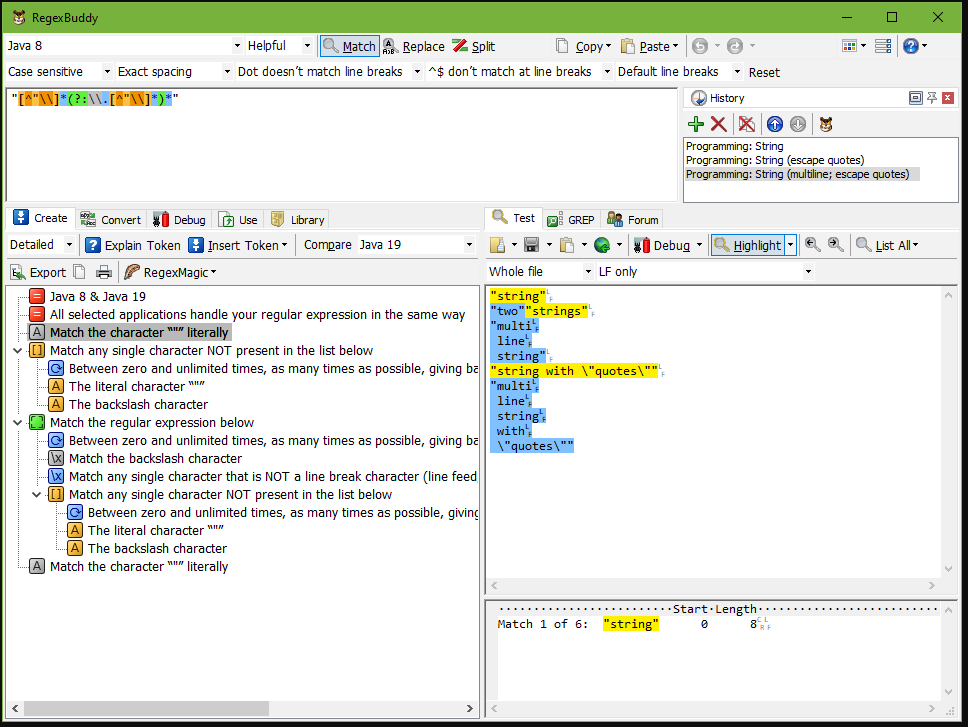
2. 单字符匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | . 匹配任意一个字符(除了\n)[] 匹配[]内列举的字符\d 匹配数字0-9\D 匹配非数字,不是数字的都行\s 匹配空白,即 空格,\t tab键,\n 换行\S 匹配非空白\w 匹配单词字符,即A-Z, a-z, 0-9, _\W 匹配非单词字符, 即非字母,非数字,非下划线 |
1 2 3 4 5 | [hr] 即可以匹配单个字符h,又可以匹配单个字符r,[a-h] 可以匹配单个a , 可以匹配单个b, 可以匹配单个c, 可以匹配单个d, 可以匹配单个e, 可以匹配单个f, 可以匹配单个g, 可以匹配单个h[A-Z0-9] 匹配所有的大写字母和所有的数字 |
3. 匹配多个字符
1 2 3 4 5 6 7 8 9 | * 匹配前一个字符任意次,即可有可无+ 匹配前一个字符1次或者无限次,即至少一次? 匹配前一个字符出行1次或者0次,即要么有1次,要么没有{m} 匹配前一个字符m次{m,n} 匹配前一个字符出现从m次到n次,m<n |
举个栗子
1 2 3 4 5 6 7 8 9 | ^[a-zA-Z_]+\w* 匹配变量名[0-9]?[0-9] 匹配0-99\d{3} 连续出现4次数据\d{8,20} 连续8到20位数字\. 只能匹配. \代表转义字符,如果只写.,代表匹配任意字符 |
4. 匹配开头
1 2 3 4 5 6 7 8 9 | ^ 匹配后面一个字母开头;在中括号内 [^a]取反, 匹配不是a的字符$ 匹配前面一个字母结尾 ^[a-z]\d$ 以小写字母开头,以数字结尾[^he] 匹配不包含h,不包含e的单个字母 |
5. re模块
在python中需要通过正则表达式对字符串进行匹配的时候,可以使用re模块,这个模块里面有match(pattern,String,flag)方法, 如果匹配成功,返回object对象,如果匹配不成功,返回None。
举个栗子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import reif __name__ == '__main__': str = 'ddddffffff%' patobj = re.match('\w+', str) # group() 返回匹配的内容,这里返回ddddffffff print(patobj.group()) str2 = 'hekkko@163.com' patobj2 = re.match('^\w{4,20}@163\.com$', str2) print(patobj2.group())执行结果PycharmProjects/pythonProject/p3/repat.pyddddffffffhekkko@163.comProcess finished with exit code 0 |
6.匹配分组之 |
|匹配左右任意一个表达式
1 2 | #匹配0-100^[0-9]?[0-9]$|^100$<br><br>import re<br>if __name__ == '__main__':<br> str3 = '100'<br> patobj3 = re.match('^[0-9]?[0-9]$|^100$', str3)<br> print(patobj3.group())<br><br> str4 = '99'<br> patobj4 = re.match('^[0-9]?[0-9]$|^100$', str4)<br> print(patobj4.group())<br><br>result<br>PycharmProjects/pythonProject/p3/repat.py<br>100<br>99<br><br>Process finished with exit code 0 |
7.匹配分组之()
()看成一个整体,进行整体匹配, (ab)将括号中字符ab作为一个分组
1 | import re<br>if __name__ == '__main__':<br> str5 = 'helll@163.com'<br> patobj5 = re.match('^\w{4,20}@(163|126|qq)\.(com)$', str5)<br> print(patobj5.group())<br> print(patobj5.group(1)) #正则表达式里面第一个小括号的匹配内容 <br> print(patobj5.group(2)) #正则表达式里面第二个小括号的匹配内容<br><br><br>C:\Users\GINAGZLI\.virtualenvs\p3-uIsbL7fV\Scripts\python.exe C:/Users/‘’‘’‘’/PycharmProjects/pythonProject/p3/repat.py<br>helll@163.com<br>163<br>com<br><br>Process finished with exit code 0 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import reif __name__ == '__main__': str6 = '010-11111111' str7 = '1234-2222222' patobj6 = re.match('(\d{3,4})-(\d{7,8})', str6) patobj7 = re.match('(\d{3,4})-(\d{7,8})', str7) print('qu hao', patobj6.group(1)) print('dian hua hao ma', patobj6.group(2)) print('qu hao', patobj7.group(1)) print('dian hua hao ma', patobj7.group(2))C:\Users\GINAGZLI\.virtualenvs\p3-uIsbL7fV\Scripts\python.exe C:/Users/uuuuu/PycharmProjects/pythonProject/p3/repat.pyqu hao 010dian hua hao ma 11111111qu hao 1234dian hua hao ma 2222222Process finished with exit code 0 |
8. 匹配分组之 \
\num 表示引用第num个()里面的pattern
\1 表示引用第一个()里面的pattern
1 2 3 4 5 6 7 8 9 10 11 12 13 | import reif __name__ == '__main__': str8 = "<html>testPattern</html>" # \1表示引用()里面的pattern 也就是这串([a-zA-Z0-9]+),这里需要用转义字符\\1机器才能按\1办事儿 patobj8 = re.match("<([a-zA-Z0-9]+)>.*</\\1>", str8) print(patobj8.group())C:/Users/oooo/PycharmProjects/pythonProject/p3/repat.py<html>testPattern</html>Process finished with exit code 0<br><br><br><br><br>import re<br>if __name__ == '__main__':<br> str9 = "<html><h1>testPattern</h1></html>"<br> # patobj9 = re.match("<([a-zA-Z0-9]+)><\\1>.*</\\1></\\1>", str9) 我不清楚这个错在哪里, 这个匹配不到,不能多次引用同一个么? 拜托能为我解惑的朋友给留言<br> patobj9 = re.match("<([a-zA-Z0-9]+)><([a-zA-Z0-9]+)>.*</\\2></\\1>", str9) 这个能匹配到<br> print(patobj9.group())<br><br><br> |
9. 匹配分组之别名
1 2 3 4 5 6 | import reif __name__ == '__main__': str10 = "<html><h1>testPattern</h1></html>" #?P<name1>是[a-zA-Z0-9]+的别名 ,(?P=name1)代表引用name1 patobj10 = re.match("<(?P<name1>[a-zA-Z0-9]+)><(?P<name2>[a-zA-Z0-9]+)>.*</(?P=name2)></(?P=name1)>", str10) print(patobj10.group()) |
10. re模块的其他用法
10.1 search 查找
re.search('hello','helloxxxx')能匹配成功,re.search('hello','xhelloxxxx')能匹配成功
match是从正则开头的才能匹配到,比如 re.match('hello','helloxxxx')能匹配成功,re.match('hello','xhelloxxxx')不能匹配成功
search的搜索范围比match大,直接在字符串里面搜索
1 2 3 4 | import reif __name__ == '__main__': str11 = "dfgsdgad9999dddd" patobj11 = re.search('\d+', str11) |
10.2 findall() 返回一个列表
1 2 3 4 5 6 7 8 9 10 11 | import reif __name__ == '__main__': str12 = "dfgsdgad9999dddd, 5555,444,fff666,777" patobj12 = re.findall('\d+', str12) print(patobj12)C:\Users\GINAGZLI\.virtualenvs\p3-uIsbL7fV\Scripts\python.exe C:/Users/77777/PycharmProjects/pythonProject/p3/repat.py['9999', '5555', '444', '666', '777']Process finished with exit code 0 |
10.3 sub 替换
sub("正则pattern", new , 要替换的字符串)
返回值是替换后的字符串
1 2 3 4 5 6 7 8 9 10 11 12 | import reif __name__ == '__main__': str13 = "dfgsdgad9999dddd, 5555,444,fff666,777" patobj13 = re.sub('\d+','10000', str13) print(patobj13)C:\Users\ooooo\.virtualenvs\p3-uIsbL7fV\Scripts\python.exe C:/Users/ooooo/PycharmProjects/pythonProject/p3/repat.pydfgsdgad10000dddd, 10000,10000,fff10000,10000Process finished with exit code 0 |
三个双引号定义一个多行的字符串
strhtml = """
<p>1 src="vender.e349f038.js"</p>
<script type="text/javascript" src="runtime~app.e349f038.js"></script>
<div class="reminders Football close" style="top: 0px; left: 0px;"></div>
<script type="text/javascript" src="runtime~app.e349f038.js"></script>
<p>5 type="text/javascript" src="app.e349f038.js"</p>
"""
10.4 split
1 2 3 4 5 | import reif __name__ == '__main__': str14 = "hi:hello icsics open,world" patobj14 = re.split(':|,| ', str14) print(patobj14)<br><br>C:\Users\66666\.virtualenvs\p3-uIsbL7fV\Scripts\python.exe C:/Users/555555/PycharmProjects/pythonProject/p3/repat.py<br>['hi', 'hello', 'icsics', 'open', 'world']<br><br>Process finished with exit code 0<br><br> |
10.5 贪婪和非贪婪
在 * ? + {} 后面加个?会把贪婪模式变成非贪婪模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import reif __name__ == '__main__': str14 = "aaa123456" patobj14 = re.match('aaa\d+?', str14) print(patobj14)<re.Match object; span=(0, 4), match='aaa1'>Process finished with exit code 0import reif __name__ == '__main__': str14 = "aaa123456" patobj14 = re.match('aaa(\d+?)', str14) print(patobj14)<re.Match object; span=(0, 4), match='aaa1'>Process finished with exit code 0import reif __name__ == '__main__': str14 = "aaa123456" patobj14 = re.match('aaa[\d+?]', str14) print(patobj14)<re.Match object; span=(0, 4), match='aaa1'>Process finished with exit code 0 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import reif __name__ == '__main__': str15 = '< span id = "tournament" class ="tab-title-label" > Tournament < / span >' #下面一句pattern中的?就是非贪婪匹配,只取第一个id的值, patobj15 = re.search('id = \".*?\"', str15) #这里我不太明白,我以为是下面这样写,但是这样写不对,请明白的朋友给留言解释,先谢过 #patobj15 = re.search('id = \".*\"?', str15) print(patobj15)<re.Match object; span=(10, 27), match='id = "tournament"'>Process finished with exit code 0 |
1 2 3 4 5 6 7 8 9 10 | import reif __name__ == '__main__': str15 = '< span id = "tournament" class ="tab-title-label" > Tournament < / span >' patobj15 = re.search('id = \"(.*?)\"', str15) print(patobj15.group(1))tournamentProcess finished with exit code 0 |
10.6 r的作用
让\只是斜杠的作用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import reif __name__ == '__main__': str16 = "<html><h1>testPattern</h1></html>" patobj16 = re.match("<([a-zA-Z0-9]+)><([a-zA-Z0-9]+)>.*</\\2></\\1>", str16) #不加r就这么写 \\2 \\1 , patobj16r = re.match(r"<([a-zA-Z0-9]+)><([a-zA-Z0-9]+)>.*</\2></\1>", str16) #加r就这么写 \2 \1 , 只对\ 不用转义了, 其他的 比如 \. 还是跟以前一样 print(patobj16.group()) print(patobj16r.group())<html><h1>testPattern</h1></html><html><h1>testPattern</h1></html>Process finished with exit code 0 |
抽空写的,持续6天,写完了,应该比较全了,如果还有要补充的,麻烦朋友们留言。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架